
中国潜在产出测算比较
2012-05-22 07:56高哲峰
中国流通经济 2012年6期
高哲峰
(中国科学院研究生院,北京市 100049)
“潜在产出”(Potential Output)指一个经济体在非加速通货膨胀、资源被充分利用的条件下,能够实现可持续的最大产出水平;“产出缺口”(Output Gap)是建立在潜在产出概念基础之上的、表示实体经济水平偏离潜在产出水平的程度。[1]它们是宏观经济学中的重要概念,有助于对宏观经济形势的准确分析和判断,是宏观经济政策制定的重要参考依据,对一个国家和地区短期经济稳定和长期经济增长具有非常重要的意义。
如何准确测算潜在产出和产出缺口,是当今宏观经济研究的热点问题,因为潜在产出规模和产出缺口数额不是可以直接观察到的,而只能通过实际产出的数额进行计算和估计,自20世纪60年代起,涌现了大量的潜在产出和产出缺口的估算方法。
本文对目前的测算方法进行分析和比较,选择两种方法进行实证研究,并对结果进行进一步比较,旨在推动我国潜在产出测算方法的进一步深化。
一、潜在产出的基本测算方法和评析
综观潜在产出的测算方法,大体可以分为三类:统计分解趋势法、经济结构关系估计法和二者相结合的方法。[2]
统计分解趋势法是把时间序列分解为周期性成分和永久性成分,去除掉实际产出中的暂时性成分,运用多种统计技术和计量技术,计算出实际产出的趋势值,在此基础上估算出潜在产出。这类方法主要包括各种滤波方法,包括HP滤波法、BP滤波法、UC-卡尔曼滤波法等。经济结构关系估计法用经济理论分离出周期性和结构性因素对产出的影响,并在一定的约束条件下,建立要素产出与投入间的关系,从而对潜在产出作出估算。比较典型的方法包括索罗增长模型方法和CD生产函数方法。二者相结合的方法包括结构向量自回归模型(SVAR)等,目前尚处于探索阶段。
各类测算方法都有其自身的优势和这样那样的不足。统计分解趋势法的优势在于比较简便和易用;比较而言更加灵活,体现在估计参数值和数据系列趋势方面,允许估计的参数数值随经济的发展而变化;[3]另外消除趋势法在确定时间趋势变化时更加快捷。但是,各种滤波技术是从电力工程和物理学等其他学科借鉴而来的,缺乏经济理论基础,造成了计算结果经济学的解释意义不强;[4]很多滤波方法所选取的参数是靠主观经验判断,影响了估算的可信度;会遇到样本末期问题等。[5]
经济结构关系估计法因为其模型是根据生产关系建立的,因此所得出的结论富有经济学方面的解释意义,能揭示出更多的内涵,这是经济结构关系估计法最大的优势。但同时,其对数据的要求较高,很多数据难以直接取得,一些数据往往是通过某些估计方法得到的;另外,模型是以生产关系模型为基础建立起来的,生产关系模型是否合理,是否与中国的市场环境相适应,是一个需要考察的问题。
国内外已有大量的潜在产出和产出缺口测算研究和实践,大多不是采用单一的方法,而是同时采用多种测算方法。其中使用最普遍的是生产函数法,另外各种滤波方法也被大量采用。
本文采用了统计分解趋势法中比较典型的HP滤波法,因为HP滤波法相对于之前的趋势剔除法具有很好的适应性和灵活性,是趋势剔除法中最典型的一种;同时采用了经济结构关系估计法中应用最广的CD生产函数法,生产函数法充分考虑了资本投入或现有资本存量、劳动投入、全要素生产率等,体现了潜在产出的供给面特征,[6]比较好地反映了潜在产出的本质,是经济结构关系估计法中经典的方法。本文将用这两种方法对我国的潜在产出进行实证研究。
另外,在以往的产出计算方法中,都是使用总量数据如GDP对中国的潜在产出进行估算,这是无可厚非的,但这种做法忽视了中国经济的一个重要特点,即中国经济的发展是不平衡的。
一般来讲,发展快的地区,真实产出水平会接近或高于潜在产出水平,而发展慢的地区,真实产出水平会低于潜在产出水平。采用全国GDP等总量指标,这种区域不平衡的现实情况无法在数据中得到体现。如果完全忽略地区发展水平差异,在全国范围内实行统一的财政金融政策,可能会造成某些地区的经济更加超越潜在产出水平,而另外一些地区经济发展水平仍远低于潜在产出水平,因此虽然国家宏观政策的方向是正确的,但经过调节的实际产出水平仍与潜在产出水平相差甚远,甚至造成更加严重的不平衡,政策的效果就会大打折扣。
为了克服上述缺陷,本文将对各省的潜在产出水平分别进行估计,试图对各地区的潜在产出水平进行比较,以揭示各地区的差异。
二、实证研究
本文采用《中国统计年鉴》1984~2010年的年度数据。需要说明的是:第一,1992年及之前的年鉴,没有提供各地区“国内生产总值”数据,因此采用了各地区“国民收入”的数据作为替代。第二,海南省1987年及重庆市1996年才单独进行统计。为了数据的前后一致性和可比性,未把它们单独计算,而是把海南省与广东省合并计算,重庆市与四川省合并计算。第三,《中国统计年鉴》有时会对旧版的数据进行修订。如各地区国内生产总值数据,2010年的年鉴根据第二次经济普查的结果修订了2005~2008年的数据,本文均采用最后修订数据。
GDP数据均折算为2010年不变价格。本文以末年(2010年)为基年的处理方法有些不同寻常,这主要是受统计数据的影响,具体而言是为了克服海南和重庆GDP数据不连续的问题,因海南省和重庆市1984年没有统计数据,如果以1984年为基年,无法进行计算,而以2010年为基年就避免了这一问题。
本文先计算各省的潜在产出,再合成全国的潜在产出。首先使用全国数据,对潜在产出进行估计,以便与分省数据估计结果进行比较分析。
在使用全国数据的时候,遇到一个统计数据上的问题,即各省的GDP加总值大于全国的GDP数值。根据《中国统计年鉴》的说法,各地区国民收入是由各地统计局计算的,在计算方法上同全国有不一致的地方,故各地区数字相加之和不等于全国数字。所以这里全国数据有两个:全国GDP、各省加总的GDP,以便能和各省的潜在产出进行对比。再加上把分省的潜在产出合成全国潜在产出,数据来源共有3个,每种数据分别用HP滤波法和CD生产函数法进行测算,最终得到六组全国潜在产出数据(参见表1)。
1.HP滤波法
首先用全国GDP数据(记为GDP1)对潜在产出进行估算,具体步骤如下:
步骤一:为检验现实产出序列的平稳性,进行ADF检验,结果显示,现实产出GDP1为非平稳序列,存在单位根。对GDP1取对数,记为LnY,对LnY再次进行ADF检验,结果显示,仍为非平稳序列,并含有一个单位根过程。进一步对LnY的一阶差分继续进行ADF检验,选择不含时间趋势项和常数项。检验表明,一阶差分序列在1.3%的显著性水平下拒绝原假设,接受不存在单位根的结论,从而可以认为,GDP1对数序列(LnY)的一阶差分序列为平稳序列,可以应用HP滤波法。[7]
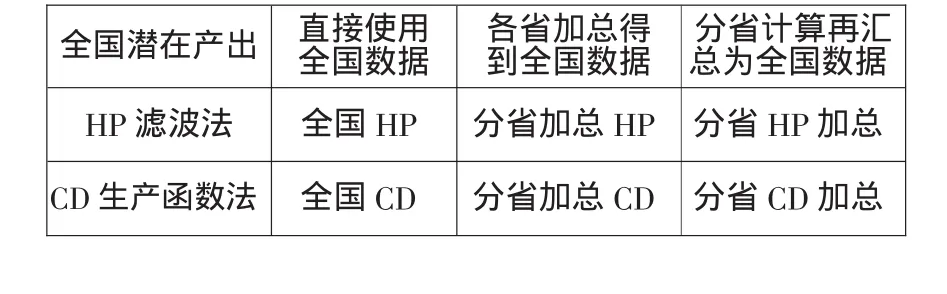
表1 六组全国潜在产出数据来源和计算方法
步骤二:用HP滤波法估算潜在产出。在采用HP滤波法进行潜在产出估算时,因使用年度数据,遵循了通常做法,采用让和阿林(Ravn and Uhling)的建议值,年度数据取λ=100,用Eviews5.0求得我国1984~2010年各年的潜在产出及产出缺口。
用各省加总GDP数据(记为GDP2),采用HP滤波法对潜在产出估算的过程与前面完全相同,不再赘述。使用计算全国潜在产出同样的步骤,计算各省的潜在产出。比较异常的是四川(含重庆)的数据,异常的时间在1996年和1997年,正好是重庆成立直辖市有单独统计数据的时候,可能在统计口径上存在一定的偏差。
2.CD生产函数法
CD生产函数法的基本模型[7]是:

其中 Yt为现实产出,At为技术水平,Ktα为资本存量,Ltβ为劳动投入;α、β分别是资本和劳动投入对产出的贡献程度。两边同时取自然对数可得:

通常假设α+β=1,即规模收益不变,代入上式,得回归方程:
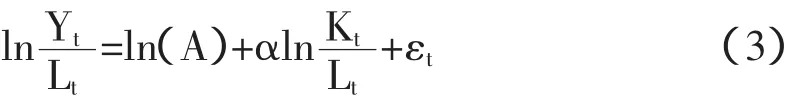
这是一个双对数模型,可以用普通最小二乘法(Ordinary Least Square,OLS)加以估算。
CD生产函数法的难点是该方法对数据要求非常高,主要面临两个难题:资本存量的测算和潜在就业的估算。
(1)资本存量Kt的计算。戈德史密斯(Goldsmith)在1951年开创的永续盘存法(Perpetual Inventory Approach)是测算资本存量的基本方法,被经济合作与发展组织(Organization for Economic Co-operation and Development,OECD)国家广泛采用。[8]其基本公式为:

Kt表示第t年的资本存量,Kt-1表示第t-1年的资本存量,It表示第t年的投资,αt表示第t年的折旧率。因为需要折算为不变价格,把投资进行了折算,公式变为:

Pt为固定资产价格折算指数。
在对我国资本存量进行实际测算时,有三个难点:基年资本存量的确定、固定资产投资价格指数的确定、资本折旧的确定。[9]
统计年鉴没有提供中国早期的固定资本存量,仅有全民所有制企业固定资产数据,所以,确定早期的资本存量一般采取推算方法。本文采用了郭庆旺和贾俊雪整理的1978~2002年数据,[10]1983年资本存量为7794.1亿元(1978年不变价格),再折算出用2010年不变价格计算的1983年资本存量为35960.08亿元。
关于固定资产投资价格指数Pt如何确定的问题,目前普遍的做法是用其他指数来替代,本文直接采用了《中国统计年鉴》的“固定资产投资价格指数”。不过《中国统计年鉴》没有提供1988年(1989年年鉴)和更早年份的指数,所以本文1984~1988年的指数采用“全社会零售物价总指数和生活费用价格指数”替代。
王小鲁等在计算固定资本形成时,采用了5%的折旧率。[11]本文采用了他们的做法,假定的固定资产折旧率为5%,首先是出于计算上的方便,另外该数值与《中国统计年鉴》国有企业1978~1992年间的固定资产折旧率大致相当。
(2)潜在就业估算。本文主要借鉴了郭庆旺和贾俊雪的研究,采用如下公式来估算:[12]
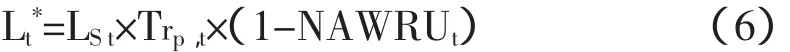
其中Lt*表示潜在就业,LSt表示达到工作年龄的人数,Trp,t表示趋势参与率,NAWRUt表示非工资引致失业率。我国目前缺乏参与率等数据,所以用HP滤波法对全社会经济活动人数进行分解处理,得到趋势全社会经济活动人数,替代公式中的LSt×Trp,t;另外,利用 HP 滤波法对劳动就业人数与经济活动人数的比值进行分解,用其趋势成分来代替作为变通。这样利用该公式就得到了我国1978~2002年各年的潜在就业量。
估算过程如下:
步骤一:用现实GDP、实际就业、资本存量对公式(3)进行回归:
步骤二:对全要素生产率εt用HP滤波法进行分解,把趋势项和潜在就业数据代回原式,可以得到潜在产出的数据。
对各省加总GDP(记为GDP2)采用同样步骤进行测算,这里不再赘述。
用CD生产函数法测算各省的潜在产出,与测算全国的潜在产出的过程完全相同。
三、实证结果的比较和分析
1.全国潜在产出计算结果的比较
上文的计算得到6组潜在产出结果,对6种潜在产出的增长率进行比较。
(1)比较各种方法得出的潜在产出增长率。①数量差别。全国HP、全国CD数值,均比分省加总HP、分省CD加总数值低。这是因为全国数据小于分省数据加总额造成的,不具有可比性。分省加总HP和分省HP加总,分省加总CD和分省CD加总在数量上差别很小,说明计算全国潜在产出,两种途径没有明显差别。②形态差别。使用HP滤波法计算的增长率明显比较平滑,起伏很小,而用CD生产函数法计算的结果明显波动性较强,起伏较大。使用HP滤波法时,结果的平滑程度跟计算时λ的取值有关,λ越大,曲线越平滑。不过从波动峰值上看,HP滤波法的结果显示,1984~1990年的变化比较平缓,而CD生产函数法在1989~1990年出现了较大幅度的下滑,这更加符合实际情况。
(2)比较各种方法得出的产出缺口。①数量差别。从直观上看,各种算法的差别不大。②形态差别。各种方法的形态相仿,但比较曲线峰值,区别较大。1984年,CD生产函数法的缺口均为正值,而HP滤波法的缺口均为负值;1988年,CD生产函数法的缺口转为负值,而HP滤波法的缺口转为正值;CD生产函数法在1990年出现了最大的负值,HP滤波法出现在1991年;1994~1996年的峰值出现时间差别较大,总体CD生产函数法的峰值出现较早,这在1999年之后的峰值表现更为明显;2007年的峰值出现时间非常一致;2010年CD生产函数法为负值,HP滤波法为正值。
从整个国家经济发展的脉络上看,1978年我国开始实行改革开放,工作重心放到了经济建设上,设立经济特区、鼓励贸易、改革开放、扩大对外经济交流。这一时期经济增长较快,产出缺口应该为正,所以CD生产函数法似乎更符合实际情况。1992~1996年间,出现了“高增长、高通胀”的情况,1994年之后,CD生产函数法的产出缺口开始下降,预示了当时“高增长、高通胀”的情况难以为继,而HP滤波法的峰值出现较晚,说明CD生产函数法更有前瞻性。1997年出现了亚洲金融危机,至2000年,积极的财政政策发挥作用,经济加速增长,CD生产函数法早于HP滤波法一年见底,再次表明了CD生产函数法更有前瞻性。2007年开始出现次贷危机,国际经济环境急转直下,结合2011年我国进行的经济结构调整,我国经济处在转型期,产出缺口为负比较符合实际情况,说明CD生产函数法更符合实际情况。
综上所述,用CD生产函数法计算的产出缺口,比较能反映经济的基本状态,而且具有一定的前瞻性。
以前学者认为消除趋势法和CD生产函数法相对有效可靠,通过本文进一步的比较,发现CD生产函数法更有优势。当然,本文通过1984~2010年区间的数据研究得出的上述结论,时间跨度比较小,时间序列对样本长度是敏感的,因此本文的结论可能存在一定的局限性。
2.经济区域间潜在产出和产出缺口的比较
《中国经济年鉴》1994年版中明确划分了东部、中部和西部三大经济区,简称东中西“老”三区。[13]到“十五”末,中央对西部的资金投入大幅增加,因此个别地区积极投身西部地区,为了争取享有国家“西部大开发”的政策支持,最终原中部地区的内蒙古和东部地区的广西被归入西部区,这被称为东中西“新”三区。后将东北三省的辽宁、吉林、黑龙江划为一个独立的经济区,我国经济区划由“三分法”转变为“四分法”(参见表2)。
从4个地区潜在产出的增长率来看,东部一直居前,东北基本居末,2006年以后才有赶超趋势。从4个经济区的变化节点(峰值)来看,还是有很多差别的。1990年,东部和西部到达谷底,东北和中部1991年才到达谷底;1994年,东部为峰顶,西部和中部1995年为峰顶,而东北1997年才到达峰顶,且高度较其他地区低很多;2004年东北到达峰顶,其他地区变化比较平缓;2010年趋势比较一致,但东北下降较快。2000年比较具有典型意义,因为各个地区的产出缺口均接近为“0”,这一年对应的潜在产出增长率分别为10.57%、9.07%、9.36%、9.89%。

表2 中国经济分区(四分法)
四、政策建议
潜在产出对宏观经济政策的制定有重要意义,在具体实践中,应该注意以下几个方面:
第一,地区间的均衡。本文通过研究发现,各地区的潜在产出水平存在一定差异。因此,在制定宏观经济政策的时候,要充分考虑各地区的差异性,在制定统一政策的同时,再根据各地区的实际情况对政策进行微调,以保证政策最大的适用性。
第二,统计数据的规范化。本文的研究证明CD生产函数法对潜在产出的测算更为有效,但CD生产函数法的一个难点是对数据要求高。在实际对各省潜在产出计算当中,更是碰到了不少数据方面的问题。如《中国统计年鉴》中,各省的GDP加总不等于全国GDP,据称是统计口径的差异造成的,其他数据如人口等也有类似情况,对各省的计算造成困扰。国家需要不断完善统计工作,实现统计数据的科学化、规范化,为科学研究打下良好的基础。
第三,注重人力资本投入,增加教育投资。从CD生产函数法计算潜在产出的过程来看,劳动力和资本是产出水平的重要决定因素。我国长期以来经济增长主要靠投资拉动,因为这是最容易控制的经济增长因素。但人力资本的投入其实就像马车的另一个轮子,没有它经济就不能顺利前进。而且人也是科技发展水平的重要推动力,而科技水平也是潜在产出的重要参数。
[1]、[7]颜双波,张连城.潜在产出与产出缺口的界定与测算方法[J].首都经济贸易大学学报,2007(1):42-48.
[2]王兴华.我国潜在产出测算及因素分析[D].北京:首都经济贸易大学,2008.
[3]李文芳,方伶俐,凌远云.两类潜在产出估计方法的优缺点比较[J].知识丛林,2006(6):143-144.
[4]李文芳.潜在产出测算研究[D].武汉:华中农业大学,2006.
[5]、[6]胡乃武,刘睿.潜在产出估计的文献综述[J].山西财经大学学报,2004,26(6):4-6.
[8]、[9]、[13]张军,章元.对中国资本存量 K 的再估计[J].经济研究,2003(7):35-43.
[10]、[12]郭庆旺,贾俊雪.中国潜在产出与产出缺口的估算[J].经济研究,2004(5):31-39.
[11]刘本盛.中国经济区划问题研究[J].中国软科学,2009(2):91-90.
猜你喜欢
今日农业(2021年6期)2021-06-09
江苏地方志(2021年1期)2021-03-25
支部建设(2020年30期)2020-12-18
房地产导刊(2020年5期)2020-06-24
中国交通信息化(2019年10期)2019-11-16
中国交通信息化(2019年12期)2019-08-13
中国交通信息化(2019年3期)2019-06-18
中国公路(2017年5期)2017-06-01
中国卫生(2015年9期)2015-11-10
东西南北(2015年9期)2015-09-10
