
P2P网络中的语义异构和语义映射
2012-07-04 09:42:56吴鹏
制造业自动化 2012年14期
吴 鹏
(四川工程职业技术学院,德阳 618000)
1 问题的提出
对等计算对文件共享系统具有较大的贡献。可是,用户在这种文件共享系统中只得利用文件标示符做出查找,很多时候无法获得期望的效果。因此,结构化数据这一概念就规划至对等计算范畴里,P2P数据管理系统应运而生[1,2]。
在P2P数据管理系统中,有多个数据源,也就是说它是多数据的一个管理系统。但如若数据源不一致,就算面对真实世界中同一个实体,也会出现不一致的表述和描述形式。因此,语义异构的问题就随之而来。
通常,信息集成领域传统做法是采用中介系统——集中式的方式对语义异构问题进行阐述。采用物化的方式,把全部数据源集中至核心;把全局查询查询分析后向数据源发送;利用全局模式对所有的数据进行统一的管理。
P2P数据管理系统并没有中心控制结点,它是通过动态广域网进行处理的,不能形成全局、统一的视图。如需在该系统中对语义异构问题进行处理,达到数据整合的目的,就应当在各个数据元之间构建语义映射。
通常语义映射是通过单一数据表当做运算单位。可是常常出现查询一次就会牵涉数据库里诸多数据表的情况,还出现了一种情况是必须同时得到全部需奥数据表,查询指令才能进行的现象。执行多表查询定位指令时,应把其余的多个数据库中名字相重的表去除。所以,要执行多表定位,仍然具有诸多问题要处理。
基于上述情况,本文进行深入的探讨,指出利用分层索引机制的方式来处理。另外,利用多节点集群P2P系统[3]以及通过举例数据表的查询算法[4],能够在P2P数据管理系统里成功运行单表甚至是多表的范围以及精确匹配的查询工作。
另外,把数据表的查询、数据库的定位以及元组的发现分开运行,独立实现。本课题对数据表的查询以及数据库定位问题进行探讨。
2 数据表在P2P网络中的存储
2.1 网络结构
本文通过研究,就P2P数据管理系统的特性进行多节点几圈P2P系统的设计。在该体系里,多节点相互汇聚,成为集群。图1表明了集群是当做一个整体,进行hordc53环的形成过程。

图1 多节点集群P2P系统
显然,每个集群内,拥有诸多节点。它们能够按照需求,构筑成为许多小的子系统。假若有个集群里的节点数量偏少,就将其两两结合组成网络。假若有个集群里节点数量偏多,而要进行数据共享,就将运用随意P2P算法构筑P2P子网络。
通常,多节点的集群P2P网络体系在构成时,能够把一样的数据位于集群里增添一些备份,以期提升数据的下载速度以及增加安全性。此外,能够把和语义有关的数据向相同的集群进行分配,进而使得语义聚集能够运行。
因此,本文下述讨论与研究,均为基于多节点的集群P2P网络开展的。
2.2 数据资源缓存
在P2P数据管理体系里,将有多个节点拥有数据库共享的功能。将一个数据库内的多节点缓存,构筑集群,如此就可以在查询功能执行时,若寻到其中一个节点,对于找寻另外的节点就比较便捷了,即查询算法的简化。而对于在一个数据库里含有多个数据表进行缓存,而关于集群子网络中进行缓存的分布方法,缓存子网能够利用所有一个结构化P2P算法进行运行。而运行集群子网采用Chord协议的方式,描绘成如图2所示。
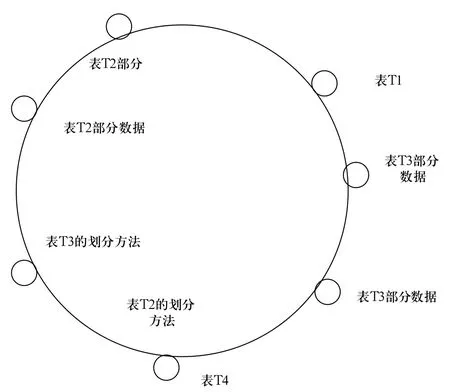
图2 缓存数据源节点子网
3 语义异构问题
通常P2P数据管理体系里含有多组数据源,而数据源存在一定的差异,其对于现实中相同的实物,仍然具有不一样的表述与描述,因此,语义异构这一问题的产生也是因上述差异而导致的。
要处理语义异构的问题,需在各个数据源节点,就要在共享的数据表属性以及表名中队一些列关键字进行定义,以此当做语义映射的媒介。而关键字一样的异构数据源[5],其间将构建自动的映射关系。上述相同的关键字,即当做数据共享的外模式。经外模式的合理运用,先前产生的数据就成为了名称相似的多组数据。而外模式在节点内并没有彻底的物化成视图,它仅仅构筑了内、外双模式,即数据表中真实的一种模式间互相对应的一种关系。系统执行查询过程中,运用下文阐述的算法,把通过外模式运行的查询程序向通过内模式运行的查询程序进行替换,再运行程序。
通常外模式表述的文件生产以及维护,通过数据源节点管理员,使用半自动的运行模式得以实现,其通过描述文件的方式在节点里存储。假若数据表的缓存通过所节点得以储存,详见图2表明的T2参数,则外模式描述文件通过储存表的归类方式的节点得以储存以及输送。假若数据表的缓存通过其中一个节点得以储存,详见图2表明的T1参数,则外模式描述文件通过此节点进行储存以及输送。
此外,除了录入表和属性的名称,外模式还录入数据表属于的集群标识符,以及输送描述文件节点的IP地址。图3举例说明外模式描述文件:

图3 外模式描述文件示例
而外模式描述文件生成以后,应把其输送至整套P2P网络体系里。因外模式描述文件保存的节点都根据数据表的全部名称,通过哈希运算[6]得到,例如图3所表明的外模式描述文件,根据表“同学信息表”或者“学生信息表”,其文件标识符就是通过哈希运算取得。再把外模式描述文件向对应的后记集群进行传递。
后继集群接收该文件以后,把它保存至集群里的节点,以便查询过程可以使用。
通常会有名字一样的数据表存在于各个数据库中,而外模式描述文件,按照数据表名称,运用哈希运算获取文件标识符同时向P2P网络进行传送。所以上述名字相同却来自于各个数据库的表,其外模式文件将向一个集群汇聚。
4 数据表的定位
指的是通过外模式描述文件当做前提而执行的。按照查询所牵涉的数据表数目,能够划成单表以及多表查询。
4.1 单表查询时数据表的定位
通常外模式描述文件按数据表名称当做关键字,运用哈希运算向P2P网络进行分布。假若数据表处于外模式文件里存在K个名称,应把外模式描述文件根据各个名称当做关键字执行哈希运算,再向网络进行分布,备份数量为K。
所有数据表在外模式描述文件中都有几个别名,而属性在数据表里也都有几个别名。假若各个表名—属性名均有完整的一份数据备份对应。则会有大量的冗余数据生成,进而使得系统开发以及储存成本提升。
为提升查询效率,减弱复杂程度,将按照外模式描述文件修改查询条件,进而做到提升数据资源的使用效率,降低备份数目的目标。
图3所示为外模式描述文件。有关真实数据模式有:学号、姓名、年龄、身高,即学生信息表的相关内容按上文阐述,学生信息表有其他的别人,而里面的4个属性都有另外的别名。假若5个参数组合都有一个备份,则共有2×3×3×3×2=108个数据备份。这是不合理的。所以,外模式描述文件寻获后,将会查询条件作出替换,把全部别名转换成数据表里学生真实姓名,之后的查询均采取转换后查询条件。
按数据表执行查询应对相关因素进行充分的考虑。按上述提及的查询举例,具体阐述查询的整个运行流程:
2)如后继集群里并未产生对应的外模式描述文件,那么显示查询失败。否则,进行后续工作。
3)开启获得的外模式描述文件,执行有没有叫“学生信息表”的表名,同时要包含“学生序号,姓名,学生身高,Age”这些属性内容,若无,查询失败。否则,进行后续工作。
4)替换查询条件。把查询条件里的名称转变成<TableInofrmation>下第一个表名。把全部属性名称转变成< Shuxing>下第一个属性名。
5)传送外模式描述文件的IP地址以及节点,也是在共享这个数据表的集群里。和节点构建连结,假若连结成功,将执行元组查询。否则,进入下个步骤。
6)假若连结失败,原因或许是节点失效,但此时共享数据表集群或许还是有效的。按照已获得的外模式描述文件里的Cluster ID,即集群标识符,进行数据表集群的查询。假若找到,即执行与阿奴查询。否则,退出运行程序。
4.2 多表查询时数据表的定位
所谓多表查询,指的是不止一个数据表,经一个及一个以上属性的连结而执行的查询。其中最为简洁的即2个数据表,经单个数据连结而做出的查询。举例:数据表M、N,经M,x和N,y属性执行查询,则为Select * Fromm,N Where M.x = N.y。
多表查询,顾名思义将牵涉多个数据表。所以应保证其中的数据表以及其数据均所属于同一数据库,才可以执行下一步的查询工作。需要注意的是,外模式描述文件通过数据表当做单位,向网络进行分布,而数据表所在集群即使确定,也不能保证多表查询一定能够顺利准确的运行。
所以,应就查询进行做出调整。运用上文阐述的方式核实第一个表属于哪个数据库。把查询指令传递至数据库所属的集群。再判别查询所涉的另外数据表有无在集群范围内。也就是通过数据表的名称为关键词,进行集群子网范围的查询。假若存在相应元数据的外模式描述文件,且所需属性均包含,就执行元组查询。如若不然,显示查询失败。
5 相关工作
就数据表定位以及语义异构相关研究,不同的学者也有相应的一些解决意见。
PeerDB[7]项目运用关键字进行属性名以及关系名标注的方式,体现异构数据源应语义映射。另外,就所有关键字均构建一定的物化视网。另外,PeerDB项目通过非结构化P2P网络为前提,相同数据库内的数据表,无法构成语义聚集。不能处理多表查询。另外,所有关键字均构建一定的物化视图,提升查询效率。另外也增添数据冗余,使得系统灵活性减弱。
Hyperion[8]项目将复杂的映射表达式、ECA[9]以及映射表有关规则控制节点相互信息转化进行定义,妥善处理了P2P范畴中有关的语义异构,上述任务应由专家在节点中在查询发起前,以及增添网络期间进行构建,所以系统运作成本颇高。
PIER[10]项目提出系统里的全部节点均适用于普用的标准全局模式,并未确定特定的算法进行节点间语义异构问题的处理。
6 结束语
由于其管理系统里的节点自治性问题使得数据模式出现了异构问题,P2P数据管理系统需要进行数据集合,给予用户一个统一的查询入口。
课题在所有数据源节点就共享的数据表的名称以及属性进行定义。而语义映射的媒介就是关键字。其中标的相同的关键字结合即构成共享数据的外模式。这种方式的处理将先前共享的数据,看起来就像是有着类似名字的数据。可是在节点内,斌给把外模式彻底物化成视图。却仅仅构建了内、外模式间互相对应的连结。
完成定义的关键字列表,执行外模式描述文件,向网络进行分散,而外模式描述文件在生成时,就涵括了数据表以及属性全部的别名,还把外模式描述文件根据数据表的别名向P2P网络进行分布。而在进行查询时,外模式描述文件寻求之后,即刻便把查询请求里的全部别名向真实数据表以及属性名进行转化,因此,不但可以便捷的根据任何名字寻求所需数据表,还能够降低数据备份数目,简化算法,提升运行效率。
[1] 余敏, 李战怀, 张龙波.P2P数据管理[J].软件学报, 2006,17(8): 1717-1730.
[2] 余敏, 李战怀, 张龙波.P2P数据管理研究趋势[J].计算机应用研究, 2006, 23(8): 4-7.
[3] 姚佳丽, 张坤龙, 王珊.基于P2P的数据索引与查询[J].计算机科学, 2005, 32(3): 69-72.
[4] Zhao Dan.Mylopoulos[J] An ECA Rule Rewriting Mechanism for Peer Data Management, 2006.
[5] 周婧, 王意洁, 李思昆.一种基于数据相关性的优化数据一致性维护方法[J].计算机学报, 2008, 315: 741-754.
[6] 凌波, 周水庚, 周傲英.P2P信息检索系统的查询结果排序与合并策略[J].计算机学报, 2007, 30(3): 405-414.
[7] Karger, Lehman Consistent hashing and random trees Distributed caching protocols for relieving hot spots on the World Wide Web 1997.
[8] Stoica t.Morris R Chord.A Scalable Peer-to-peer Lookup Protocol for Interne: Applications[J], 2003, (01).
[9] 蒋卓明, 周旭, 许榕生.基于ISP-Join的动态P2P流量优化模型[J].北京理工大学学报, 2010(1): 64-68.
[10] 汤天亮, 张晓龙, 陈珂, 等.一种高效的P2P环境中的窗口查询算法[J].计算机研究与发展, 2009, z(2).
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
党员生活(2020年2期)2020-04-17 09:56:30
铁道通信信号(2018年10期)2018-12-06 09:34:56
计算机与生活(2018年3期)2018-03-12 08:38:11
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
中国石油企业(2014年4期)2014-11-30 06:13:06
汽车零部件(2014年10期)2014-11-11 12:25:04
