
语义知识库存储方案研究
2012-02-28 05:10殷浪
网络安全与数据管理 2012年9期
殷浪
(武汉理工大学 计算机科学与技术学院,湖北 武汉 430063)
随着网络的发展,当今社会已经步入了信息时代。网络资源呈指数增长,互联网己成为一个巨大的信息源,如何提高检索质量,寻求令人满意的检索模式和技术已经是全球的研究重点。当前基于关键词的信息检索由于数据缺乏语义信息及其查询处理缺乏语义支持,只能查找出与用户在语法层上匹配的信息,而无法给出与其在语义层上具有相关性的其他信息,从而导致信息查询结果质量低下。Tim Berners-Lee提出了语义网,使网上信息提供具有计算机可以理解的语义,它的发展和成熟使得高效、高质的语义检索成为可能,以克服基于关键词的信息检索技术的缺陷。但是基于知识库的语义查询通常比较缓慢。本文研究了语义知识库的相关存储方案,并采用LUBM测试集从查询时间和存储空间这两个方面比较几种不同的存储方案[1-3]。
1 语义检索技术
1.1 Protégé
Protégé是一款基于Java的图形界面本体工具,是由美国斯坦福大学开发的免费开源平台。它为用户提供了一系列的工具支持构建领域本体模型和基于本体的知识库应用,常用于定义本体模式。
1.2 Jena
Jena是惠普实验室提供的针对语义Web应用的开源Java开发包[4]。它支持应用程序调用Jena提供的接口操作本体数据;支持主流的本体描述语言,如RDF、RDFS和OWL;支持多种本体的存储模型,如内存模型和数据库模型等。Jena常用于定义实例并对本体数据进行查询维护等。本文将使用Jena API进行相关查询分析。
1.3 Sparql
Sparql(Simple Protocol and RDF Query Language)是为RDF开发的一种查询语言和数据获取协议,它为W3C所开发的RDF数据模型所定义,但是能用于任何可以用RDF来表示的信息资源[5]。RDF的三元模式构成了图形模式,而Sparql的查询解决方案试图将每个图形模式变量的绑定与查询模型节点进行匹配。
Sparql协议和 RDF查询语言(Sparql)目前是 W3C的工作草案或推荐标准,还在讨论中。Sparql构建在以前的 RDF查询语言(例如 rdfDB、RDQL和 SeRQL)之上,拥有一些有价值的新特性。
2 本体知识库存储方案
2.1 文件系统
Jena可以在文件系统中持久化本体知识库,即基于文件系统的存储。该方式实现起来比较简单,很多本体相关工具都支持对文件格式的本体进行存取。但是,这种方法不仅效率低,而且很难适应数据量较大的情况。基于文件系统的存储方式一般只适用于规模较小的本体。
早期的本体数据管理工作是基于文件系统实现的,它们用简单的文件格式存储本体数据并支持一些基本的操作。这类工作主要用来编辑和建立本体,并不是为大规模本体数据的存储和查询管理服务的,如Protégé。
2.2 关系数据库
由于关系数据库技术发展成熟,大多数现有的本体数据管理工作使用关系或对象-关系数据库管理系统作为后台存储。Jena就可以在关系数据库(Relational Database)中持久化本体知识库。当前支持的数据库引擎有 Oracle、PostgreSQL和 MySQL。 以 MySQL为例,下面的代码说明了如何将OWL文件导入到MySQL持久化模型。

在持久化到数据库后,可以通过ModelMaker.openModel(modelName)来访问该模型。
2.3 TDB
TDB是Jena的一个组件,可大规模地存储和查询RDF数据集,且支持Sparql查询[6]。TDB是一个具有高性能、非事务性的RDF数据存储器,可以通过命令脚本和Jena API来访问和管理TDB存储。以下代码是说明如何将OWL文件存储为TDB的。
DatasetGraphTDB graph =TDBFactory.createDatasetGraph(TDBlocation);
TDBLoader.load(graph, "file:///"+owlfile);
3 实验设计和性能评估
3.1 实验设计
3.1.1 硬件环境
本实验测试是在个人电脑上进行的。具体环境是:2.20 GHz Intel(R)Core(TM)2 Duo CPU T6600,2 GB 内存,250 GB的硬盘,WindowsXP操作系统,JavaSDK 1.6.1。
3.1.2 测试数据集
LUBM是Lehigh大学提出的语义Web数据测试集。它基于大学这个领域,采用机器自动生成的数据作为测试数据,提供14个测试查询和一套性能指标[7]。它可以根据用户指定的参数产生不同规模的数据,由此测试在不同规模的环境下,系统的实例查询性能。LUBM测试集是目前最流行的语义Web测试集。它生成的数据满足本体层的规范,因此,也可以作为推理系统的测试数据集。但是LUBM测试结果也存在一个问题,即生成的数据中属性的个数是固定的,仅有64个。随着数据量的增加,数据会失去语义Web的一大特点——稀疏性,导致测试的结果不能反映实际应用的效果。
这14个测试查询,有的涉及推理机,由于篇幅有限,只做了部分测试。以下是3个测试查询语句。

3.2 实验结果对比
库容量和转载时间的比较如表1所示。其中,库容量是指各种不同的存储方式所占用的磁盘空间的大小;转载时间是指从文件形式的知识库转换到其他存储方式所需要的时间。
由于关系型数据库会保存知识库中所有的三元关系,因此耗时会比较多。对于1个50 MB左右的OWL文件,就已经耗时4个多小时。因此,如果是较大的本体知识库,想借关系数据库来改善检索效率的话,其可行性需要斟酌。相对于关系数据库,TDB所用时间要少很多,值得借鉴。
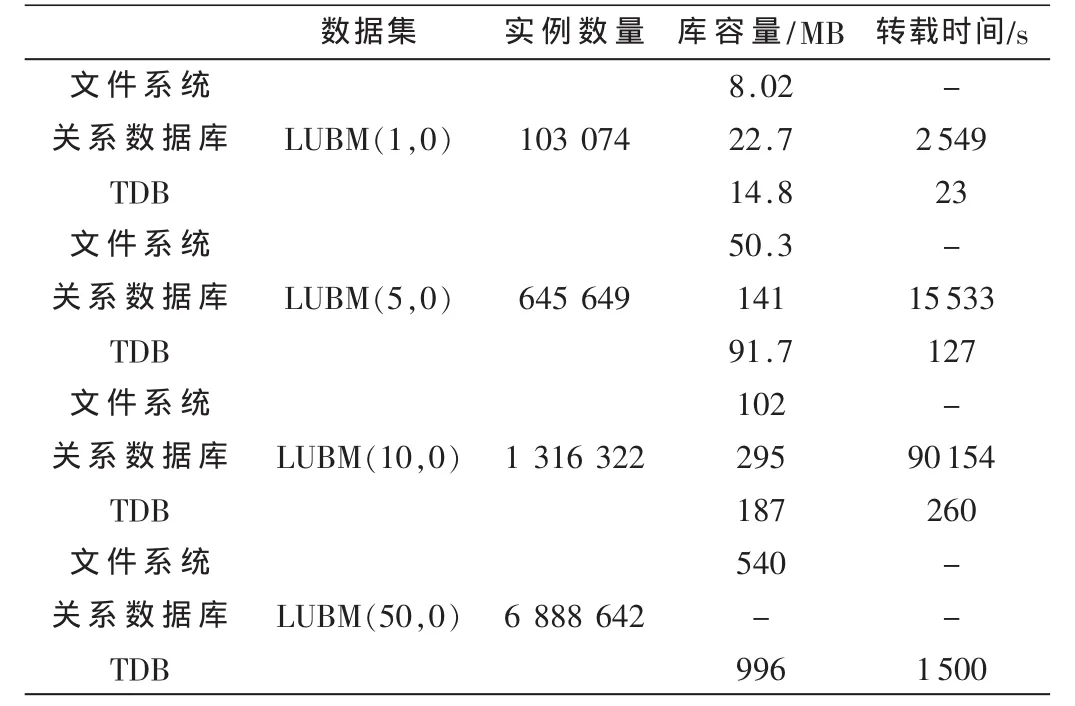
表1 库容量和转载时间比较
对于上面提到的3个Sparql查询语句,在用文件系统、关系数据库和TDB这3种不同的存储方式存储时,查询所消耗的时间和查询结果如表2所示。
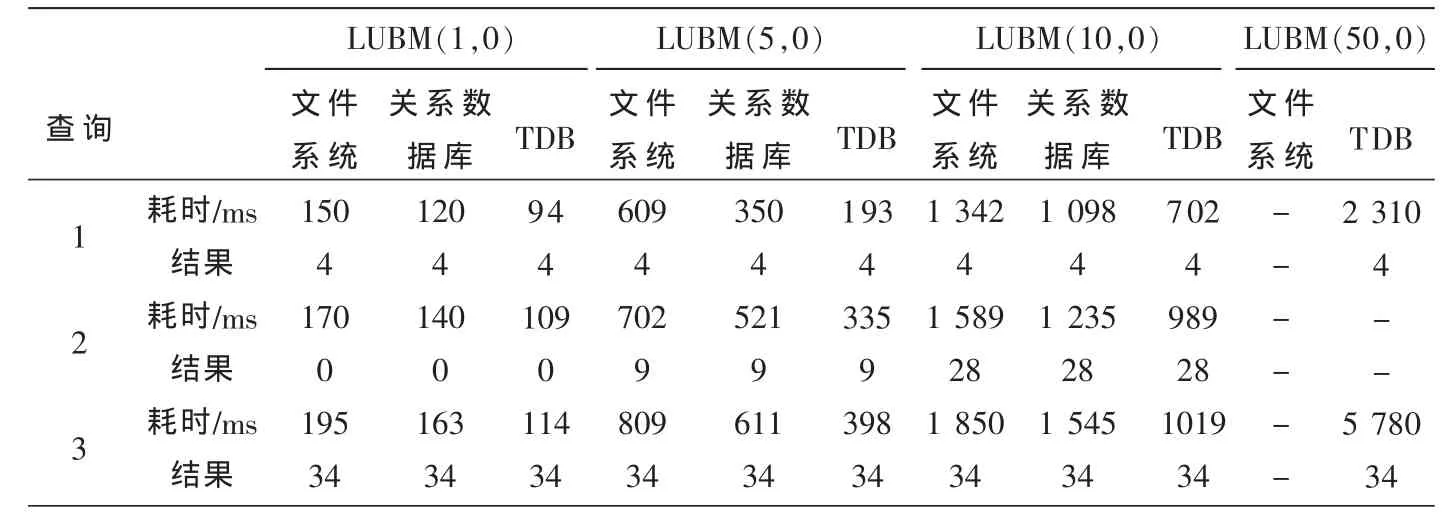
表2 查询测试结果
由表2可知,TDB在查询方面要比文件系统和关系数据库的效率高。
针对目前语义检索领域中基于文件或者关系数据库存储方案下检索效率慢的问题,本文分析了这几种存储方案在查询响应时间和存储空间上的区别,并提出了基于TDB的知识库存储方案。实验证明,该方法能较大程度上提高用户检索效率,并且能降低存储所需空间。基于本体的语义检索的知识中,推理机还没有涉及。如果添加了推理机,语义检索的速度将会更慢,因不属于本文研究内容,故没有作比较。
本体知识库的存储方案其实还有很多方式,如4store、BigData和BigOwlim等。由于能力有限,无法对每种方式进行比较,只对研究项目所用到的存储方式比较。这些将是以后研究工作中的重点。
[1]JARRAR M,MEERSMAN R.Ontologyengineering-the DOGMA approach[C].AdvancesinWebSemanticsI.Lecture Notes in Computer Science, 2009,4891:7-34.
[2] MILLER E. Semantic web applications[J]. INTAP Interoperability Technology Association for Information Processing, 2003(34):210-212.
[3] GRUBER T R. A translation approach to portable ontologies[J].Knowledge Acquisition, 1993,5(2):199-220.
[4]栾艳,丁二玉,骆斌.基于Ontology的语义检索技术[J].计算机工程与应用,2005,28(41):156-159.
[5]于水明.基于本体的语义检索的应用研究[D].大连:大连海事大学,2007.
[6]谢圣献,谢光.语义检索在电子商务中的应用研究 [J].微计算机信息,2008,24(12):50-56.
[7]Gao Yuanbo, Pan Zhengxiang, HEFLN J.An evaluation ofknowledge base systems for large owl datasets[C].Third International Semantic Web Conference,2004:6-7.
猜你喜欢
山东冶金(2022年2期)2022-08-08
哈哈画报(2021年10期)2021-02-28
制造技术与机床(2019年6期)2019-06-25
制造业自动化(2017年2期)2017-03-20
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
河北大学学报(自然科学版)(2015年1期)2015-02-27
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
江西理工大学学报(2013年1期)2013-03-20
