
基于知网的论文按需检索系统
2012-04-29 00:44:03蒋莘
电脑知识与技术 2012年2期
蒋莘
摘要:数字图书馆是Web数据库的典型应用领域之一。为了帮助用户高效地访问数字图书馆中的海量资源,该文提出一种按需论文检索系统,通过本地搜索和在线搜索的有效结合,可以批量处理用户的查询请求,进行快速响应。在详细介绍系统框架和实现原理的基础上,该文对基于知网的原型系统实现过程进行了详细阐述。
关键词:Web数据库;数字图书馆;按需检索;知网
中图分类号TP311文献标识码:A文章编号:1009-3044(2012)02-0340-05
CNKI-based Requirement-oriented System for Searching Paper
JIANG Xin
(Wenzhou Teaching andResearching Institute, Wenzhou 325000, China)
Abstract: Digital library is one of the typical applications of web databases. To help users to effectively access the resources in digital li? brary, a requirement-oriented system for searching paper is proposed. By means of the combination of local search and online search, the system can deal with the users query in the way of batch processing. The details of the system based on the open-source libcurl library are introduced, which can construct and submit the query form to CNKI automatically.
Key words: deep web; digital library; requirement-oriented; CNKI
Web作为互联网信息发布平台蕴含着海量信息,按照信息蕴涵的“深度”可以将Web划分为Surface Web和Deep Web[1]。与Surface Web相比,Deep Web蕴藏了更加丰富的高质量结构化信息,也被称为Web数据库。如何使得用户能够方便地访问Web数据库中隐藏的丰富资源是一项极其值得期待的需求[2],已经成为近几年来数据库领域研究的热点。
作为Web数据库典型应用的数字图书馆[3],基于现代计算机和网络技术的数字信息资源系统,将分散于各种载体、不同地理位置的信息资源以数字化的方式储存,以网络化的方式互相连接,通过分布式的信息管理实现全球范围的信息资源共享[4]。近年来,数字图书馆的建设得到飞速发展,知网、万方等数据库中存储着越来越多的丰富数字资源。然而,从如此海量的信息中快速获取用户所需的信息,并不是一件容易的事情。如何构建以用户需求为导向,以服务为中心[5]的数字资源检索系统引起了广泛关注。
本文针对数字图书馆中的典型资源——中国知网(CNKI)进行应用研究,在分析其工作原理的基础上,设计出一个根据用户的需求批量地从知网获取相关信息的按需论文检索系统,以实现用户“随需即取”的查询体验。
1基于知网的论文按需检索系统框架
通常,用户要从知网、万方、期刊网等数据库中下载论文资源,必须使用一个合法的帐号登录到网站的检索系统,然后通过网站提供的查询表单提交搜索关键字,网站后台动态地生成检索结果,以网页的形式返回给用户。这种方式最大的不足在于一次只能进行一个搜索,用户需要花费大量的时间等待网站的查询响应[6]。为了提高用户查询的效率,本文设计了一个按需的论文检索系统,借助于本地搜索和在线搜索的智能组合,能够以批处理的方式响应用户的检索请求,极大地提高了用户的检索效率。目前,我们已经实现了基于中国知网的论文按需检索原型系统,系统的体系结构图如图1所示。
该系统的基本原理如下:在系统中,我们将用户的历史检索请求存储在本地数据库中。当用户提交一个新的检索请求时,系统首先检索本地元数据库,判断该请求是否存在于本地数据库中。如果存在,则进行本地搜索并将与该查询请求相关的论文返回给用户。如果不存在,则系统自动抽取用户的检索请求信息并构造出知网能够接收的查询请求,提交给知网服务器进行在线检索。在将知网返回的查询结果返回给用户的同时,系统存储该查询及相应结果于本地服务器,便于后续查询使用。
2知网的工作原理分析
中国知网(CNKI)是全球领先的数字出版平台,是一家致力于为海内外各行各业提供知识与情报服务的专业网站[7]。从知网上获取信息和从谷歌、百度等通用搜索引擎获取信息的不同之处在于:知网是授权访问的网站,要想从知网上获取信息,必须具有知网注册用户的权限,并且处于已登录状态。
在知网的查询首页,如果用户指定了查询信息并点击“跨库检索”按钮,浏览器将再次发送一个表单给知网,该表单中的各个查
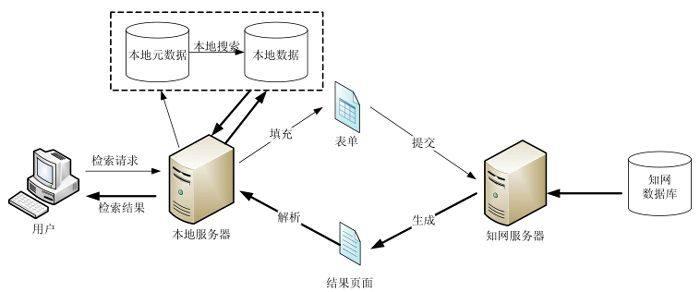
图1按需论文检索系统体系结构图询属性包括:检索项、匹配、开始年份、结束年份、检索词以及所选择的数据库。
知网与谷歌、百度等搜索引擎获取信息之间的另一个不同之处是:谷歌与百度把搜索关键字等相关信息直接拼接在url地址中,并用http的GET方式向服务器索取搜索结果;而知网则像它提交登录信息一样,把搜索关键字等相关信息拼装在一个表单中,并用http的POST方式把该表单发送给服务器,以请求搜索结果。
在查询首页中,当用户输完检索词等相关信息并点击“跨库检索”按钮后,浏览器就把相应的查询属性拼装成一个表单,用POST方法提交给知网。
在将该查询表单发送给知网服务器之后,浏览器将收到一个如图2所示的结果页面。为表示方便,将被框起来的部分称为“内页”,框意外的部分称为“外页”。实际上,在提交了第一个查询表单之后,浏览器只收到了外页。而当浏览器继续提交第二个表单后,才将收到内页。这第二个表单是由浏览器自动提交的,不需要用户再输入相关的查询信息。
具体来说,浏览器在收到外页后,根据外页的“要求”自动构造了一个第二个查询表单,该查询表单不仅包括前面提到的所有查询属性,还包括了其他的一些默认的属性,如“searchflag=0”等。第二个查询表单发送之后,浏览器将收到查询结果页,也就是图5中的内页。内页包含了所有符合要求的论文详细信息的链接地址。这些链接地址是临时的,一段时间之后将会失效,即过了有效时间之后用户再点击那些链接将无法跳转到详细信息的页面。如果查询结果数量比较多,结果页面并不会一次把所有结果的链接都显示出来,而是每次只显示10条,用户可以点击“下一页”链接来继续显示后续的10条链接,以此类推。
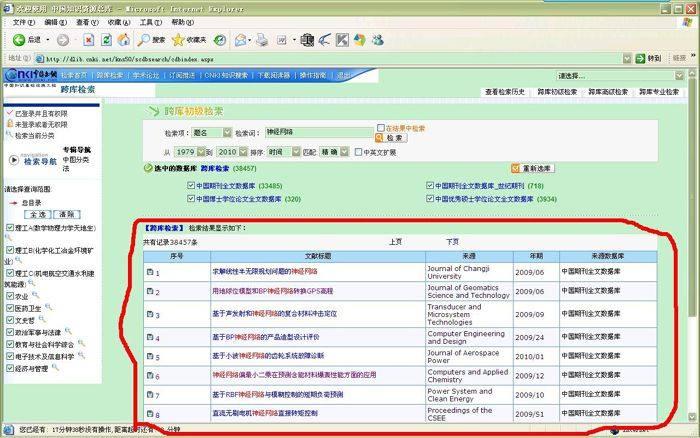
图2知网的查询结果页面
如果用户在有效时间之内点击那些详细信息的链接,那么浏览器将使用http的GET方法去获取这个页面,该页面也就是用户所需要的最终页面,包含了论文的作者中文名,作者单位,关键词,摘要等详细信息,并提供了该论文的caj格式和pdf格式的全文供用户下载。
3按需论文检索系统的实现
在深入分析知网的信息获取原理基础上,本章将介绍如何实现基于知网的论文按需检索系统,利用程序自动实现与知网服务器的交互功能,达到根据用户需求从知网上批量下载资源的目标。
3.1系统类库定义
本文所实现的原型系统均基于libcurl库进行开发,系统中所定义的主要类库介绍如下。
由于每个新定义的CURL类型指针在使用前都需要用curl_easy_init函数初始化,为了使用方便,将把CURL类型的指针封装在Curl类中。
class Curl{
public:
Curl(){根据*link的值调用curl_easy_init函数}
Curl(const Curl&c){修改*link的值}
Curl&operator=(const Curl c){复制c并修改*link} CURL*get();
virtual~Curl()
{
根据*link的值调用curl_easy_cleanup函数
}
private:
CURL*curl;
int*link;
};
每次构造一个新的Curl对象时都会由构造函数自动地调用curl_easy_init函数对curl成员进行初始化,而每次删除一个Curl对象时都会由析构函数调用curl_easy_cleanup函数来对curl成员做清理工作。因此,使用Curl类将不用再考虑何时需要调用curl_easy_init函数和curl_easy_cleanup函数,从而简化了对CURL指针的使用。
类GetPage用于实现网页信息的获取功能。由于http协议提供了两种获取信息的方式:GET和POST,因此类GetPage定义为一个基类。可以通过调用set_ret_func_h等四个成员函数来设置如何保存获取到的页面和把获取到的页面保存到哪里。为了使用方便,GetPage的构造函数指定了默认的回调函数和存储区,这样,就不必在每次获取网页前设置回调函数和存储区了。
为了使程序能够分别使用GET方法和POST方法获取页面,从GetPage类派生出两个类GetPage_get和GetPage_post,分别对应使用GET方法和使用POST方法。其中GetPage_get类相对其基类GetPage没有增加任何成员,而GetPage_post则增加了一个string成员post_content,用来存放表单的内容。另外,虽然GetPage_get和GetPage_post都继承了它们基类的url成员,但含义不一样:Get? Page_get中的url存放所要获取的页面的url地址,而GetPage_post中的url存放的是提交表单的目的地址。
class GetPage{
public:
typedef size_t(*ret_func)(void*,size_t,size_t,void*);
GetPage(string u);
GetPage(Curl c,string u);
void set_ret_func_h(ret_func h);//设置报文头的回调函数
void set_ret_func_b(ret_func b);//设置报文体的回调函数
void set_stream_h(void*sh); //设置报文头的存储区
void set_stream_b(void*sb); //设置报文体的存储区
virtual int get_html(void); //获取页面
void*get_sh(void); //获取报文头
void*get_sb(void); //获取报文体
Curl get_Curl(void);//返回本对象所使用的Curl对象
virtual~GetPage();
protected:
Curl curl;
string url;
ret_func head,body;
void*streamh,*streamb;
bool alloc_flag_h,alloc_flag_b;};
由于需要频繁地从获取的页面中解析出一些信息(如链接地址等),所以定义一个Parser类,用于从一个字符串中获取以指定字段开头,并以指定字段结尾的字符串。在类Parser中,read_file函数用于把源字符串读到成员file中。parse函数的作用是从成员file中找出以head开头并以tail结尾的字符串。在其参数中,如果reserve_head的值为true,则会在目标字符串中保留head;如果为false,则在目标字符串中不保留head。reserve_tail也一样,表示是否保留tail。最后一个参数get_first_num表示最多把多少个符合条件的目标字符串存放在作为返回值的list中,0表示返回所有符合条件的,n(n>0)表示返回符合条件的前n个。
class Parser{
public:
Parser(string s);
void read_file(string&str);
list
reserve_tail,unsigned int get_first_num=0);
private:
string file;
list
};
3.2知网的自动登录实现
在Curl,GetPage和Parser三个类实现之后,就可以实现登录知网的程序了。因为libcurl库支持自动跳转,即自动重定向,从而不用特意地去判断是否需要跳转,而直接得到查询首页。登录过程的流程如下所示。

cnki_login函数最后返回Curl对象这一步是必需的,因为这个Curl对象“保存”着程序和知网之间的交互信息(cookie),即这个Curl对象维持着程序作为已登录用户的状态。返回这个Curl对象将便于后续的查询操作能始终使用这个Curl对象与知网进行交互。
其实,从本质上来讲,整个登录的过程就是为了使程序在之后的查询过程中能始终以已登录用户的身份来与网站进行交互,因此,cnki_login函数的最终目标就是生成一个具有已登录用户身份的Curl对象,并把该对象返回给后续的程序使用。
3.3本地数据库的存储模式
系统的本地数据库用于存储用户的查询需求和查询结果,主要包括两个模式:需求表和结果表。需求表用来存放用户的需求,即用户对所要搜索论文的相关描述,程序将会根据每一条需求分别从知网上获取相关信息。需求表的模式如图3所示。其中,searchfield表示查找域,即“题名”,“关键词”,“作者”等;database表示所要选择的数据库;match表示匹配模式,“1”为精确匹配,“2”为模糊匹配;value表示搜索关键字;startyear和endyear分别表示查询的起始年份和结束年份。
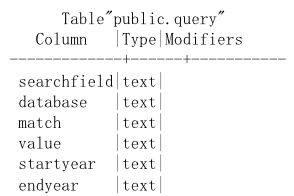
图3需求表模式
结果表用来存放每一篇论文的相关信息,其模式如图4所示。其中,titlech和titleen分别表示中文题名和英文题名;authorch和authoren分别表示中文作者名和英文作者名;keych和keyen分别表示中文关键词和英文关键词;abstractch和abstracten分别表示中文摘要和英文摘要;pdf_url表示该论文的下载链接地址。
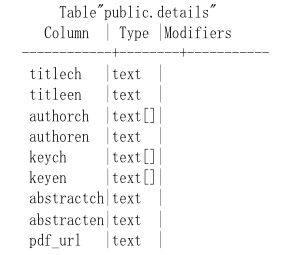
图4结果表模式
由于程序只需要对需求表执行读操作和对结果表执行写操作,因此仅为DbOper类定义两个相应的成员函数,就可以实现用户需求的获取,DbOper类定义如下所示。
class GetQuery{
public:
int setQuery(Query&);//获取需求并拼装成表单
string getJQ()const;//获取拼装后的表单
private:
void joint();//把需求拼装成表单
Query q;
string jointedQuery;//用来存放表单};
3.4查询处理的实现
系统的查询处理由类DoQuery实现,其功能包括:把查询表单提交给知网,解析知网返回的结果页面并获取论文的详细信息,以及把这些信息存入数据库之中。DoQuery类定义如下所示。
class DoQuery{
public:
DoQuery(const Curl&,const GetQuery&);
void setGetQuery(const GetQuery&);
void setUrl(const string&);
int run(DbConn&);
private:
DoQuery();
Paper detail_parse(string);
Curl curl;
string post_url;
string post_content;
};
一般来说,应该将所获得的内页中的所有论文链接地址解析出来,一页解析完之后再解析后一页,直到所有链接地址都解析完成。但知网比较特殊,同一次搜索出的所有结果链接都是相关联的。例如第一条结果链接地址为“/kns50/detail.aspx?QueryID= 17&CurRec=1”,则第二条的地址为“kns50/detail.aspx?QueryID=17&CurRec=2”,以此类推,每条结果的地址除了最后一个数字不同,前面的完全相同。因此,可以只解析出第一个结果链接的地址,抽取其最后一个数字之前部分地址,然后来推出所有结果的链接地址。该方法可以大大地提高程序的效率。假设某个搜索请求的结果有210条,每个结果页面显示10条结果,而获取1个页面的速度为0.2秒,那么用该方法将整整剩下(210-10)/10*0.2=4秒时间。
在获取了结果的地址之后,run函数将根据每个地址循环地通过GET方法从知网上获取论文详细信息的页面。对于每一个论文详细信息的页面,run函数将会调用DoQuery类的私有函数detail_parse来从中解析出诸如作者名,关键字,摘要,论文下载链接地址等信息并存入数据库中。
3.5用户查询需求的响应
针对某一组用户需求(查询关键字),该系统可以将从知网检索得到的有效结果全部存储在本地数据库中,每条检索结果记录对应需求表中相应的需求编号。然而,对于不同用户而言,其查询需求各异,如果有效地利用系统存储在本地的检索结果是提高查询效率的关键。由于系统在本地数据库中的需求表存储了用户查询的相关信息,因此可以利用不同的SQL查询来表达用户的不同需求。
不同用户需求之间的关系可以通过其查询结果集合间的关系所呈现。基于结果集合上的覆盖关系,任意两个需求可被分为相离、相交和相容三种情况。假设用户需求都被执行过至少一次,执行后的返回结果已被存储在数据库中。需求关系判断的基本思想如下:首先产生需求P、Q的对应数据集data(P)、data(Q)。当遍历data(P)集合后,如未发现与data(Q)存在交集,则视为需求相离;当所有data(P)中的记录都相交于data(Q),则P相容于Q。当data(P)与data(Q)部分相交,还要结合对data(Q)的遍历做进一步判断。此时,如果data(Q)中的记录都相交于data(P),则是Q相容于P,否则P、Q是相交关系。
由于判断所需的数据均存储于本地,对于已经存储在数据库中的用户需求关系判断很容易实现,但对于一个新的用户需求而言,其查询结果尚未获取,而无法使用上述方法判断与已有需求之间的关系。我们通过构造SELECT查询在本地数据库中检索是否存在满足新用户需求的数据。例如,新用户需求形如“searchfield=SF,value=V,…”,我们可以构造如下查询:“select * from public.que? ry where searchfield=SF and value like‘%V%”,在用户需求表中检索匹配的记录,如果检索成功,则将这些需求对应的查询结果直接返回给用户,否则就将用户需求提交知网进行在线查询。通过这种处理方式,系统一定程度上提高了用户需求的响应效率,而更加完善的用户需求响应方案也是我们下一步研究的重点。
4结论
为了帮助用户高效地访问数字图书馆中的海量资源,本文提出一种基于知网的按需论文检索系统,通过本地搜索和在线搜索的有效结合,批量处理用户的查询请求,进行快速响应。下一步将继续完善本系统,将其扩展到其它的数字资源库。
参考文献:
[1]刘伟,孟小峰.Deep Web数据集成研究综述[J].计算机学报,2007,30(9):1475-1489.
[2]崔晓军,彭智勇.Deep Web信息按需集成研究综述[J].武汉大学学报:理学版.2009,55(4):465-472.
[3]马翠嫦.国外数字图书馆可用性评价研究综述[J].现代图书情报技术,2007,2(2):1-6.
[4]陈亚召.以需求为导向的数字信息资源建设模式研究[J].图书馆,2009(2):105-106.
[5]李虹.面向用户的数字图书馆信息服务模式研究[J].情报杂志,2007,26(8):134-136.
[6]鲁海宁.自建数据库信息服务平台模式构建[J].图书馆工作与研究,2009(2):40-43.
[7]朱延峰.数字图书馆信息服务模式问题简析[J].南阳师范学院学报,2011(8):1-5.
猜你喜欢
纯碱工业(2023年6期)2023-04-21 16:18:44
现代交际(2017年13期)2017-07-18 09:53:01
北方文学·下旬(2017年3期)2017-04-20 10:39:32
医学信息(2016年29期)2016-11-28 09:27:00
资治文摘(2016年7期)2016-11-23 01:00:24
商情(2016年39期)2016-11-21 09:27:10
电脑知识与技术(2016年24期)2016-11-14 00:45:40
中国科技博览(2016年22期)2016-11-01 17:44:11
企业导报(2016年12期)2016-06-17 16:54:31
科技视界(2016年5期)2016-02-22 11:41:39
