
基于贝叶斯分类器和条件随机场模型的词义消歧对比研究
2011-12-31 13:42屠明萍
文教资料 2011年36期
屠明萍
(南京师范大学 文学院,江苏 南京 210097)
词义消歧就是在某个特定的上下文中,确定某个多义词在该上下文中特定义项的过程[1]。词义消歧作为一个中间任务,对自然语言处理十分重要,很多应用都需要经过词义消歧才能更好地发挥作用,比如机器翻译、信息检索、自然语言内容语义分析、语法分析、语音识别和文语转换等都需要词义消歧的结果。词义消歧是一种自然语言处理技术,它根据知识获取的方法可分为两种:一是基于词典的消歧方法,指把机读词典(语文词典或义类词典)作为外部知识源,它本质上是一种基于规则的方法,有时也用到简单的统计,但并非语言模型意义上的统计;二是基于统计的消歧方法,由研究者给出多义词形的义项数并分义项提供训练用的例句,例如贝叶斯分类器(Naive Bayes Classifier,NBC)。
条件随机场模型(Conditional Random Field,CRF)自从被引入自然语言处理以来,在词性标注、专名识别和语义角色标注中都取得了很好的效果,而它在词义消歧任务中的出色表现更是吸引了很多人的注意。本文通过“保守”一词的词义消歧实验将贝叶斯分类器和条件随机场模型的消歧效果进行了比较,进而根据实验结果对比分析两种模型的优缺点。
1.两种典型的词义消歧模型概述
1.1贝叶斯分类器(NBC)
贝叶斯分类器是一种用于单点分类的概率模型,是贝叶斯公式的推广,适合处理单点分类问题。所谓“单点分类”,是指序列中的一个符号对应于什么状态,与序列中的其他符号对应于什么状态无关。它用来做词义消歧时遵循的基本思路是考虑歧义词周围的其他词的信息,把上下文(观察窗口)看成词的集合(词袋),根据这些信息进行词义消歧。对于词义消岐来说意味着:窗口中的词序和结构不重要,窗口中的词都是独立地起作用,这就是朴素贝叶斯假设。贝叶斯分类器的消歧算法如下:

forallsensesskofw{score(sk) =logP(sk);forallwordsvjinthewindowc score(sk) +=logP(vj|sk);}chooses’=argmaxskscore(sk);
这类似于一个投票过程:k个词义,好比k个候选人。每个词义的选票数相同。每个词义本身的费用,是一张保底的选票。Baseline消岐算法只看这一张选票。其余选票数(线索词个数)不大于窗口宽度,可能是赞成票(正数),也可能是反对票(负数)。投票结束时,累计费用最小的词义“当选”,即为消岐结果。
1.2条件随机场模型(CRF)
1.2.1条件随机场概述
条件随机场是一个在给定输入节点(观察值)条件下计算输出节点(标记)的条件概率的无向图模型,特别擅长处理序列标记问题。(2)其公式表示为:

pλ(Y|X)是求在λ参数制约下类别向量Y的条件概率
Z(x)是归一化因子。n是序列长度,m是特征函数个数。特征函数fi有两种:一是状态特征函数,二是转移特征函数。
1.2.2CRF训练和标注的相关文件及格式
用条件随机场模型进行训练有两个输入文件,一是训练语料,二是特征模板。训练语料有特定的格式要求,它由若干行组成,每行的列数必须相同,第一列是待分类的token,最后一列是类别标记。若干个连续的tokens组成一个sentence,每个sentence后面有一个空行,文件结束时再加一个空行。表1是本文所用到的条件随机场训练文件的一部分。其中第一列是词,第二列是词性,第三列中只对歧义词进行词义标记,其它词的词义都用none标记(如左图表1)。

?
特征模板是训练出模型必不可少的条件,它的基本格式是%x[row,col],其中row表示与当前token的相对行数,col表示列的绝对位置。特征可分为原子特征,一元复合特征和二元特征。表2是一个CRF特征模板样本及其意义解释。
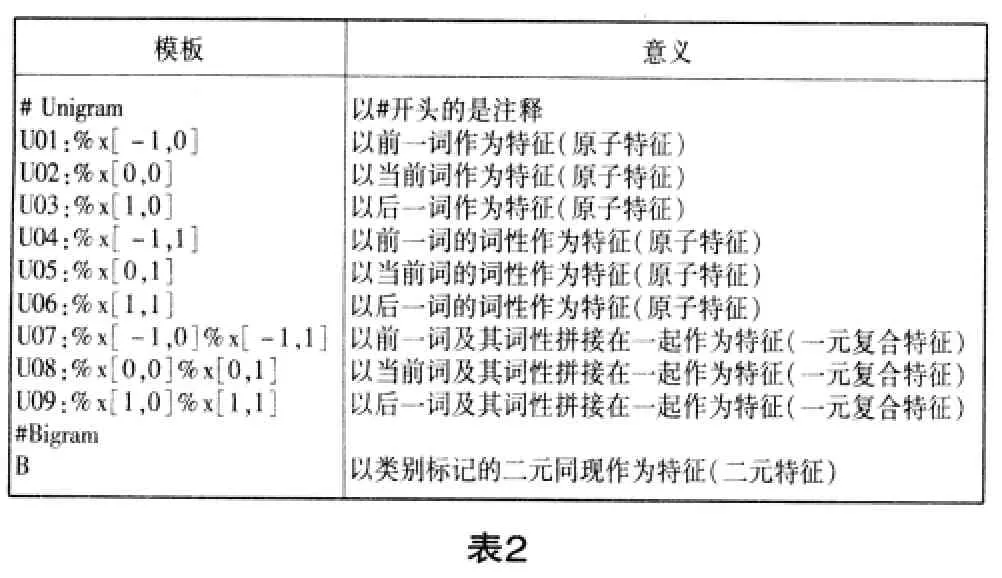
?
CRF训练有一个输出文件,即模型文件。CRF标注同样有两个输入文件和一个输出文件。输入文件包括测试语料和模型文件,测试语料的格式与训练语料大致相同,但可以没有标记。本文的测试语料是有标记的,这是为了便于评测正确率。测试所用的模型文件就是训练得到的模型文件。标注的输出文件就是标注好的语料,其结果是在测试语料增加一列类别标记。
2.实验过程
2.1实验前的准备
本文是为了比较两个模型在词义消歧任务上的优劣,所以实验分为两部分,一是基于贝叶斯分类器的词义消歧实验,二是基于条件随机场模型的词义消歧实验。本次实验的操作平台为Windows7系统。基于条件随机场的训练和测试采用TakuKudo编写的工具包“CRF++0.47”。(下载地址:http://crfpp.sourceforge.net/)。
两个实验所用的语料都是来自1998年上半年《人民日报》的1356句包括“保守”一词的句子,因为“保守”是一个典型的多义词,一个意思是“严守”,另一个意思是“守旧”。其中,用1260句作为训练语料,另外96句作为测试语料。训练语料和测试语料都经过分词和词性标注。
2.2贝叶斯分类器词义消歧
用贝叶斯分类器做词义消歧的实验分为三个步骤:训练、分类和评测。
训练阶段,设定训练文件的上下文窗口为5,在每个句子前人工标注该句中“保守”的正确意义。训练得到模型,即线索词及其词频信息。分类阶段,加载训练得到的模型,输出词义消歧的结果。评测阶段,制作测试文件的标准答案,并对消歧结果计算其召回率。
2.3条件随机场模型词义消歧
基于条件随机场模型的词义消歧实验同样分为三个步骤:训练、标注和评测。
训练阶段,首先要用转换程序将普通文本格式的训练语料转换为条件随机场模型特定的训练文件格式。然后,也是最重要的一步,就是特征模板的确定。多义词的一个显著特点是,意义与词性之间存在密切联系,词性不同,往往意义也不同。根据这一特点,此次实验采用的7个模板有6个加入了词性特征,只有1个未加词性特征,以观察词性特征对词义消歧的贡献。这7个模板及其解释如表3所示。(表中的“∪”表示取并集)
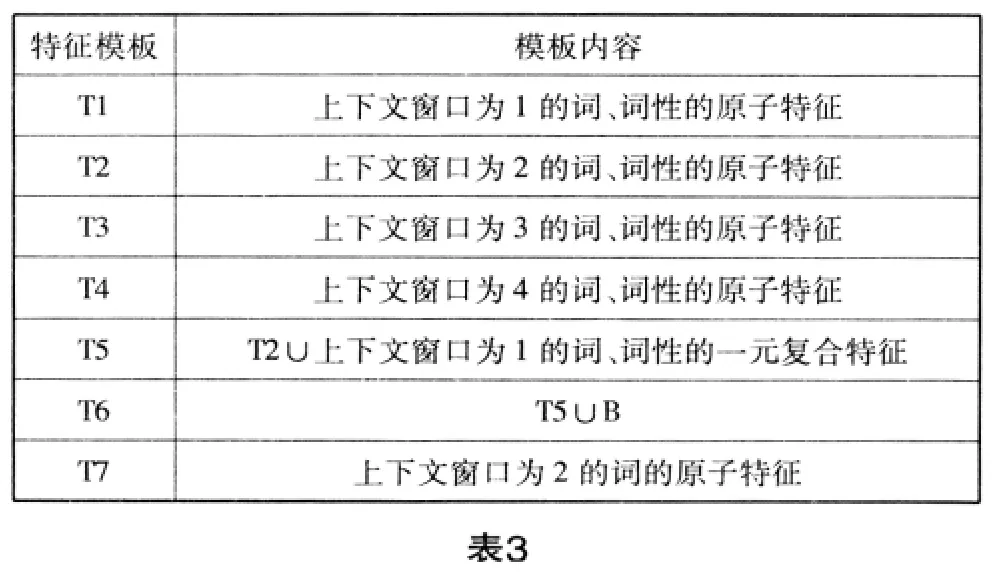
?
训练时添加特征模板、训练文件及一个空的模型文件,再进行一些参数的设置,即得到了模型文件。标注阶段,在标注窗口添加模型文件、已转换成相应格式的测试文件以及一个空的标注结果文件(用于输出)。评测阶段,用CRF评测程序对标注结果进行评测,得出词和句子的标注正确率。
3.实验结果及分析
3.1CRF词义消歧结果分析
基于条件随机场的消歧实验使用了7个不同的特征模板,所以有7个消歧结果,并且每个结果都有封闭测试和开放测试结果,而封闭测试和开放测试都有其词正确率和句子正确率。关于实验结果的评价指标,本文采用召回率(R),其计算公式如下:
召回率(R)=正确标注的个数/待标注多义词的个数
具体数据如表4所示。
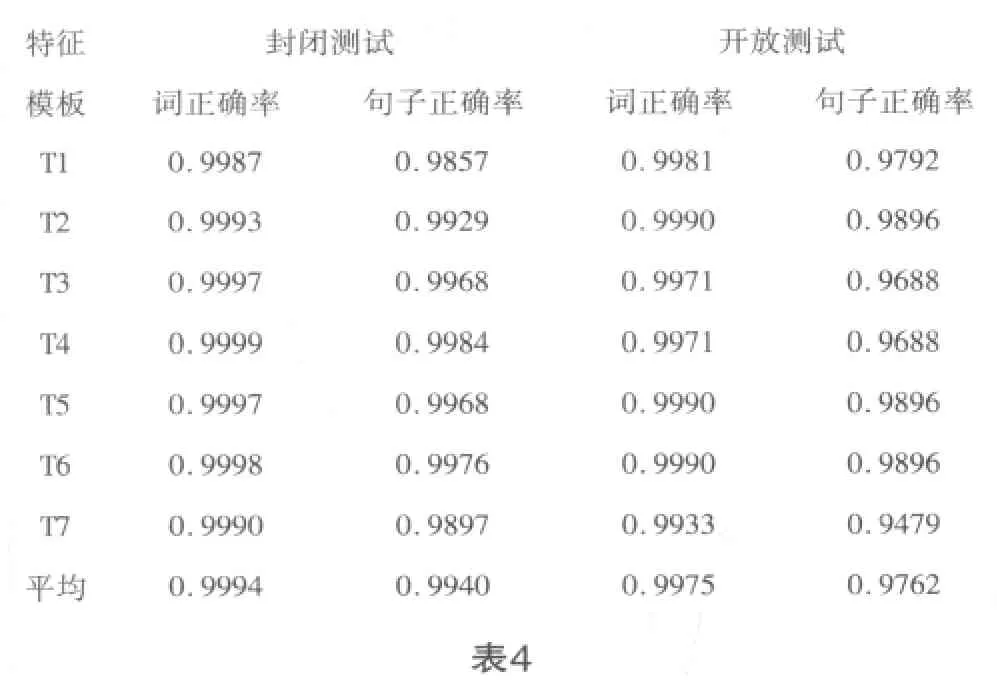
?
结合表5我们可以更清晰地看出各个消歧正确率的对比。7个模板的封闭测试词正确率和句子正确率都在99%以上,且词正确率和句子正确率差距很小,这是因为此次实验只针对每个句子中的一个多义词进行消歧,其他词都标注为none。但是封闭测试并不能说明多大问题,主要是看开放测试正确率。让人惊喜的是,本次实验开放测试正确率也相当高,词正确率依然在99%以上,句子正确率也达到了97%以上。再看各个模板开放测试的结果。T1到T2窗口长度由1变为2,词正确率和句子正确率都提高了。T2到T4虽然窗口长度由2逐渐拓宽到4,但词正确率和句子正确率反而下降了,这说明窗口长度在2时达到最佳消歧效果,再加大窗口长度只会增加噪声,不利于消歧。T5由T2再加上上下文窗口为1的词和词性的一元复合特征,正确率并没有提高。这说明在本次实验中一元复合特征对消歧结果并无影响,但是不排除在其他实验中有作用,至于是积极作用还是消极作用有待于以后更深入的研究。T6是在T5基础上增加了二元特征,但结果表明消歧正确率并未因此而提高。T7和T2相比少了词性特征,正确率降低了不少,特别是句子正确率,是所有模板中正确率最低的。这说明词性特征对词义消歧作用是非常积极的。这根汉语多义词的特点有关,很多多义词由于词性不同意义也会不同,例如本次试验中的“保守”作为严守义是动词,而作为守旧义是形容词。
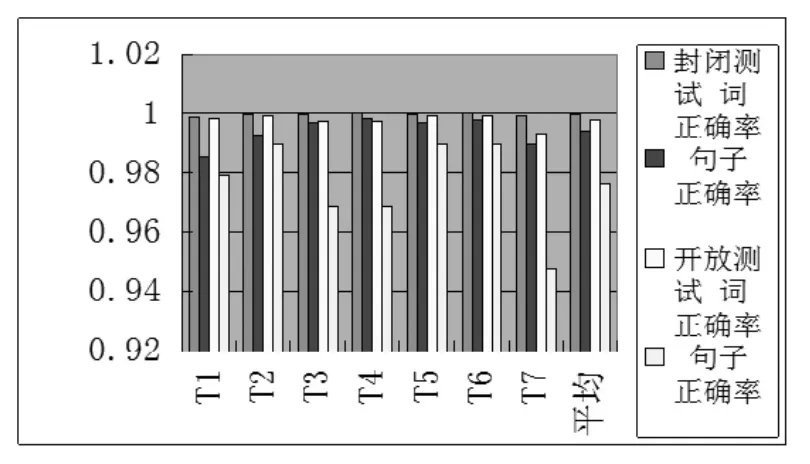
表5
3.2CRF与NBC词义消歧结果对比分析
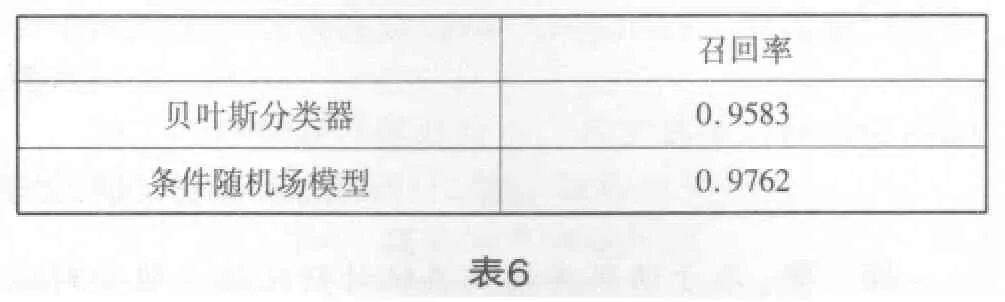
贝叶斯分类器的结果只有一个,而条件随机场模型词义消歧的结果有若干个,究竟取哪个与贝叶斯分类器作比较呢?我们发现,条件随机场模型消歧实验开放测试结果中的句子正确率其实就是我们所要使用的评价指标(召回率),因为它反映了词义标注的实际结果。为了更公平地比较两者的消歧效果,我们用条件随机场实验的句子正确率的平均值与贝叶斯分类器的召回率作比较。具体数据见表6。
?
显然,条件随机场模型的消歧效果要优于贝叶斯分类器的消歧效果,在本次实验中前者比后者要高出1.8个百分点。条件随机场模型能出色地完成词义消歧任务与该模型的特性是分不开的。CRF模型较好地克服了输出独立性假设和马尔科夫性假设的局限性,能从上下文中任意地选择所需要的特征,并且有很强的特征组合能力。特别是在本次实验中,词性特征显示出极为重要的作用,正是因为这一点,条件随机场模型在词义消歧任务上要明显胜于贝叶斯分类器。
然而不得不提的是,贝叶斯分类器虽然在最终消歧结果上不及条件随机场模型,但是它的训练简单省时,而条件随机场模型需要在训练之前准备好特征模板,而且参数过大,训练时间较长。在这一点上贝叶斯分类器又有其优势。
4.结语
本文采用贝叶斯分类器和条件随机场模型分别在同等规模的训练集和测试集上进行了词义消歧的对比实验。在理论上条件随机场模型能从上下文中任意地选择所需要的特征,而且有很强的特征组合能力,而贝叶斯分类器只对上下文的词形做训练,所以消歧结果应该是条件随机场模型优于贝叶斯分类器,而实验结果也证明了这一点。但是在训练复杂度上,条件随机场模型要比贝叶斯分类器更为复杂一些。本文的实验还有一些不足的地方,比如条件随机场模型的特征选择,除了词和词性以外应该还可以增加其他特征以提高消歧正确率,这就需要更深入的研究了。
[1]黄昌宁,夏莹.语言信息处理专论[M].北京:清华大学出版社,1996:78-101.
[2]丁德鑫,曲维光,徐涛,董宇.基于CRF模型的组合型歧义消解研究[J].南京师范大学学报(工程技术版),2008,8,(4):73-76.
[3]苗雪雷.基于条件随机场的汉语词义消歧方法研究[D].[硕士学位论文].沈阳:沈阳航空工业学院,2007.
[4]王达,张坤.贝叶斯模型在词义消歧中的应用[J].计算机时代,2009,(7).
[5]于丽丽,丁德鑫,曲维光,陈小荷,李惠.基于条件随机场的古汉语词义消歧研究[J].微电子学与计算机,2009,(10).
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15
哈尔滨工程大学学报(2020年8期)2020-11-13
西夏研究(2020年1期)2020-04-01
新高考(英语进阶)(2018年3期)2018-05-14
电脑与电信(2018年12期)2018-03-23
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
语言与翻译(2014年3期)2014-07-12
郑州大学学报(理学版)(2014年2期)2014-03-01
