
浅谈蒙古文单词自动识别系统的研究
2011-10-16 01:51:22乌云塔娜
赤峰学院学报·自然科学版 2011年11期
乌云塔娜
(赤峰学院 数学与统计学院,内蒙古 赤峰 024000)
浅谈蒙古文单词自动识别系统的研究
乌云塔娜
(赤峰学院 数学与统计学院,内蒙古 赤峰 024000)
在信息技术席卷全球范围时,具有悠久文化历史的蒙古族人也不甘落后于时代的步伐,各种用途的蒙古文软件也像雨后春笋般涌现出来.本文中主要描述了对蒙古文单词自动识别系统(以下简称为蒙文单词识别系统)的介绍,设计过程及今后的发展展望.
Access;Unicode;音素
我国是一个统一的多民族国家.国家在《宪法》和《民族区域自治法》中规定,各民族都有使用和发展自己语言文字的自由,并积极帮助各少数民族用自己的语言文字发展教育.那么,对于使用人口有320多万的蒙古族而言,今后人们对蒙文信息处理方面的应用和需求将不断扩大.因此,借鉴和吸收其他民族的先进经验及技术,开发实用的蒙古文软件是我们今后的发展趋势.
1 蒙文单词识别系统简介
蒙文单词识别系统是以蒙古文单词词性为研究的系统.它使用了Borland C++Builder集成开发环境,以Microsoft Access 2003为后台数据库,以内蒙古明安图互连网技术开发有限公司开发的Mongolian Unicode Editor为编辑器开发出来的.
1.1 系统功能
对于用户而言,蒙文单词识别系统具有对用户输入的一段蒙古文文字或一篇蒙古文文章自动识别每个单词词性的功能.而且,也为用户设计了系统帮助模块,主要是对用户的使用加以了说明.
对于管理者而言,蒙文单词识别系统又分别设计了管理模块和添加模块.管理模块中包括词根管理、词尾管理、词典管理(主要是为了后续程序设计的方便,将蒙古文单词的词性用大写英文字母分别表示出来,为此而建立的Access库)、用户管理.添加模块中包括添加词根和添加词尾,主要功能是为词根库及词尾库添加或删除词根及词尾.
1.2 系统工作界面
蒙文单词识别系统由11个窗口组成,其中采用的工作界面是Windows模式的操作界面.用户只要在相应的命令上点击鼠标即可完成对应的操作.系统针对用户的主要工作界面如下图1所示.
1.3 基本操作
1.3.1 蒙文单词词性的识别
用户需要将在Unicode下编辑的蒙古文通过Windows的记事本转换成ASCII字符集的文本,再用蒙古文单词识别系统中的文件->打开命令即可完成蒙古文单词词性的自动识别工作,也可对处理后的文本进行保存、打印等操作.
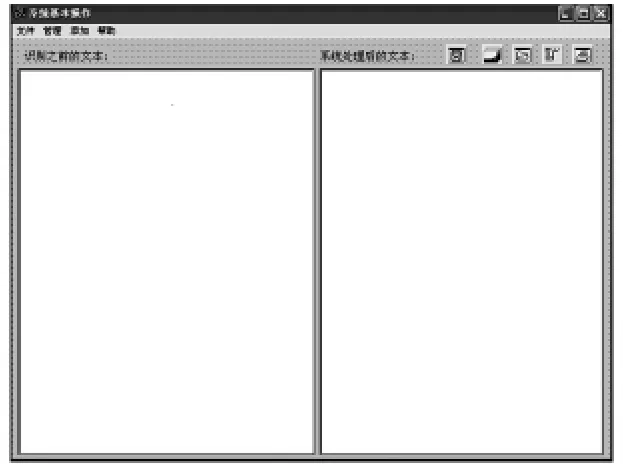
图1
1.3.2 词根及词尾的添加
这个操作主要是针对管理员而言的.首先从“系统基本操作”窗口中点击“添加”菜单,然后从弹出的子菜单中选择“添加词根”命令,输入您要添加的词根以及此词根对应的输入符,再从词性栏中选择当前的词根所能构成的词性,点击“确定添加”按钮,出现如图2所示确认窗口,点击“确定”,出现数据添加成功窗口,如图3.
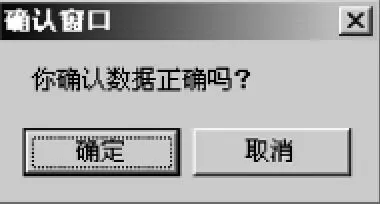
图2

图3
如果在图2中选择“取消”按钮,系统将不添加您此次输入的词根.
添加词尾的操作基本与添加词根的操作相同.
2 蒙文单词识别系统的设计过程
2.1 字库统计
字库统计是蒙文单词识别系统设计的重点,如果字库收集的全面、准确的话,将对后继系统的判断带来很大的帮助.但是蒙古文自发展以来已有800多年的历史,期间文字的演变就经历了好几代,即使是在现在,蒙古文也有好几种写法.那我们到底是以什么为标准呢?最后,由于时间及人力的限制,我们主要是依据《近代蒙语》整理了字库.
蒙古文文字本身是拼音文字,字母上下连书,行款从左到右.其中词的结构可划分为词根、词干及词尾部分.单词中直接由词根组成的词叫基本词.由词根、词干及词尾组成的词叫合成词.基本词统计时较容易,我们只需将蒙古文文字的所有词根从相关的书籍上查找到录入到库中就可以了.但也并不是说一点问题都没有.例如:判断这个词时可以是名词也可以是形容词,这种词只能到语句的环境中才可以识别.那我们建库时到底把这个词列入到名词当中还是形容词当中呢?我们采取的方法是将此类文字的词性设成经常使用到的词性,尽量减少错误的发生.
字库建立当中,输入词尾时也出现了一些问题.例如:输入感叹词“因为我们的系统只能一个单词一个单词地识别词性(在2.2程序设计中详细说明).所以在建库时不管是输入词根还是词尾,中间都不可以有空格.也就是说,比如你输入词尾时,要是输入成那系统就会出现错误.所以解决这类问题时,我们采取的办法是库中只存入“”,系统判断时分两次判断,分别都输出成感叹词.这样也不会造成什么语法错误.但是,这样做只能解决部分问题,像有些连词就不可以了.如它不是重复一个单词,而且分别把它们设成是连词的话,也有语法错误.这是本系统所未能解决的问题,希望今后能够有机会完善此项工作.
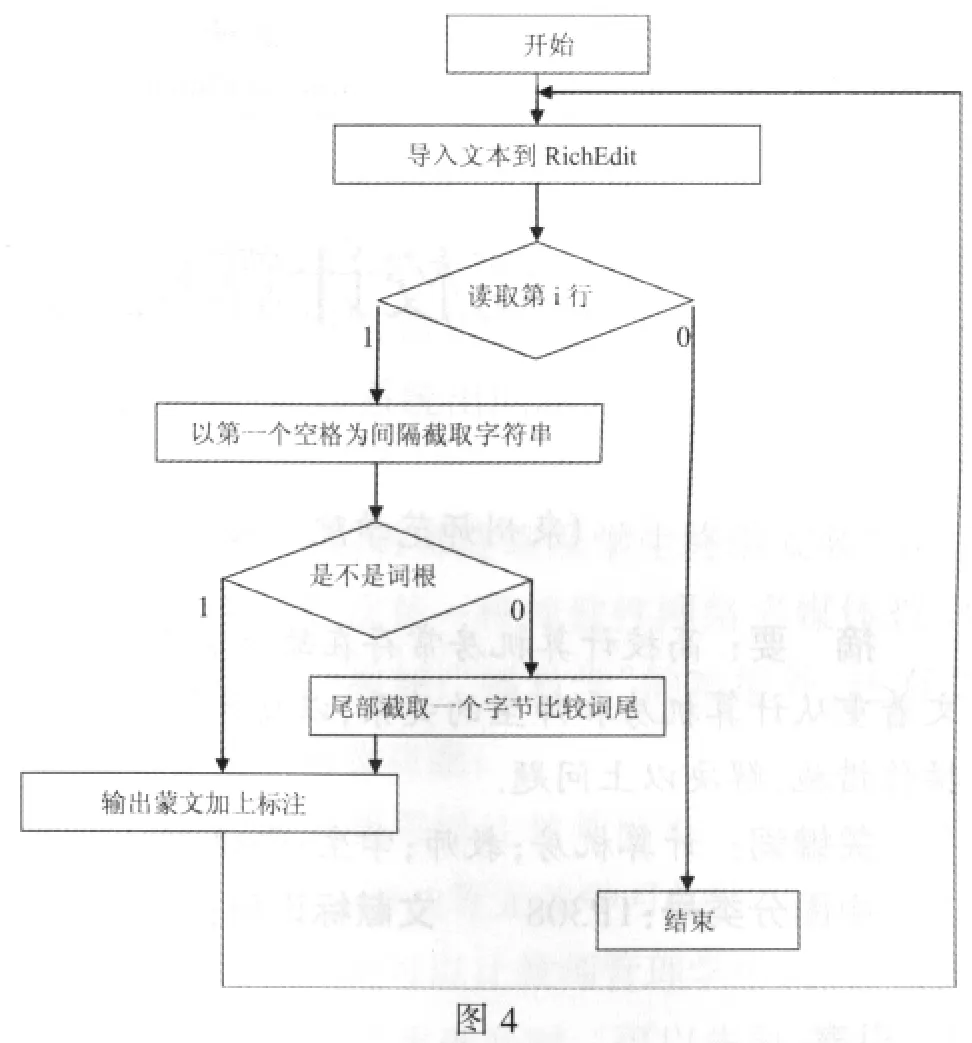
2.2 程序设计
蒙文单词识别系统的程序设计思路是先将导入的文章截取出一行,之后以空格为依据划分出单词,再把单词从头至尾以2个字节为单位进行切分(蒙文音素在计算机中占2个字节),切分一次就到词根库里查询一遍,一旦从词根库里查询到就把单词的词根部分去掉将剩下的词尾部分到词尾库里判断,最后在单词后面以大写字母N、A、M、V、R、D、G、C、S、I(N/名词、A/形容词、M/数词、V/动词、R/代词、D/副词、G/后置词、C/连词、S/语气词、I/感叹词)输出词性.例如:判断的词性时,第一步,先切分出“”之后到词根库里找,没有相匹配的,继续切分单词.第二步,切分出再到词根库里找,没有相匹配的,继续切分单词.第三步,切分出再到词根库里找,有匹配的,就视乘下的部分为词尾,提取出到词尾库里找匹配的.有匹配的输出结果
程序流程图如图4所示:
当然在系统的程序设计中还有一些不够完善的地方:
1)由于系统在划分单词时是以空格为依据的,所以在字库中不可以有空格.这将导致一些词尾无法录入到词尾库中,造成词尾的遗漏.
2)由于Borland C++Builder中的RichEdit控件不是很好的兼容Unicode中编辑的文字,所以文章识别前需将在Unicode下编辑的蒙古文通过Windows的记事本转换成ASCII字符集的文本,再用蒙古文单词识别系统识别.这给用户的操作带来了一定程度的麻烦.
3)由于蒙古文文字是竖写文字,而我们使用的Borland C++Builder中的MCSprite组件不能很好的控制换行,所以本系统处理后的文字也是横排的.这给用户的观看带来了一定程度的麻烦.
4)由于本系统设计时先从词根库里查找,找到匹配的之后,就截取出词尾到词尾库里查找,而这种设计方法对有些单词判断不了的.出现这种情况的单词大部分是人名.比如说
3 蒙文单词识别系统展望
3.1 操作更加简单、直观
在上述的2.2节中已经描述了本系统的程序还未完善的几个问题,其中包括文字的转换与编排问题,希望今后在本系统的完善工作中以上问题能够得到解决.
3.2 字库更加庞大
字库的建立是本系统的核心部分.希望今后能够建立起一个包含蒙古文全部词根及词尾的字库,为蒙古文文化的发展添砖加瓦.
3.3 能够成为今后其它蒙文软件开发基础
蒙文单词词性识别工作全面完善之后,可对今后蒙古文句子成分的判断带来帮助,也可由此判断句子的正误情况,是一项有研究价值的题目.
〔1〕余明兴,吴明哲.Borland C++Builder实例精解[M].北京:清华大学出版社,2001.
〔2〕哈斯额尔敦.近代蒙语[M].呼和浩特:内蒙古教育出版社,1996.
TP391.4
A
1673-260X(2011)11-0052-02
猜你喜欢
考试与评价·八年级版(2020年5期)2020-10-29 05:42:35
新闻研究导刊(2020年9期)2020-09-10 07:22:44
鸭绿江·下半月(2019年7期)2019-11-05 05:32:22
卫拉特研究(2018年0期)2018-07-22 05:47:46
新教育时代·教师版(2018年43期)2018-01-24 11:40:16
卫拉特研究(2017年0期)2017-12-07 00:35:12
西部蒙古论坛(2016年4期)2017-01-16 12:12:47
卫拉特研究(2016年0期)2016-12-06 09:11:56
小学生时代·大嘴英语(2016年6期)2016-07-02 20:13:31
军事历史(1993年3期)1993-01-18 00:11:40
