
指标筛选技术在神经网络数据挖掘模型中的应用
2011-12-14 07:25:58米帅军
统计与决策 2011年10期
习 勤,米帅军
(华东交通大学 经济管理学院,南昌 330013)
指标筛选技术在神经网络数据挖掘模型中的应用
习 勤,米帅军
(华东交通大学 经济管理学院,南昌 330013)
文章以分类神经网络中的RBF网络为例,讨论了神经网络数据挖掘模型中指标筛选的重要性,并以信用卡欺诈检测神经网络数据挖掘模型为实证案例,演示了指标筛选方法能有效地提高神经网络模型的分类效率与收敛速度,同时,讨论如何针对数据挖掘主题与数据特点选择合适的指标筛选技术。
数据挖掘;神经网络;指标筛选;信息增益
0 引言
根据Universal Approximation Theore[1],即神经网络具有对任何复杂函数的模拟逼近功能,这为神经网大规模应用提供了强有力的理论依据。由于神经网络是基于生物神经网络的模拟,通过不断学习来认识事物潜在的规律。同时,由于神经网络没有对数据分布进行相应的假设,这使神经网络在各行业中的应用具有广泛的适用性。另一方面,由于没有对数据分布进行假定,使神经网络对噪声数据具有相当的柔性,这进一步使人们在面对高维空间与海量数据时,更偏向于采用基于生物模拟的神经网络,而非基于传统的统计分析与计量方法,如多元统计分析等。但是,神经网络的柔性与通用逼近性在实践中有时并未给研究分析带来理想的效果,其根本原因在于,直接导入高维空间数据致使神经网络的效率急剧下降,也使得神经网络很难满足实时响应的要求,如实时欺诈监控、实时风险评级、工业实时控制等。因此,本文针对神经网络的应用,提出了高维空间的预处理,即指标筛选。
1 神经网络的基本原理
人工神经网络(Neural Networks)是对生物神经网络进行仿真研究的结果。它通过采集样本数据进行学习的方法来建立数据模型,系统通过样本不断学习,在此基础上建立计算模型,从而建立神经网络结构[2]。神经网络通过训练后可以执行复杂函数的功能,能对所有函数进行逼近,即Universal Approximation Theorem。这就是说,如果一个网络通过训练后呈收敛状态,那么神经网络就具备了执行输入到输出这种线性或非线性的函数功能。当然,这种函数不是基于理论或经验的假设,而是基于对样本的有监督的训练,使神经网络具备了模拟复杂系统的功能。根据数据挖掘主题的类型,神经网络可分为分类神经网络(含预测)与聚类神经网络。本文实证分析部分采用神经网络中的RBF网络,RBF网络属于分类神经网络,其拓扑图与学习原理可参阅相应文献[3]。RBF神经网络除了具有神经网络的相应优点外,还有两大缺陷,一是网络的训练时间较长,或需要高性机能计算机设备,当然,除非工业级的实时监控上的应用,对一般的经济分析而言,这点不足为虑。另一个不足是研究者不能得到一个基于样本训练出来的分类函数,也即不能对输入输出进行结构分析,这也是所有神经网络模型的一大缺憾。
2 指标筛选技术
数据挖掘需要处理的是海量的数据集,且变量(或指标)非常多(一般都在50个以上,称为高维空间),由于不知道相应的规则或模式,收集更多的样品指标以防止遗漏重要解释变量,但是这不等于把所的指标都应用数据挖掘建模,这样会严重影响建模的效率与对挖掘结果的解释,少量的指标有利于模型的结构解释。因此,在建模之前必须对指标进行筛选,以挑选出对目标变量或模式有重要影响的变量。
指标筛选即指标归约,是指用部分指标来代替原有的指标体系,即进行适当降维。降维的方法主要有两类,一是选择指标的子集来代替原有的指标体系,如相关分析、回归分析、信息增益与模糊集等。二是对原有指标进行变换,转化成新的综合性指标,如主成分分析。本文所述的指标筛选是子集的选择。
指标选取的方法有多种,常用的是相关分析,基于Pearson相关定理。本节重点介绍基于回归分析与信息增益的指标筛选方法。
与相关分析不同,基于回归分析筛选方法试图从线性因果关系来说明各个自变量对因变量的影响程度与方向。基于信息增益的指标筛选方法与上述两种方法完全不同。信息增益方法源于熵理论,即热力学第二定律,目前在社会学科、管理科学以及空间科学上取得了相当多的成功应用,其基本思想是以指标的信息含量来评价指标的重性,进而筛选指标。
2.1 基于回归分析的指标筛选原理
回归分析有线性与非线性之分。线性回归分析适用于取值范围不大的指标,以防止个别指标值对回归线产生较大的拉近作用,使回归线过分拟合异常值(或端点值)。回归分析指标筛选方法有:前进法(Forward)、后退法(Backward)以及步进法(Stepwise)。其基本原理如下:
Forward是在回归模型中逐步加入指标,直到没有满足一定显著性要求的指标为止。对已入选择的指标在有新的指标加入后,其显著性是否符合要求不再进行检测,即“只进不出”。显著性检测一般采用Fj偏检验。
Backward是先把所有的指标纳入到回归模型中,然后根据显著性水平,剔除显著性水平最低的指标(即T值绝对值最小的,且不显著性),再由剩下的指标重新拟合回归模型,并剔除T值最小的指标,如此循环,直到所有指标都达到一定的显著性要求为止。Backward最大的特点,也即缺点是对已剔除的指标不再有机会入选回归模型,即“只出不进”。
Stepwise是Forward与Backward的结合,也是最为常的回归筛选指标的方法。其基本过程与Forward类似,不同之处在于对已剔除的指标还有机会重新选入模型,即 “有进有出”。最为关键的是分别对剔除与选入设定了不同的显著性水平,且剔除的显著性水平αout小于进入的显著性水平αin,即所谓的“宽进严出”,否则会产生引进后再剔除这样的循环过程。
基于回归分析的指标筛选应用的关键在于对回归函数形式的假设是否与实际相符,同时指标的显著性检验需要对数据分布作相应的的假设。其优点是可以从结构上说明各指标的重要性。
2.2 基于信息增益的指标筛选原理
在进行数据挖掘时,要确定使用哪些指标,除了基于成功的经验与先验理论外,一般比较困难,况且数据挖掘的目标是发现潜在的有兴趣的模式与规律。也就是说,事先没有一定的理论认识,如有相当的认识,则可以采用其它统计手段进行分析。如果采用的指标太少,会降低数据挖掘的效果。如果选用的指标太多,会产生指标间的共线性,导致挖掘主题被“淹没”,如在判别分析中不能得到判别函数,同时参数的标准差将增大,显著性检验失效。因而,指标筛选成了数据挖掘的关键之一。
在介绍信息增益方法前,先对熵(entropy)的概念做相应解释。熵是对数据集的随机性的一种度量,是一种量化信息的概念。爱因斯坦曾指出热力学的第二定律(熵理论)是联系自然界与人类社会的桥梁,由此可见熵理论的重要性。熵理论目前已广泛应用于信息科学、管理科学与环境空间科学等。熵表达了一种物质状态所能提供的信息,如果熵小,则物质呈现出一种相对有序的状况,这就意味着所包括的信息量较少。对统计分析而言,如果一个数据集中的所有数据都属于同一类,概率取值为1,则没有不确定性,此时的熵取值为0。
假设有一个数据集S(一个样本),被解释变量(指标)为0,有 r个指标值(o1,o2,…,or),根据 o的取值可以把数据集 S划成 r个子集(s1,s2,…,sr),显然有 S=(s1∪s2∪…∪sr),s1∩s2∩…∩sr=φ。任一样品属于si概率为pi,则对样本S分成r类所需要的信息为:
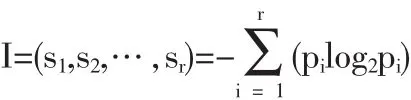
采用以2为底的对数log2pi,是因为信息编码采用二进制方式。
解释变量(评价指标)为 Ai(i=1,2,…,n),任取一个指标Ai,Ai有 m 个取值(a1,a2,…,am),根据指标 Ai的取值可能把数据集 S 划成 m 个子集(sa1,sa2,…,sam),显然有 S=sa1∪sa2∪…∪sam,S=sa1∩sa2∩…∩sar=φ, 则 sk与 sal交集为 Ckl=sk∩sal。令 nkl为 Ckl中的样品数目,其中(k=1,2,…,r,l=1,2,…,m)则根据指标Ai对样本S进行分类所需要的信息称作Ai的熵,记为E(Ai)
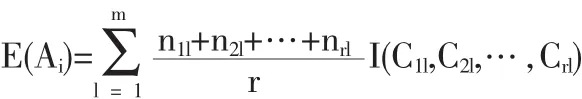
则Ai上该划分所获得的“信息增益”定义为:
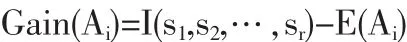
通过上述方法,可以计算每个n指标的信息增益,按信息增益从大到小的顺序选取部分指标作为评价指标。
比较回归分析指标筛选技术与信息增益指标筛选技术的原理,可以发现,除离散化之外,基于熵理论的信息增益方法对数据分布没有相应的假设,同时信息增益技术在决策树ID3与C4.5算法中起着支撑作用。一般而言,在没有数据的分布信息的情况下,使信息增益进行指标筛选更为合理。
3 基于指标筛选技术的RBF神经网络信用卡评级分析
3.1 数据来源与软件工具说明
基于指标筛选的RBF神经网络信用卡评级分析所用的数据集为DMAGECR与DMAGESCR,由SAS公司提供,分别用于模型的训练、测试。记录数分别为1000、75条,共有21个指标。目标变量为risk,“1”表示欺诈,“0”表示正常。
分析工具采用SAS/STAT,SAS/EM4.3。SAS/STAT主要是用于一般的统计分析,SAS/EM4.3主要用于决策树。
RBF神经网络数据挖掘流程如图1所示。
3.2 指标筛选

由于目标变量risk为二值型,采用Logistic回归分析进行指标筛选,方法为Stepwise。指标筛选结果,按显著性依高到 低 为 :CHECKING、INSTALLP、SAVING、PURPOSE、MARTIAL、DURATION、AMOUNT。
根据信息增益理论可得各指标的信息增益比,前六个指标值分别为:CHECKING=0.052,HISTORY=0.026,DURATION=0.022,AMOUNT=0.020,SAVING=0.015、PURPOSE=0.012
综合回归分析指标筛选结果与信息增益指标筛选结果,可以发现,衡量客户是否存在欺诈与社会人口信息类指标相关性不强(只有MARTIAL,即婚姻状况),而与客户的消费储蓄行为较为密切。两类指标筛选结论基本一致,但是在具体指标选择上还是有较大差别,其原因主要是两者的原理不同,判断指标重要性的标准不同。
上述指标筛选结论说明两个问题:一是对于信用卡欺诈建模,客户的社会人口方面的信息并不重要,是否存在欺诈与客户行为密切相关,这种简化的数据结构给经济行为结构分析带来了便利。二是在进行数据挖掘时,如果把所有的相关性不明显的指标纳入分析模型,有可能导致模型的挖掘性能大为下降,同时也会给后续的结构分析带来困难。对于一些不具有伸缩性(Flexible)的挖掘模型(如回归分析等),过多的指标不利于提取数据结构信息,即使是对一些伸缩能力很强的挖掘模型(如神经网络),指标太多也会降低挖掘模型的性能,使模型的泛化能力下降。
3.3 基于指标筛选技术的RBF神经网络数据挖掘分析
信用卡欺诈分析RBF神经网络数据挖掘,分别采用所有原始指标、基于回归分析的指标子集与基于信息增益的指标子集作为输入数据结构,以便比较其对应的准确率。
建模流程如图2所示。
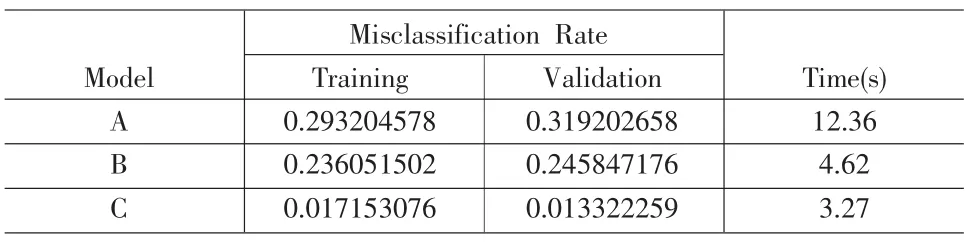
表1 RBF神经网络模型分类效率对比表
图2中SAMPSIO.DMAGECR功能为选取数据集,Data Partition功能为抽取样本,Neural Network功能为建立RBF神经网络模型。
分析结果对比如表1所示。
从表1可以发现,C模型的分类错误率较低 (0.017),且训练误判率(0.017)高于验证误判率(0.013),说明C模型具有较强的泛化能力。A模型采用原始所有指标,分类误判率较高(0.29),训练误判率(0.29)低于验证误判率(0.32),模型泛化能力较弱。对比B模型与C模型的分类误判率,可以发现,基于信息增益的指标选择,使RBF神经网络的误判率明显下降。其根本原本在于,基于回归分析的指标筛选对数据分布有一定的假定;而基于信息增益的指标筛选,除离散化外,对数据基本无要求。从RBF网络收敛速度来看,通过指标筛选能有效提高运行速度。由于本次实证只有1000条数据,采用指标筛选后,收敛速度提高3-4倍。经测试,对于20000条,指标87个的海量数据集,神经网络收敛时需1-2小时(运行于普通台式电脑),可见指标筛选对神经网络收敛速度有很大的影响。
4 总结
本文首先简要介绍了神经网络的基本原理与其在实践中的应用,指出了神经网络模型的高度柔性和处理高维空间数据的能力。其次,介绍了神经网络模型中指标筛选的必要性。再次,介绍几类常用的指标筛选技术,并着重介绍了回归分析指标筛选技术与信息增益指标筛选技术。最后,基于RBF神经网络数据挖掘模型(信用卡欺诈检测分析),比较了采用原始所有指标、回归分析子标集与信息增益指标集三种情况下,RBF模型的分类效率与收敛速度,进一步展示了指标筛选技术在神经网络模型中应用的必要性与可行性。事实上,本文所介绍的指标筛选技术适合于所有高维空间的降维处理与建模分析。
[1]Simon Haykin.Neural Networks:A Comprehensive Foundation (2ndEdition)[M].北京:清华大学出版社,2001.
[2]张云涛,龚玲,数据挖掘,电子工业出版社,2004
[3]张德丰,《MATLAB神经网络应用设计》[M].北京:机械工业出版社,2009.
[4]Jiawei Han,Micheline Kamber.Data Mining Concepts and Techniques[M].北京:机械工业出版社,2006.
[5]Mehmed Kantardzic.Data Mining Concepts,Models,Methodsand Algorithms[M].北京:清华大学出版社,2003.
O236
A
1002-6487(2011)10-0163-03
习 勤(1956-),男,江西南昌人,教授,研究方向:统计理论与方法。
米帅军(1974-),男,湖南长沙人,硕士,研究方向:统计方法与数据挖掘。
(责任编辑/亦 民)
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
大众投资指南(2021年35期)2021-02-16 01:06:26
电子制作(2019年19期)2019-11-23 08:41:36
电子制作(2019年24期)2019-02-23 13:22:26
电子制作(2018年19期)2018-11-14 02:37:02
西南交通大学学报(2018年5期)2018-11-08 10:58:04
电力与能源(2017年6期)2017-05-14 06:19:37
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20 15:25:20
知识产权(2016年8期)2016-12-01 07:01:32
信息通信技术(2015年6期)2015-12-26 01:16:46
