
一种新型RFID动态多叉树查询防碰撞算法
2012-07-04 09:43陆冰清牛国柱赵英臣
制造业自动化 2012年15期
陆冰清,牛国柱,赵英臣
(1.南京理工大学 机械工程学院,南京 210094;2.山东齐银水泥有限公司,淄博 255400)
0 引言
随着信息技术的发展,射频识别(Radio Frequency Identif i cation)技术被广泛地应用于生产管理和工业制造自动化等领域。RFID技术利用射频信号通过空间耦合(交变磁场或电磁场)实现非接触信息传递并达到识别目的。RFID系统一般包含射频标签(Tag)、读写器(Read/Write Device)和数据管理系统三部分。其中,每个标签都含有唯一的识别码;读写器与计算机系统进行通信,从而对标签进行非接触读写操作。
RFID系统在工作时,可能会有多个标签同时处在阅读器的作用范围内。这样如果有两个或两个以上的应答器同时发送数据,就会出现通信冲突,即碰撞。解决信道冲突的方法有四种:空分多址(Space Division Multiple Access,SDMA)、频分多址(Frequency Division Multiple Access,FDMA)、码分多址(Code Division Multiple Access,CDMA)和 时 分 多 址(Time Division Multiple Access,TDMA)。在RFID系统中,一般采用时分多址法来解决碰撞。TDMA是一种把整个可供使用的通路容量按时间分配给多个用户的技术。
常用的基于TDMA思想的防碰撞算法主要分为两大类:1)基于时隙随机分配的ALOHA算法,包括时隙ALOHA算法和分群时隙ALOHA算法等。2)基于二进制树型搜索算法,包括动态二进制搜索算法和查询树搜索算法等。
由于ALOHA算法吞吐量低,识别速度缓慢,还可能出现标签在相当长得一段时间内无法识别,该算法不适宜大规模标签读取。而树型的标签防碰撞协议可以达到百分之百的读取率,本文对查询树搜索算法在标签数量较多识别效率较低的问题进行研究,提出一种新的动态多叉树查询算法,有效地提高了RFID系统的识别效率。
1 改进的动态多叉树查询算法
查询树算法的基本思想是将碰撞的标签分成两个子集0和1,先查询子集0,如果没有碰撞,则正确识别标签,如果碰撞则再分裂,把子集分成00和01两个子集,以此类推,直至识别出子集0中的所以标签,再按步骤查询子集1。
1.1 算法设计思路
动态二叉树查询算法就是基于上述分解原理的防碰撞算法,它在此基础上采用曼彻斯特编码,这种编码采用半个周期的正负跳变来表示0和1,在数据传输过程中“没有变化”的状态是不允许的。因此,当阅读器收到标签的返回信号后,如果发现某些位信号的状态没有发生改变,那么阅读器就能够判断这些位一定发生了相互之间的冲突,如图1所示。

图1 曼彻斯特编码
利用碰撞位信息,没有发生碰撞的比特位直接跳过,检测下一比特位,这样可以提高搜索效率,避免出现空闲时隙。但是动态二叉树算法在每次碰撞时仅分成两支,当待识别标签数量较多时,在搜索的初期会频繁出现碰撞,搜索效率偏低。如图2所示,RFID系统内有8个4bit的待识别标签,标签ID分别为:Tag1:1100 Tag2:0111 Tag3:0101 Tag4:1110 Tag5:1101 Tag6:0100 Tag7:1111 Tag8:0110。查询过程中定义三种时隙。
1)可读时隙:只有一个标签应答,阅读器正确识别;
2)碰撞时隙:多个标签应答导致碰撞;
3)空闲时隙:没有符合查询条件的标签,无应答。

图2 动态二叉树查询算法
由图2可以看出,完成整个标签的搜索共需14个时隙,其中6个是碰撞时隙,搜索深度有3层。
动态四叉树查询算法为了避免频频发生碰撞,在检测到碰撞时将响应的标签分为四个分支依次查询,仍以上述8个标签为例,搜索流程如图3所示。

图3 动态四叉树查询算法
由图3可以看出,动态四叉树算法只有2个碰撞时隙,但多了2个空闲时隙,而且当标签数量较少时会产生很多空闲时隙,效率未必比二叉树更好。在上述RFID系统中,标签的第一比特位碰撞,第二比特位没有碰撞,根据曼彻斯特码的编码特性,可以直接确定第二比特位,采用二叉树;标签的第三和第四比特位都发生碰撞,则采用四叉树。如图4所示。

图4 动态多叉树查询算法
由图4可以看出,采用多叉树查询算法只有2个碰撞时隙,没有产生空闲时隙,总时隙也小于前面两种算法,效率更高。
1.2 算法原理及流程
上述例子说明如果防碰撞算法能根据某种准则自动选择搜索叉树时可以提高搜索效率。这种情况下可以充分利用碰撞位信息,规定当检测到某比特位发生碰撞时,再检测下一位是否发生碰撞,如果没有碰撞,则采用动态二叉树;如果碰撞则采用动态四叉树。新的算法根据碰撞比特位的分布选择分叉树,所以称为动态多叉树查询算法。
该算法的搜索流程图如图5所示,分为以下四个步骤。
步骤1:读写器初始化查询数组,使之为空数组,并发出搜索命令。
步骤2:符合查询条件的标签响应,读写器根据标签响应确定时隙状态。
步骤3:根据碰撞比特位的分布(相邻两位都碰撞,采用四叉树,否则采用二叉树,没有发生碰撞的比特位跳过),动态地选择搜索叉数,并将新的查询码写入查询数组。
步骤4:判断搜索深度是否达到最大值,如果不是,返回步骤2继续搜索。否则,算法结束。
1.3 算法分析
一般来说,RFID系统中标签的数量越多,出现碰撞的位数越多,相邻两位都发生的概率越大,可见选择四叉树还是二叉树与分支内标签个数紧密相关。下面从概率论的角度分析本文提出的算法。
假设RFID系统当前分支内有N个符合查询条件的待识别标签,任意比特位不发生碰撞的概
则当前分支采用二叉树的概率为:

图5 动态多叉树查询算法搜索流程图
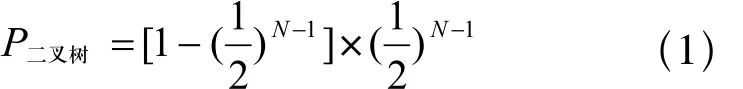
采用四叉树的概率为:

由式(1)、式(2)可以看出分支内标签个数越少,采用二叉树的概率较大,即碰撞的位数越少,相邻位碰撞的概率也越小;反之采用四叉树的概率较大。
2 算法仿真与分析
通过Matlab对上述算法进行仿真分析(标签ID为32bit),仿真结果在同等条件下取20组数据求均值。仿真结果如图6和图7所示。其中定义吞吐率为:


图6 三种算法碰撞时隙和空闲时隙对比
图6和图7分别为动态多叉树,二叉树和四叉树三种算法所需碰撞时隙、空闲时隙和吞吐率的比较。从图中可以观察出,单纯的二叉树搜索算法碰撞时隙较多;单纯的四叉树搜索算法空闲时隙较多;动态多叉树搜索算法改进了这两种算法的缺点,使吞吐率提高15%左右,从而提高了搜索效率,减少搜索时间。
3 结束语

图7 三种算法吞吐率对比
本文基于传统的查询树防碰撞算法,提出了一种动态多叉树查询算法。新算法改进了单纯动态二叉树和四叉树查询算法的缺点,通过对三种算法的仿真分析,表明本文提出的算法减少了搜索过程的总时隙,有效的提高了搜索效率和时隙的吞吐率,可以显著提高工业生产和物流管理的工作效率。
本文创新点:本文提出的算法充分利用曼彻斯特编码可以识别碰撞位的特性,通过碰撞位的分布情况,检测相邻两位的碰撞情况,动态的调整搜索叉树,从而更好的解决了射频识别系统中标签应答冲突问题。
[1] Finkenzeller K著, 陈大才译.射频识别(RFID)技术[M].北京: 电子工业出版社, 2006.
[2] 王雪, 钱志鸿, 胡正超等.基于二叉树的RFID防碰撞算法的研究[J].通信学报, 2010, 31(6): 50-57.
[3] WANG T P.Enhanced binary search with cut-through operation for anti-collision in RFID systems[J].IEEE Communications Letters, 2006, 10(4): 236-238.
[4] Jihoon Myung, Wonjun Lee, Srivastava J.Adaptive binary splitting for efficient RFID tag anti-collision[J].IEEE Communications Letters, 2006, 10(3): 144-146.
[5] 刘路, 陈洪云, 何怡刚.一种新型RFID联合防碰撞算法[J].微计算机信息, 2010, 26(10): 145-146.
[6] 丁治国.RFID关键技术研究与实现[D].合肥: 中国科学技术大学, 2009.
猜你喜欢
电子制作(2022年16期)2022-09-23
舰船电子工程(2022年7期)2022-09-06
现代电力(2022年2期)2022-05-23
现代计算机(2021年14期)2021-07-09
军民两用技术与产品(2021年2期)2021-04-13
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
计算机与数字工程(2020年8期)2020-10-14
小读者之友(2019年9期)2019-09-10
东坡赤壁诗词(2018年6期)2018-12-22
意林·少年版(2018年1期)2018-02-07
