
基于数据包的三层挖掘技术分析研究
2011-10-26 06:20陈淼谭顺华西南科技大学信息学院621000
中国科技信息 2011年11期
陈淼 谭顺华 西南科技大学信息学院 621000
基于数据包的三层挖掘技术分析研究
陈淼 谭顺华 西南科技大学信息学院 621000
本文基于VC和MySQL软件开发平台,采用数据包的分层挖掘技术对网络数据包进行深度挖掘和统计分析。
数据包;分层挖掘;重复粒度
引言
据CNNIC发布26次调查报告[1]显示,截至2010年12月,我国网民已达3.84亿。在如此庞大的一个网络用户群体中,资源访问是广大网民的主要活动之一。针对类似校园网的大型网络拓扑,流入这种拓扑结构的重复访问数据将成为本文关注的热点。因其重复暂用网络带宽和消耗资源,提高了网络资源访问的成本,在海量重复数据传输的累积过程中,这种浪费是呈正相关的。本文以某大学校园网流量监测平台为基础,配合数据包三层挖掘技术提取分析了这种重复资源的消耗状况。
一、数据源
原始数据包捕获是进行数据挖掘研究的基础,数据的可靠性决定了我们挖掘分析的准确度。在本次研究中我们利用winpcap提供的用户接口捕获校园网络拓扑中共享网络上主机的收/发数据包。经过测试,我们结合winpcap接口开发的数据包捕获软件捕包效率可以达到99.63%以上,见下表1[2],可以忽略漏掉的少量数据包对实验结果的影响。
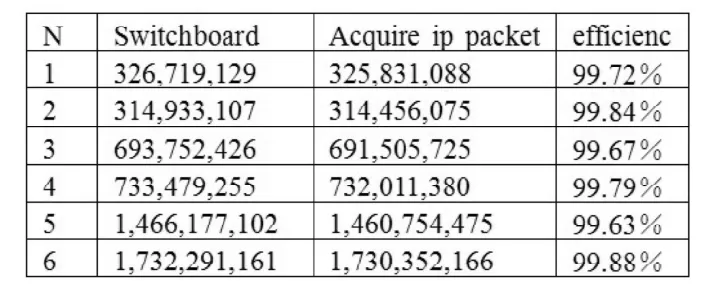
表1 数据包获取实验数据
二、分层挖掘模型
数据挖掘是建立在统计学抽样、人工智能和模式识别等思想的基础模型上,发掘出我们感兴趣的数据特征。如图1。在分层挖掘过程中,首先针对原始数据包进行第一层数据挖掘。在Web资源访问过程中都需要主机首先向资源服务器发送资源请求信息,然后资源服务器才会根据请求消息响应传送资源。根据GET请求特征,将原始数据包中的资源请求信息和资源响应数据提取分离出来分别存入数据库。在第二层挖掘中根据数据库中的数据信息,关联第一层挖掘记录的两张表,进行数据统计分析,从中提取出重复访问资源信息,验证资源重复访问对网络带宽重复使用造成的资源浪费。在第三层挖掘中,根据第二层挖掘信息,提取出用户访问热点页面,建立一个页面资源访问比例模型。

图1 三层数据挖掘模型
三 第一层挖掘
针对已经捕获的80端口原始数据,我们根据数据包分析方法[2]提取出其中的源和目的IP与端口信息。这个基本特征将构成数据包分析的四元向量<S_IP,S_Port,D_IP,D_Port>,通过这个四元向量,我们可以从中重组出通信会话数据。在GET消息提取中,我们同样根据关键字段信息,建立GET请求消息分析模型,提取出其中的URI、Referer、Host三个字段信息,构成资源定位标准。在资源定位标准的三个字段信息提取过程中,URI、Referer、Host是三个固定的关键字,在数据包中他们都以ASCII码编码方式存在,通过他们的结束标识符“ ”即可从原始数据包中按字节读取出字段信息。
这种基于原始数据包的第一层挖掘技术避开了传统数据挖掘基于固定结构的文本信息挖掘更具优势。在原始数据包层进行挖掘,把HTTP标准协议作为基础模型,这种数据挖掘技术更加具有普适性和通用性,可以大大提高数据挖掘效率。经过对数据源的第一层挖掘,我们从133G的80端口进出数据中挖掘出360. 8万条资源请求消息,说明用户在上网活动中资源请求是相当频繁的。
四、第二层挖掘
在第二层挖掘中,通过数据库统计辅助处理,我们分析出360.8万条Web资源访问请求中存在的不同的独立资源请求总计仅有193.5万次,资源请求重复率高达46.36%,接近总访问次数的一半。这种情况意味着针对类似校园网这种特殊网络拓扑,在资源访问过程中存在着相当高比例的重复请求事件,接近一半的数据在网络上的传输属于带宽重复占用,这势必造成一种巨大的资源浪费。其中同一资源访问重复率最多的高达6.96万次,相对次之的也有6.94万次。
这种情况表明,校园网中集群用户在网页浏览和资源请求中会对同一Web页面和该页面关联的资源进行重复访问请求。这样,进入类似校园网拓扑的资源数据流中就会多次出现同一资源。通过上面数据和图表的观察分析,这种重复性地资源传输所占据的比例是很高的,这必然会在一定程度上限制高速互联网的发展。
五、第三层挖掘
通过以上两层数据挖掘,已经完成重复资源请求模型分析。在页面重复访问统计中,我们针对页面重复访问累计排名,可以从中挖掘出当前的热点页面,如图2所示。通过资源热度分析,可以帮助我们建立用户兴趣模型。不仅可以分析出当前热点话题,而且还可以了解用户兴趣爱好,这样将有利于帮助我们进行更高层的应用挖掘。从媒体角度出发,可以通过该兴趣模型,将媒体的视角倾向于大众的眼光。这样,网络的服务才能趋于完美,更关注网民的意愿。

图2 热点页面分析
六、结语
在本文的分层数据包挖掘分析中,首先根据原始数据包结构特征,完成数据包的层次结构挖掘,最终形成重复Web资源粒度挖掘决策树。在今后的研究中,将进一步优化海量信息热点挖掘算法,配合动态资源访问策略解决校园网热点信息重复资源访问传输的问题。
[1]中国互联网络发展状况统计报告. 2010年1月
[2]Miao Chen, Shun-hua Tan, Guo-hai Y,ang Yi-zhi Wang. Research on network business identification technology based on IP packets. IEEE ICACIA2010
[3]WANG Hui, SUN Zhi-gang, DAI Bin, HE Jun-feng, GONG Zheng-hu. Dynamic flow control mechanism in large-scale streaming media multicast systems.Journal on Communications 1000-436X(2010)10-0088-10
[4]Shunhua Tan, Miao Chen,Guohai Yang and Yizhi Wang;Research on Network Data Mining Techniques, 2011International Conference on Information and Industrial Electronics
10.3969/j.issn.1001-8972.2011.11.051
猜你喜欢
保健医苑(2022年1期)2022-08-30
计算机与数字工程(2022年3期)2022-04-07
动漫界·幼教365(中班)(2021年4期)2021-05-23
民用飞机设计与研究(2020年4期)2021-01-21
甘肃教育(2020年18期)2020-10-28
电子制作(2019年10期)2019-06-17
物联网技术(2018年8期)2018-12-06
中央民族大学学报(自然科学版)(2018年2期)2018-11-09
电子制作(2017年8期)2017-06-05
通信技术(2012年4期)2012-02-15
