
自适应时间阈值的RFID数据清洗算法
2012-07-04 09:42潘伟杰李少波许吉斌
制造业自动化 2012年13期
潘伟杰,李少波,2,许吉斌
(1.贵州大学 教育部现代制造技术重点实验室,贵阳 550003;2.中国科学院 成都计算机应用研究所,成都 6100413;3.贵州大学 计算机科学与信息学院,贵阳 550025)
0 引言
射频识别(Radio Frequency Identification, RFID)系统中,由于RFID阅读器本身数据的不可靠性以及无线传输信号受外界干扰等诸多因素,出现漏读、多读和脏数据的情况;同时,RFID系统中存在海量中间数据。为了减少以上情况的出现,提供高质量的RFID数据,对RFID原始数据进行处理显的尤为重要。
目前,RFID的数据清洗技术研究已经取得一定的进展。文献[1~3]通过将数据过滤算法嵌入到标签阅读器当中,解决漏读和脏数据。但由于阅读器本身的处理能力和存储单元的限制,这种处理方法能产生的效果还比较有限。文献[4~6]采用定长时间窗口清洗方法应用在中间件中,设定一个时间窗口,在窗口内若标签被读到则认为其存在于阅读区域内,虽然方法简单易行,但缺乏灵活性,不能很好地实现数据过滤。文献[7,8]采用一种基于事件驱动的滑动时间窗处理RFID数据,设定一个固定的时间阈值,当新的阅读到达时,根据时间戳和时间阈值,判断其过期时间,然而该方法缺乏灵活性,没有解决冗余读问题。文献[9~11]采用一种基于伪事件的数据清洗方法,将标签的冗余读当作伪事件,通过设定时间阈值的方式,来判断标签是否为伪事件,对伪事件数据进行丢弃。在一定程度上解决了冗余读的问题。文献[12]用阅读区域的大小和标签的运动速度估计出时间窗口长度,但是在实际应用中阅读器的阅读区域是一个范围估计值,存在着较大误差,而且该方法只能用于固定流速的标签信息处理,对于非匀速标签运动则无法实现数据过滤。文献[13]提出一种自适应调整滑动窗口大小的数据清洗方法(Statistical sMoothing for Unreliable RFid data,SMURF),把阅读器读取到的RFID数据流看做统计学中的随机事件抽象成样本统计和建模,并且灵活的根据当前得到的样本对窗口大小进行连续的动态调整。但是这种方法会对时间窗内的数据重复存储,消耗大量的系统内存,同时也可能造成多读和漏读数据,同样不能解决非匀速标签运动问题。
针对目前研究的不足,本文提出一种新的自适应时间窗的RFID数据清洗算法(Adaptive Time-thresholds for RFID Data Cleaning Algorithm,ATDCA)。将时间窗模型和伪事件过滤模型结合在一起,基于分层机制过滤数据,解决冗余读问题,减少系统缓存。
1 相关算法研究
1.1 自适应滑动窗口RFID数据清洗算法
SMURF算法中规定窗口大小为w,阅读器在大小为wi个时段中检测单标签i,在窗口的每个时段中,只有部分时段能读到标签i,窗口中每个阅读周期的平均阅读率定为piavg。
针对单标签清洗,利用伯努利二项分布模型来处理数据。为了保证阅读器读到数据的完整性,要求窗口的大小能保证存在于标签阅读区域内的所有标签都被读到的概率δ满足理,SMURF算法规定标签发生动态变化的条件为:签阅读出现的次数。
而对于多标签聚集清洗的情况,SMURF算法采用一种基于π-estimator分布模型的多标签阅读清洗问题解决方案,用以确定窗口的标签数量。通过窗口中标签至少出现一次的概率为:估计出窗口中间总的标签数量为:中sw表示窗口检测出的标签集合。假设不同标签之间相互具有独立性,则Nw'的方差可以表示为而标签发生动态变化的条件为:表示在当前窗口和当前1/2窗口内存在标签个数之和。针对这两个条件的响应具体操作与解决单个标签的情况类似。SMURF算法可以根据窗口数据自动调整窗口大小,当新阅读产生时,标签进入时间窗口,将每次读到的标签信息依次放入缓存队列当中,每个标签的信息,在一个时间窗口中只输出一次。从而改善窗口大小设置不合理而造成的漏读、冗余读等问题[13]。
1.2 基于伪事件的RFID数据清洗方法
伪事件是一种人为定义的事件,以特定时间触发特定动作。将冗余读设为伪事件,分别对各个伪事件设定阈值,判断标签信息的读入是否为伪事件。
针对冗余读伪事件,设定阈值δ1,当标签首次被发现,记该时刻为t,在时间区间[δ1,δ1+t]内,若标签被重复读取,则认为是重复读伪事件,不输出该标签信息。该方法解决了传统数据清洗方式会给系统带来大量中间数据的问题,减少了缓存的开销[10]。
由于每个标签在其存在周期内都可能被读到多次,SMURF算法在存储时间窗内每次阅读产生的标签信息需要消耗大量的缓存,同时在一个时间窗内的标签被读取次数随机性较大,如果仅仅通过设置阈值来达到清除多读数据和脏数据,可能会导致真实标签被误判为多读数据或者脏数据。而伪事件的RFID数据清洗方法设定的阈值是固定的,取值缺少灵活性。
2 自适应时间阈值的标签数据过滤
2.1 改进算法的思想
ATDCA结合时间窗模型和伪事件过滤模型,以伪事件过滤算法为基础,通过设定事件过期时间阈值,过滤阅读范围内的标签信息,触发事件过期阈值根据阅读范围内标签的存在状态自适应改变。
算法首先通过查询缓存队列中的标签信息,来判断新阅读产生的数据是否为冗余读数据,从而实现阅读范围内新标签的发现和信息输出。在实际应用中,大量已过期的标签信息占用大量的缓存空间,增加了查询消耗。因此要求缓存队列中的数据要实时更新。SMURF算法可以得到当前时刻时间窗的长度,其长度根据读卡器阅读区域内的标签数目变化而自适应的变化,可以动态的反应当前时刻阅读区域内的标签存在状态,所以选择自适应时间窗的大小作为缓存队列中标签信息过期的阈值。利用标签时间戳和阈值实现标签过期的判断。
阅读器在实际读取标签信息时,会出现多读数据和脏数据,这些信息在以时间窗作为阈值的数据过滤算法中很难有效地与真实存在的标签信息进行区分。但是在单缓存队列的方法中,由于标签信息的过期时间是整个存在周期,而同一个信息多次发生多读或误读的概率极低。因此对多读数据和脏数据设置一个时间阈值来判断标签信息的真实性。
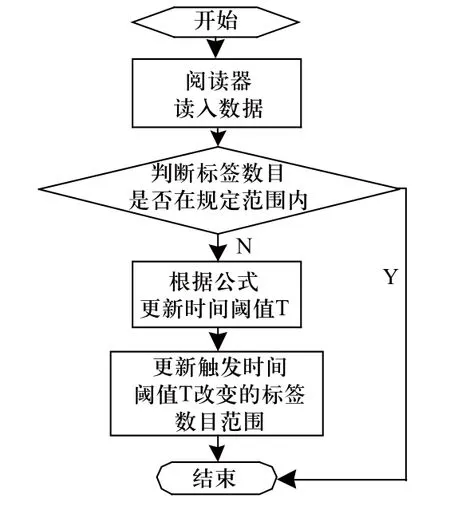
图1 单缓存队列中数据过滤
当新的阅读产生,查询此时缓存队列中的标签数目,若标签数目在阈值有效范围内,则不更新时间阈值。若标签的数目不在范围内,则触发时间阈值更新,更新完成后,通过算并更新阈值。
2.2 改进方法软件实现
定义标签缓存队列的单元格式:∪t={[UIDt][][Nt]},其中UID为标签ID,Tend为标签预计过期时间, N为标签被读到的次数,i表示标签的序号。
标签在整个存在周期内,被阅读器多次重复发现。当一个新的阅读发生时,系统查询缓存队列,判断它是否已存在缓存队列当中,若已经存在,则根据此时的时间t和时间阈值长度T,求出标签的预计过期时间Tend= t+T,更新该标签的相关信息,并且将标签信息放入队列末尾;若不存在,则将标签的相关信息直接插入缓存队列末尾,同时顺序查询缓存队列,若当前时间大于或者等于某个标签的预计过期时间则认为该标签已经过期,从缓存队列中删除该标签。具体实现流程如图2所示。
步骤1:读写器进行新的阅读,得到标签UID。
步骤2:系统缓存队列中的标签数目是否在阈值有效范围内。若在有效范围内,转至步骤4执行,若不在有效范围内转至步骤3执行。

图2 算法流程图
步骤4:根据标签被读取时刻的时间t和此时的时间阈值T计算出标签信息的预计过期时间Tend= t+T。
步骤5:将标签中记录的UID与缓存队列中的标签信息进行对比,判断标签信息是否已经存在于缓存队列当中。若已存在则转至步骤6执行,若不存在则转至步骤7执行。
步骤6:将标签被读到的次数Nt加1,更新标签的预计过期时间等相关信息,并且将该标签信息移至缓存队列末尾,转至步骤8执行。
步骤7:将标签被读到次数记为Nt 加1,并将该标签的相关信息插入到缓存队列末尾,转至步骤9。
步骤8:判断标签被读到的次数,若次数大于μ,认为该标签信息为真实信息,将其输出给上层模块并且对其进行标记,转至步骤9。
步骤9:更新缓存队列,统计缓存队列长度L并初始化计数值k=1,用以表示缓存队列的第一个标签信息,转至步骤10。
步骤10:将缓存队列中第一个标签的预计过期时间与当前时间相比对,若当前时间已经超出或者等于标签的预计过期时间,则认为标签信息已经过期,将其从缓存队列中删除,转至步骤9。若没有,则转至步骤11。
步骤11:判断读操作是否停止,若停止,则结束数据清洗,若没有停止,转至步骤1继续执行清洗操作。
2.3 改进方法的硬件实现
改进方法的清洗过滤器主要由计算器、时钟、比较器和缓存队列组成,清洗机制如图3所示。
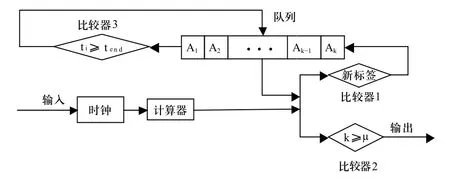
图3 清洗过滤器结构图
其中时钟用于获取当前时间t,计算器用于计算此刻时间窗长度T,并且得出标签预计过期时间。比较器1用于判断标签是否已经在缓存队列当中,从而实现对缓存队列的添加。比较器2用于判断标签是否是真实数据,过滤多读数据和脏数据。比较器3用于判断标签是否过期,从而删除队列中的冗余信息。
3 仿真结果及分析
标签信息由Matlab随机产生,取标签的置信区间δ≤0.01,保证标签被读到的概率大于1-δ≥0.99,每个阅读周期中,标签任意标签被读大小w为满足条件的最小整数值,μ=2。在试验中,考虑到标签的两种通过场景,分别是快通过场景和慢通过场景,这两个场景的区别是每个时间窗长度之内,标签的变化率的大小,在快通过场景,标签的变化率可能达到 60%~70%,取θ =70%,在慢通过场景标签的变化率可能只有5%~10%,取θ =10%。
由图4可以看出,相比较SMURF算法,随着读写器阅读区域中标签的数量的增大,传统数据清洗方法所占用的缓存空间与改进方法相比差距成倍增长,从而可以看出改进方法能有效地减少缓存空间的占用率。到的平均概率
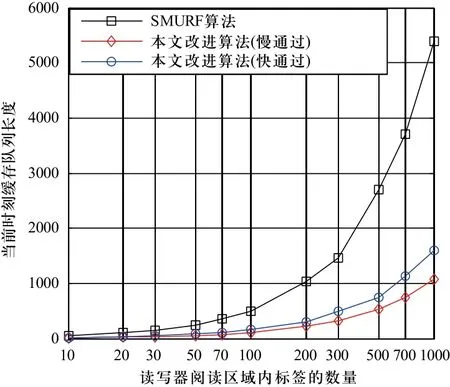
图4 与SMURF算法比较
而对于伪事件标签清洗方法,其发出的标签信息量由时间窗值T与时间阈值T '之比还有标签的变化率θ有关,
由图5可得,在时间阈值T '选取的不是很恰当时,当标签慢速通过,伪事件标签清洗方法会带来大量的冗余数据输出,会严重的影响系统的性能;当标签快速通过时,它依然还会有一定的冗余数据输出。而两种改进方法都基本不会带来冗余数据的输出。

图5 与伪事件标签清洗比较
4 结束语
本文针对RFID系统中的冗余读事件和缓存清理进行了探讨,深入研究了现有RFID数据清洗技术。提出了以自适应时间窗长度作为阈值来触发标签输出和过期的改进数据清洗方法。实验结果表明,改进后的算法在保证数据的准确性、实时性和精简性。相对SMURF算法,该算法大大降低了缓存队列的长度;相对伪事件过滤算法,其时间阈值自适应调整,灵活性增强,进一步解决了时间阈值选取不当造成的冗余数据输出问题。而且相比起以往的数据清洗方法,其对于多读数据和脏数据有更好的过滤效果,算法的硬件实现简单,显著提高了RFID原始数据的清洗效率。
[1] 姜兆宁, 丁香乾, 李谦.生产线嵌入式RFID终端读写器设计[J].微计算机信息, 2007, 23(8): 221, 225, 226.
[2] 丁帅, 杨善林.基于.NET精简框架的嵌入式RFID服务组件[J].计算机工程, 2008, 34(17): 50-52, 55.
[3] Rasmus Jacobsen, Karsten Fyhn Nielsen, Petar Popovski,Torben Larsen.Reliable Identification of RFID Tags Using Multiple Independent Reader Sessions[C].Orlando, FL, USA:Presented at IEEE RFID 2009 Conference, 2009: 64-71.
[4] Graham Cormode, Vladislav Shkapenyuk, Divesh Srivastava, Bojian Xu.Forward decay: A practical time decay model for streaming systems[C].Washington DC,USA: ICDE '09 Proceedings of the 2009 IEEE International Conference on Data Engineering, 2009: 138-149.
[5] Shawn R.Jeffery, Gustavo Alonso, Michael J.Franklin, Wei Hong, Jennifer Widom.Declarative Support for Sensor Data Cleaning[C].Dublin, Ireland: PERVASIVE'06, 2006: 83-100.
[6] Shawn R.Jeffery, Gustavo Alonso, Michael J.Franklin1,Wei Hong, Jennifer Widom.A Pipelined Framework for Online Cleaning of Sensor Data Streams[C].Atlanta, USA:the 22nd International Conference on Data Engineering,2006: 140-142.
[7] Harald Vogt.Efficient Object Identification with Passive RFID Tags[J].Lecture Notes in Computer Science, 2002,2414: 98-113.
[8] 陈金花, 刘国辉, 吴军, 周鑫.数据过滤在RFID系统中的应用[J].光通信研究.2009, (4): 41-43.
[9] Yijian Bai, Fusheng Wang, Peiya Liu.Efficiently Filtering RFID Data Streams[C].Seoul, Korea:the First Int'l VLDB Workshop on Clean Databases, 2006: 50-57.
[10] 王妍, 石鑫, 宋宝燕.基于伪事件的RFID数据清洗方法[J].计算机研究与发展, 2009, 46 (z2): 270-274.
[11] 谷峪, 李晓静, 吕雁飞, 于戈.基于RFID应用的综合性数据清洗策略[J].东北大学学报(自然科学版), 2009, 30(1):34-37.
[12] 王文闯, 凤宇.基于动态时间窗的射频识别中间件数据过滤算法[J].信息与电子工程, 2009, 7(3): 177-179, 183.
[13] Shawn R.Jeffery, Minos Garofalakis, Michael J.Franklin.Adaptive Cleaning for RFID Data Streams[C].Seoul,Korea: VLDB, 2006: 163-174.
猜你喜欢
临床骨科杂志(2020年1期)2020-12-12
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
制造技术与机床(2019年9期)2019-09-10
军营文化天地(2018年2期)2018-12-15
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
探测与控制学报(2015年4期)2015-12-15
Coco薇(2015年11期)2015-11-09
