
一种无指导的情感短语极性判别方法
2011-10-13 01:11:42罗侃海量信息技术有限公司北京100190
天津科技 2011年2期
罗侃(海量信息技术有限公司北京100190)
宁建军(文汇新民联合报业集团·新民网上海200041)
一种无指导的情感短语极性判别方法
罗侃(海量信息技术有限公司北京100190)
宁建军(文汇新民联合报业集团·新民网上海200041)
在情感分析任务中,情感词或情感短语的极性判别是一项非常重要的任务。提出一种新的基于无指导学习的情感短语极性判别的方法。在该方法中,首先从新闻网站上抓取大量无标注的新闻评论数据。经过去除噪音并进行分词和词性标注之后,使用预先设定的模板抽取情感短语。然后人工标注少量种子词。通过分析种子词和情感短语的共现信息,最终得到情感短语的极性值。实验证明,这种方法可以有效判别情感短语的极性,并且能够用于句子级别的情感倾向分析。
情感分析情感极性判别情感短语
0 引言
随着Web 2.0概念的深入人心,越来越多的网站开始注重以与用户交互的方式来吸引用户;另一方面,用户也习惯在各个平台上发表自己对于产品、人物、事件等各个要素的评论。这些评论不但数量巨大,且覆盖面极广。无论是潜在的消费者、商家还是政府,甚至更多的个人和组织都可以从这些海量的评论中得到有用的信息以帮助决策。例如,一个潜在的消费者可以通过查找其他消费者对于某款产品的评论而了解到该产品的优劣,继而可以帮助用户选购到合适的商品。又如,政府可以通过分析大量的评论了解广大民众最关心的时政问题并据此进行相应的决策。
然而,互联网上的评论数量往往非常巨大。在如此多的评论面前,仅凭人力难以逐个阅读。因此,将评论分类并得到相应的统计信息是一个非常自然的想法。在已有的情感分析任务中,有的研究者延循传统的文本分类方法:整理收集有标签的语料并抽取相应的特征,然后使用统计模型进行分类。这种方法在实际应用中面临两方面的问题:①不同领域的特征差异较大。例如在手机这个领域中,“大”是一个表达正面情绪的特征;而在笔记本这个领域中,该特征却是一个表达负面情绪的特征。②在某些领域,例如时政新闻类,还没有公开的有标注的数据。此外,博客、论坛上还有大量的未标注评论。这两点原因导致基于有指导学习的方法难以满足现实的要求。
有的研究者关注于如何构建一个情感词典。在这样的体系下,情感倾向的判断依赖于词典的覆盖率和准确率。然而,将词的情感倾向进行转义是非常常见的语言现象。例如,“满意”是一个正面的词语。在收集的评论中,“满意”出现的次数为2 568次,“不满意”出现的次数为725次,“……才满意?”类型的反问或疑问句类型出现的次数为68次。因此,一个好的基于词表的情感倾向的判别系统还要处理各种变化的否定式等转义现象。而且,领域的相关性也是在构造词表过程中出现的非常困难的一个问题。此外,在现实数据中,大量的评论有错别字、漏字、简写、缩写等现象。综合以上这些因素,基于词表的系统在判别文档情感极性时面临很大的困难。
针对以上提出的问题,本文将抽取的对象锁定在短语级别。与单个词相比,短语具有如下几个优点:①在不同语境下存在不同倾向性的可能性更小。例如“期待奇迹发生”表达了非常明确的正面情感倾向。单个词“期待”则有可能在正面或是负面的情形下使用,例如“还是别期待”就表述了负面的情绪。②在某些情况下,单个词没有主观倾向性或者倾向性不明。例如,“取消”在一般情形下表达了否定的含义。“税收”则是一个客观性的名词。两者结合之后形成的短语“取消了税收”在大部分语言环境下蕴含了正面的情感倾向。
本文提出的基于无指导学习的情感短语极性判别方法能够在极少量的人工标注基础上得到质量较高的情感短语及其情感倾向,并且抽取出来的情感短语能够有效的用于评论的倾向性判别。
1 相关工作的分析
国内面向中文的情感分析研究,随着两届《中文倾向性分析评测》(Chinese Opinion Analysis Evaluation,COAE2008,COAE2009)的召开,获得了极大的关注,而之前的研究则较为零散。COAE评测的任务涵盖了情感分析这一方向的大部分问题,如情感词的识别与极性判断、情感相关要素的抽取、句子及篇章的主客观识别与褒贬倾向判断等。在情感表达的语言单位上,大部分国内的研究定位于词汇,即识别情感词以及判断其极性。对这一问题的主要方法是在HowNet等现有的情感语义资源的基础上进行领域扩展,从而获得领域相关的情感词词表。扩展的主要依据有词性、句式、句法等语言学约束条件,[1-2]与HowNet等现有情感词的共现关系,[1]情感词的上下文模版等。[3]
一个词的情感性质(是否是情感词,极性如何)依赖于其出现的上下文。因此,COAE要求抽取而得的情感词要注明前后的语境,以判断其是否确实作为情感词出现。这是一种消除词汇情感不确定性的手段,如果直接将情感识别定位于短语层面,这样的不确定性将很自然的基本得到消除。
文献[4]的研究不是以词汇为基础进行情感分析。在文献中,作者在人工标注好的主客观训练语料中抽取了连续双词词类组合模式作为区分主观文本与客观文本的特征,进而对文本进行主客观性的分类。因为是长度为2的顺序词类,这样的特征比词汇显得更“抽象”,也无法谈到褒贬极性的区分。
国外情感分析的研究起步更早,在各个级别的会议上都已发表了大量的相关文献。研究词的情感极性问题最早见于文献[5]。在文献[5]中,研究者通过分析形容词之间组成的词对来判别形容词的情感倾向。这些词对通过“and”、“or”、“but”、“either-or”以及“nether-nor”连接起来。这个方法是基于这样一种假设:通过这些词连接的词对拥有相同或是相反的情感极性。例如使用“and”相连接的词对就含有相同的极性。通过输入一些初始词及其情感极性,最终能够得到大量形容词的情感极性。
Turney[6]提出了另一种方法来计算词语的情感极性。该方法先输入少量的正面和负面的种子词,通过搜索引擎搜索种子词与目标词共现的次数,并通过点间互信息(Point-wise Mutual Information,PMI)得到目标词的情感极性。然而,该方法需要连接到外部的网络资源。此外,主流中文搜索引擎不支持该方法所需的“NEAR”修饰符:即两个词只在一定距离之内共现。
文献[7]则是通过分析WordNet来得到目标词的情感极性。该方法首先通过WordNet以及同义词构建出词网络。每个目标词的极性则是通过判断该词与“Good”和“Bad”之间的距离哪一个更近来获得。
2 基于无指导学习的情感短语极性判别方法
该方法的第一步是抽取带有情感倾向的短语。已有工作阐述了单个形容词表达情感倾向的重要性。[8]正如第一点提到的,单个形容词在不同上下文会存在转义的现象,并且不同领域的形容词可能含有不同的主观倾向。因此,本文使用短语作为基本的情感倾向单元。通过人工方式总结了一批模板,使用这些模板作为抽取短语的方式。
首先,算法需要将评论进行切词和词性标注。使用海量分词研究版作为切词工具以及BasePoS1http://bcmi.sjtu.edu.cn/~zhaohai/index.ch.htm l作为词性标注工具。该词性标注工具的标准依照宾州树库的词性标注标准。表1列出了抽取短语过程中所使用的模板。其中,AD为副词,VA为表语形容词,VV为其他类动词,AS为语助词,DEC为“的”字语助词,NN为名词等等。更多的解释可以参考相关文档2ftp://ftp.cis.upenn.edu/pub/treebank/doc/tagguide.ps.gz。
该方法的第二步是计算每个短语的情感极性。使用浅层语义分析(Latent Semantic Analysis,LSA)技术来比较情感短语与种子词之间的强弱关系。LSA使用矩阵奇异值分解(Singular Value Decomposition,SVD)来分析词语间的统计关系。LSA首先需要将文本转换为矩阵形式,其中行向量表示短语,列向量表示文档。和传统做法不同的是,将属于同一篇新闻的评论整合为一个文档。这种做法暗含了一个假设,即隶属于同一篇新闻的评论往往含有类似的情感极性。通过观察发现,这个假设在大部分情况下是成立的。另外一个原因是:新闻类评论的文本往往很短,一句话往往只有一个候选短语。因此如果把单篇评论作为一个文档来对待,很难得到短语间的共现信息。
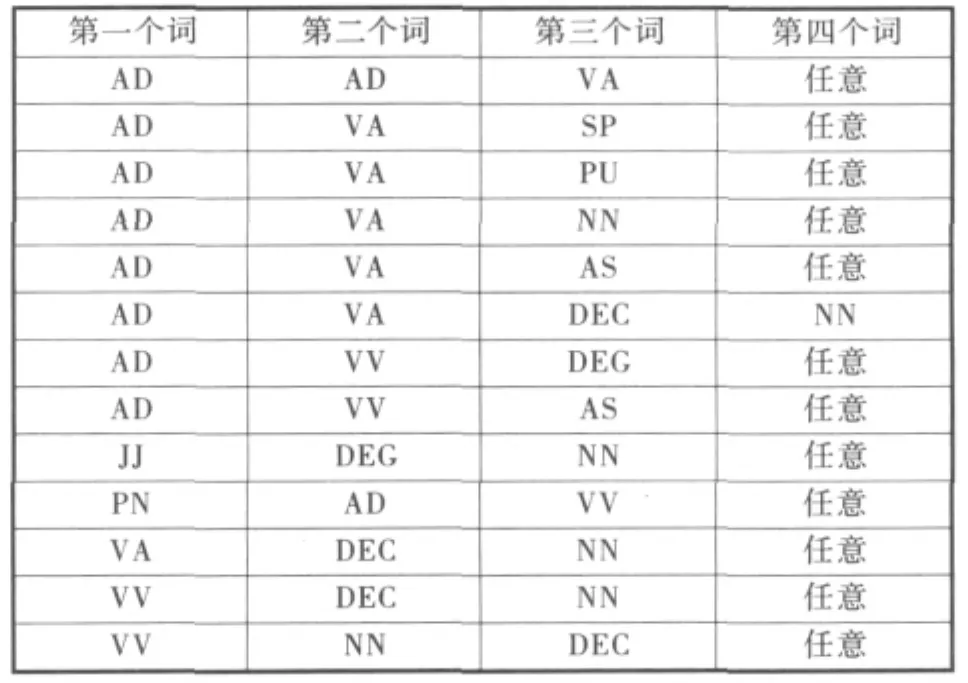
表1 短语模板
SVD分解会将矩阵X分解为3个矩阵的积,即:X=UΣVT。假设矩阵X的秩为r,选择K≤r。那么Xk=UkΣk是秩为K时对X矩阵的最好近似。假设Phrase1和Phrase2在矩阵中相应的行向量分别那么它们的相似度:LSA(Phrase1,Phrase2)
人工选择了4个正面种子词和4个负面种子词共计8个种子词作为初始输入。8个种子词的列表见表2。这些种子词在语料中都有很高的出现频率,而且出现转义等情形也较少。
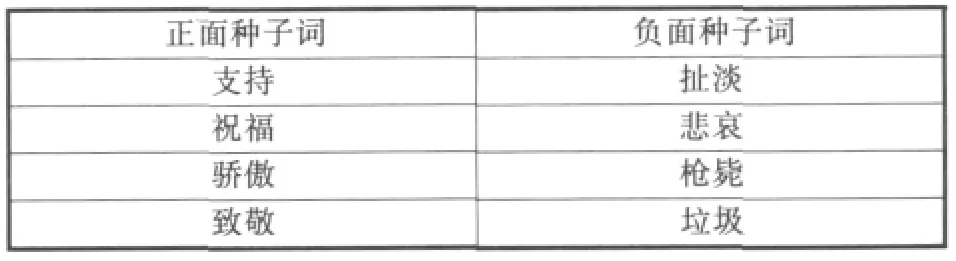
表2 种子词列表
对于任意一个短语Phrase,其情感极性SP用如下公式计算:
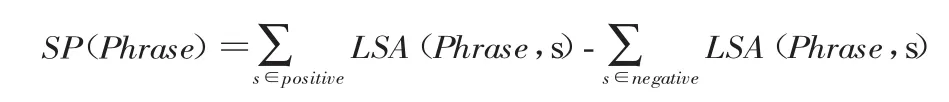
其中s表示种子词。当SP大于零时,该短语为正面性短语,反之当SP小于零时,该短语为负面性短语。
该方法的第三步是计算文档的情感极性。将文档中所有已计算极性值的情感短语抽取出来。然后对所有的情感极性值取平均。当平均值大于0.05时,评论被归类到正面类评论。当平均值小于-0.05时评论被归类到负面类评论。当平均值居于-0.05和0.05之间时则为中立类评论。
3 实验及其结果
3.1 实验数据说明
抓取了新民网32 006 538条时政、民生类新闻评论。通过随机的方式选择了977篇新闻及其对应的15 004条评论进行标注。标注的类别为:正面、负面、中立和未知。正面类的主要包括了赞扬、同意、支持等主观倾向。负面类的主要包括了愤怒、贬损、辱骂、抗议等主观倾向。中立类的主要包括了感慨等主观倾向以及客观类评论。未知类的标注准则则是当该评论难以判断其所属的类别时使用。4个类别对应的数量见表3:
3.2 情感分类实验
考察了不同大小的情感极性值对于分类结果的影响。结果见表4所示。其中,短语集大小的百分比指的是依据SP值从大到小选取的短语占所有抽取短语的比例。例如,10%表示实验中使用了正面短语集合和负面短语集合各自SP值最大的10%短语。第二列指的是15 004条评论中含有特定短语集中短语的比例。第三列指的是只考虑正面和负面类评论时得到的准确率。第四列指的是考虑正面、负面以及中立评论得到的准确率。准确率的计算公式为:实验结果显示,当只考虑正面以及负面类评论时,基于短语情感极性最高能得到87.15%的准确率。相应的代价是只能命中大约1/5的评论。而此时,分为3类的准确率也能达到65.8%。随着短语集的增大,准确率随之减小而命中的评论数量则随之增大。短语集合中SP值较小的短语大多为出现频率很低的短语。因此,可以认为当候选短语出现了足够多的数量,基于无指导学习的方式能够有效的学习到其情感倾向。
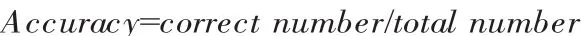
4 结论与展望
提出了一种基于短语与种子词的共现信息来计算情感短语的极性。大规模真实语料上的实验表明,当问题定义为正负面的二类问题时,使用该方法得到的情感短语用以判断评论的情感倾向最高能得到87%的准确率。
基于短语的方法主要的问题是不能命中大部分的评论,且短语的抽取工作依靠人工总结的规则。下一步的研究方向是扩大短语抽取的规则集合以及机器自动识别情感短语的方法。■
[1]乔春庚,孙丽华,吴韶.基于模式的中文倾向性分析研究[C].北京:第一届中文倾向性分析评测论文集,2008:21-31.
[2]刘军,刘全升,陈漠沙.第一届中文倾向性分析评测结果浅析[C].北京:第一届中文倾向性分析评测论文集,2008:125-141.
[3]王秉卿,张姝,张奇.中文情感词识别[C].北京:第一届中文倾向性分析评测论文集,2008:63-69.
[4]叶强,张紫琼,罗振雄.面向互联网评论情感分析的中文主观性自动判别研究[J].信息系统学报,2007(1):79-91.
[5]Hatzivassiloglou and McKeown.Predicting the semantic orientation of adjectives[M].Madrid,Spain:Proceedings of the eighth conference on European chapter of the Association for Computational Linguistics,1997:174-181.
[6]P.D.Turney.Thumbs up or Thumbs down?Semantic orientation applied to unsupervised classification of reviews[C].Philadelphia:Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics,2002:417-424.
[7]J.Kamps,M.Marx,R.J.Mokken et.al.Using WordNet to measure semantic orientation of adjectives[J].Lisbon,Portugal:Proceedings of the 4th International Conference on Language Resources and Evaluation,2004(4):1115-1118.
[8]J.M.Wiebe.Learning subjective adjectives f rom corpora[C].Menlo Park:Proceedings of the 17th National Conference on Artificial Intelligence,2000:735-740.
注:本文为基金项目论文,获上海市科学技术委员会科研项目《新闻网站专题页面富媒体信息搜编技术研究及其系统实现》(课题号:09dz1502000)资金资助。
2011-03-08
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
时代英语·高一(2019年5期)2019-09-03 02:09:34
能源(2018年8期)2018-09-21 07:57:22
知识经济·中国直销(2018年6期)2018-06-29 07:55:52
电测与仪表(2016年11期)2016-04-11 12:20:42
新闻研究导刊(2015年17期)2015-12-25 12:36:42
电源技术(2015年5期)2015-08-22 11:18:28
语言与翻译(2015年4期)2015-07-18 11:07:43
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
数理化学习·高一二版(2009年2期)2009-03-30 05:02:56
