
一种基于规则的桌面搜索索引机制
2012-05-08 04:41苏金波叶红
电脑知识与技术 2012年7期
苏金波 叶红
摘要:Google,百度,MSN和其他一些工具提供了强大的Internet,桌面搜索功能,为用户查找信息提供了便捷,但这些搜索工具并不关心数据本身的结构和语义,搜索结果常有用户不关心的垃圾数据,而一些有用的数据却不能列出。该文探讨了一种基于规则,将数据的结构和语义考虑在内的桌面搜索索引方法。该方法首先对原始数据进行规范化,然后根据一系列的规则对规范化数据创建索引文件,通过该方法可获得更好的搜索结果,而且该方法可通过扩展应用到其他领域。
关键词:规则;谓词;桌面搜索;索引
中图分类号:TP393文献标识码:A文章编号:1009-3044(2012)07-1521-03
A Rule-based Method of Index in Desktop Search
SU Jin-bo, YE Hong
(Department of Computer Sci., Anhui Univ., Hefei 230039, China)
Abstract: Google, Baidu, Msn and other products provide users powerful way of searching for information on the Internet, desktop. But these facilities dont care the structure and semantics of data, the search results often include what users dont want,some data which users care can not be listed. This paper discusses a new method of index in desktop searching, it fully exploits the structure and semantics of data, this method firstly normalize the raw data,create index files based on some rules. With it, better search results can gained, and the method can be applied to other domain with some extension.
Key words: rule; predicate; desktop search; index
一些诸如Google,百度,MSN等搜索工具可以方便用户在Internet,桌面上搜索自己感兴趣的资料。这些工具一般是利用倒排文件,将用户可能用到的关键字和相关文档关联起来,通过这些关键字用户可以很快找到对应的文档。但是这种索引机制并不考虑数据本身的结构和语义,所以在桌面搜索[1]中,搜索结果往往包含大量用户不关心的文档,或是一些该被找到的文档却被遗漏。本文讨论了一种扩展的倒排索引机制,该机制基于规则对原始文档进行规范化,能够把数据的结构和语义[2]也考虑在内。通过它可以获得更好的搜索结果。
1问题举例
以图1会议室预定系统为例,当邀请者创建一个预定,把被邀请者加入、填写会议时间和地点后,系统自动生成一个邀请函并通过Email发送到被邀请者的邮箱中,假设邀请函以图2的XML[3]文档表示。本文讨论的皆以XML表示,非XML表示的文档都可以通过接口转换成XML文档。

图1会议室预定系统

图2邀请函原文档
其中<被邀请者/>记录在另一个XML文档:

图3被邀请者XML文档
如果用不考虑数据的结构和语义的传统搜索算法[4],用户输入“张三”进行搜索,那么图2所示的文档不会被列出,因为它并没包含“张三”这个关键字,但用户却希望能看到图4所示的搜索结果(因为“张三”是被邀请者之一)。类似的,如果用户输入“402”关键字,图2文档就会被找出,因为包含了“402”这个关键字,但这个结果并不是用户关心的(因为会议是在401室开的,而不是在402)。

图4邀请函实例
图4是图2文档的一个实例,其中的<被邀请者/>被“替换”成实际的值:“张三,李四”;会议室402也从文档中删去。类似的对原始文档实例化的例子还可以举出很多,比如“限定”条件(在某些条件下成立,某些条件下该被删除)。
这个例子说明如果不考虑数据的结构和语义,在桌面搜索中,一部分用户想要的结果就会被漏掉,或者一些不需要的结果就会被搜出。为了提高桌面搜索结果的准确性,本文接下来讨论了一种扩展的索引机制。
2扩展算法
传统的索引是基于原始数据创建倒排文件[5][6]的,为了能将数据的语法语义也考虑在内,我们对传统索引方法进行扩展,首先基于一系列的规则,对原始文档进行变换,生成包含数据的结构和语义信息的规范化文档。然后基于规范化的文档再生成倒排文件。整个扩展索引机制的结构图如图5所示。
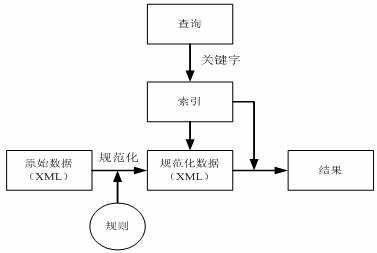
图5扩展索引机制的结构图
规则是规范化的基础,用以说明原始文档该如何被规范化,规则以XSLT[7-8]和XQuery[9]表达式构成。由于应用程序的开发者和使用者最清楚原始数据的结构和语义,规则的定义可由他们编写完成。图6是前面例子用到的两个规则。在实际应用中还可以对规则库进行修改和添加。
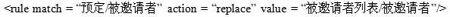
图6“替换”规则
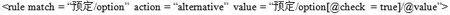
图7“选择”规则
match属性用XPath[10-12]指出原始XML文档哪些部分需要被应用规则,action属性指出规则的策略。不同的規则可以有不同的属性,图6中的value属性指出被替换的值。下面对规范化和扩展索引的创建算法进行描述。
2.1规范化
所谓的规范化就是根据规则,在原始数据的基础上把所有可能的实例全部生成出来,如前面例子中由图2生成图4的过程。规范化过程分以下两步:
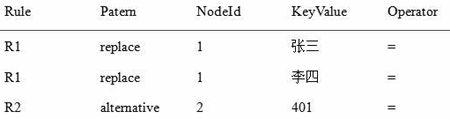
1)构造标记表(d, R)(d:原始文档,R:规则)
目的是用来标记原始文档中哪些元素必须被打上“select”和谓词(predicate)标记,其中predicate谓词属性是用来说明元素所受到的约束。
①对于匹配规则r∈R的每个节点n∈d,向表T中加入一条记录t,使得t.Rule←r,t.Pattern←r.Pattern,t.NodeId←n。
②根据规则中的value属性对节点n进行求值,并设置t.KeyValue和t.Operator。前面的例子的标记表如表1所示。
表1图2对应的标记表
2)规范化原始文档
扫描标记表,如果是replace类型的规则,在t.NodeId指向的节点外加一个select节点,该节点的predicate属性为t.Rule t.Operator t.KeyValue;如果是alternative规则,将满足条件的option节点用t.KeyValue代替,其余的option节点全部删除,规范化的文档如图9所示。对于其他规则,可以根据语义添加select和谓词(predicate)属性。
因为规则是以XSLT和XQuery表示,所以规范化过程可以由程序自动完成。具体见文献[7-9]。

图9规范化后的文档
2.2索引创建
和传统搜索索引创建方法类似,只是不再基于原始文档,而是基于规范化后的文档创建倒排文件,创建步骤如下:
1)如果关键字不在select元素内,则把该关键字加到倒排文件中,且predicate设置为true(表明该关键字在任何条件下永真).
2)如果关键字在select元素内,则加在倒排文件中的predicate属性值根据规则的约束来定,比如在图2例子基础上再加上一个约束条件:如果时间是上午(time<=12.00)用401会议室,如果是下午(time>12.00)用402会议室,那么倒排文件表如表2所示。
表2扩展的倒排文件
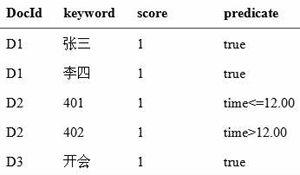
其中添加了Score这一列用来记录该关键字出现的次数,也可以是其他一些信息,搜索结果可以根据score进行排序。
搜索过程和传统的搜索方法一样,以给定的关键字,通过扫描倒排文件,如果找到相关记录,根据predicate条件判断是否为真,如果为真便可以找到规范化的文档。因为这些规范化的文档就是所有原始文档可能生成的所有实例,所以通过这样的索引机制可以给用户提供更准确的搜索结果。对于详细的搜索过程,不是本文重点,可参考相关文献[5-6]。
3结束语
传统的桌面搜索方法不考虑文档所包含的结构和语义,搜索结果常带有垃圾文档,或是用户关心的文档却未找到,本文对传统桌面搜索索引进行扩展,添加一系列规则,用以对原始文档进行规范化,基于这样规范化的文档构建起来的倒排文件,包含原始文档的结构和语义,可以为用户提供更好的搜索结果。这种索引机制还可以通过扩展应用到其他领域。
参考文献:
[1]向凯全,王盼卿,陈军广,等.装备领域中语义桌面上的个人主观本体研究[J].计算机技术与发展,2011,21(8).
[2]邓辉文.离散数学[M].北京:清华大学出版社,2010.
[3] W3C.Extensible Style sheet Language (XSL)[EB/OL].[2001-10-15].http://www.w3.org.
[4] Cormen T H.算法导论[M].北京:机械工业出版社,2006.
[5]王能斌.数据库系统教程[M].北京:电子工业出版社,2002.
[6]数据结构[EB/OL].http://www.xjife.edu.cn/teacher/wjj/DataStructure/web/wenjian/wenjian10.6.1.htm, 2002.
[7] XSLT 2.0 and XQuery 1.0 Serialization[EB/OL].Second Edition. [2010-12-14].http://www.w3.org/TR/2010/REC-xslt-xquery-serialization-20101214/.
[8]洪新华,夏群兵.XSLT在XML文档中的应用研究[J].电脑知识与技术, 2009(5).
[9] Word Wide Web Consortium. XQuery 1.0 and XPath 2.0 Formal Semantics [EB/OL]. http://www.w3c.org/TR/query-semantics/, 2002.
[10] XML Path Language (XPath) 2.0[EB/OL].[2010-12-14].Second Edition.http://www.w3.org/TR/2010/REC-xpath20-20101214/.
[11]郭太飞,何洁月.归纳学习XPATH Web信息提取规则[J].计算机技术与发展, 2007,17(3).
[12] Deitel H M.Java Web Services for Experienced Programmers [M].北京:机械工业出版社,2003.
猜你喜欢
现代哲学(2023年3期)2023-10-27
数学小灵通(1-2年级)(2021年4期)2021-06-09
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
幸福(2018年33期)2018-12-05
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
中国科技信息(2016年14期)2016-07-31
外语学刊(2016年4期)2016-01-23
