
基于遗传规划集成学习的网络作弊检测
2012-06-29 07:03牛小飞马少平张冬梅
中文信息学报 2012年5期
牛小飞,马 军,马少平,张冬梅,2
(1.山东大学 计算机科学与技术学院,山东 济南 250101; 2. 山东建筑大学 计算机科学与技术学院,山东 济南 250101;3. 清华大学 计算机科学与技术系,北京 100084)
1 引言
目前,搜索引擎已成为人们日常生活中的重要工具。对于一个确定的查询,搜索引擎通常能返回成千上万个网页,但是大部分用户只读前几个,所以在搜索引擎中网页排名非常重要。所有试图不合逻辑地增加网页排序的欺诈行为被称为“网络作弊”(Web Spam)[1],它们严重降低了搜索引擎检索结果的质量,检测网络作弊已成为搜索引擎的重要挑战之一。
网络作弊被广泛地分为内容作弊和链接作弊。内容作弊是指为了使作弊网页和某些查询相关而故意改变网页中的内容。链接作弊是指通过操作链接结构图来混淆超链接结构分析算法,从而提高某些网页的重要性,使其在搜索引擎中的排名靠前。Ntoulas等提出通过内容分析得到内容特征,然后使用这些特征构造分类模型来检测内容作弊[2]。Gyongyi 等提出 TrustRank算法从作弊网页中分离出正常网页[3]。 L. Becchetti 等提出Truncated-PageRank,在网络链接结构图上得到网页链接属性,然后利用它们构造分类器来识别链接作弊[1]. Becchetti 等为建立网络作弊识别分类器研究了度之间的相关性、TrustRank等链接特征[4]。Castillo等使用PageRank、TrustRank和Truncated-Page-Rank 等抽取出转换后的链接特征,并同时使用内容和链接特征来检测网络作弊[5]。Na Dai 等提出利用从网页历史版本中获取的内容特征来提高作弊分类[6]。Yiqun Liu等提出利用用户行为特征从普通网页中分离出作弊网页[7]。
从以上文献中可以看出,分类是识别网络作弊的有效技术。目前基于分类的识别方法重点是如何得到更好的特征或使用更好的分类方法来提高分类性能,但是大都忽略了数据集中作弊样本和正常样本的不平衡性,即正常样本比作弊样本多得多,这将影响网络作弊识别的性能。欠抽样[8]是从数据层面上解决不平衡数据集分类问题的有效方法之一,如何抽取比较多的正常样本而又不丢失正常样本的信息是一个重要的问题;集成学习是从算法层面上解决不平衡数据集分类问题的有效方法之一,它可以将多个分类器的结果组合起来得到更准确的分类器。对于集成学习来说,如何产生差异较大的个体分类器或基分类器和如何将多个分类器的结果进行组合是两个非常重要的问题。
针对上述问题,本文提出基于遗传规划(Genetic Programming, GP)[9]的集成学习方法(Genetic Programming-based ENsemble Learning, GPENL)来检测网络作弊,研究了抽取训练集的方法,基分类器的创建和分类结果的表示,使用遗传规划进行集成的过程及有关遗传规划的设置。其主要贡献是将欠抽样技术和集成学习融合起来提高非平衡数据集分类的性能,在集成时利用遗传规划思想对多个基分类器的分类结果进行组合,学习得到优化的组合方案来提高网络作弊的识别性能。
为了验证GPENL算法的有效性,作者使用WEBSPAM-UK2006数据集进行了实验,实验结果表明无论是同态集成还是异态集成,GPENL均能提高分类的性能,且异态集成比同态集成更加有效;GPENL比AdaBoost、Bagging、RandomForest、多数投票集成、集成异种分类器的EDKC算法[10]和基于Prediction Spamicity的方法[11]取得更高的F-度量值。
2 相关知识
在非平衡数据集中,样本较多的一类被称为多数类,而只有少数样本的一类被称为少数类或稀有类。因为样本的不平衡性,如果使用传统的分类方法对其进行分类,则分类器会倾向于把一个样本预测为多数类样本,这样会导致少数类样本的识别率较低。改变样本的分布和设计新的分类算法是两类有效的方法。前者主要有过抽样和欠抽样两种。过抽样方法是通过增加少数类样本来增加少数类的分类性能,欠抽样方法是通过减少多数类样本来提高少数类的分类性能。集成学习是解决不平衡数据集分类问题的有效算法。
集成学习的基本思想是先训练多个基分类器,在对新的实例进行分类的时候,通过对多个基分类器分类结果进行某种组合来决定最终的分类,以取得比单个基分类器更好的性能,提高学习系统的泛化能力。按照基分类器之间的种类关系可以把集成学习方法划分为同态集成和异态集成。同态集成是指集成的基分类器都是使用同一种分类算法所得的分类器,只是它们之间的参数有所不同,例如,Bagging和Boosting算法;异态集成指的是对使用不同分类算法所得的基分类器进行集成,如EDKC算法。至于多个基分类器分类结果的组合,最常用的方法是多数投票和基于权重的组合,文献[10]以基分类器在训练数据集上对稀有类分类的F-measure度量值乘以一个系数进行组合;文献[12]指出利用遗传算法从已有的基分类器中进行选择后再集成。到目前为止,没有人说自己所得的组合方式是最好的,因为谁也不知道这个问题最好的解决方案是什么,它可以被看作是一个优化问题,考虑到遗传规划是一个强大的优化工具,本文提出使用遗传规划找到更好的组合方式。
在遗传规划中,一个个体I表示一个问题的一种解决方法,所有个体构成了一个群体P={I1,I2,…,I|P|}。 其基本过程是,首先随机产生一些个体形成一个群体,使用适应度函数为群体中的每一个个体赋予一个适应值,用来评价每一个个体的性能。然后这些个体通过遗传操作(繁殖、交叉和变异)一代一代地进化,直到给定的终止条件满足或达到特定的代数,最终能产生一个有更好适应值的个体作为这个群体的最优解。
3 基于遗传规划的集成学习检测网络作弊的算法
3.1 GPENL算法的基本处理过程
GPENL算法的基本处理过程: 首先通过欠抽样从原训练集中抽样得到t个不同的训练集;然后使用c个不同的分类算法对t个训练集进行训练得到t*c个基分类器;接下来利用遗传规划学习得到t*c个基分类器的集成方式。最后再根据多个基分类器对测试样本的分类结果和GP所得的组合方式来判断一个测试样本是否是作弊样本。
使用遗传规划得到优化集成方式的过程: 首先根据原训练集采用欠抽样方法抽样得到一个用于GP学习的新训练集T′ ;然后使用m个基分类器分别对T′ 和校正集V进行分类,得到T′ 和V的m个分类结果GT和GV;初始化一个群体,计算其中每个个体(基分类器集成方式)的适应值,不断执行遗传操作得到更好的个体,当一代执行完时保存本代中最适合GT的个体,当G代执行完后,对于所保存的G个个体,计算在GT和GV中的适应值之和,其值最大的个体作为GP优化后的集成方式。
3.2 基分类器的构建及结果的表示
假设N为训练集T中的正常(Normal)样本集,S为T中的作弊(Spam)样本集,如果|N|/|S|的值越大,则不平衡的程度就越大。欠采样技术是随机从N中抽取子集N′(|N′|<|N|)与S组成一个新的训练集训练得到分类器。这样新的训练集中正常样本和作弊样本会相对平衡,训练得到的分类器比直接使用原不平衡训练集得到的分类器更有效。然而,N∩N′ 集合中样本的有用信息就被忽略了。GPENL算法将N分成几个互不相交的子集N1,N2,…,Nt,即Ni⊂N(|Ni|= |S|,1≤i≤t,t=|N|/ |S|),且Ni∩Nj=∅(1≤i≤t,1≤j≤t,i≠j),如果N-(N1∪N2∪…∪Nt)≠∅,则再从N中随机抽取|S|-|N-(N1∪N2∪…∪Nt)|个样本与N-(N1∪N2∪…∪Nt)组成Nt+1,此时t=t+1;然后让新的训练集Ti=S∪Ni(1≤i≤t);最后分别使用所选的c个分类算法训练得到t*c个基分类器。这样既能充分利用N中所有正常样本的信息,又能产生差异较大的基分类器。基分类器对样本的分类结果用1或-1来表示,如果一个样本被分为Spam,则结果为1(表示正例),否则为-1(表示负例)。
3.3 遗传规划的相关设置
本文中,一个个体被定义为表示组合多个基分类器结果的一个函数表达式,例如,F2*0.8+F8-F1,其中Fi表示第i个分类器的结果,从这个表达式中,我们可以看出,一个个体包含运算数和运算符,运算数是常数或基分类器对样本的分类结果,我们所用的运算符是加法(+)、减法(-)和乘法(*),因为它们都是二元运算符,所以我们用二叉树结构表示一个个体。这样一个个体的输出结果会是一个实数,对于一个给定的样本x和一个个体I,如果I(x)>0,则我们认为I将x识别为Spam,否则为Normal。根据对个体的定义,我们不难看出: (1) 当运算数只是基分类器对样本的分类结果,运算符只用加法时,个体所表示的函数表达式即为多数投票集成;(2) 当运算数用常数和基分类器对样本的分类结果,运算符用加法和乘法,且只能常数和基分类器对样本的分类结果进行相乘,m个相乘结果进行相加时,个体所表示的函数表达式即为基于权重的集成。因此,多数投票集成和基于权重的集成都是遗传规划中个体所表示的函数表达式的特例,那么利用遗传规划应该能进化得到比多数投票集成和基于权重的集成更好的集成方式。
适应度函数用于评价个体的性能,对于相对平衡的数据集,精确度经常被用作适应度函数。而对于非平衡数据集来说精确度就不再合适了,例如,在一个非平衡数据集中,多数类样本占95%,少数类样本只有5%,一个个体把所有样本都分成多数类时,精确度也能达到95%,但是一个少数类样本都没识别出来,显然这样是没意义的。我们使用F-度量作为适应度函数,因此,定义个体I在数据集D上的适应度函数F(I,D)=F-measure(I,D)。
我们所使用的遗传操作是繁殖、交叉和变异。繁殖操作是把选择出的好的个体直接放到下一代;交叉操作从随机选出的两个个体中分别随机选择一棵子树,然后交换它们,从而产生两个新的个体,对比原来选出的两个个体和新产生的两个个体的适应值,选出最好的两个放到下一代;变异操作是使用随机产生的一棵新树替换被选出的一个个体的子树,从而产生一个新的个体,然后比较原来的个体和新产生的个体的适应值,将好的那个放到下一代。交叉和变异操作根据交叉和变异率(Rc和Rm)执行,Rm太大或太小都不合适,类似于文献[13],Rm和Rc被初始化为0.05和0.95,在第g代,根据式(1)调整Rm和Rc的值。
(1)

3.4 算法描述
算法1: 基于遗传规划的集成学习检测网络作弊的GPENL算法
输入: 训练集T、校正集V、测试集P
群体的个数PN
输出: 测试结果
(1) 取出T中的正常样本集N和作弊样本集S;
(2) 将N分成几个互不相交的子集N1,N2,…,Nt,即Ni⊂N(|Ni|= |S|,1≤i≤t,t=|N|/ |S|),且Ni∩Nj=∅(1≤i≤t,1≤j≤t,i≠j),如果N-(N1∪N2∪…∪Nt)≠∅,则再从N中随机抽取|S|-|N-(N1∪N2∪…∪Nt)|个样本与N-(N1∪N2∪…∪Nt)组成Nt+1,t=t+1;令Ti=S∪Ni(1≤i≤t);然后从N中随机抽取|S|个样本组成N′,令T′=S∪N′;
(3) 对Ti(1≤i≤t)分别使用c个不同的分类算法进行训练,得到t*c个基分类器;
(4) 使用t*c个基分类器对T′进行分类,并将t*c个结果存为GT;
使用t*c个基分类器对V进行分类,并将t*c个结果存为GV;
使用t*c个基分类器对P进行分类,并将t*c个结果存为GP;
(5)i=1; 定义一个空的群体R′;
(6) 使用GT和GV作为训练集和校正集调用算法2,将返回的个体放入R′;
(7)i=i+1; 如果i≤PN,则继续执行(6);
(8) 使用R′中的每一个个体为GT中的每一个样本计算,将结果存为GT′;
使用R′中的每一个个体为GV中的每一个样本计算,将结果存为GV′;
使用R′中的每一个个体为GP中的每一个样本计算,将结果存为GP′;
(9) 使用GT′和GV′作为训练集和校正集调用算法2,返回个体BI;
(10) 利用BI为GP′中的每一个样本计算,如果其值大于0,则输出结果1,否则输出结果为-1;
算法2: 使用遗传规划寻找更优组合方式的算法
输入: 训练集GT、校正集GV,表示个体的二叉树的深度K、执行的代数G、个体数N
输出: 本次寻找过程最优的组合方式
(1) 根据K的值随机产生N个表示组合多个分类器的个体初始化群体P;让g=0,Rm=0.05,Rc=0.95; 定义空的群体P′和Q′。
(2) 对于每个个体I∈P,计算F(I,GT);
(3) 执行繁殖操作,将max{F(I,GT)|I∈P}对应的个体直接放入P′;
(4) 计算P中所有个体适应值的平均值,然后根据公式1调整Rm和Rc;
(5) 根据Rm和Rc选择交叉或变异操作;
(6) 如果|P′|=N-1或选择的是变异操作,则执行变异操作,将被选出的个体和变异后的个体中较好的那个放入P′;
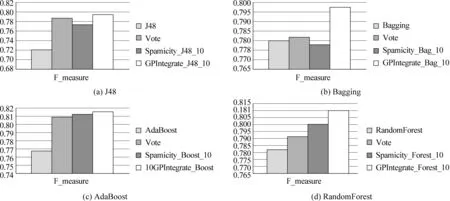
(7) 如果选择的是交叉操作,并且|P′| (8) 如果|P′| (9) 将P′中max{F(I,GT)|I∈P}对应的个体放入Q′,让P=P′,P′=Φ,g=g+1。 (10) 如果g (11) 对于Q′中的每一个个体I,计算F(I,GT)+F(I,GV),然后输出max{F(I,GT)+F(I,GV)|I∈Q′}对应的个体为本次执行过程所找到的最优组合方式。 本文中利用遗传规划集成多个基分类器结果时使用了PN个群体,将每一个群体得到的集成方式进一步集成来得到更好的集成方式。算法1中的第(1)~(3)步完成了基分类器的构建,并抽取了不同于构建基分类器时所用的t个训练集的一个新的集合T′,用于遗传规划学习时的新训练集;第(4)步完成利用各基分类器分别对新的训练集T′、校正集V、测试集P分类;第(5)~(9)步总体完成使用遗传规划学习得到多个基分类器进行集成的更好方式;其中第(5)~(7)步学习得到PN个集成方式,第(8)~(9)步将这PN个集成方式进一步组合得到更好的结果;第(10)步将使用GP学习得到的集成方式用于测试样本,并输出测试结果。 算法2中的第(1)步是初始化操作;第(2)~(9)步是一代的执行过程,其中第(3)步是繁殖操作,第(6)步是变异操作,第(7)步是交叉操作,第(9)步将当前这一代中最好的个体保存在Q′中;第(11)步用训练集和校正集同时来评价每一代中保存下的最好个体,并输出这两个集合上适应值之和最大的个体作为本次执行GP所找到的最优组合方式。 我们实验所用的数据集是WEBSPAM-UK2006,它包含了11 402台主机中的7.79 亿个网页,我们使用了既有内容特征又有转换后的链接特征的4 411个Normal样本和1 803个Spam样本。每一个样本有96个内容特征和138个转化后的链接特征,所以每一个样本被表示成包含234个特征和一个类别标签的235维的向量。 针对不平衡数据集,目前常用的分类性能评价标准有:F_measure、G-mean、WeightedAccuracy(WA)[10],它们分别被定义如下: 其中,TP表示被正确分类的正例(Spam as Positive)样本数;TN表示被正确分类的负例(Normal as Negative)样本数;FP表示被错分为正例的负例样本数;FN表示被错分为负例的正例样本数;r=(TN+FP)/(TP+FN),即r为负例样本数与正例样本数之比。 4.3.1 GPENL算法集成异态分类器的性能 为了验证GPENL算法在异态集成时的有效性,我们取了2 000个Normal样本和500个Spam样本作为训练集,1 000个Normal样本和250个Spam作为校正集,1 000个Normal样本和250个Spam样本作为验证集进行了实验。实验过程中,将训练集中的Normal样本等分为四份,每份和500个Spam样本组成一个训练集,这样将原来的训练集分成四个训练集,然后分别使用Bagging、AdaBoost、RandomForest分类算法进行训练共得到12个分类器,Bagging使用的基分类算法是J48(即决策树分类算法C4.5),AdaBoost使用的基分类器是DecisionStump。在使用GP集成各分类器时,首先设置PN=3,第一个群体有70个个体,繁殖60代,第二个群体有80个个体,繁殖80代,第三个群体有80个个体,繁殖60代,二叉树深度都设为4;将这三个群体训练得到的集成方式进一步组合时,设置只有一个群体,有80个个体,繁殖60代,二叉树深度为3。由于遗传规划执行过程的随机性,我们将相同条件下执行五次的平均值作为其结果。表1给出了各方法的结果。 表1中的前三行是对于给定的训练集和测试集直接使用AdaBoost、Bagging和RandomForest的测试结果,第四行利用EDKC基于权重进行集成的结果,第五行是多数投票的集成结果,第六行是利用Prediction Spamicity方法集成的结果,第七行是使用GPENL进行集成的结果。从表1中我们不难看出,将AdaBoost、Bagging 和RandomForest的结果集成起来都一定程度上提高了分类性能,与AdaBoost、Bagging和RandomForest中性能最好的RandomForest相比,GPENL方法的F_measure高出近4.2%,WA高出5.55%,G-mean高出5.92%。将12个分类器的结果按照Prediction Spamicity方法和GPENL方法进行集成所得的F_measure、G-mean、WA都比EDKC要好,与多数投票相比,这两个方法所得的WA和G-mean略低一点,但F_measure都要好;与EDKC算法相比,GPENL方法的F_measure高出1.84%,WA高出2.95%,G-mean高出2.97%;与Prediction Spamicity方法相比,GPENL方法的WA和G-mean差不多,但F_measure要高出1.29%,主要原因是使用遗传规划进行集成时我们以F_measure为适应函数。 表1 不同集成方式的分类性能比较 4.3.2 GPENL算法集成同态分类器的性能 为了验证GPENL算法在同态集成时的有效性,我们使用了与4.3.1节中相同的训练集、校正集和测试集,从原训练集中抽取得到10个训练集,前四个的Normal样本互不交叉,后六个的Normal样本从原训练集中的Normal样本中随机抽取。然后选择一种分类算法(J48、Bagging、AdaBoost或RandomForest)对这10个训练集训练得到10个分类器,最后再分别使用多数投票(Vote)、Prediction Spamicity方法和GPENL算法进行集成。图1中(a)、(b)、(c)、(d)分别给出使用J48、Bagging、AdaBoost和RandomForest的结果。 从图1中不难看出,对于J48和Bagging,Prediction Spamicity方法不如投票结果好,而对于AdaBoost和RandomForest,Prediction Spamicity方法比投票结果要好些,这说明Prediction Spamicity方法并不总是比多数投票集成性能好。不管使用哪种分类算法,GPENL算法都不同程度地提高了分类性能,并且比多数投票(Vote)和Prediction Spamicity方法都要好。对于Bagging,GPENL算法能使F_measure增加1.77%;对于AdaBoost,GPENL算法能使F_measure增加4.8%;对于RandomForest,GPENL算法能使F_measure增加2.73%;而对于J48,GPENL算法能使F_measure增加7.5%,这说明使用GPENL算法集成较弱的分类器后性能提高更大。对比图1中(a)和(b),我们不难发现,将10个J48类型的分类器使用GP集成后的F_measure(0.797 7)比原训练集上使用Bagging的F_measure(0.78)还要大,这进一步说明了,使用GP进行集成比多数投票集成效果更好。对比表1和图1中的结果,我们可以看出,图1中不管是使用GP集成哪种类型的分类器,它们的结果都不如表1中GPENL_12的F-measure高,这也证明了使用GP集成不同类型的分类器能取得更好的性能,即异态集成优于同态集成,因为使用不同分类算法训练得到的基分类器之间差异性更大。 图1 GPENL算法集成同态分类器的结果 本文提出了利用基于遗传规划的集成学习方法GPENL来识别网络作弊,提高了非平衡数据集分类的性能;研究了抽取训练集的方法,基分类器分类结果的表示,使用遗传规划进行集成的过程及有关遗传规划的设置。WEBSPAM-UK2006数据集的实验验证了GPENL算法在同态集成和异态集成时的有效性,同态集成时,GPENL算法比多数投票和Prediction Spamicity方法都要好,并且验证了使用GP将10个决策树集成后的结果比Bagging算法的F-measure要高;异态集成时,GPENL算法比异态集成的EDKC算法和基于Prediction Spamicity方法的结果都要好,并且验证了异态集成比同态集成的有效性。 未来的工作是在GPENL算法中使用更多不同的分类算法和不同的个体数、代数、表示个体的二叉树深度等参数值;为网络作弊检测寻找更有效的新特征等。 [1] Becchetti L., Castillo I C., Donato I D., et al. Using Rank Propagation and Probabilistic Counting for Link Based Spam Detection[C]//Proceedings of WebKDD 2006, Vol 4811: 127-146. [2] Ntoulas A., Najork M., Manasse M., et al. Detecting spam web pages through content analysis [C]//Proceedings of the 15th International Conference on World Wide Web, WWW 2006: 83-92. [3] Gyöngyi Z., Garcia-Molina H., Pedersen J.. Combating web spam with trustrank [C]//Proceedings of the 30th International Conference on Very Large Data Bases, 2004, 30: 576-587. [4] L. Becchetti, C. Castillo, D. Donato, et al. Link-based characterization and detection of Web Spam [C]//Proceedings of AIRWeb, 2006. [5] Castillo C., Donato D., Murdock V., et al. Know your neighbors: Web spam detection using the Web topology [C]//Proceedings of SIGIR2007: 423-430. [6] Na Dai, Brian D. Davison, Xiaoguang Qi. Looking into the Past to Better Classify Web Spam [C]//Proceedings of AIRWeb ’09, Madrid, Spain (April 21, 2009). [7] Yiqun Liu, Rongwei Cen, Min Zhang, et al. Identifying Web Spam with User Behavior Analysis [C]//Proceedings of AIRWeb 2008, Beijing, China, April 22. [8] Xu-Ying Liu, Jian-xin Wu, Zhi-Hua Zhou. Exploratory under-sampling for class-imbalance learning [J]. IEEE Systems, Man, and Cybernetics Society, 2009, 39 (2): 539-550. [9] Koza J.R.. Genetic Programming: On the Programming of Computers by Means of Natural Selection [M]. MIT Press, Cambridge, 1992. [10] 孙丽娜. 集成异种分类器分类稀有类[D]. 郑州大学硕士学位论文, 2007: 31-33. [11] Guang-Gang Geng, Chun-Heng Wang, Qiu-Dan Li, et al. Boosting the Performance of Web Spam Detection with Ensemble Under-Sampling Classification [C]//Proceedings of FSKD(4) 2007: 583-587. [12] Zhi-Hua Zhou, Jianxin Wu, Wei Tang. Ensembling Neural Networks: Many Could Be Better Than All [J]. Artificial Intelligence, 2002, 137: 239-263. [13] Jung-Yi Lin, Hao-Ren Ke,Been-Chian Chien, et al. Designing a classifier by a layered multi-population genetic programming approach [J]. Pattern Recognition, 2007, 40: 2211-2225.4 实验
4.1 实验数据集
4.2 评价标准
4.3 实验结果和分析

5 结论和将来的工作
猜你喜欢
区域治理(2022年40期)2022-11-27汉字汉语研究(2021年4期)2021-11-26电子技术与软件工程(2019年18期)2019-11-18动漫界·幼教365(小班)(2019年10期)2019-10-28动漫界·幼教365(大班)(2019年10期)2019-10-28动漫界·幼教365(中班)(2019年10期)2019-10-28中国惯性技术学报(2018年4期)2018-11-08小学阅读指南·低年级版(2018年5期)2018-11-02故事作文·低年级(2017年12期)2017-12-13电子技术与软件工程(2017年14期)2017-09-08
