
短期负荷预测的聚类组合和支持向量机方法①
2011-10-30 01:57梁建武陈祖权谭海龙
电力系统及其自动化学报 2011年1期
梁建武, 陈祖权, 谭海龙
(中南大学信息科学与工程学院, 长沙 410083)
短期负荷预测的聚类组合和支持向量机方法①
梁建武, 陈祖权, 谭海龙
(中南大学信息科学与工程学院, 长沙 410083)
为提高电力系统短期负荷预测的精度,提出了一种基于聚类组合和支持向量机的短期负荷预测方法。该方法用SOM网络训练规格化的特征数据并获得初始聚类中心,将初始聚类中心作为C-均值算法的输入,并用DB指数评价聚类结果以获得最佳聚类数,通过训练可得相似日样本,最后选择合适的参数和核函数构造支持向量机模型来进行逐点负荷预测。预测结果表明,该方法比单一的支持向量机算法具有明显的优势。
短期负荷预测; 聚类组合; SOM网络;C-均值; 相似日
目前,短期负荷预测方法主要包括回归分析法[1]、时间序列法[2]、人工神经网络方法[3,4]、模糊预测法[5]和小波分析法[6,7]等。
支持向量机SVM(support vector machine)方法较好地解决小样本、非线性、高维数和局部极小点等实际问题[8],在时间序列预测问题上得到了应用[9]。但其预测精度在很大程度上依赖于训练集的选择,恰当、合理的样本可使预测方法快速、有效地逼进目标矢量,达到误差要求。
本文考虑到电力负荷变化的周期性和相似性特点,根据自组织映射SOM(self-organizing map)网自组织和C-均值算法高效率的特点,通过将两者组合进行聚类,引入DB指数[10]作为聚类质量评价标准,获取与预测日特征相似的相似日样本集,以克服传统SVM方法训练样本集过大的缺点,利用SVM模型对预测日96点负荷进行预测,取得了满意的预测精度。
1 基本原理与方法
1.1SOM算法
SOM神经网络是由Kohonen[11]首次提出的。SOM网络包含输入层和输出层两层神经元。输入层对应一个高维的输入向量,输出层是由一系列组织在二维网格上的有序节点构成,输入节点与输出节点通过权重向量连接。在每个输入样本学习过程中,SOM找出与之距离最小的输出层单元,即获胜单元,然后更新获胜单元及其邻近区域的权值,使得输出节点保持输入向量的拓扑特征。
SOM聚类的过程如下。
步骤1权值初始化。对输出层每个节点的权重wj赋随机数为初值。
步骤2从训练样本选取一个输入向量并进行归一化处理,得到xi,求wj中与xi距离最小的连接权重向量

(1)
式中:‖ ‖为距离函数,对于连续数值属性的数据集,通常采用欧氏距离。
步骤3定义g为获胜单元,Ng(t)为获胜单元的邻近区域,对于邻近区域内的单元,使其向xi靠拢的调整权公式为
wij(t+1)=wij(t)+η(t)(xi(t)-wij(t))
i=1,2,…,n;j∈Ng(t)
(2)
η(t)是学习速率,随着时间的增加而逐渐下降,一般可取为

步骤4缩小邻域半径,重复步骤2~步骤4,当训练的权值误差小于允许值或者达到预设的迭代次数时,训练结束,输出聚类结果。
1.2C-均值算法
C-均值聚类算法以C为参数,把n个对象分为C个簇,以使簇内具有较高的相似度,而簇间的相似度较低。相似度的计算根据簇中对象的平均值来进行[12]。其算法描述如下。
步骤1初始化。设定聚类类别数C及每个类别的初始聚类中心Z={Z1,Z2,…,Zc},X={x(1),x(2),…,x(n)}表示输入的样本向量,Si表示所有属于第i个聚类中心的样本集合,设定迭代停止阈值ε。
步骤2样本划分。对于所有的输入样本向量,x(p)∈Si,如果
‖x(p)-Zi‖<‖x(p)-Zj‖
j=1,2,…,C;i≠j
(3)
步骤3计算新的类聚中心
(4)
式中,Ni是属于集合Si中样本的数量。

经过C-均值算法划分后,同一个簇的样本具有最大的相似性,而不同簇的样本之间的相似性尽可能的小。
1.3 支持向量机回归算法
SVM最初用来解决模式识别问题,其分类算法能实现较好的泛化功能,随着Vapnik不敏感损失函数[13]的引入,SVM已经扩展到用于解决非线性回归估计问题。
设给定的训练数据集为
{(xi,yi)|i=1,2,…,L|}
x∈Rd,y∈R
(5)
其中,L为样本总数,构造回归估计函数f(x)=wφ(x)+b,w为权向量,b为偏差。系数w和b可以通过最小化回归风险来估计为
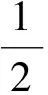
(6)
其中L(y,f(x))为损失函数定义为
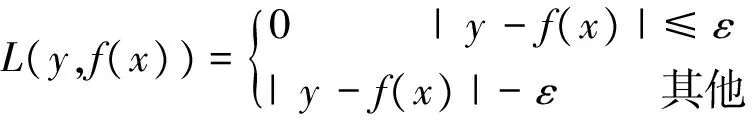
(7)

(8)

引入拉格朗日因子α和α*,得到
(9)
(10)
式中,K(xi,x)=φ(xi)φ(x)称为核函数,核函数是满足Mercer条件的函数。
2 预测模型设计
2.1 样本数据处理
考虑预测日的天气状况以及日期类型、季节类型对日负荷产生较大的影响,本文建立的样本特征值包括以下几类:A={a1,a2,…,ak},预测日前k日的预测时刻负荷数据;B={b1,b2,…,bl},预测日前一日预测时刻前后l个时段的负荷数据;C={c1,c2,…,cm} ,预测日及其前一日的气象数据,包括最高温度、最低温度、平均温度和湿度等;D={d1,d2},预测日的周属性,包括工作日和双休日;E={e1,e2,e3,e4},预测日的季节类型,包括春、夏、秋、冬等。
样本数据都需要进行规格化,对需要规格化的属性A,maxA,minA分别为属性A的最大值和最小值,属性A的一个原始数据v进行规格化处理后为v′,即

(11)
2.2 基于聚类组合和SVM的预测模型
本文提出的预测模型首先根据聚类组合算法选出与预测日具有相似特征的相似日,然后通过构造相似日训练样本作为SVM的输入进行学习训练,克服单纯SVM方法数据量大的缺点,以获得高精度的预测结果。该混合预测模型如图1所示。
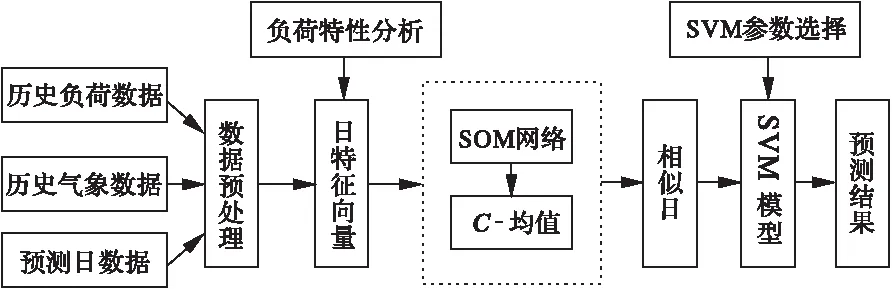
图1 基于聚类组合和SVM的预测模型
聚类组合算法的具体执行步骤如下。
步骤1权值初始化。对竞争层每个节点的权重wj赋随机数为初值,设置学习速率η(t)、领域的初始值Ng(t)以及总的训练次数N。
步骤2从训练样本选取一个输入向量xi,输入到网络输入层。
步骤3根据式(1)计算wj中与xi距离最小的连接权重向量wj。
步骤4根据式(2)更新获胜单元及其邻近区域Ng(t)内单元的权值,使其向xi靠拢。
步骤5选取一个新的输入向量给网络输入层,转到步骤3,直到输入向量全部输入到网络。
步骤6更新学习速率η(t),缩小邻域半径Ng(t),返回步骤2,迭代次数加1,当训练的权值误差小于允许值或者达到预设的迭代次数时,训练结束,输出聚类结果。
步骤7保存SOM网络中c个输出节点的权值,并用这c个权值作为C-均值算法的初始聚类中心Z={Z1,Z2,…,Zc},该聚类的DB指数计算式为
(12)
式中:Dk是所有子类的值到该类中心点距离的均值;Dk(Qi,Qj)是子类中心点之间的距离。当DB指数最小时,可求得最佳聚类数。
步骤8合并初始聚类中心最近的两个聚类,聚类数c=c-1,重新进行聚类,获得新的DB指数DB*,如果DB*≤DB,记录c为当前最佳聚类数,如果c>1,则重新执行步骤8。
步骤9获得DB最小时的聚类数c为最佳聚类数,并将当前聚类中心作为C-均值算法的初始聚类中心Z={Z1,Z2,…,Zc},X={x(1),x(2),…,x(n)}、 表示输入的样本向量,si表示所有属于第i个聚类中心的样本集合,设定迭代停止阈值ε。
步骤10根据式(4)进行样本划分。
步骤11根据式(5)计算新的聚类中心。
其中步骤1~6是用SOM网络对数据进行初步聚类,获得一个大致的聚类结果,保存SOM网络的权值,步骤7~12是利用SOM网络保存的c个权值作为初始聚类中心,并利用DB指数获得最佳聚类数c,使用C-均值算法对原始数据进行聚类。经过C-均值算法划分后,同一个簇的样本具有最大的相似性,而不同簇的样本之间的相似性尽可能的小。
3 预测实例及结果
3.1 相似日的选择
本文结合湖南某地区历史负荷数据、气象数据和日期类型,对该地区2004年7月30日全天96点负荷进行预测,首先需要从历史日中选择与预测日具有相似气象与负荷特征的相似日。将预测日前3个月,前一年预测日前后各一个月的历史数据规格化处理,形成聚类样本,每个样本包括17个特征数据:日最高温度、日最低温度、日平均温度、日平均相对湿度、星期类型、天气类型、季节类型、前一日尖峰平谷段负荷均值、前6日每日平均负荷。使用MATLAB的SOM工具箱对历史日进行初步聚类,聚类结果如图2所示。
根据SOM网络初步聚类的结果,利用C-均值算法进一步训练,并获得不同分类数的DB值,当分类数为17时,此时DB指数最小,故将17作为最佳聚类数。表1是分类数为17时C-均值算法的聚类结果,与序号为0的预测日属于同一类别的日期序号就是所要找的相似日,即第8类的日期序号,根据这些相似日形成预测样本进行SVM预测。

表1 最终聚类结果

图2 SOM聚类结果
3.2 预测结果
根据第3.1获得的相似日构造相似日训练样本集,并建立预测日样本集,每个样本包括16个特征数据:日最高温度、日最低温度、日平均温度、日平均相对湿度、相似日或预测日前6日的预测时刻负荷数据、相似日或预测日前一日预测时刻前后2个时段的负荷数据、周属性、季节类型。然后使用LIBSVM[14]软件包进行预测,其中核函数选择RBF核函数,参数选择C=78,σ2=10,ε=0.1。
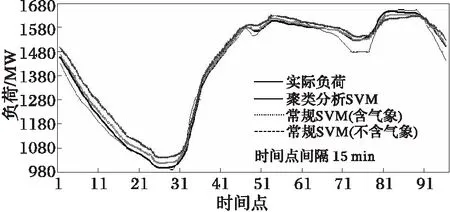
图3 2004年7月30日实际负荷和预测负荷
为了进行比较,本文根据文献[15]的方法建立了常规SVM模型(含气象数据和不含气象数据),通过对该地区2004年7月30日全天96点负荷进行预测,与本文提出的基于聚类组合和SVM预测模型进行比较,各个模型预测负荷与实际负荷见图3。图4为各个预测模型的误差比较曲线。

图4 误差比较曲线
由图4可知,本文模型预测结果在全天绝大多数时间的相对误差小于2%,结果较理想。含气象数据的SVM预测模型比不含气象数据的SVM模型,预测精度有明显的提高。一天中较大误差主要发生在上午8、9点、晚上5~7点以及午夜过后,这主要是因为这些时刻是工作和休息间隔的时候,负荷情况不是很稳定。
用本文提出的方法和单纯的SVM算法(含气象数据和不含气象数据)分别预测从2004年8月2日至8月8日连续一周的96点负荷,表2为2004年8月2日至8日连续一周误差统计结果。
每日的预测误差采用平均绝对百分误差(MAPE)衡量,即

(14)

表22004年8月2日至8日MAPE比较
Tab.2ComparisonofMAPEfromAug.2,2004toAug.8,2004%

方法8月2日8月3日8月4日8月5日8月6日8月7日8月8日平均值聚类分析SVM1.772.311.281.852.832.141.942.02常规SVM(含气象数据)2.093.071.842.332.872.662.392.46常规SVM(不含气象数据)3.073.462.722.673.433.712.973.15
从表2中可以看出,使用本文方法,最大MAPE为2.83%,最小MAPE为1.28%,平均MAPE为2.02%,与使用常规SVM算法相比,本文方法整体预测效果较为理想。
4 结语
本文提出了一种基于聚类组合和支持向量机短期负荷预测方法,通过SOM和C-均值聚类组合算法,选取合适的相似日,构造相似日样本,通过SVM模型逐点训练得到最终的预测结果。该方法能有效地处理负荷序列的噪声及非平稳性,实验表明它是一种有效的短期负荷预测方法。
[1] Vapnik V ,Golowich S E,Smola A J. Support vector method for function approximation,regression estimation and signal processing[C]∥Advances in Neural Information Processing Systems 9 Conference, Denver, USA: 1996.
[2] Amjady N. Short-term hourly load forecasting using time-series modeling with peak load estimation capability[J].IEEE Trans on Power Systems,2001, 16(3): 498-505.
[3] Chow T W S,Leung C T. Neural network based short-term load forecasting using weather compensation[J].IEEE Trans on Power Systems,1996,11(4):1736-1742.
[4] 赵宇红,肖金凤,陈忠泽(Zhao Yuhong,Xiao Jinfeng,Chen Zhongze).混合模糊神经网络在短期负荷预测中的应用(Application of hybrid fuzzy neural network in short-term load forecasting)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2006,18(2):99-104.
[5] Daneshdoost M, Lotfalian M, Bumroonggit G,etal.Neural network with fuzzy set-based classification for short-term load forecasting[J].IEEE Trans on Power Systems, 1998, 13(4): l386-1391.
[6] Du Tao,Wang Xiuli, Wang Xifan. A combined model of wavelet and neural network for short term load forecasting[C]∥International Conference on Power System Technology, Kunming, China: 2002.
[7] 顾洁(Gu Jie).应用小波分析进行短期负荷预测(Application of wavelet analysis to short-term load forecasting of power system)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2003,15(2):40-44,65.
[8] Vapnik V N. Statistical Learning Theory[M].New York: New York Wiley, 1998.
[9] 朱家元,段宝君,张恒喜(Zhu Jiayuan,Duan Baojun,Zhang Hengxi). 新型SVM对时间序列预测研究(Prediction of time series based on least squares support vector machines)[J].计算机科学(Computer Science),2003,30(8):124-125.
[10]Davies D L,Bouldin D W. A cluster separation measure[J].IEEE Trans on Pattern Analysis and Machine Intelligence,1979,1(2):224-227.
[11]Kohonen T. The self-organizing map[J].Proceedings of the IEEE, 1990,78(9):1464-1480.
[12]Han Jiawei,Kamber M. 数据挖掘概念与技术[M].范明,孟小峰译.北京:机械工业出版社, 2001.
[13]Cristianini N,Taylor J S.支持向量机导论[M].李国正,王猛,曾华军译.北京:电子工业出版社,2004.
[14]Chang Chih-Chung, Lin Chih-Jen. LIBSVM: a library for support vector machines[EB/OL].http://www.csie.ntu.edu.tw/~cjlin/libsvm, 2001.
[15]潘峰,程浩忠,杨镜非,等(Pan Feng,Cheng Haozhong,Yang Jingfei,etal). 基于支持向量机的电力系统短期负荷预测(Power system short-term load forecasting based on support vector machines)[J].电网技术 (Power System Technology),2004,28(21):39-42.
ApplicationofClusteringCombinationandSupportVectorMachineinShort-termLoadForecasting
LIANG Jian-wu, CHEN Zu-quan, TAN Hai-long
(Institute of Information Science and Engineering, Central South University, Changsha 410083, China)
In order to improve the accuracy of power system short-term load forecasting,a method of short-term load forecasting based on clustering combination and support vector machine is proposed.First,the standardized data are trained through SOM network and the initial clustering center are acquired,then the initial clustering centre is used as the input values of theC-means algorithm,and the best number of the clustering is obtained through DB index,the samples of similar days are acquired through training.Finally,support vector machine using appropriate parmaeters and kernel function are constructed and the load was forecasted point by point.The results showed that the method has a distinct advantage than simple support vector machine algorithms.
short-term load forecasting; clustering combination; SOM network;C-means; similar day
2009-11-06
2010-01-25
国家自然科学基金资助项目(60173041)
TM715
A
1003-8930(2011)01-0034-05
梁建武(1963-),男,副教授,研究方向为网络通讯、安全、认证,计算机应用。Email:liang_jianwu@tom.com 陈祖权(1978-),男,硕士研究生,研究方向为通信网络的理论与技术。Email:chzq1121@163.com 谭海龙(1983-),男,硕士研究生,研究方向为数据挖掘和智能技术在电力负荷预测中的应用。Email:who_qiaoyu@163.com
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
铁道通信信号(2019年6期)2019-10-08
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
自动化学报(2017年7期)2017-04-18
雷达学报(2017年6期)2017-03-26
现代电子技术(2016年15期)2016-12-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
电子设计工程(2015年6期)2015-02-27
