
一种基于LDA的社区问答问句相似度计算方法
2012-06-29 07:03熊大平林鸿飞
中文信息学报 2012年5期
熊大平,王 健,林鸿飞
(大连理工大学 信息检索研究室,辽宁 大连 116024)
1 引言
近年来,随着Web 2.0的高速发展,UGC (User-Generated Content) 网站,像社交网络、书签、微博、照片共享等,越来越流行了。社区问答系统(CQA)也是其中的一种,它吸引了大量的用户,已经积累了海量信息,任何人都可以在上面进行提问和回答。
但由于自然语言中存在歧义性,从CQA语料库中找到相似的问题并不那么简单,其根本原因是: (1)相同的词可以表达不同的意思;(2)不同的词可以表达相同的意思。即相似的问题会有不同的词汇、句法和语义特点,例如,“How can I have my vision restored in a few months?”和“Any ways let myopia restore eyesight in a short period?”是关于恢复视力的两个相似的问题,但它们既不包含很多相同的词,也有着不同的句法结构。如何找到两个相似的问题也就变得十分困难。
早期有学者提出了一种词汇相关统计方法来进行问句的匹配[1],进一步,有综合利用统计信息和基于WordNet的语义信息来进行问句相似度的计算[2]。一个问题,不仅有单个特征词的统计信息和特征词间的语义信息,还有更大范围的主题信息,例如,上面两个问句例子的主题信息是有关恢复视力方面的,从特征词的信息来看,它们是不大相似的,但从主题信息来看是两个相似的问句。
针对上述情况,本论文提出了一种新的LDA主题模型的匹配框架来解决相似问句的匹配问题,从问句的统计信息、语义信息和主题信息三个方面来计算问句间的相似度。最后,线性综合三个方面的相似度来得到整体相似度。
(1) 统计相似度: 基于VSM模型,利用问句的特征词的统计信息来计算相似度。
(2) 语义相似度: 利用WordNet得到特征词间语义相似性,从而得到问句间相似度。
(3) 主题相似度: 基于LDA模型,利用问句的主题信息来计算相似度。
本文其余章节结构组织如下: 第2节介绍相关的工作;第3节是本文提出的基于LDA的问句相似度计算方法;第4节给出试验部分;第5节为总结并提出未来的一些研究方向。
2 相关工作
传统的问答系统(QA),其目标是直接找到问题的答案[3],需要从文档中精确地抽取出问题的答案,而且对查询问句和候选文档均进行深层分析,不具有用户交互特性,而基于社区的问答系统(CQA),是一个开放的、互动的网络平台,有着用户的广泛参与,提供了大量可利用的信息,例如,问题答案对,用户间的网络图结构关系,用户对答案的投票等信息,其目标是对用户提交的问题进行问题匹配并返回答案,更贴近用户需求。如何有效地利用这些信息,学者们提出了很多不同的技术和方法。
文献[4]提取了CQA中大量的非文本信息,蕴含了问题和答案间的关系,如用户对一个问题下每个候选答案的点击次数,并提出了一种基于语言模型的检索模型来得到高质量的答案。文献[5]是同时利用非文本和文本统计信息,并运用回归分析来预测问题的最佳答案。文献[6]提出了一种利用问题类别信息的检索模型,该模型综合问题间的相似度和问题所属类别间的相似度来得到最终的相似分,并按得分进行排序。
利用机器学习的方法。文献[7]提出了一种基于概率的排序模型来同时解决答案的相关性和相似性,该模型使用逻辑回归来估计一个候选答案可能成为正确答案的概率。文献[8]提出一种结合问题答案间关系的类比推理模型来对候选答案进行排序,
该模型先是将那些高质量的问题答案对从语料集中分类提取出来,并利用类比推理的思想按得分进行排序。
基于链接的专家发现方法,其思想是: 根据回答用户提问这种关系来建立用户回答网络图结构,并假定: 高权威的用户往往产生高质量的答案。文献[9-10]采用了HITS算法来计算答案的权威性来查找权威专家,并得到了较好的效果。文献[11]进一步提出了一种按专业知识对用户进行排序的模型,并发现高质量的答案与具有丰富的专业知识网络是高度相关的。
同时,一些学者针对用户在社区问答中得到答案的满意度进行了预测研究[12],用户提交问题后,根据得到的答案所用的时间,答案的质量等因素,来预测用户对答案的满意度。
3 问句相似度计算
在本文中,“问句”、“问题”和“文档”三者的概念等同。
3.1 框架概述
首先,对Yahoo! Answers网站中抽取的语料集,建立问题对应答案的索引,问题集的索引。对查询q,先用VSM模型检索,得到初步的结果,再用语义模型(SEM)、LDA模型对初步的结果再次进行检索,最后将得到的结果进行线性综合。框架的流程图如图1所示。
3.2 VSM模型
向量空间模型(Vector Space Model, VSM)是60年代末由Gerard Salton等人提出的,本文采用一种流行的VSM模型[6]。
给定查询q和问题d,则它们之间的相似度计算如式(1)。
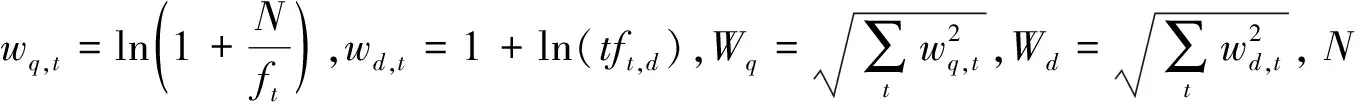
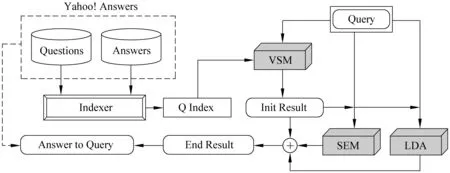
图1 框架的流程图
3.3 语义模型(SEM)
给定两个特征词w1和w2,利用WordNet来计算两个特征词之间的语义相似度
其中,distance(w1,w2)是两个特征词w1和w2间语义的最短距离,并且定义两个相同的词的语义相似度为0,即:distance(w1,w2)=0时,Sem(w1,w2)=1。
对于给定一个查询q和问题d,首先对其进行去停用词和去除功能词的处理,然后再用二分图的方法来计算两句子的相似度[2]。其计算公式如式(3)。
其中wqi和wdi分别表示查询和问题的特征词,|q|和|d|分别表示查询和问题的特征词个数总和,maxsim(wqi,d)和maxsim(wdi,q)定义如下。
(4)
3.4 LDA主题模型
LDA[13]模型是目前应用最广泛的一种概率主题模型,是一个多层的产生式概率模型,包含词、主题和文档三层结构。在本文中,词指特征词,主题指隐含主题,文档指问题。
3.4.1 LDA模型
LDA主题模型是一种概率图模型,其表示形式如图2所示。LDA描述了基于潜在主题生成文档中词的概率抽样过程,其模型由文档集合层的参数(α,β)确定,其中α反映了文档集合中隐含主题间的相对强弱,β刻画所有隐含主题自身的概率分布。生成文档的过程如下。
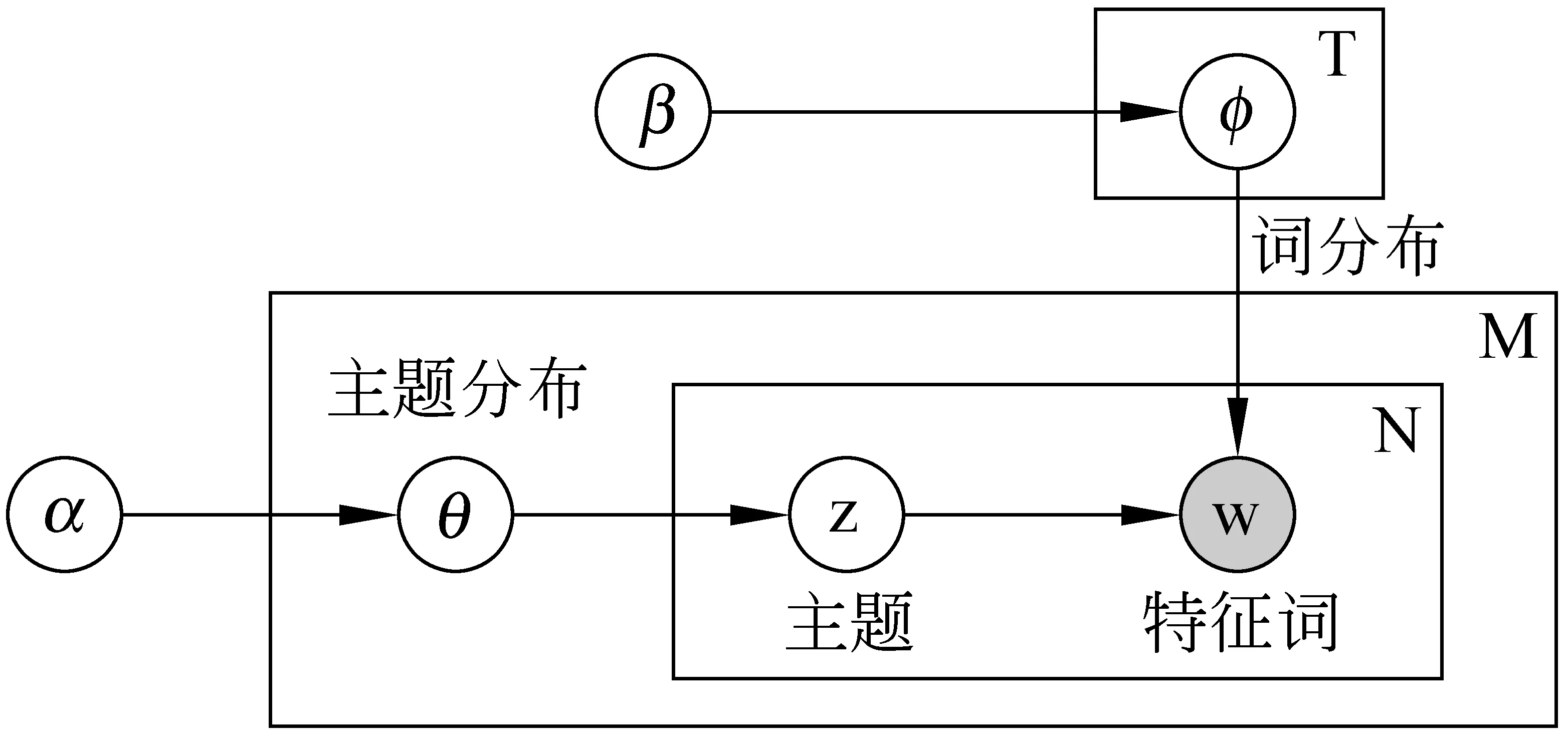
图2 LDA的概率图模型表示
(1) 对于每个主题t,由Dirichlet(β)分布,得到该主题上的一个词多项式分布φ(t)。
(2) 对于每个文档d,由Dirichlet(α)分布,得到该文档上的一个主题多项式分布θd。
(3) 对于每个文档中的每一个单词wi:
a) 从主题多项式分布θd抽取一个主题t。
b) 从该主题上的词多项式分布φ(t)抽取一个单词作为wi。
3.4.2 基于LDA的问句相似度
由LDA主题模型可知,问句中的特征词w的概率计算如式(5)。


在该算法中,经过一定的迭代次数,得到词分布和主题分布的概率后,对于查询q和问题d,可以得到其主题zi的V维词分布概率。
查询q和问题d可以用主题表示如式(8)。

4 实验
4.1 实验数据
本文的实验语料是部分选取Yahoo! Answers (http://answers.yahoo.com)的一个数据集(http://ir.mathcs.emory.edu/?q=node/60)。由于数据的稀疏性会影响LDA主题模型,故选取相对热门的问题类别,每个类的问题数都在1 000个以上,共45个类,每个问题都含有提问者选出的最佳答案。最后的实验语料集信息如表1所示。

表1 语料集的统计信息情况
对语料的每个类别,随机抽取100个问题,由人工总结问题的中心主题,由中心主题手工构造1到3个查询。共计106个查询,含不同的长度和形式,从而避免出现构造的查询,在语料库中无相关问题,即无返回结果。表2是一些查询的例子。

表2 部分查询的例子
由于选取的语料都是已解决的问题答案对,即每个问题都有最佳的答案。并基于这样的假设: 对于某个问题,对应的最佳答案代表了最准确的信息。
于是,对查询返回的结果,利用问题的最佳答案来判断是否是相关文档,即是否是相似的问题。
4.2 结果评价
为了评价本文的检索方法的性能,本文采用了四种不同的检索系统进行对比实验,其中(2)为文献[3]中的方法。
(1) VSM: 基于简单向量空间的检索模型;
(2) VSM+SEM[3]: 在模型(1)的基础上,加上基于WordNet的语义检索模型;
(3) VSM+LDA: 在模型(1)的基础上,加上基于LDA主题的检索模型;
(4) VSM+SEM+LDA(Ours): 在模型(2)的基础上,加上基于LDA主题的检索模型。
4.2.1 AP@1和MAP
对给定的查询,平均准确率AP@1表示了在返回的第一个结果中,相关文档的平均百分比,百分数越高,性能越好。在本文中,MAP表示计算返回的前10个结果的平均准确率,即MAP10。表3为本文的方法与对比实验的方法在AP@1和MAP的结果。

表3 四种模型在AP@1和MAP上的结果
4.2.2 MRR (Mean Reciprocal Rank)
由于MAP考虑的只是相关文档百分比,忽略了相关文档的排序顺序,故针对问答系统对返回结果特有的要求,本文采用MRR来进一步评价。所有查询的MRR计算公式如式(13),结果如图3所示。
其中,|Qr|指查询的个数,rq指对查询q返回的第一个相关答案的排序位置。

图3 四种模型在MRR上的结果
4.3 实验结果分析
本文采用了AP@1、MAP和MRR三种指标来进行结果的评价。结果如表3和图3所示,从中得到以下几点结论。
(1) 单只用VSM模型时,就得到了较高的平均准确率(MAP=0.678 3),可以推断出高准确率是因为从Yahoo! Answers中抽取大量的语料集,并选取了相对热门的类别,而且是根据类别的主题思想构造查询,故与每个查询相关的问题比较多。
(2) 加上语义模型(SEM),相比只用VSM模型,AP@1有了一定的提高,这是因为在Yahoo! Answers中存在很多语义上比较相似的单词,另一方面,MAP只提高了1.489 0%,是因为VSM模型就已经得到了较高的结果,再加上SEM模型后提升就不大了;语料也有一定的影响,用其他的语料,提升可能会更大些。
(3) 在VSM模型基础上加上主题模型(LDA),相比只用VSM模型和VSM+SEM模型,AP@1有了一定的提高, 这说明使用主题来表示查询后,能更好发现那些特征词不相似,但主题比较相似的问题。比VSM+SEM模型的效果要好一些,一方面是因为LDA模型在将特征词转化成主题时,内部结构间接地结合了一定的语义信息,相比SEM,范围要大一些,故效果要好一些;另一方面,本文的查询是通过每个类的主题思想来构造的,查询返回结果会多一些。
(4) 在VSM模型基础上同时加上语义模型(SEM)和主题模型(LDA),其结果是最好的,AP@1值为0.849 1,相比VSM模型,MAP提高了4.732 4%。这说明了同时结合语义和主题信息,能够更好地理解查询所要表达的信息,故而能更好地找到相似的问题。
(5)由图3可知,本文采用MRR来进行进一步的评价,其结果与AP@1和MAP结果的趋势是相一致的。
(6) 实例说明,对于引言中的两个关于恢复视力的相似问句例子,假定: 查询q为“How can I have my vision restored in a few months”,问题d为“Any ways let myopia restore eyesight in a short period”。进行去停用词,词干化后,并假定主题个数为K=6,如表4所示。

表4 词在主题中的分配(K=6)
则查询q和问题d由主题向量表示时,都含有主题1、主题2和主题3,故由主题相似度计算公式(9)可知,存在很大的相似性。
5 结束语
本文提出了一种新的基于LDA主题模型的匹配框架来解决相似问句的匹配问题,这也是第一次尝试将LDA主题模型用于计算问句的相似度,并综合VSM模型、语义模型构造的问答系统,如实验部分所述,显示了很好的性能。
该检索系统目前只是集中解决了单问句的相似度匹配问题。对于一个含有多个问句,对问句进行大量篇幅的说明,所包含的信息量很大的提问,本检索系统没有得到很好的应用,这有待于对检索框架的进一步改进和完善,这也是今后继续研究的方向。
[1] A. Berger, R. Caruana, D.Cohn, et al. Bridging the Lexical Chasm: Statistical Approaches to Answer-Finding[C]//Proceedings of SIGIR, New York, NY, USA, 2000: 192-199.
[2] Song Wanpeng, Feng Min, Gu Naijie, et al. Question Similarity Calculation for FAQ Answering[C]//Proceedings of SKG, 2007: 298-301.
[3] D. Molla, J. Vicedo. Question answering in restricted domains: An overview[J]. Computational Linguistics, 2007, 33(1):41-61.
[4] J. Jeon, W. B. Croft, J. H. Lee, et al. A framework to predict the quality of answers with non-textual features[C]//Proceedings of SIGIR, Seattle, USA, 2006: 228-235.
[5] M. Blooma, A. Chua, D. Goh. A predictive framework for retrieving the best answer[C]//Proceedings of SAC, Brazil, 2008: 1107-1111.
[6] Cao Xin, Cong Gao, Cui Bin, et al. A Generalized Framework of Exploring Category Information for Question Retrieval in Community Question Answer Archives[C]//Proceedings of WWW, Raleigh, New York, NY, USA. 2010: 201-210.
[7] J. Ko, L. Si, E. Nyberg. A probabilistic framework for answer selection in question answering[C]// Proceedings of NAACL/HLT, Rochester, NY, 2007: 524-531.
[8] Wang Xinjing, Tu Xudong, et al. Ranking community answers by modeling question- answer relationships via analogical reasoning[C]//Proceedings of SIGIR, New York, NY, USA. 2009: 179-186.
[9] P. Jurczyk, E. Agichtein. Discovering authorities in question answer communities by using link analysis [C]// Proceedings of CIKM, New York, NY, USA, 2007: 919-922.
[10] Shen Jie, Shen Wen, Fan Xin. Recommending Experts in Q&A Communities by Weighted HITS Algorithm[C]//Proceedings of IFITA, 2009: 151-154.
[11] J. Zhang, M. Ackerman, L. Adamic. Expertise networks in online communities: Structure and algorithms[C]//Proceedings of WWW, New York, NY, USA, 2007: 221-230.
[12] Liu Yandong, Bian Jiang, E. Agichtein. Predicting Information Seeker Satisfaction in Community Question Answering[C]//Proceedings of SIGIR, New York, NY, USA. 2008: 483-490.
[13] M. Blei, A. Ng, M. Jordan. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, b: 993-1022.
[14] T. L. Griffiths, M. Steyvers. Finding scientific topics[C]//Proceeding of the National Academy of Sciences. 2004: 5228-5235.
猜你喜欢
客联(2022年3期)2022-05-31
通信技术(2021年12期)2022-01-25
计算机系统应用(2021年9期)2021-10-11
中国新闻周刊(2021年26期)2021-07-27
计算机应用与软件(2018年9期)2018-09-26
计算机技术与发展(2018年8期)2018-08-21
计算机应用与软件(2018年1期)2018-02-27
中国机械工程(2017年22期)2017-12-02
电脑爱好者(2017年7期)2017-05-06
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
