
基于treemap的mysql测试结果可视化研究
2012-04-29 05:12:52孙柳红
电脑知识与技术 2012年5期
孙柳红
摘要:随着软件行业技术的飞速发展,软件产品规模在不断的变大,由此出现软件缺陷数量日益增多的现象,如何通过软件测试来有效地提高软件产品的质量,显得尤为重要。传统的手工测试方法存在很多局限性,自动化软件测试技术应运而生,特别是分布式的测试体系能大大的提高硬件资源利用率,缩短测试周期。在这一方面上mysql数据库已经自带了一个完整的测试框架,用户可以方便的执行各种测试用例来验证数据库是否正常运行。但是该测试框架的不足之处在于测试结果是以单独的文本文件形式存放,这样很不利于查看各个测试用例通过与否,也不利于查看未通过用例的失败原因。因此在这样的背景下提出了基于treemapSDK的mysql测试结果分析可视化研究,对整个测试结果集进行全面的分析,分类反馈给用户哪些用例测试通过,哪些用例测试失败,并且提示失败用例的出错行及具体内容,方便用户对测试结果的管理。
关键词:mysql;treemap;自动化软件测试;测试结果分析
中图分类号:TP311文献标识码:A文章编号:1009-3044(2012)05-1089-05
MYSQL Test Result Set Visualized Analyse Based on Treemap
SUN Liu-hong
(College Computer Science, Sichuan University, Chengdu 610065, China)
Abstract: With the rapid development of technology which is in the software industry,the scale of software products continue to become larger and larger,thus making the number of software defects become much more than ever. It is particularly important that how to effec? tively improve software quality by software test. Traditional manual testing methods has many limitations. Automatic software testing tech? nology emerged,which can greatly improve hardware resource utilization and reduce test cycle especially in distributed testing system. In this case, the mysql database already came with a complete test framework, which can be easily performed by user to execute a variety of test cases to verify whether the database runs successfully. However,there is a shortcoming in the test framework,that is the test results are kept separate in text file format,so it is not only disconvenient for user to check whether each test case is successful,but also not disconve? nient to find root problem of failture. Therefore,it is suggested that making the mysql test results visual by using treemap SDK in this back? ground.By doing so,we can make all-around analysed of test result set,and give feedback to users,telling them those failed test case,let users convenient to manage test result set.
Key words: automatic software test; test result set analyse; treemap; mysql
随着软件产品规模的不断扩大,功能不断的增多,软件与用户之间的交互性也越来越重要。还早在DOS时代的软件提供给用户的操作接口就是各个复杂难记的命令,这使得软件的使用者范围被紧紧的圈死在了有专业知识背景的人员里。但是现在软件产品普遍大众化以后需要提供给用户一个友好的,直观的,易操作的交互界面。软件可视化指用各种图形图像的方式为用户直观地展现软件的数据,功能及服务,并提供各种清晰明了的功能操作键让用户方便地对数据进行操作,使得用户更容易理解和消化软件所包涵的信息。同时,软件测试可视化指测试软件的整个过程可视化,即用各种图形图像方式为测试人员展现整个测试的过程,使得测试人员更容易理解整个测试的流程以及各个测试部分之间的关系。因此,测试的结果的可视化是软件测试可视化的不可缺少的组成部分。它使测试结果更直观的展现出来并且有利于测试人员分析测试结果。
就目前的研究情况来看,Mysql的开发小组并没有开发对测试结果进行可视化统计分析的系统的打算,而且国内外也暂时没有任何关于这一问题的研究案例,所以本文的提出了在Mysql上开发第三方图形化界面的测试结果统计分析系统,这不仅仅是对Mysql的一个很好的功能扩展,也可以为分布式自动化测试提供测试结果汇总,分析,统计并可视化的发展前景提供一个参考方法。该系统使用JDK6.0处理Mysql自带的TestFramework测试框架所产生的测试用例结果集,然后通过treemap可视化工具显示处理后的测试用例结果集,从而验证了测试结果可视化的可行性优越性。
1相关工作
随着信息爆炸时期的到来,信息可视化已然成为一门崭新的科学领域,它结合了图像学,人机交互,数据挖掘等多门学科的理论和方法。目前信息可视化的研究热点有:层次信息可视化,多维信息可视化,文档(文本)可视化,Web可视化。结合mysql的测试结果文件类型可知,对mysql的测试结果的可视化属于文档(文本)可视化。随着软件的规模不断增大,对软件测试后的测试结果文件也是不断增多的,故对测试结果的可视化就成为了对大型文档集合的可视化过程。目前,Stephen G. Eick等人在可视化系统Seesoft中实现了一种对计算机程序进行可视化的方法[5]。Seesoft已经在软件开发和项目管理方面实现了可视化。美国西北太平洋国家实验室(Pacific Northwest National Laboratory)的科学家们提出了一系列的信息访问和可视化分析工具,这些技术统称为SPIRE(Spatial Paradigm for Information Retrieval and Exploration)[5]。通过运用这项技术可以探讨出文档之间的关系。针对测试结果而言便可以探讨出测试用例间的关系从而为测试用例的筛选提供依据。而以上工具及技术未曾针对软件测试结果文档的自身特点进行可视化的。
针对信息可视化的模型,目前流行的是Stuart Card, Jock Mackinlay, Ben Shneiderman提出的信息可视化参考模型[2]。本系统参考了该模型和流程[7]来进行mysql测试结果的可视化,验证了该模型在测试结果可视化这一具体问题上实现的可行性。原始数据映射到结果数据的过程,本文是使用JDK6.0自行开发实现的;而结果数据映射到视图是使用treemap完成的。treemap作为可视化技术目前已经有了相当多的研究和相关产品,例如,Maryland大学关于treemap的产品有treemap4.0[3],PhotoMesa[3],Treemap Algorithms[3]等,针对不同领域Maryland大学有更多产品[3]。这些产品已经可以完全使用与实际当中。
目前的软件产品都有各自的图形化操作界面,精美的,易用的界面往往会为一款软件产品带来强有力的竞争力,因此在可视化领域的技术也是非常丰富的。针对不同的软件应用领域可视化工具也是各不相同的。DirectX和OpenGL无疑是可视化开发中,尤其是对图形图像的开发中非常有名的两个支柱技术。除此之外也还有其他基于它们开发出来的可视化工具技术如:MatLab,GPT? map,GIS,以及本文下面将要使用到的treemap等。
2系统的关键技术及创新点
2.1关键技术
系统的关键部分是要把原始的文件处理转换为treemap能识别的csv中间文件,具体的算法实现如下:mysql中的r文件夹内只会存在两种不同后缀名的文本文件,一种result文件,一种是reject文件。所以该部分模块的输入就是系统程序所在的同级目录里的r文件夹。首先,当系统运行以后读取r文件夹,依次获取每个文件的文件名,以文件名中最后一个点号最为分割符分隔当前读取到的文件名,然后判断如果最后一个点号后面的字符串是reject则说明点号前面的字符串代表的测试用例是未通过的,把该文件名存放在一个名为notPass的String数组中暂时保存起来,同时还要把该文件名以及能够标识它为未通过的其他信息,包括可能出错的位置,输出给用来生成csv文件的系统模块;如果最后一个点号后面的字符串是result则直接获取点号前面的文件名后存放在一个名为all的String数组中,直到所有的文件都扫描过一遍后再来和notPass中的文件名比对,只要该文件名未曾在notPass中出现的话说明它对应的测试用例是测试通过的,同时把该文件名以及能够标识它为通过的其他信息输出给用来生成csv文件的系统模块。
2.2创新点
目前Mysql的测试框架输出结果完全是基于文本的形式存放,还没有任何的图形化分析工具,当测试用例数量庞大,尤其是失败用例居多的情况下会给测试人员对测试结果的分析工作带来极大的不便。采用图形化的方式来区分通过的和未通过的测试结果,并统计各自的数量,同时还能找出失败原因可能所在的行数和内容将会大大的减轻测试人员的工作负担,提高他们的工作效率。
Treemap作为可视化技术未曾运用于测试结果的当中,而本系统首次运用它来可视化测试用例集,有利于测试人员分析测试结果,使得测试更进一步地自动化,证明了使用treemap来可视化测试结果这种方法是可行的。
3系统设计与实现
3.1系统概述
系统分为三大步:处理信息;分析信息;可视化信息。具体如图1所示。
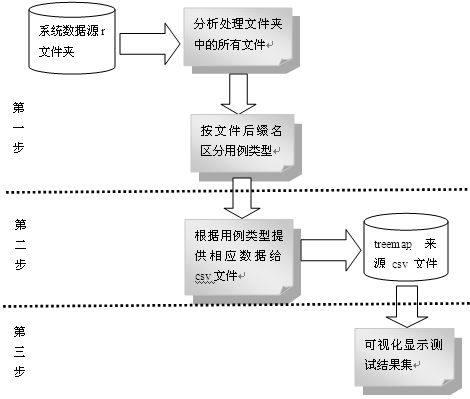
图1系统流程图
系统的详细执行流程如下:第一步,读取r文件夹中的所有文件,根据文件后缀名区分用例类型(通过和未通过)。第二步,根据不同用例类型获取相应csv文件信息,并将其写入csv文件。第三步,使用treemap将csv文件可视化测试结果集。
系统的关键部分是要把原始的文件处理转换为treemap能识别的csv中间文件,从文件能获取的信息只有一个文件名,所以处理模块要先根据文件的后缀名来区分文件代表的结果类型,然后根据不同的类型增加其他的附加信息来明确的区分测试用例。
csv文件中的每一行代表一个用例信息,构造规则为“用例名,是否通过,显示尺寸,类别,出错行”,这样treemap从csv文件中读取一行一行的数据后可以用第二列的数值来进行验收区分,用第四列的数值来进行分组显示,用第五列的数值来显示提示信息。
整个系统是完全自动化运行的,用户只要执行程序从读取r文件夹到生成csv文件,最后到显示图形界面结果都是自动完成的,这样就可以极大的方便用户进行查看分析,大大的节省了时间,提高了工作效率,也体现了自动化测试的概念。
3.2各模块实现
各个模块的流程图如图2。1)测试文件处理模块
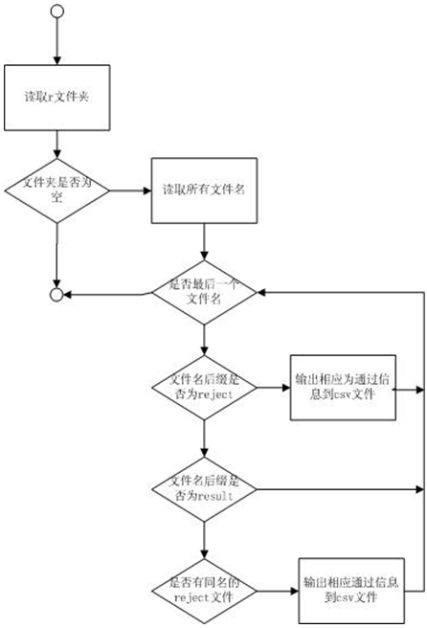
图2测试文件处理模块流程图
对测试结果存放目录r文件夹分析的流程,该过程主要的作用是把一个个分散的文件信息数据化后输出给下一个模块,这样就实现了把测试结果集中化,分类化的功能。所有的处理数据会在下一个模块中被输出到一个名为testResultSet.csv的文件中存放起来。
2)csv文件生成模块
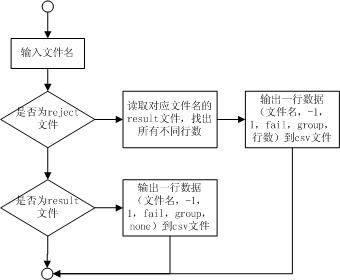
图3 csv文件生成模块流程图
该模块接受文件名和文件扩展名作为输入参数,根据扩展名来判断文件名对应的测试用例是通过的还是未通过的。如果是通过的则使用1,test case passed等附加信息来标识该用例;如果是未通过的则使用-1,test case failed等附加信息来标识该用例。该模块运行结束后就会自动生成一个testResultSet.csv的文件存放所有用例的情况,这样就为treemap构造好了数据来源。csv文件,每一行代表一个数据项,而每一列代表该数据项的各个数据域属性,所以每一行数据项应该有的数据域为caseName,isPass,size,group,difference line。
①isPass的值设定为1代表测试用例通过,-1代表测试用例未通过;
②group的值相应的设定为test case passed和test case failed;
③difference line相应的为none和所有不同的行数;
④size全部设定为1,因为用例之间没有层次关系;
csv文件作为系统的中间文件如图6所示。
3)treemap显示模块
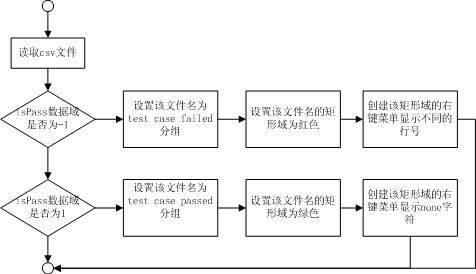
图4 treemap显示模块流程图
该模块读取csv文件作为输入,把文件中的caseName指定给treeamp的label属性,这样默认每个矩形域显示测试用例的名字;把文件中的isPass指定给treemap的color属性,这样默认的通过的用例的矩形域显示为绿色,未通过的用例的矩形域显示为红色;把文件中的size指定给treemap的size属性,各个用例之间是独立的,没有相互从属关系,size值都为1;把文件中的group指定给grou? pList,所以用例分为test case passed和test case failed两类;difference line作为每个矩形域的弹出菜单内容,通过的用例显示为none,未通过的用例显示具体的存在差别的行数。
4系统验证
4.1测试数据与步骤
测试数据:mysql自带的存放测试结果的r文件夹,包含22个文件。它包含有result和reject两种类型的文件。
测试步骤:
把r文件夹放到本程序系统的目录里面,首先查看文件夹里的文件,初步统计出result文件和reject文件各自的数量,并检查re? ject文件是否有同名的result文件,如果没有说明数据来源可能存在问题,需要先修正后再测试。
直接运行run.bat文件来启动程序,这时应该可以看到程序窗口内分为绿色和红色的两大区域,各自区域又被若干白色边框的矩形域分割开来,每个小矩形域上都会显示有不同的字符串,当把鼠标移动到任何小矩形域上时都会弹出一个小菜单,如果是绿色的矩形域的弹出菜单应该显示的是none字符串,如果是红色的矩形域的弹出菜单则显示的是具体的xL字符串。当在矩形域上单击鼠标右键的时候弹出菜单的最下面会附加两个选项单分别是zoomIn和zoomOut,选择zoomIn可以使某个分组界面占据满显示区域,选择zoomOut则退出当前显示区域返回默认显示区域。
此外为Size,Color,Label选择不同的数据列显示的内容也会随之做相应的改变,这样可以方便用户根据不同的需求来进行查看操作。
4.2测试结果与分析总结
程序在处理完r文件夹内的文件后得到csv文件如图5所示。
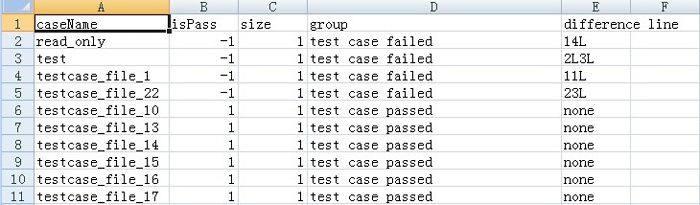
图5 csv文件内容
使用treemap可视化后得到图6所示结果。

图6程序运行初始结果
通过zoomIn可以分别进入通过用例组或者未通过用例的界面,同时在不同组的界面中选定某个用例可以显示出用例的名称及difference line是none或者几行(不同处所在行)。使用zoomOut可退出当前界面。
从以上测试截图中可以看出程序运行结果符合预期的设想,主界面分成两个部分,一个是test case passed组,并且提示了通过的用例数量为18,另一个分组是test case failed组,提示的未通过用例数量为4,这个结果是符合r文件夹里的实际情况的。
通过用例在选中之后提示difference line为none,未通过testcase_file_1用例在选中之后提示提示difference line为2L3L(与得到csv文件相符),表示reject文件和result文件中的第2和第3行存在不同处,即testcase_file_1的result所对应同名的reject文件中第2和第3行不同,并且有相应的提示界面显示其各自不同处的内容。
本系统把繁杂的数据自动化处理,直观化显示,用户所要做的就是运行程序就能得到想要了解的信息,极大的方便了用户,体现了自动化的理念。
系统不足在于对于未通过的用例在图形界面上只能提示存在的不同行数,而具体的不同内容是在另外的控制台下显示的,这样显得不够灵活。由于mysql自带的测试用例集中各个用例间无层次关系,size值全部为1,不能更多的显示在测试用例间有层次关系情况下的可视化结果,因此无法确定在其他大型测试中是否能正确的可视化测试结果。
程序系统能够按照最初的设计思想和期望结果运行,得到的结果是正确的。
5小结
本文使用treemap实现了mysql本身自带测试用例所产生的测试结果的可视化系统,该系统实现了对基于文本的自动化测试结果的可视化,验证了对测试结果可视化的可行性,并展现了测试结果可视化后对测试人员的优越性。下一步我们可将考虑该系统是否能够扩展到所有其他自动化测试工具所产生的测试结果文件中;亦可以应用到其他软件测试平台,例如分布式自动化测试平台[10]。使用其他可视化开发工具来实现测试结果的可视化,并分析各种工具可视化测试结果的优劣,得出何种可视化开发工具更适用于自动化测试结果集的可视化。
参考文献:
[1] Kong N,Heer J,Agrawala M.Perceptual Guidelines for Creating Rectangular Treemaps[C].IEEE Information Visualization,2010.
[2] Card S,Mackinlay J,Shneiderman B.Readings in Information Visualization:Using Vision to Think[C].Morgan Kaufmann,1999.
[3] Shneideman B.Treemaps for space-constrained visualization of hierarchies[EB/OL].http://www.cs.umd.edu/hcil/treemap-history/.
[4] Bederson B B,Shneiderman B.Ordered and quantum treemaps:Making effective use of 2D space to display hierarchies[J].ACM Trans On Graphics,2002,21(4):833-854.
[5]冯艺东,汪国平,董士海.信息可视化[C]//第一届全国虚拟现实技术研讨会论文集.北京:中国工程图学学会,2001:324-329.
[6]刘玮,周宁.基于文本的信息可视化方法研究[J].现代图书情报技术,2003(2):34-36.
[7]张海营.信息可视化议[J].科技情报开发与经济,2005,15(8).
[8]周宁,张会平,金大卫.文本信息可视化模型研究[J].情报学报,2007,26(1):155-160.
[9]任磊,王威信,周明骏,等.一种模型驱动的交互式信息可视化开发方法[J].软件学报,2008,19(8).
