
基于Web挖掘的化学物质信息提取应用研究
2012-05-04 08:07:54李书琴杨会君
计算机工程与设计 2012年8期
冯 硕,李书琴,杨会君
(西北农林科技大学 信息工程学院,陕西 杨凌712100)
0 引 言
Internet作为世界上最大的信息资料库,已经成为化学工作者快速获取信息的主要途径。然而Web信息的急速膨胀,对化学工作者如何大规模的获取和有效利用分布在Internet上的化学资源方面提出了一个巨大的挑战[1]。解决这一问题的基本思路是建立网络资源与其网址的索引[2]。目前在化学领域已经建立起了几个比较有代表性的化学资源导航系统[3-4],虽然已有了以上诸多的的Internet化学导航系统,但其目前主要靠人工来搜集资源[1]。如果单纯地采用人工方式去查找和处理信息,会对人力资源大大浪费。而且当信息源站点数据更新后,靠人工发现非常困难,而且更容易出错。为此,希望能有一套计算机软件系统自动地持续地获取国内外一些权威的网站中化学物质的相关数据,从而提高信息获取的效率和数据的准确性。在计算机领域,基于Web信息挖掘技术日益成为人们研究的热点问题[5]。现有的Web信息提取方法包括基于自然语言方式、基于包装器、基于Ontology方式、基于HTML(hypertext markup language,HTML)结构、基于Web查询等信息抽取方法,但无论是自然语言处理还是包装器技术,只是针对一个特定的信息源,一个特定主题和领域[6],目前在很多行业和领域都可以看到垂直搜索引擎的应用研究,然而在化学领域应用较少。
本文在研究现有抽取程序的基础上,实现自动抽取指定网站中化学信息并集成到数据库,以解决人工手动获取信息效率低下和准确率低等问题。主要研究如何对多信息源网站中化学物质信息的获取与集成、构建信息全面准确的化学物质信息数据库,为建立新化学物质生态危害影响模型与预测评价体系准备基础数据。本文将根据系统结构组织分3个层次,即业务层、数据访问层、交互层,本文首先介绍数据获取与预处理,它属于业务层,是系统的核心;然后介绍数据查询和更新,它包括数据访问层和交互层:数据访问层主要是操作数据库和一些可复用的工具类,交互层主要是系统与用户的交互界面。
1 数据获取与预处理
数据获取与预处理的目标是从国内外一些权威的网站中抽取化学物质的基本信息及其相关属性如熔沸点、降解性、BCF (bioconcentration factors,BCF)等结构化数据,这些结构化数据存储在统一的数据结构中,从而实现异构数据的统一。主要模块包括网页获取、信息抽取、数据预处理和任务调度。
1.1 数据的动态获取
网页获取与信息抽取是数据获取的两个核心模块,为动态获取网站中的化学物质信息,本文提出任务分割、重试机制、动态更新检查等一些相关技术。
1.1.1 网页获取
通过对所选信息源网站进行分析,发现大部分网站的网页属于动态网页,个别属于静态网页,静态页面的URL(universal resource location,URL)直接以 HTML超链接形式嵌在客户端网页的HTML文件中[7]。
针对静态网页,根据聚焦爬虫[8-9]技术,分析要抓取页面的特点,在描述和定义抓取目标的基础上,根据网页内容进行分析,收集跟主题相关的网页,然后对该网页进行解析,提取将该网页中的URL保存到预先设定的队列中。然后,根据基于内容评价的搜索策略[10]从该队列中选择有用的链接,并将页面保存到本地,然后重复上述过程,直到该网站中所有相关的网页均被下载为止。所有被爬虫抓取的网页将会被系统存贮。具体流程如图1所示。
而动态网页,一般是由预定义的模板或服务器端脚本,通过临时填充后台数据库中的信息生成[11]。一般搜索引擎不可能访问到一个动态网站中全部网页。所以本文根据网页的特点模拟人工点击浏览过程,通过提交表单、建立会话,获得网页。
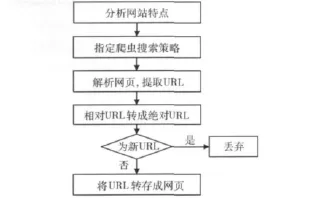
图1 静态网页获取流程
动态网页获取的具体流程:首先通过对所选择的几个动态站点进行分析,找到数据所在的网页,以及这些网页的拓扑结构,然后对网页的源代码进行解析和对JavaScript脚本语言分析,动态生成URL,获取该网站的Cookie,建立http会话,进而读取相关的页面,最后将抓取到的页面存储到本地磁盘。为了避免耗费不必要的时间无限制地等待响应缓慢的服务器或者规模庞大的网页,因此设置了超时机制。如果一个网页在15s内不能下载,则需要重试下载。对于具体网址只会重新下载3次,如果3次都不能下载,则不再下载该网页。具体流程如图2所示。

图2 动态网页获取的流程
1.1.2 信息抽取
对网页信息进行结构化信息抽取,也就是从网页的非结构化、半结构化数据中抽取出结构化数据。对所选信息源网页面进行分析,发现页面中数据属于半结构化信息,因而本文采用基于包装器的信息抽取技术[12],抽取相对结构化的数据。而包装器就属于结构化信息抽取技术中基于模板的方法,由一系列的抽取规则[13]以及应用这些规则的计算机程序代码组成,将同一类网站中的特定数据按要求提取出来。本文根据数据项左右边界来定位数据项,实现对不同信息源信息的抽取。本文主要根据对网页信息特点和html语言的分析,生成html的DOM (document object model,DOM)树,通过对DOM树结构和目标数据项所在位置进行分析,根据DOM树中对应的节点确定目标数据项的定界符——即对感兴趣语义项的上下文描述[14],从而该数据项被唯一确定。尽可能找到所需数据对应标签的id等能够唯一标识该数据的属性,或其标签的父亲、兄弟或孩子结点从而间接的找到本文所需的数据项。以从The NCLASS Database on Environmental Hazard Classification中取得物质的CasNo(化学物质登录号)为例。观察下载的html源码发现CasNo包含在如图3所示的代码中。

图3 网页源码
需要提取这个代码片段value中的字符串,首先根据“id="txtAllCasNumber"”得到包含CasNo字符串的元素<input>,然后通过value得到该属性的值"1333-74-0"即可得到此物质的CasNo,其伪代码如图4所示。

图4 获取CasNo的伪代码
1.1.3 大任务分割
本文选择的信息源数据比较多,如果采用一次性全部抽取的方法,必将给信息源站点带来巨大的压力,甚至有可能遭到封杀,而且这样方式任务粒度太大,不容易控制。本文将一次性大数据量抽取过程分为多次持续抽取过程。
经过观察分析,发现所选取的几个信息源网站有一定的共性,都有该网站包含总物质数,数据库端物质排序有规律等。因此,从开始抽取,每次抽取任务结束后都记录任务信息,下次任务开始时,读取任务信息,在上次的基础上继续抽取,这样就可以分多次持续并且无重复地进行对将整个数据库中的信息抽取出来,有效地避免了一次性全部抽取带来的问题。
为了持久化任务信息,本文定义了一个XML(eXtensible markup language,XML)文件保存抽取任务日志,每次抽取前读取历史任务信息,完成任务时更新任务信息,以保证任务信息是最新的。
定义XML日志中元素如下:
<pageCount>:记录信息源网站数据库中包含物质的总数;
<finishCount>:记录已抽取的物质总数,其属性time为更新该节点的时间;
<countOfTask>:为每一次调度抽取的物质数量;当信息源数据库剩余物质小于该数量时,按实际数量抽取;
<finishCountOfTask>:记录上一次抽取成功的个数;
<networkErrorUrls>:记录因为网络错误导致抽取失败的URL,下次调度时优先重试;
<pageStructErrorUrls>:记录因为网页结构错误导致抽取失败的URL,其属性repeatTimes记录重试次数,用于抽取监控;
<notExistErrorUrls>:记录因为URL不存在导致的抽取失败,用于抽取监控。
系统通过维护该XML文件就可以完成大任务的分割。
1.1.4 失败重试机制
Web信息抽取涉及到很多外在的因素,比如网络经常变化、网络连接失败,这些因素都可能导致抽取失败,有些失败可能只是偶然的,比如网络不稳定导致的抽取失败,在下次网络比较好的情况下,完全有可能重试成功。所以,失败重试机制的引入非常重要。
由于抽取结果不能是简单的成功还是失败,需要对抽取结果进行重定义,因为系统需要对不同的结果做出不同的反应,如网络错误系统需要重试抽取,结构错误系统需要监控报警等。本文根据需要定义Result储存返回结果。
Result数据结构包含了以下信息:
(1)返回结果码:定义成功、网络错误、URL不存在和页面结构错误四类结果码。
(2)获取数据:定义为一个Object,因为获取数据不一定是CompoundsDTO (定义的统一数据结构),还有可能是其他类型。在取数据时,应首先判断其返回结果码是不是为成功。
(3)url:本次抽取的URL,实际上是个处理对象,系统将直接对其进行处理。
(4)errorMessage:更详细的结果信息,一般出错时才设值。
重试机制的实现非常简单,在每次抽取任务调度时将抽取失败的URL存放到上节XML对应的URL列表中,在下次任务调度时首先取得需要重试URL列表,逐一重新访问抽取,如果成功,则保存到数据库中同时从XML文件中删除该URL,失败则更新该URL重试次数。
1.1.5 动态更新检查
信息源网站数据库更新包括两种情况:一是数据记录增加,增加一种新物质信息;二是修改原来的物质信息记录。
对于第一种情况,跟一般的数据抽取一样,抽取程序不加区别对待。
对于第二种情况,需要按抽取方式重新抽取数据,抽取数据后将化学物质的主要信息拼接,使用CRC(循环冗余校验码)对所得字符串进行编码。对于不同的内容,其编码结果不同,相同的内容编码结构相同。判断物质信息是否更新,只需将这个CRC和原始库中基本信息表中最高版本CRC编码对比,即可判断物质信息是否更新。如果该种化学物质有更新,将该物质信息存入原始库。简化了数据库操作。
1.2 数据预处理
由于互联网上的数据来自不同的数据源,存在异构,所以首要任务是设计一个统一的数据结构CompoundsDTO作为全局模式,将不同数据源中的数据映射到该全局模式中,然后将不同数据源的同种数据转换成统一格式,根据正则表达式和排序算法,提取出更为合理的数据进行集成。本文采用了一种最简单也是最合适的方式,即设计一组POJO(简单Java对象)来消除,这组POJO能完全表示一种物质,包括化学基本信息、理化性质、降解与蓄积性、生物系统效应、风险分类5个类,并将这5个类聚合到CompoundsDTO类中。本文将从信息源网站中获取到一种物质数据封装成一个CompoundsDTO对象,可以消除不同数据源之间的语义冲突,如生物降解性在http://apps.kemi.se/nclass/AllSubstances.asp 数 据 源 中 存 在“Yes”和 “No”两种描述,而在另一数据源http://cfpub.epa.gov/eco tox/advanced_query.htm 中使用 “Ready Biodegradab-ility”和 “Non-Biodegradability”来进行表达,本文统一成 “生物降解”和 “非生物降解”来描述,不但消除了异构,而且方便业务操作时的接口定义。
1.3 任务调度
任务调度模块是系统实现自动化的核心,系统将对各信息源网站的抽取工作通过接口的形式向外公布,如任务调度框架--Quartz调度。本文将抽取的大任务分割成多个小任务,在减小任务粒度的同时带来了如何保证数据抽取的连续性和可行性问题,由于数据抽取通常是一次性执行的任务,如果程序意外中断,程序就要重新执行,因而由大任务分割而成的小任务,也存在如何记录现场的问题,而Quartz的持久化机制能够保存任务调度现场的数据[15],从而保证了抽取的连续性,同时为保证任务的连续性和实时性,Quartz可以很方便地将这些任务制作成一个个的作业,然后设定它执行的时间规律[16]。本文是在Spring框架中进行任务调度的,首先要创建调度任务,将这些任务按照Quartz原则创建成Job作业。调用抽取服务接口完成抽取工作,并配置到SpringIoc中供触发器使用。然后设定执行时间,系统实现调度时选用的是Spring中提供的Cron-TriggerBean调度器,它可以精确的控制任务的运行时间。最后在Spring中创建调度器实例,将调度工作交给Quartz框架,然后随着SpringIoc的启动调度器也随着启动。
2 数据查询和更新
数据更新主要是将抽取数据进行预处理得到的最新数据存入数据库中,包括向数据库中动态添加互联网上新增的化学物质信息和修改数据库中已有的但发生变化的物质信息。数据查询就是为用户提供一个查询系统,用户可以查找到自己所需的化学物质信息。
2.1 化学品环境安全数据库系统框架结构和指标体系
化学品环境安全数据库包含了化学物质的基本信息、化学物质理化性质、降解性与蓄积、生物系统效应、健康毒性、风险分类6个表,各种相应的有关化学品环境安全所需的信息数据分别纳入相应的表中。化学品环境安全数据库系统的总体框架如图5所示。

图5 化学品环境安全数据库系统框架结构
化学品环境安全数据库中各表的数据组织分别如下:
化学物质的基本信息主要收集了各种化学物质的Cas号、英文名称、中文名称、分子式、分子量、结构式、SMILES表达式。用来对所收集化学物进行简单识别。
理化性质数据组织见表1。

表1 各种理化性质数据组织
降解与蓄积主要收集了化学品在各种环境介质中的行为参数方面的资料,在降解与蓄积表中,许多行为参数指标数据项中的数值均与测试时的环境条件或测试生物物种密切相关,因此数据表中添加环境条件、物质等属性,其数据组织见表2。
生物系统效应的数据组织见表3。
健康毒性主要收集了化学物质的致癌性、经口毒性、经皮毒性等43种特性信息。
风险分类主要收集了中国风险类别、美国风险类别、欧盟风险类别、PBT类别。
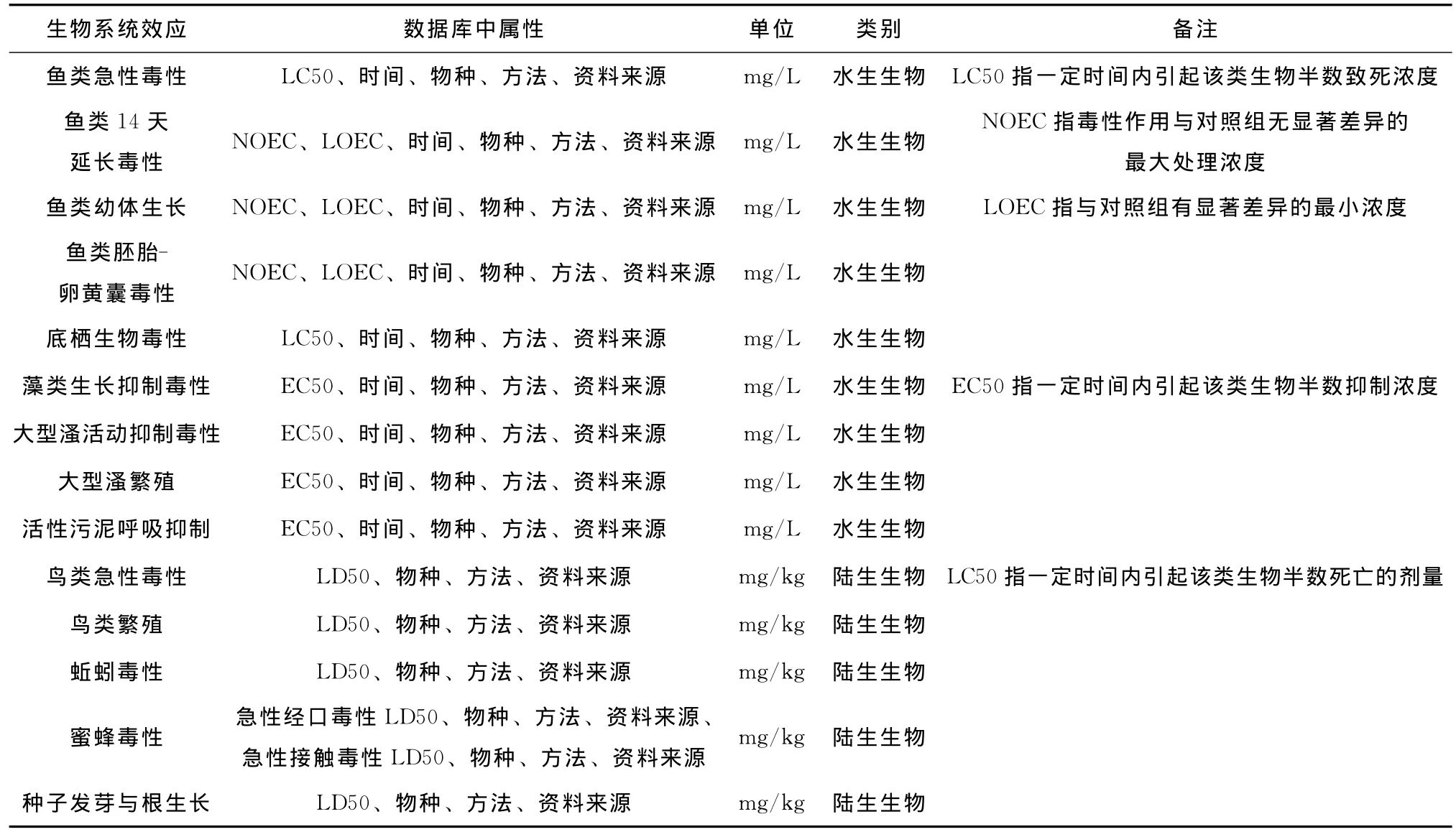
表3 生物系统效应数据组织
2.2 化学品环境安全数据库系统的更新与查询
数据访问层采用面向对象编程方法中常用的关系对象映射 (ORM)方式,并将对数据库的操作通过接口形式向外公布,方便外部使用。化学品环境安全数据库采用mysql完成。数据查询简单、方便,可以以单个casno为查询条件,并同时选择多个属性查询,显示基本信息和所选择的属性值;或以多个casno为查询条件,选择其一个或多个属性进行查询,以对比其属性值。在Spring中使用Ibatis进行数据库访问操作,首先配置SQL Map,包含了查询的sql语句及参数、结果形式;然后装配SQL Map,装载sql配置文件到Ibatis的执行引擎;创建模板类,创建Spring提供的SqlMapClientTemplate,并置入DAO对象;使用模板类操作数据库。
3 测试与结果分析
本文在设计时主要以可靠性和可用性为原则,所以在技术选择时,选择可靠的、简单的、主流的并且经过大量测试的工具,主流技术参考文档较多,出现问题能很快查阅看,而且主流的技术框架往往经过大量测试和实践验证,框架本身非常可靠;而简单是指接口封装好,层次清晰,使用简单,降低了开发和使用成本;在解析网页时,主要使用了Jsoup和HtmlParser两个开源工具。
本文从选定的信息源网站中随机选取了如表4所示的一些网页作为测试数据。然后在基本信息、理化性质、降解与蓄积、生物系统效应、风险分类这五类信息中各选择100个数据,再分别对网页中这100个数据和已抽取的数据进行比较,观察被准确抽取出的数据量,其结果如图6所示。
对结果进行分析,500个数据共抽取出来了472个,对于抽取出来的472个数据与网页上源数据进行比较,尚无错误数据。然后以一个网站为例对系统进行整体测试,其测试情况见表5。该网站共有55000多个化学物质,将其分割成多个任务每次完成100个网页的抽取,实际完成数为93.3%。在没有抽取出来的数据中65%返回错误码为600,属于网页结构错误;35%返回结果码408,属于网络错误是由于网络超时页面没有响应。对返回结果码为408的网页进行重试,重试成功率为35.7%。

图6 已抽取数据与网页中数据比较结果

表4 测试网站

表5 抽取信息测试情况
本文运用开源任务调度框架Quartz将抽取任务实现成一个时间程序,有时间触发,从而实现自动化抽取;将整个网站数据抽取这个大任务分割、引入失败重试机制等设计保证了系统的稳定性和可靠性;系统采用面向对象设计方法,采用松散耦合的设计等原则以便提供系统扩展性。当需要新增信息源网站时,实现和回归测试成本都将比较低。
4 结束语
本文实现了对指定信息源网站中化学物质信息的自动获取,并将其集成,实现数据库的实时更新,为用户查询时提供最新数据,同时为后期建立新化学物质生态危害影响模型与预测评价体系准备基础数据;用户可以查询所需的化学物质相关信息,并提供了简单的统计信息。本文设计时采用的技术都是可靠的经过大量测试和实践验证,保证了系统的统一、松散耦合原则,实现了系统的可靠性、可扩展性、自动化、可维护性。由于本文信息抽取时是针对不同的网站编写不同的抽取规则,因而系统的查准率较高,但正因为如此,若新增加网站,就需要编写新的抽取规则,通用性不好。
当下出现的一些脚本工具 (比如tb-qlexpress),可以将简单逻辑脚本化 (可配置,逻辑作为脚本引擎的参数),如果将抽取规则脚本化,当信息源网站页面结构发生变化时,只需在线配置、测试抽取规则即可,响应变化非常快。另外,当新增信息源网站时,只需新增一条抽取规则脚本,无需重新发布应用程序,有待于进一步研究。
[1]XIA Zhaojie,LIANG Chunyan,GUO Li.Design and implementation of a chemistry focused web crawler [J].Computer Engineering and Applications,2006,42 (10):204-229 (in Chinese).[夏诏杰,梁春燕,郭力.化学主题网络爬虫的设计和实现 [J].计算机工程与应用,2006,42 (10):204-229.
[2]LI Xiaoxia,YUAN Xiaolong,XIA Zhaojie,et al.A set of discovery tools for internet chemical information [J].Computers and Applied Chemistry,2008,25 (9):1079-1082 (in Chinese).[李晓霞,袁小龙,夏诏杰,等.Internet化学信息的系统挖掘工 具 [J].计 算机 与 应 用 化 学,2008,25 (9):1079-1082.]
[3]LI X X,YUAN X L,NIE F G,et al.Overview of ChIN,a web guide of chemical information for 10years [J].Computers and Applied Chemistry,2007,24 (1):125-129.
[4]University of liverpool.Links for chemists [DB/OL].http://www.liv.ac.uk/Chemistry/Links/links.html,2005.
[5]GAO Limin,LI Jun,XIAO Yanqin.Research of information mining based on the web [J].Computer Knowledge and Technology,2010,6 (16):4339-4341 (in Chinese).[高立敏,李俊,肖艳芹.基于Web的网络信息挖掘技术研究 [J].电脑知识与技术,2010,6 (16):4339-4341.]
[6]LI Haijian,WANG Xiaofeng.Analysis of web information extraction methods [J].Journal of Langfang Teachers College,2009,9 (3):39-40 (in Chinese).[李海健,王晓丰.Web信息抽取的现状及未来展望 [J].廊坊师范学院学报,2009,9(3):39-40.]
[7]YANG Xi,LUO Yanjing,ZHONG Feng.A method of dynamic web crawling by vertical search engine [J].Science & Technology Information,2008,(4):205 (in Chinese).[杨曦,罗燕京,钟锋.面向垂直搜索引擎的一种动态网页的抓取方法 [J].科技信息 (学术研究),2008,(4):205.
[8]ZHANG H X,HUANG S T.An incremental approach to link evaluation in topic-driven web resource discovery [G].LNCS 3521:Proceedings of the First international Conference on Algorithmic Applications in Management,2005:301-310.
[9]ZHOU Lizhu,LIN Ling.Survey on the research of focused crawling technique [J].Computer Applications,2005,25(9):1965-1969 (in Chinese).[周立柱,林玲.聚焦爬虫技术研究综述 [J].计算机应用,2005,25 (9):1965-1969.]
[10]LIU Hanxing,LIU Caixing.Survey on searching strategies of focused crawler [J].Computer Engineering and Design,2008,29 (12):3160-3162 (in Chinese).[刘汉兴,刘财兴.主题爬虫的搜索策略研究 [J].计算机工程与设计,2008,29(12):3160-3162.]
[11]WANG Xiaobin,WANG Pengpo,SHI Zhaoxiang.Semi-structure page information extraction algorithm with automatic granularity selection [J].Computer Engineering and Applications,2009,45 (6):165-172 (in Chinese). [王晓斌,王鹏坡,石昭祥.自动粒度选择的半结构化页面信息抽取 [J].计算机工程与应用,2009,45 (6):165-172.
[12]LI Yuejin.Research of internet-based information extraction technology [D].Dalian:Dalian University of Technology,2005(in Chinese).[李跃进.基于Internet的信息抽取技术研究 [D].大连:大连理工大学,2005.]
[13]SHI Qian,CHEN Rong,LU Mingyu.Implementation of rule induction-based information extraction system [J].Computer Engineering and Applications,2008,44 (21):166-170 (in Chinese).[石倩,陈荣,鲁明羽.基于规则归纳的信息抽取系统实现 [J].计算机工程与应用,2008,44 (21):166-170.]
[14]LIU Jun,ZHANG Jing.DOM based extraction of topical information from web pages [J].Computer Applications and Software.2010,27 (5):188-190 (in Chinese). [刘军,张净.基于DOM的网页主题信息的抽取 [J].计算机应用与软件,2010,27 (5):188-190.]
[15]FANG Geng.Design and implementation of a short message sending scheduling platform [J].Information Technology,2010,34 (12):55-62 (in Chinese).[方赓.一种短消息发送调度平台的设计及实现 [J].信息技术,2010,34 (12):55-62.]
[16]HU Liqiang,ZHOU Dongchu,WANG Wei.Research and application of quartz and web integration [J].Computer and Modernization,2010,25 (8):98-104 (in Chinese). [胡利强,周冬初,王伟.Quartz调度器与Web程序整合的研究和应用 [J].计算机与现代化,2010,25 (8):98-104.]
猜你喜欢
图书馆论坛(2023年2期)2023-03-10 05:46:38
中学生数理化·中考版(2022年5期)2022-06-05 07:52:30
思维与智慧·下半月(2021年11期)2021-11-23 06:32:38
思维与智慧(2021年33期)2021-11-23 03:05:22
中学生数理化·中考版(2021年5期)2021-11-22 07:50:18
活力(2019年19期)2020-01-06 07:35:02
中学生数理化·中考版(2019年5期)2019-06-26 00:56:38
电子制作(2018年10期)2018-08-04 03:24:38
中学生数理化·中考版(2018年3期)2018-05-29 01:15:25
电子制作(2017年2期)2017-05-17 03:54:56
