
基于空间分布支持向量机的图像分割
2012-01-15 02:54:42杨伟
延边大学学报(自然科学版) 2012年1期
杨 伟
(泉州理工学院 通识教育中心,福建 泉州362000)
基于空间分布支持向量机的图像分割
杨 伟
(泉州理工学院 通识教育中心,福建 泉州362000)
利用模糊聚类与支持向量机结合的方法,将图像的空间分布信息作为支持向量机的特征分量,并用模糊聚类获得的分类结果作为支持向量机的初始训练样本对图像的所有像素点进行分类,同一类中的像素点形成一个分割区域,以此获得图像分割.实验表明,该方法获得的图像分割效果较好,在一定程度上解决了特征维数过大所导致的维数灾难问题.
模糊聚类;支持向量机;图像分割;空间分布
图像分割是图像处理与机器视觉必不可少的重要环节,其方法很多,如阈值法、聚类法、区域生长法、神经网络等,但研究表明单一的图像分割方法难以达到理想的效果.近年来,随着新理论和新方法[1]的不断出现,多种特征的融合和多种分割方法的结合在图像分割中得到广泛应用,并取得了较好效果,如:文献[2]结合二维直方图和模糊C-均值聚类的方法,有效地抑制了噪声,并在充分考虑图像中各个像素的灰度值分布的基础上,克服了噪声和灰度不均匀敏感的缺点;文献[3]引入Fisher线性判别法对K均值的聚类图像分割做了进一步细化,克服了K均值聚类易受样本的几何形状及排列影响的缺点,同时实现了无监督聚类的图像分割.目前,关于如何选取有效的图像空间分布特征进行分类以及如何对一般灰度分布非线性的图像进行分类的问题研究得较少,由此本文以图像的空间分布作为分类特征信息,通过核函数将一般非线性灰度图像的特征信息映射变换到高维特征空间,并以支持向量机构造线性判别函数来实现原空间中的非线性灰度图像分割.
1 图像的空间分布信息
理想的图像分割不但要求所有的特征应当属于相同的目标区域,而且还要求他们在空间上应该紧凑,所以,成功的分割算法应当既用到图像像素的特征信息,又用到定位于图像像素的空间分布的信息.文献[4]提出了一种图像空间分布信息的度量的模糊聚类方法(FSCM),该方法在计算样本的离散性时同时考虑特征向量的离散性和空间位置的距离.
设图像定义为在W×H的矩形网格上的二维数据集S= {(i,j)∶1≤i≤W,1≤j≤H},其中(i,j)为图像像素的坐标.把坐标地址为s=(si,sj)的像素值x标为特征xs,索引s表示该像素在图像网格中的位置.为了能既利用图像的特征信息,又能有效利用图像的空间分布信息聚类,对特征xs和第r类中心vr的相异性的测量drs采用特征相异性dFrs和空间相异性dSrs的组合:

其中:α是加权因子;dFrs为传统的距离度量,表示xs与第r类原型vr特征离散性,公式为:

drSs的计算应满足性质:如果1个像素的位置处于目标区域内,那么应该认为它与目标区域类更有相似之处.
在图像网格中,定义每个像素位置s的邻域为ηs,邻域集η={ηs∶s∈S}.由于在同一邻域内的像素点彼此之间是相关的,因此,1个像素的空间相关关系可被描述为包含该点的邻域.如果xs邻域内的所有像素点都属于第r类,那么可以认为xs也属于第r类,并且归一化设定空间相异性drSs为0;反之,如果邻域内没有任何1点属于第r类,则认为特征xs不属于第r类,并且置drSs归一化为1;其他情况下drSs的范围选取在0~1之间,数值的大小对应于被第r类所拥有的邻域像素点个数.
基于以上思想,drSs的计算公式定义为:
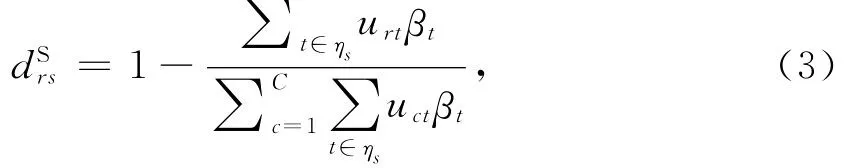
其中:c是所预想的分类个数;βt是s邻域ηs中的每个位置t的贡献因子,表示点t对全部空间的隶属关系;权值urs是特征xs对第r类vr的隶属度函数,它满足以下2个约束条件:


一般地,邻域越紧密,邻域内的点交互关系越强,而且各点的贡献越大.因此,对于每个邻近点t,βt在点s与点t之间是1个与距离相关的函数,定义为:
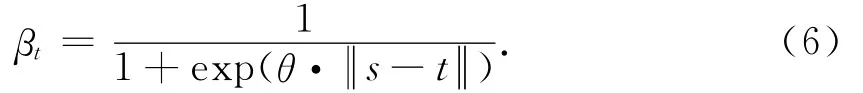
其中系数θ决定了2个点相互关系消失的快慢.θ值小表示邻域中不同点所做的相似贡献,θ值大表示空间的相异性更依赖临近的像素.本文经过多次实验,θ值设定为0.7.
2 基于空间分布的支持向量机
模糊聚类算法其迭代容易陷入局部极值、迭代过程中的计算量太大、空间结构信息未能有效利用、分割出来的区域不连续以及过分割等问题.而支持向量机(SVM)方法[5-8]以其优良的判别分类性能,克服了传统方法的过学习和陷入局部最小的问题,具有很强的泛化能力.本文将图像的空间分布信息作为SVM的特征向量分量,训练样本由模糊C-聚类得到初始分割提供(仅提供分类的数目,不知道其中类的属性).
假设存在训练样本(x1,y1),…,(xn,yn),x∈Rd,y∈{+1,-1},其中n为样本数,d为输入维数.当训练样本集线性不可分时,引入非负松弛变量ξi,i=1,2,…,n.分类超平面最优化问题描述为
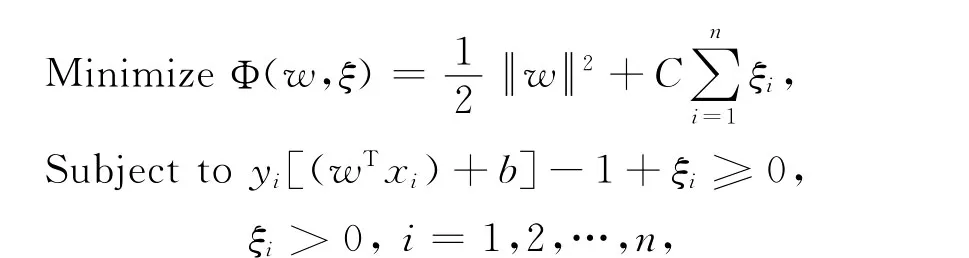
其中C>0为惩罚系数.对于样本线性不可分的情况,可以利用非线性变换φ(xi),i=1,…,n,将样本映射到某一更高维的特征空间中,使样本在这个高维的特征空间中实现线性正确分类.
通过求解最优化问题,可得到相应的最优决策函数:

在特征空间中样本之间的内积用核函数K(xi,xj)表示,因此上式可写为f(x)=sgn{wTφ(x)+分类超平面的权值向量w*和阈值b*为

其中x*(1)和x*(-1)分别表示2类中任意1个支持向量.在训练图像中随机选取n个训练样本点作为输入空间X={xn}和输出域Y={yn},其中xi= {x,dSi}= {x,dS1i,dS2i,…,dSki},x为图像样本点xi的特征分量,dSi= {dS1i,dS2i,…,dSki}为xi空间分布信息.由此可确定最优分类判别函数的参数〈w*,b*〉,对图像进行分割.
1)支持向量机参数的选择.核函数的选取直接影响支持向量机的性能[9].由于多项式核函数具有计算简单、识别率高的优点,因此本文采用多项式核函数:K(x,xi)= [σ(x·xi)+1]q.训练过程需要调整σ和q,通过采用网格搜索方式在二维参数空间遍历这2个参数,并观察其对图像分割的影响,得到最佳经验值q=3,σ=1.
2)惩罚因子C和输入样本个数的选择.惩罚因子C的选择应适中,如果C值过大,就会增大对错分样本的惩罚,导致错分样本减少,分类器的VC维增大,分类器的泛化性能变弱,程序运行时间过长;如果C值过小,就会减小对错分样本的惩罚,导致错分样本增多,分类器的VC维减小,分类器的泛化性能变弱,图像分割精度不高.经过实验发现,C=100时图像分割精度较为理想.
从图像随机选取n个样本作为训练样本输入空间X,并由模糊聚类分割已初分割图像选取对应的输出域Y,本文选取n=500.
3)空间邻域窗口的选择.对于图像的样本点s,邻域窗口可以选择3×3.点s邻域内的点对点s空间信息dSi的贡献由式(3)和式(6)决定.
4)SVM多分类方法选取.常用的多分类方法有一对多方法[10-11]、一对一方法[10-11]和k- 类SVM方法[12],由于一对多方法和一对一方法存在不可分区域,所以本文采用k-类SVM方法.该方法对于给定l个训练样本 (x1,y1),(x2,y2),…,(xl,yl),其中xi∈Rn,yi∈ {1,2,…,k},i=1,2,…,l,k个二类分类器通过求解一个优化问题同时获得,其中第i个分类器wTiφ(x)+bi将第i类的训练样本与其他训练样本分开,其决策函数为
综合以上描述,基于空间分布支持向量机图像分割的具体算法为:
第1步 先将图像进行模糊C-均值聚类,初步分得k个区域(k=1,2,3,…),其中将属于第r个区域的样本点标记为r.令yr=r作为SVM的输出域Y= {yn}的元素,并由(3)、(6)式得到每个像素点空间特征分量dSi= {dS1i,dS2i,…,dSki}.
第2步 在图像中随机选取n个样本点{xn}(n足够大)作为输入空间,每个样本点的特征向量为xi= {x,dS1i,dS2i,…,dSki},其中x是该样本点的像素值,dSri是像素点i对第r类的空间邻域信息.输出域Y={1,-1}(两类问题);或Y={1,2,…,k}(多类问题),则训练集表示为S= {(x1,1),…,(xk,k)}.
第3步 通过训练集求得第i个类的关联:一个权重向量和一个偏置,(wi,bi),i∈ {1,…,m},得到决策函数:
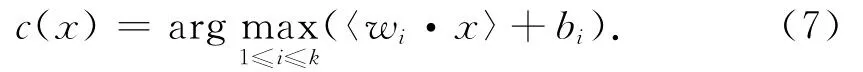
第4步 将特征向量xi代入(7)式,得出每个特征的分类yr=c(xi).将相同输出的特征向量归为同一类.
第5步 将得到的特征向量新分类重新作为训练样本返回第2步进行迭代.当第n次迭代属于第r分类像素数(Nnr)与第n-1次迭代属于第r分类像素数(Nn-1r)之差其中r=1,2,…,k,ε为较小正整数)时算法收敛结束迭代.
第6步 以该类任意支持向量样本点的第1个分量作为该类每个像素的灰度值,完成图像分割.
3 实验结果和分析
实验分别用模糊C-均值(FCM)、空间分布模糊C-均值(FSCM)、支持向量机(SVM)和空间分布支持向量机(SSVM)对细菌图进行两类分割,图片大小为256×256,领域为3×3.实验图像见图1,实验结果如下表1.分割错误率的计算公式为:,其中N为图像中所有像素的个数,Nr为分割参考图中属于第r分类的像素个数,N′r为算法分割结果属于第r分类的像素个数,r=1,2,…,k,k为所分类数目.

图1 4种不同分割方法结果图

表1 4种不同方法分割错误率的比较
实验表明:单纯的模糊C-均值图像分割的识别率最低,空间分布模糊C-均值的识别率相对模糊C-均值有所提高;支持向量机和空间分布支持向量机之间的差别不大,它们的识别率比模糊聚类有大幅地提高,达到了很好的效果(90%).实验表明融合模糊聚类支持向量机的方法优于单纯的模糊聚类方法.
4 结论
本文算法结合了图像的灰度和图像空间分布信息,并以此作为支持向量机的特征向量,通过融合2种图像特征,克服了聚类算法的不足,是对多种特征、多种方法融合的图像分割的一种尝试.本文讨论的分割算法都只是针对灰度图像,引用的特征有限(一幅图像包含颜色、灰度、纹理等多种特征),如何从图像提取到合适的分割特征,以及综合多种重要特征来作为支持向量机的特征分量,是需进一步研究的问题.
[1]林瑶,田捷,罗希平.图像分割方法综述[C]∥全国信息与自动化技术推广应用大会论文集.北京:中国自动化学会,2001:86-97.
[2]甄文智,范九伦,谢维信.基于二维直方图的图像模糊聚类分割新方法[J].北京:计算机应用工程,2003,39(15):89-91.
[3]Clausi D A.K-means Iterative Fisher(KIF)unsupervised clustering algorithm applied to image texture segmentation[J].Pattern Recognition,2002(35):1959-1972.
[4]Xia Yong,Feng Dagan,Wang Tianjiao,et al.Image segmentation by clustering of spatial patterns[J].Pattern Recognition Letters,2007(28):1548-1555.
[5]Boser B,Guyon I,Vapnik V.A training algorithm for optimal margin classifiers[C]∥Proceedings of the 5th Annual Workshop on Computational Learning Theory.Pittsburgh:ACMPress,1992:144-152.
[6]Cortes C,Vapnik V.Support vector networks[J].Machine Learning,1995,20(3):273-297.
[7]Scholkopf B,Burges C,Vapnik V.Extracting support data for a given task[C]∥Proceedings of First International Conference on Knowledge Discovery &Data Mining.Menlo Park:AAAI Press,1995:262-267.
[8]Vapnik V.Statistical Learning Theory[M].许建华,张学工,译.北京:电子工业出版社,2004:324-360.
[9]付岩,王耀威,王伟强,等.SVM用于基于内容的自然图像分类和检索[J].北京:计算机学报,2003,26(10):1261-1265.
[10]Hsu C W,Lin C J.A comparison of methods for multi-class support vector machines[J].IEEE Transactions on Neural Networks,2002,13(2):415-425.
[11]Weston J,Watkins C.Multi-class support vector machines[D].London:Technical Report,1998.
[12]Platt J,Cristianini N,Taylor J.Large margin DAGs for multiclass classification[C]∥Proceedings of Neural Information Processing Systems.Boson:MIT Press,2000:547-553.
Image segmentation based on SVMusing spatial patterns
YANG Wei
(CenterforGeneralEducation,QuanzhouInstituteofTechnology,Quanzhou362000,China)
We propose a ne whybrid methods for image segmentation that base on support vector maching(SVM)combined withC-mean fuzzy clustering.This method spatial pattern information is used as component characteristics of the SVM,and the classification results from fuzzy clustering are used as the initial samples of the SVM.Then the pixels of the image are classified by SVMand the pixels in the same class form a segmental region.The experimental results sho wthat the ne wmethods combing fuzzy clustering and SVMcan get better results and the error ratio caused by the segmentation is decreased.
fuzzy clustering;support vector machines;image segmentation;spatial patterns
TP391.4
A
1004-4353(2012)01-0083-04
2011-11-29
杨伟(1981—),男,助教,研究方向为小波分析及其应用.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
自动化学报(2018年7期)2018-08-20 02:59:04
电子测试(2017年15期)2017-12-18 07:19:27
周口师范学院学报(2016年5期)2016-10-17 06:36:47
CHIP新电脑(2016年3期)2016-03-10 14:22:03
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
