
一种基于热平衡分布机理的负载调度策略
2012-05-17 11:56:14王东光邓见光
湖南人文科技学院学报 2012年2期
刘 霖 ,王东光, 邓见光
(1. 湖南人文科技学院 计算机科学与技术系,湖南 娄底 417000;2.东莞理工学院 工程研究所,广东 东莞 523808)
温室效应的加剧以及服务器持续增长的能耗使节能成为研究的热点[1]。高性能服务器通常采用多CPU,CPU工作时产生大量的热量影响系统的稳定同时引起能耗增加,造成性能下降[2]849-852,为了维持服务器的工作需要冷却系统把产生的热量带走。
风扇冷却系统是服务器中广泛使用的冷却方案,它使用对流传热原理,通过温度传感器调节风扇转速而带走服务器产生的热量维持系统工作稳定,风冷系统中风扇的转速与功耗成立方关系[3],高端服务器中风扇消耗的能量已经超过服务器总能耗,统计表明达到51%以上[4],如IU机架服务器达到80w, 2U机架服务器上风扇消耗达到240W,同时不断增加的风扇转速造成了工作环境中的噪音与机器的震动,故使用某种方式在不影响服务器性能的条件下优化风扇冷系统具有积极的意义。
操作系统(OS)通常使用动态负载平衡策略(DLB)动态迁移线程均衡任务后高效利用资源[5],但此方法未考虑热量分布,造成了各个内核热量分布的不均匀性,加大了冷却开支。
为了进行温度控制,动态热量管理(DTM)被广泛关注,reactive技术使用一个温度门限值,通过此门限值控制风扇转速,不过此技术功耗效率不高,文献[6]提出了温度预测迁移技术,它们能预先预测温度发生与迁移情况,虽然此方法相对准确但适应性学习期间不能进行预测,同时此技术为单CPU设计并且动态冷却没有足够精确的被模拟。本文使用一种全新的温度预测原理,快速而准确的进行温度预测,提出一个多层预测负载调度算法,克服传统DTM的不足,在不影响服务器工作前提下显著降低系统能耗。
一 热平衡机理调度策略设计
(一)风扇冷却系统优化原理
风扇冷却过程中带走的热量随风扇的转速增加而增加,风速转速与其消耗的能量成指数级关系,因此为了更好的节省能耗,希望CPU中热量产生的比较平衡,同时在CPU内部热量分布同样比较均衡,这样能使风扇平均转速较少冷却系统消耗更少的能量。执行这些优化需要在socket间进行智能化的工作分派,也能减少温度通过在热核与冷核间进行负载迁移,因此本案优化风扇能耗的原理是在内核级与socket级间进行基于热量的任务调配,从而使热量平衡分布,最大限度的平均风扇转速,在不影响系统性能的情况下以较低的冷却能耗去维持系统正常工作。
1. socket 级优化
在socket级管理工作调度,在每一个调度期间收集温度,性能,风扇转速等信息,通过均衡技术与微调技术而降低风扇的转速。
均衡技术的目标在平衡socket间的功耗不平衡性,使socket间的温度平衡产生一个更统一的风扇速度分布;微调技术目的是当负载基本平衡时在小范围内的子集内进行负载调度而消除热子集从而使风扇的平均转速最小而降低能耗。
2. 内核级优化
内核级减少单个套接件的温度,内核级策略使用预先热量管理,使用一种新的温度预测方法具有预测代价低准确度高等优点,依据预测的结果把线程从热点迁移到最冷内核,这样平衡了各个内核之间的温度。它们由操作系统进行调度,调度时间在毫秒级之间,因此相对于高级调度时间可以忽略不计,对系统的稳定性没有影响。
(二)内核级调度设计与实现内核级策略思想
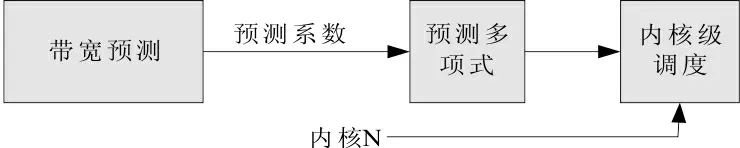
图1 内核级调度原理
温度的预测使用异于传统的新方法,传统方法基于时域,对性能产生影响,我们的方法使用的是热量与频谱固有的物理规律进行温度预测,因此预测方法对工作集来说是独立的,预测参数能在设计阶段被精确的估计出来,并且进行预测时几乎不要额外的代价。操作系统中执行的内核级线程迁移开支仅仅只有微秒级,比处理器为了节能而进入低能耗状态微小的多,迁移费用主要来自线程状态的转换与私有cache的准备。
1. 温度预测
温度预测是内核级调度的基础,温度预测器的基本思想是有限带宽信号与热量存在固有的关系,只要求出预测系数,就能方便预测出对应工作产生的热量,在设计阶段求出预测系数或者使用自适应函数[7]可以预先得到热量分布情况。
使用电功原理可知温度能模拟成一个RC网络[8],单个模具组件的温度能被模拟成一个简单的低通RC过滤热阻,连接到相邻单元,温度频谱范围可以通过RC网络分析或者计算机辅助设计工具进行计算。对于高端CPU可以忽略水平热阻的影响而进行简化处理,因为它们的值比水平值高很多[9],温度频谱范围可以模拟成如下形式:
(1)
其中T(ω)代表的是角频率的函数,τc是等于RC的内核温度常数,给定温度下是一个低能滤波器,它满足有限带宽限制条件,文献[10]88-91指出带限信号能用如下的线性方程进行预测:
(2)
an是预测系数,tn代表的是第n个时间点,N代表样本数为N,在均匀采样的条件下,如果用ds表示采样间隔,那么有tn=t-nds,为了能进行预测应用,估计误差必须足够的小,使佩利-维纳定理与施瓦茨公式误差的边界可以由(4)进行表示。
(3)
(4)
(5)
(4)中f是频率,W是赫兹频率带宽。等式第一部分代表信号能量,第二部分是预测误差和,(4)可以写成如下形式:
ε2≤x2εIεI是误差,x2是信号能量
误差积分代表的是一个预测系数的N维函数E(a1,a2,…,aN)通过最小化εI能得到BLP系数,为了得到优化系数,使用特征向量优化方法,文献[11]指出误差积分部分可以表示成如下的形式:
εI=vTΩv
(6)
V是一个有N+1个元素的向量,为了满足此式,向量V须有第一个元素v1=1,矩阵Ω可以表示为:
B是一个N个组件的向量,D是一个N(N矩阵,b与D能通过最小化误差而得到[12],对于误差系统方程如下:
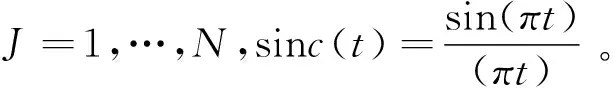
S(t)=sinc(2Wt)。sinc(t)是偶函数所以矩阵Ω是对称的,矩阵是正定的故所有特征值也是正数,最小预测误差下的优化预测系数能得到,通过最小化的vTΩv在所有可能的向量空间中的v1=1, 对于这个归一化长度为一的特征向量集,矩阵Ω的最小特征值决定了这个向量,设V为对应最小特征值的特征向量,对于此选择的特征向量有vTΩv等于最小的特征值,规一化特征向量,依特征化向量的定义有vnor=v/v1,有预测系数为:
ai=vnormi+1
(7)
(7)指出了预测系数只与信号带宽有关,对于无效分布的例子,预测上界dP能够通过奈奎斯特条件得到有2dpW<1,温度的频谱带宽依据的是τc,提取τc可以简单地在设计时得到使用的芯片布局和封装的热参数[2]852-861。
文献[10]88-93给出了预测距离ds的计算方法与证明。整个温度预算的流程是在设计过程中使用(7)计算设计系数,收集进行温度预测的样本点并且应用方程(2)进行温度预测,因为计算预测多项式的时间可以在几个指令周期完成,因此可以认为预测的开支可以忽略不计。
2. 内核级预测管理(CPTM)
使用基于预测器得到的温度预测进行工作迁移,把热点内核的工作迁移到冷内核。迁移的启动由热核的预测温度门限值与冷热核温度差决定。如果冷核也在执行过程中,在冷核与热核之间进行任务交换。对于即将到来的工作负载,策略使用预测结果找到可用的冷核并分派它进行使用,算法伪码描述如算法1:
Algorithm 1: CPTM
计算所有内核热量T,记最大为Tmax,最小为Tmin
While(未标记的内核数>1 and Tmax>Tcand 温度差
大于门限值)do
预测最热内核corehot
预测最冷内核corecold
If 最冷内核为空闲状态then
迁移最热内核到最冷内核并做标记
Else
交换最热内核与最冷内核并标记
Endif
从没有标记的内核中重新找出Tmax,Tmin
Endwhile
把新任务指派给能用的最冷内核
(三)socket级调度设计与实现
本级调度的目的是希望各CPU有均衡的温度分布,由两部分组成:平衡与微调。
1. socket级冷却子系统
冷却子系统能通过智能化的在CPU各个socket之间分配任务而降低能耗。
有两种类型的情况,如果是多个socket之间的消耗的功率不平衡,进行平衡调度节省能耗时被称为“平衡”(blance);不妨假设socket1处的冷却气流是socket2气流的两倍,为了降低平均空气流速,从Socket2中交换两个中等规模的线程与socket1中的最热线程进行交换,因为新移进来的热线程与已经存在的最热线程功耗相当,所以并不会增加Socket1的最高温度,但是会降低Socket1的平均温度,因为消耗的总功耗在减少,我们把这类调度称为微调策略。(consolidation)
2. 状态空间控制器与调度
调度的第一个阶段主要是在不同的CPU之间进行负载调度以保证各个CPU消耗的功耗尽量相当。通过平衡风扇转速,风扇转速与能耗成立方关系,从而可以使风扇消耗的功耗变小。如果用ccost表示风扇消耗的功耗与平均功耗之差,那么有如下关系式:
(8)
为了设计控制器,对CPU在特定时间与环境温度瞬时值有如下关系:
(9)
其中τca为时间常数,pcpu(t)代表的是时刻t的瞬间CPU功耗,对于多个CPU对于上式进行向量化有:
(10)
其中Y,Z均为对角矩阵,其对角元素分别对应于(6)中的分母值的具体化,持续系统可以用如下的离散化等式进行描述:

(11)
反馈控制控制规则可以表示成为:
Pcpu(k)=-GTca(k)+G0Tref(k)
(12)
此处Tref为目标温度
Tref的计算可以通过基于当前风扇转速与目标风扇转速的差异而得到,Tref由两部分组成:
Trefi(k)=Tcai(k)+ΔTcai(k)
(13)
Tca通过附着在散热器上的传感器得到,ΔTca代表了当前风扇转速与目标转速,即环境热阻,因此可以由欧姆定理方便的进行估计,因此最后的结果可表示为:
(14)
通过对(11)的进一步计算可以得到每个CPU状态空间时间常数为:
(15)
此式说明瞬时时间是采样时间与控制特征值λi的函数,因为散热器的温度变化比较慢,因此时间常数可以设置在秒级的范围内,从而使控制变的平稳而有效。
3. CPU socket级调度策略(SLS)
用ΔPCPU表示功耗差,Pthr表示线程在CPU的功耗,Smin表示的是一个门限值,算法描述如下:
Algorithm 2:socket level scheduling
计算每个cpu对应的ΔPCPU、Pthr、设置空队列Q
负载均衡
for i 在未标注的cpu集中do
for j 在第i个CPU中的线程执行
dest←最大的ΔPcpu的标记索引值
if Pthrj<-ΔPcpuior Pthrj<ΔPdestthen
If CPUdest有闲内核且无内核级迁移 then
计算迁移线程j到CPUdest后节能值
Else
把j线程与与CPUdest中未标记的最冷线程交换并计算冷却系统节省的能量
Endif
If 冷却系统节能大于Smin那么
此迁移事件记录在队列Q中并且标记
迁移线程
更新ΔPcpu与线程指派
标记CPU i 和dest
End if
End if
End for
End for
微调策略如下:
While ( 未标记的CPU数大于一时) do
h←最大风扇转速的未标记的CPU的索引
if (风扇有不同的速度) then
L←主风扇对应的未标记的CPU的索引
Else
L←未标记的CPU中除去H后的索引
End if
在L对应的CPU中找到最热的线程hl;
从H中找出找出所有线程功耗小于Phl的线程组成一个最小线程集(Scool),此集的总功耗大于最热线程消耗的功耗,然后标记此CPU;
If Scool集非空 then
计算从Scool中线程与hl线程交换后冷却系统节省的能耗
If 节省的能耗大于Sminthen
此迁移事件记入队列Q中,标记L对应的CPU,更新线程指派
End if
End if
End while
执行队列Q中的所有迁移事件。
二 实验验证
为了验证内核级方法(CPTM)的效果,在单一socket中执行混合负载,设置本地环境温度为摄氏42度,用CRTM,DLB策略与新方案进行比较,实验结果如下(图2):
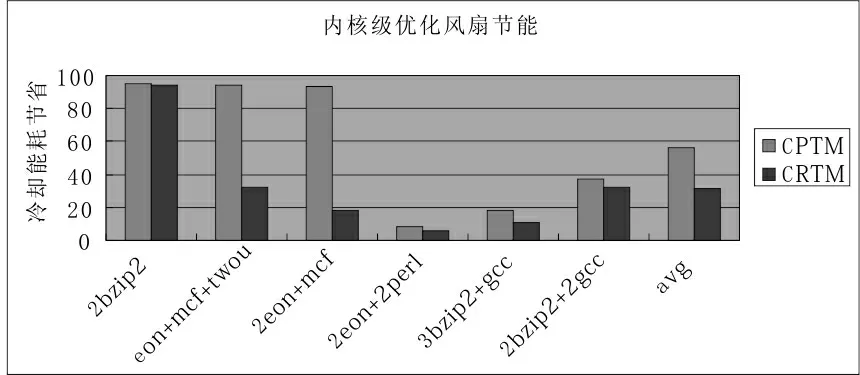
图2 CPTM测试
有如下结论:CPTM策略优于CRTM超过传统的策略,平均节能达到DLB的56%,由减少风扇转速而得到。冷却系统在负载较轻时以及负载差异较大时冷却风扇节能优化效果更明显,因为在低负载时有更多的冷内核用于平衡热内核的分布,如在处理器利用率50%的2bzip2基准测试中新方案的冷却系统优化达到95%;组合负载2eon+mcf代表的是CPU密集型与存储器密集型负载集,当他们的负载达到75%时新方案冷却优化能达到93.3%;2perl+2eon组合代表的是CPU密集型负载,因为内核基本处于工作状态,此时冷却系统能耗基本没有得到优化。据此CPTM达到预期优化效果。
把内核级与socket 级调试综合称为MTTM,为了检验其效果使用有各种温度分布与线程利用率的工作集组合(表1)。
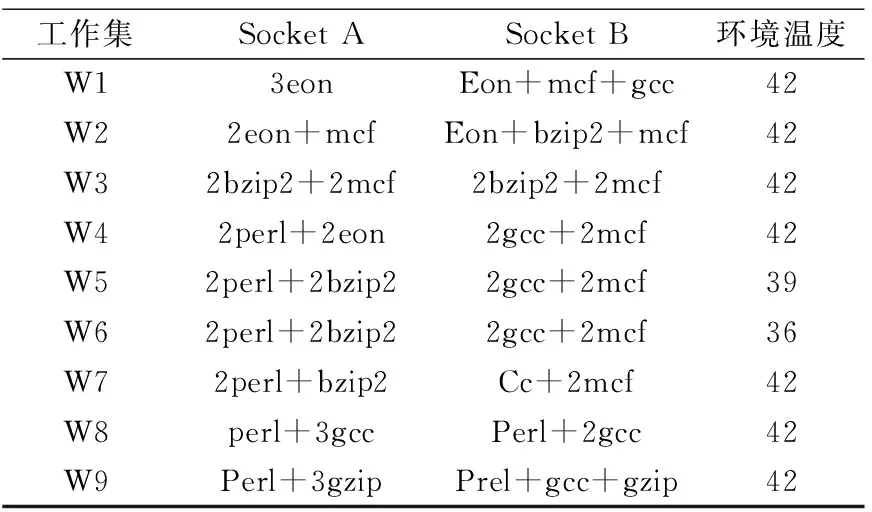
表1 实验工作集
为了评估MTTM的效果使用各种热量值与CPU利用率不同的基准测试集组合成复合负载进行测试,参与实验的策略是CRTM, CPTM, MTTM与经典DLB策略进行比较,实验结果(图3)。
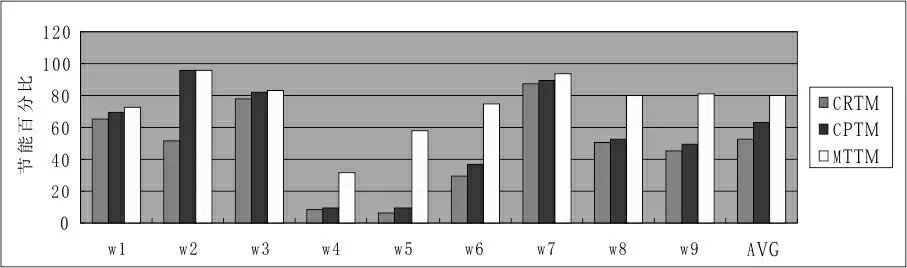
图3 MTTM策略测试
有如下结论:本方案对冷却系统的能耗节省超过其它方案,并且明显效果优秀;平均改善情况超过DLB达到80%,主要原因是来自于socket级的平衡调度与微调策略以及内核级的主动线程迁移。实验结果中的W5工作集由于工作集在Socket之间的迁移,负载socketA有较高的功耗密度而SocketB保持的是中等功耗密度,此时只通过单纯的内核级线程迁移不足以产生冷却能耗的节省,但在两个socket之间进行平衡调度能平衡温度分布,因此节省58%的冷却能耗;而W8与W9对能耗的贡献主要来源于微调作用,在W8新策略用两个gcc 与perl进行交换,当socket级调度不再有作用时微调发挥作用而降低冷却系统的能耗。
三 结论
高端服务器产生了大量的热量,冷却系统需要消耗大量的能量以维持服务器正常工作的环境,已有的研究通常针对单一Socket情况并且没有对冷却系统动态能耗控制进行精确模拟或者提供冷却优化时以牺牲服务器性能为代价。本文提出一种多层次的工作调度策略,通过此策略在多Socket CPU平台上平衡热量分布,降低最高温度的出现,从而减少风扇转速而降低能耗,同时基于带宽与热量的规律提出的预测机制预测时几乎不占用系统开销,为策略的有效实现奠定了基础。实验表明新方案优于现行的优化策略,可以提供高达80%的冷却能耗节省率,是一种较好的优化策略。
参考文献:
[1]刘发贵,吴泽祥,麦伟鹏. 一种硬盘动态电源管理方法[J]. 华南理工大学学报, 2010, 38(1): 97-101.
[2]AJAMI A, BANERJEE K, PEDRAM M. Modeling and analysis of nonuniform substrate temperature effects on global ULSI interconnects[J]. IEEE Trans on Comput-Aided Design Integr. Circuits System, 2005, 24(6).
[3]PATTERSON M. The effect of data center temperature on energy efficiency[C]. 2008 11th IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems, I-THERM. FL, United states, 2008: 1167-1174.
[4]LEFURGY C, PAJAMANI K, RAWSON F. Energy management for commercial servers[J]. IEEE Comput, 2003, 39(12): 39-48.
[5]CHOI C, FRANKE H, WEGER A, BOSE A. Thermal-aware task scheduling at the system software level[C]. ISLPED'07: Proceedings of the 2007 International Symposium on Low Power Electronics and Design. United states: Portland, OR , 2007: 213-218.
[6]COSKUN A, ROSING T, GROSS K. Proactive temperature management in MP SoCs[C]. ISLPED'08: Proceedings of the 2008 International Symposium on Low Power Electronics and Design. India: Bangalore, 2008:165-170.
[7]MUGLER D. Computationally efficient linear prediction from past samples of a band-limited signal and its derivative[J]. IEEE Transaction on Information Theory, 1990, 36(3): 589-596.
[8]SKADRON K, STAN M, HUANG W, VELUSAMY S, SANKARANARAYANAN K, TARJAN D. Temperature-aware Microarchitecture[C]. Conf Proc Annu Int Symp Comput Archit ISCA . United states: San Diego, 2003:2-13.
[9]HEO S, BARR K, ASANOVIC K. Reducing power density through activity migration[C]. Proceedings of the International Symposium on Low Power Electronics and Design. Korea: Seoul, 2003: 217-222.
[10]MARVASTI F. Nonuniform Sampling Theory and Practice[M]. New York: Kluwer academic/Plenum publisher, 2001.
[11]MUGLER D, WU Y. An integrator for time-dependent systems with oscillatory behavior[J]. Comput on Methods Appl Mechanic Eng, 1999, 17(1): 25-41.
[12]MUGLER D. Computational aspects of an optimal linear prediction formula for band-limited signals[J]. Comput Appl Math, 1992, 21(1): 351-356.
猜你喜欢
现代装饰(2022年4期)2022-08-31 01:41:24
今日农业(2021年9期)2021-07-28 07:08:36
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
信息安全研究(2018年12期)2018-12-29 11:01:56
环球市场(2017年36期)2017-03-09 15:48:21
个人电脑(2016年12期)2017-02-13 15:24:40
电子制作(2016年19期)2016-08-24 07:49:54
电子世界(2015年22期)2015-12-29 02:49:44
电源技术(2015年11期)2015-08-22 08:51:02
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
