
SF-MAX-Log-MAP并行译码算法及其应用研究
2012-06-13 02:09孙增友张利杰
东北电力大学学报 2012年4期
孙增友,张利杰,田 勇
(东北电力大学信息工程学院,吉林吉林132012)
Turbo码诞生于1993年,是由法国的Berrou[1]等人首次提出的。由于其解码性能非常接近于Shannon理论极限,Turbo码成为了第三代移动通信的信道编码方案之一。为满足移动用户的需求以及应对其他通信技术的挑战,3GPP提出了从WCDMA、HSPA到LTE的演进方案。由于3GPP LTE支持高达100 Mbps的峰值速率,而Turbo最大码块长达6 144 bit。当码块较长时,若采用串行译码方式,其实现的复杂度高,延时大,采用并行译码不失为一种较好的选择。
文章在阐述Turbo码的串行和并行译码结构的同时,探讨了SF-MAX-Log-MAP算法的优越性,将其应用于分块并行的Turbo译码算法中,并在LTE系统中进行了分析。
1 串行译码结构
1.1 Turbo 译码结构
Turbo译码需采用递归迭代方法。为使Turbo码达到较好的性能,分量译码器必须采用SISO算法,从而实现迭代译码过程中软信息在分量译码器之间的交换。
如图1所示:Turbo译码器的串行结构,在第一次迭代过程中,子译码器1由信息位xs和校验位sp作为输入,外信息Le(dk1)作为输出,子译码器2以经过交织的信息位xs'、xp2和经过正交织的E12作为输入,外信息Le(dk2)和硬判决值作为输出。在第二次迭代过程中,信息位xs、校验位xp1和经过反交织的Le(dk2)作为输入,这样周而复始进行下去,直到达到最大迭代次数。此时子译码器2得到对最大似然函数值(LLR)的硬判决输出值s'。

图1 Turbo译码器结构
1.2SF-MAX-Log-MAP 算法
Forney等人证明了最优的软输出译码器是后验概率(APP)译码器[2],其中MAP(最大后验概率)算法最为经典。最大后验概率(MAP)译码算法是1974年由Balh,Cocke,Jelinek和Raviv共同提出的,因此也称为BCJR算法[3]。它是基于网格的软入软出译码算法,译码准则是在噪声信道下对马尔可夫过程的状态及输入输出进行逐一估计。它可以准确地计算每一信息比特的后验概率,但由于MAP算法包含了大量的指数和乘法运算,难以实现。若将其转换到对数域,可变乘法为加法。后来在对数域对MAP算法进行了修正。一种为Log-MAP算法,另一种为MAX-Log-MAP算法。
MAX-Log-MAP算法相比较与MAP算法实现比较简单,但是却存在着性能差距。根据文献[4]由于MAX-Log-MAP算法在计算过程中对Jacobian Logarithm算法,式(1)进行了近似,忽略了修正函数
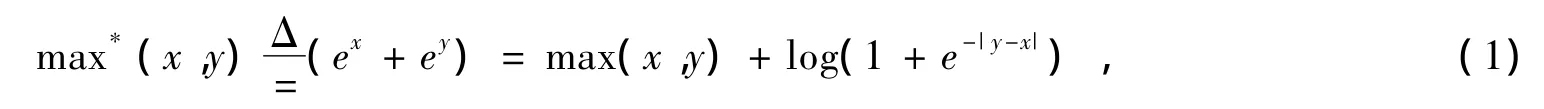
(1+e-|y-x|),放大了子译码器的外信息,为改善MAX-Log-MAP算法的性能,可以在MAX-Log-MAP算法中对子译码器外信息乘以一个尺度因子Sp(0<Sp<1),使得子译码器外信息逼近MAP算法中的子译码器外信息LeMAP(dk),且当Sp=0.7时,译码性能最好。此时外信息为:

此算法即为SF-MAX-Log-MAP算法。它使Turbo码在较小的译码复杂度情况下,达到与Log-MAP算法接近的误码率性能。这一性能改进具有现实的意义。
2 并行译码结构
由Turbo码的串行译码过程可以看出,Turbo码的译码时延主要由两部分[6]:一是译码等待时延,串行译码器要等到整个数据块结束后方可译码,二是译码计算时延,计算量越大,时延也就越大。为减小时延,S.Yoon等人提出了一种通过子块间交换信息来提高译码性能的分块并行译码算法[7]。该算法中,若信息帧长为N,各个子块长为W,则所分子块数为M,。与M组子译码器相对应,每个子译码器进行独立译码,M为译码并行度。这种简单的分块并行译码算法的译码时间缩短为串行译码的,但由于在译码过程中,各子块之间相互独立,没有充分利用码元之间的外信息,与串行码相比,译码性能有很大损失。
为充分利用码元之间的信息,J.KIM,H.PARK等人提出一种通过子块间重叠一部分码元来提高译码性能的算法[8],该算法将长度为N的码块分解为M个子块,N=M×W,相邻子块之间有2V码元相互重叠。其译码结构如框图2。从图2可发现,在整个码块中,子块1和子块M的长度为W+V,其余子块长度为W+2V。以子块2为例,重叠算法中子块长度比简单分块并行译码算法延长了2V码元,每次迭代中,对这2V码元进行计算都有利于提高前后向递推变量的计算。V越大,计算量越大,计算出的前向和后向递推量越准确,译码性能也就越好。

图2 子块重叠的并行译码结构
3 改进的并行译码算法——SF-MAX-Log-MAP并行译码算法
MAP算法计算量较大,Log-MAP算法把乘法运算转换为对数域的加法运算,比MAP算法更有利于实现。尽管如此,进一步简化Log-MAP算法和降低Log-MAP对存储空间的要求对算法的实现具有重要意义。MAX-Log-MAP算法则进一步简化了计算量,但系统误码率变大了,在误码率为10-6时编码增益比MAP算法降低了0.3~0.4 dB[9]。改进的SF-MAX-Log-MAP算法在相同的误码率情况下编码增益只比MAP算法相差0.1 dB,编码增益大约提高了0.22 dB[10],更好的实现了译码性能和计算量的折中。若是将SF-MAX-Log-MAP算法替代Log-MAP并行译码算法中的Log-MAP算法,则可实现译码时延小,计算量小,误码率低,满足LTE系统对误码率低和延迟小的要求。
下面对SF-MAX-Log-MAP并行译码算法进行了简单阐述。
首先根据图2,将帧长为N的输入数据分割为M个子块,相邻子块重叠长度为V。由对数据的分块处理情况可知,第一子块的前向递推初始值和最后一个子块的后向递推初始值是确定的,分别为:
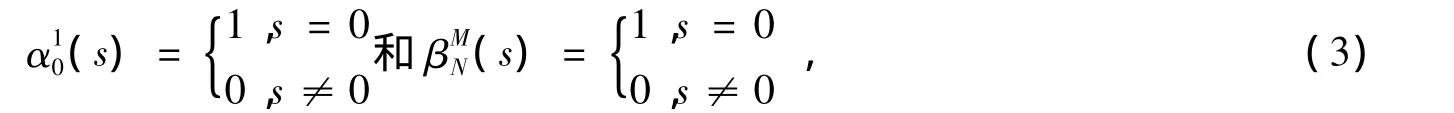
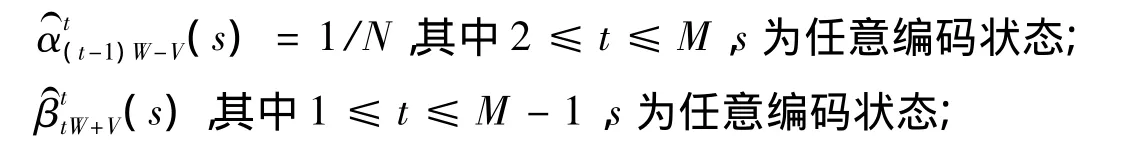
然后,按照以下SF-MAX-Log-MAP算法计算前向、后向递推公式以及分支转移概率,最后对最大似然函数值进行硬判决,输出译码结果。
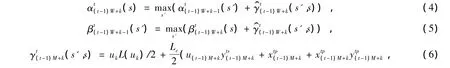
外信息输出为:

最大似然函数值为:

4 性能仿真
通过MATLAB仿真,验证了此改进算法的有效性。并就LTE系统中Turbo码的误码率性能进行了研究,分析了其关键参数(交织长度、并行度、交叠长度)对译码性能的影响。仿真相关信息如下:
编码方案:LTE中的Turbo码编码方案
其中分量码为8状态递推系统卷积码,生成多项式为[D3+D2+1,D3+D2+D+1],码率为1/3,
调制方式:BPSK
信道模型:AWGN
译码算法:SF-MAX-Log-MAP并行译码算法
迭代次数:2
4.1 译码算法比较
如图3(a)所示:为并行度为2和重叠长度L=32的情况下,三种并行译码算法的性能比较。在三种并行译码方式中Log-MAP并行译码算法性能最好,MAX-Log-MAP并行译码算法性能与它有较大的差距,而SF-MAX-Log-MAP并行译码算法改善了这种性能差距。因此提出的SF-MAX-LOG-MAP并行译码算法是可行的。

图3 不同译码算法的译码性能比较
如图3(b)所示为:交织长度(码长)为1 024的情况下,分别采用串行和并行方式进行译码时,Turbo码的误码率性能。从此图中可以看出,采用并行译码结构,Turbo码的性能有一定的损失。但这种损失非常小,因此在LTE系统中采用并行译码结构是可行的。
4.2 交织长度的影响
图4所示仿真图可以看出:在译码并行度为4,交叠长度为32的并行译码过程中,交织长度为2 048的码块比交织长度为1 024的误码率低,译码性能好。因此,在相同的并行度和交叠长度条件下,交织长度越长,译码性能越好。这是因为在并行度不变的情况下,交织长度越长,编码器输出的码间自由距离越大,码抵抗突发错误的能力越强,译码性能也就越好。
4.3 并行度的影响

图4 交织长度对Turbo码误码性能的影响

图5 并行度对Turbo码误码性能的影响
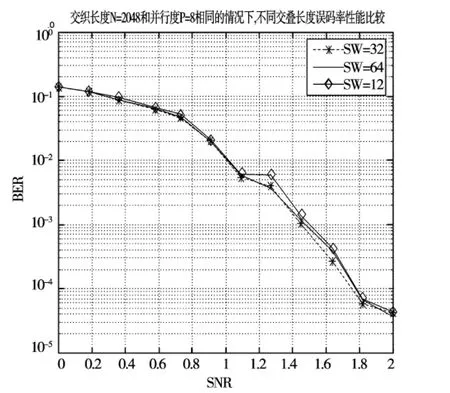
图6 交叠长度对译码性能的影响
图5所示:在交织长度为2 048和交叠长度为32的并行译码过程中,若采用的并行度分别为8和4,则两情况的误码率基本吻合。考虑到并行度越大,系统的复杂度越大,费用越高,采用并行度为4的译码器比较合适。因此,LTE采用并行译码方案时,不仅应考虑译码效率还需考虑占用的硬件资源及系统的复杂性。
4.4 交叠长度的影响
图6中所示为:在交织长度和并行度相同的情况下,交叠长度分别为12、32和64的误码性能仿真。从仿真图中可以看出:当交叠长度L=12时译码性能最差,L=32和L=64时译码性能基本吻合。由此,当交叠长度较小时,增大交叠长度可以改善译码性能,但当增到一定程度时,并不能改善译码性能。因此,在并行译码过程中应选择较合适的交叠长度,若交叠长度太小,译码性能不理想;交叠长度过大,计算量也越大,不利于降低译码时延。
5 结 论
在Turbo码的Log-MAP并行译码算法和SF-MAX-Log-MAP算法的基础上,对它们进行了结合,提出了SF-MAX-Log-MAP并行译码算法。通过仿真表明:此算法在减少了大量运算量的同时,保持了Log-MAP并行算法的译码性能。在LTE系统中,当Turbo码长较大时,选择合适的并行译码算法可以降低译码时延。此并行译码算法需确定合适的并行度、交叠长度,且在满足误码率和时延要求的情况下,需兼顾考虑译码系统占用的硬件资源,以降低Turbo译码系统费用及复杂度。
[1]C BERROU,A.Glavieux and P.Thitimajshim.Near Shannon Limit Error-Correcting Coding and Decoding:Turbo-Codes[C].IEEE Int.Conf.on Communications,1993:1064 - 1070.
[2]刘东华.Turbo码在无线移动通信系统中的应用[J].广东通信技术,2001,21(2):38-42.
[3]BAHL L R,COCKE J,JELINEK F,et al.Optimal decoding of linear codes for minimizing symbol error rate[C].IEEE Transactions on Information Theory,1974:284 -286.
[4]L.PAPKE.P.ROBERTSON,and E.VILLEBRUN.’Improved decoding with the SOVA in a parallel oncatenated(Turbo-code)scheme,’in Proc,IEEE Intenarional Conference on Communications(ICC’96)[C],Dallas,Tex,USA,June,1996(1):102 -106.
[5]J.KIM,H.PARK,B.KIM and S.PARK.Mod ed enhanced max-log-maximum aposteriori algorithm using variable scaling factor[C].IET Commitafion,2007:1061 -1066.
[6]陈雷,田晓燕.时延改进的Turbo码译码算法[C].1944-2011 China Academic Journal Electronic Publishing House.
[7]YooN S,BAR-NESS Y.A parallel MAP algorithm for low latency Turbo Decoding[J].IEEE ommuncate,2002,6(7):288 -299
[8]H SU,I WANG C.A Parallel decoding scheme for Turbo codes[C].Proc ISCCA98,1998,4(6):445 -448.
[9]VOGT J,FINGER.AN Improving the Max-Log-MAP Turbo decoding[J].Electronics Letters,2000,36(23):1937 -1939.
[10]汪汗新,叶俊民.基于Turbo码的Max-Log-MAP译码算法的改进.现代电子技术[J].2003,160(16):39-41.
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
美食(2022年2期)2022-04-19
现代计算机(2021年36期)2021-03-14
女报(2019年3期)2019-09-10
成都信息工程大学学报(2018年4期)2019-01-23
计算机应用(2018年12期)2019-01-07
成都信息工程大学学报(2018年6期)2018-03-21
时代英语·高一(2017年5期)2017-11-14
华人时刊(2016年17期)2016-04-05
化工学报(2015年11期)2015-09-08
