
基于k-匿名技术的学生成绩数据发布研究
2011-09-29 02:39龙琦
云南民族大学学报(自然科学版) 2011年2期
龙 琦
(云南国防工业职业技术学院传媒与信息工程学院,云南昆明650223)
基于k-匿名技术的学生成绩数据发布研究
龙 琦
(云南国防工业职业技术学院传媒与信息工程学院,云南昆明650223)
采用k-匿名模式对学生成绩的发布进行控制,在学籍管理系统中实现了对学生成绩的隐私保护.
数据挖掘;隐私保护;k-匿名;学生成绩数据发布
现在数据挖掘技术已成功地应用于教学领域,利用这项技术可以对学生来源,在校学习状况,进行分析、并预测学生毕业后的发展方向,更重要的是能对学校的办学模式、招生计划、专业设置、教学方法改进等方面起到积极的指导作用[1].由于在对学生的成绩分析时涉及到学生的个人隐私,而学校对学生进行管理的专业人员对数据进行分析和处理的能力有限,有时数据只能送给数据分析方面的专业人员分析处理以便发现其中宝贵的教育、教学规律[2-3].因而学校、科研机构在将数据交给数据分析人员时必须考虑对数据进行必要的处理,保护学生的个人隐私.
1 基于k-匿名的隐私保护
基于k-匿名的隐私保护技术作为一种新兴的信息安全技术,与传统的访问控制和加密技术有着本质的区别.访问控制技术和加密技术的核心思想是保护数据的隐秘性,保证它不被非授权的第3方访问.一般通过切断从攻击者到隐秘数据的道路(访问控制)或者使得攻击者获得的数据变得不可使用(加密技术)来实现.攻击者则以获得可用的隐秘数据为最终目标.而隐私保护技术并不保障数据的隐秘性,隐私数据完全是对外公开的,甚至任何人都可以访问,其核心是要保护隐私数据与个人之间的对应关系,换句话说就是隐私数据可以被任何人得到,但是却不能把该数据对应到某个特定的人身上.从攻击者的角度看,攻击的目标是隐私数据与个人之间的对应关系[4].
k-匿名模式将数据表中的属性分为4类:
1)标识符.它们直接标识个人身份,如学号、姓名、身份证号码等;
2)准标识符.间接(可以与其他数据表进行链接)标识个人身份,如邮政编码、家庭住址、出生日期等;
3)敏感属性.包含敏感信息的属性,如病史,信用记录等;
4)其他属性.非准标识符和敏感属性的标识符,如专业名称.
为了保护个人隐私,在数据发布的时候,必须从数据表中删除标识符,但是采用这种的处理方式并不能保护数据中的个人隐私,见表1所示.
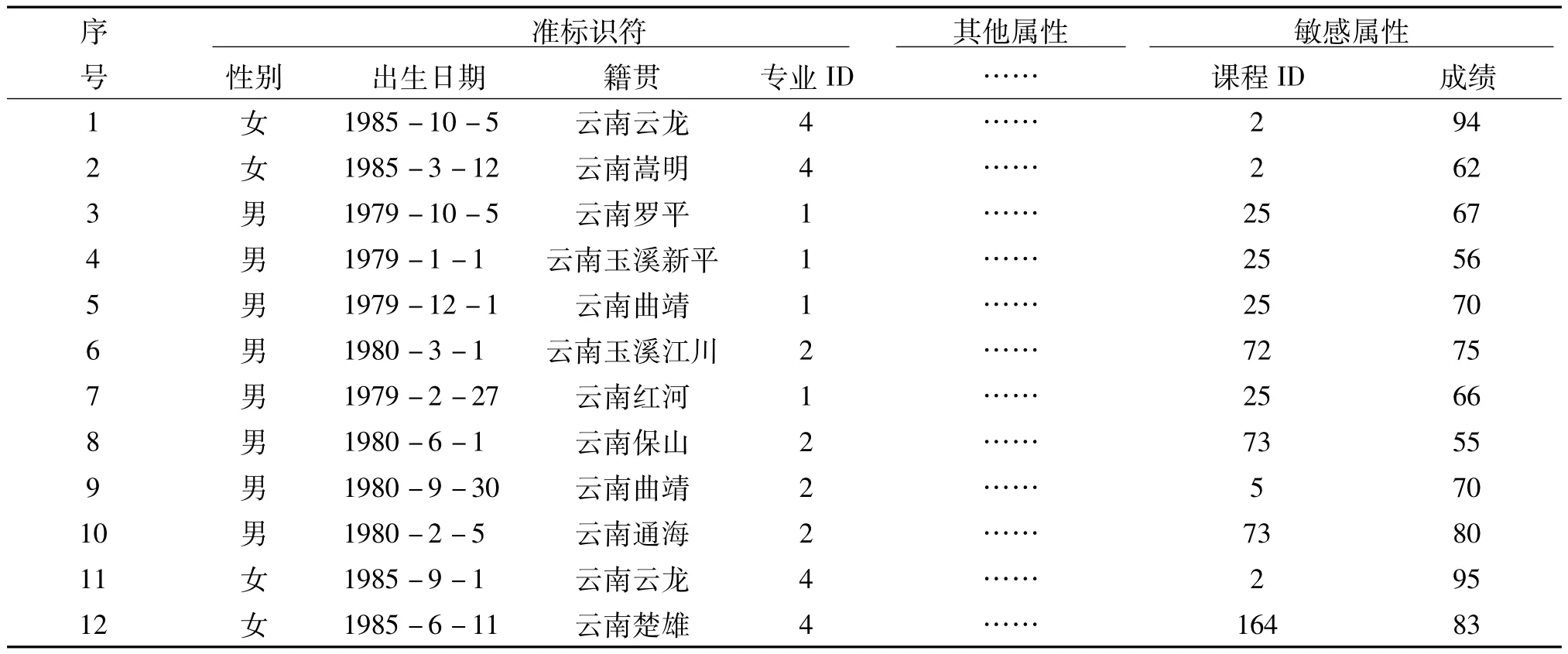
表1 原始的学生成绩数据集
在表1中尽管标识符,例如学号、姓名已经从数据集中删除,但是一些属性,如性别、生日和籍贯依然存在于表1中,这些属性集可以间接的用于分辨个人的信息.这种属性集被称为准标识符.Samarati和Sweeney提出一种隐私保护模式:k-匿名模式[5-7].如果数据集中的每一个记录都与至少k-1个关于这个数据集中的准标识符属性记录相同,那么这个数据集满足k-匿名,这个数据集就被称为k-匿名数据集.这样在k-匿名数据集中,个人就无法从最少k-1个人群中被分辨出来.
例如,表1中性别、出生日期、籍贯这3个属性组中,第1个记录是独一无二的,因此学生的身份可以被间接的发现.通过这种独特的组合,学生的个人成绩信息就可能被泄漏.为了避免侵犯隐私,表1可以修改为表2.

表2 表1的k-匿名表
在表2中,出生日期被以年的形式分组,籍贯被集束到广大地区,“*”代表一个任意数字.一项准标识符中的记录至少与其他3个记录相同,因此,没有任何个人可以被识别.
由于k-匿名模式的简洁性和适用于多种算法的特性,k-匿名模式在数据发布中变得非常流行.
2 基于k-匿名的学生成绩数据发布研究
2.1 学生成绩数据发布中的隐私保护
现在已有很多学校意识到学生成绩属于学生个人隐私,学生个人的隐私应得到保护和尊重,在对学生成绩进行发布时,主要采用了以下的一些保护措施:
1)采用用户认证方法.分配给学生与教师不同的用户权限,学生只能查询个人成绩信息,教师可以输入或查询所授班级学生的成绩信息.在查询学生成绩时,需输入个人学号、考号、身份证号、密码等个人身份认证信息,这种以对访问者授权为前提的用户认证方法,有效地保证了只有合法的用户才能存取数据库系统中的资源.学校利用这种方法在对学生成绩隐私进行保护时,存在下列问题,学生只能查询自己的成绩,不清楚自己的学习水平,将会失去学习的动力,学号对同班同学是公开的,同一考场的同学根据座次,很容易推算出同学之间的考号,好友之间可能造成个人的身份证号以及个人密码泄漏,不能控制教师在获得学生成绩信息后,在不经过学生同意的情况下对学生成绩数据进行分析、发布;
2)采用隐藏敏感属性的方法.在发布学生成绩时将学号、姓名属性隐藏,如表1所示,学生从表1中能知道自己学习所处的水平,而不知道其他同学的学习水平.学校利用这种方法在对学生成绩隐私进行保护时,存在下列问题,在表1中,第1个记录是独一无二的,因此学生的身份可能被间接的发现.结果,通过这种独特的组合,学生的个人成绩信息就可以被泄漏.
为解决上述方法中存在的隐私泄漏问题,本文拟采用k-匿名技术对学生成绩的发布进行控制.在实现k-匿名的众多方法中,泛化因其容易实现,被广泛使用,因此本文采用了泛化的方法对学生成绩数据的发布进行控制,以达到保护学生个人隐私的目的.
泛化是用1个一般化的属性值替代1个具体的属性值.例如,出生日期的“日/月/年”格式用“月/年”格式代替.所有的属性域都在层次化的结构中.对于属性来说,拥有较少值的域比拥有较多值的域更加普遍一般.最一般的域只包含了1个值.在典型的关系型数据库系统中,经常用域来描述属性值的集合,比如出生日期域、数值域、时间域等[8].
2.2 基于k-匿名技术实验方案设计
2.2.1 全局泛化与局部泛化
k-匿名中泛化的方法分为全局泛化与局部泛化,实验中将采用这2种方法.
1)全局泛化.将表中某一列内所有值全部进行泛化;
2)局部泛化.不泛化一列内所有值.只泛化相关行中独特(或重复数小于k)的值.例如,如果没有必要,出生日期不泛化.如果需要,出生日可查采用最近组合,例如,1980和1981组合成[1980,1981].在局部泛化中,同一个值可以被泛化为不同的组合.比如,1980可能被泛化为[1980,1981]或[1979,1980].泛化值被界定于最近的可组合值.希望泛化后的区间小,信息精确.
对数值属性,可以按照上面的方法做.因为它们有次序关系.对没有次序关系的分类数据属性,比如籍贯,论文采用树型结构规定他们的泛化次序.
2.2.2 实验步骤
1)数据标识.确定原始数据中的直接或间接标识个人身份的标识符、准标识符,数据发布中需要保护的对象敏感属性和其他属性;
2)全局泛化.采用全局泛化的方法对敏感属性进行保护,将学生的出生日期的“日/月/年”格式用“月/年”格式代替,将学生的出生日期的“日/月/年”格式用“年”格式代替.分析对出生日期全局泛化后,对敏感属性保护的效果;
3)局部泛化.采用局部泛化的方法对敏感属性进行保护,将k值设分别设为2,5,10分别实验,分析经过局部泛化后,对敏感属性保护的效果;
4)生成XML数据文件.Mondrian_Distrib软件包的k-匿名算法(Anonymizer)处理的数据文件为XML,因此,需将泛化后的数据转换为XML数据文件;
5)k-匿名处理.用Mondrian_Distrib的Anonymizer算法对第4步生成的XML数据文件进行k-匿名处理.
3 实验研究与分析
数据来源于学校学籍管理软件的数据库系统,硬件环境为Intel 3GHz CPU,4GB内存;软件环境为Linux操作系统;本文用到的k-匿名软件包为Mondrian_Distrib[9].
3.1 k-匿名表质量分析
在数据集中分别取50,150个记录作为本文的初始表.选择k=2,5,10时,应用k-匿名算法得到泛化后的表,进行比较,分析结果见表3.

表3 k-匿名处理后信息表
表3给出了泛化后数据精确度和敏感属性泄漏情况.从表3中可以看出,当记录数和k增加时,敏感属性被识别机率降低.
当给定k值时,不同记录数对应的数据精确度,数据精确度随记录数的增加而增加(见图1).
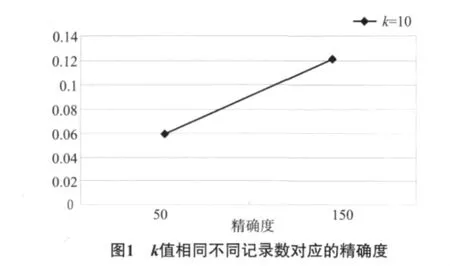
k-匿名处理后,当记录数相同时,k值增大,数据精确度降低(见图2).

当记录数相同,k值增大,敏感属性最大识别率降低,保密性增大(见图3).
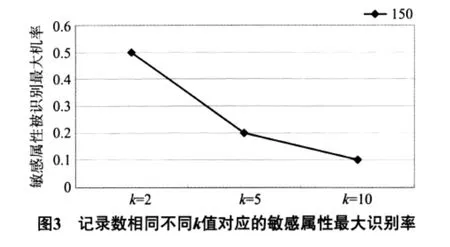
泛化表中用数据精确度作为衡量数据泛化表质量的一个标准.以上分析结果说明,k=10表的质量比k=2的质量差.但k=10表的保密性比k=2的质量好.质量和保密性的要求是矛盾的,在应用中,这2个要求需要平衡.质量同数据表的大小也有关,给定同样的k值,用同样的泛化方法,大数据表的质量好,小数据表的质量差.在应用中,如何选取k,需要从实际情况出发,平衡数据精确度和保密性这2个相互矛盾的需求,选取一个适合的k值.
3.2 k-匿名执行时间分析
记录数经重复抽样到5 000,10 000,15 000,20 000,然后再随机行间交换.
1)时间与数据大小的关系.参数设置:准标识符=5,k=10,记录数和执行时间实验结果,如表4.

表4 记录数不同时对应的执行时间(准标识符=5,k=10)
当准标识符,k值取值不变时,记录数增大,相应的执行时间增长(见图4).

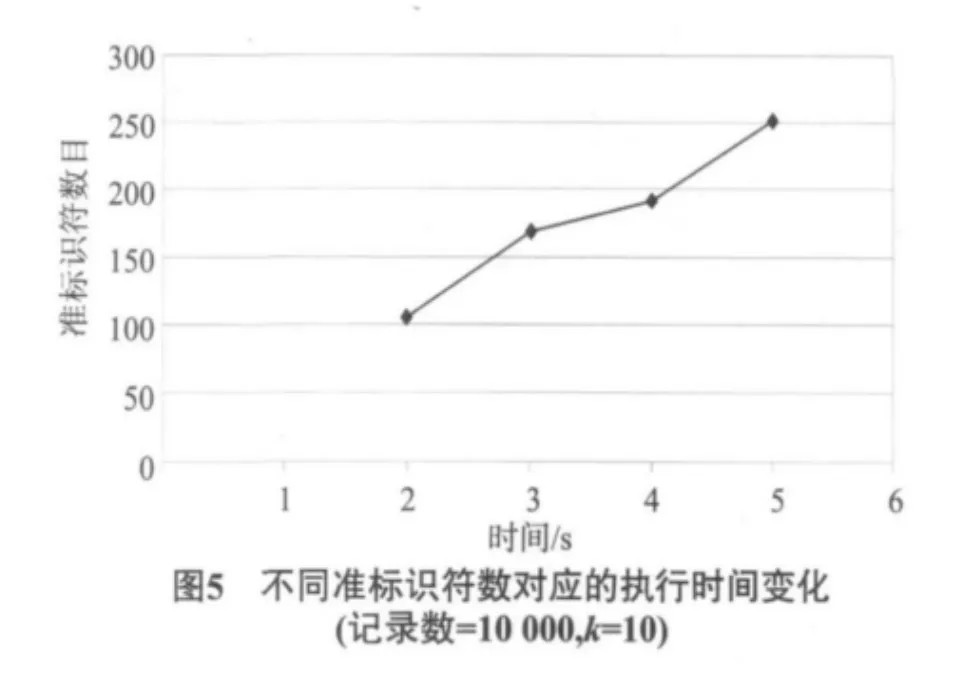
2)时间与准标识符大小的关系.参数设置:记录数=10 000,k=10,准标识符数目和执行时间实验结果,如表5.

表5 不同准标识符数对应的执行时间(记录数=10 000,k=10)
准标识符数目增大,相应的执行时间增长(见图5).
3)时间与 k的关系.参数设置:记录数=10000,准标识符=5,k和执行时间,实验结果见表6所示.

表6 不同k值对应的执行时间(记录数=10 000,准标识符=5)
当数据量相同时,k值取值增大,相应的执行时间增长(见图6).

3.3 结论
1)数据量少的表,k-匿名处理后会失去一定信息,比如,籍贯失去.要保住籍贯信息.同一个地方的学生数要至少大于k.因此最好发布数据量大的表,可以保证保护个人隐私的数据的有用.
2)k-匿名处理后表的精确度质量和敏感属性保护质量是相互矛盾的.在应用中,这2个要求需要平衡.
3)精确度质量与k的取值有关,相同的记录数,用相同的泛化方法,k值小的质量高,k值大的质量低.
4)精确度质量同数据表的大小也有关.给定同样的k,用同样的泛化方法,大数据表的质量好,小数据表的质量差.
5)k-匿名执行时间与记录数、准标识符数、k的大小有关,记录数、准标识符数,和k的取值增大,都会使执行的时间增长.
[1]张翎.概率统计方法在教学研究中的应用[J].云南民族大学学报:自然科学版,2007,16(4):368-369.
[2]张寒云,段鹏,丁钦华.基于关联规则的课程拓扑排序研究[J].云南民族大学学报:自然科学版,2009,18(2):177-179.
[3]杨春华,杨玲.高校毕业生就业竞争力分析[J].云南师范大学学报:自然科学版,2009,29(5):39 -45.
[4]刘喻,吕大鹤,冯建华,等.数据发布中的匿名化技术研究综述[J].计算机应用,2007,27(10):2 361-2 364.
[5]SWEENEY L.k-anonymity:a model for protecting privacy[J].International journal on uncertainty,Fuzziness and knowledge based systems,2002,10(5):557 -570.
[6]SAMARATIP,SWEENEY L.Generalizing data to provide anonymity when disclosing information(Abstract)[C]//Proc.of the 17th ACM SIGACTSIGMOD - SIGART Symposium on the Principles of Database Systems.W A,USA,1998:188.
[7]SAMARATI P.Protecting respondents identities in microdata release[J].IEEE Transactions on Knowledge and Data Engineering,2001,13(6):1 010 -1 027.
[8]岑婷婷,韩建民,王基一,等.隐私保护中k-匿名模型的综述[J].计算机工程与应用,2008,44(4):130-134.
[9]LEFEVRE K,DEWITT D,RAMAKRISHNAN R.Incognito:Efficient full-domain k -anonymity[C]//Proc of the SIGMOD 05 on Management of Data.New York:ACM,2005:49-60.
(责任编辑庄红林)
A k-anonymity Study of the Student-Score Publishing
LONG Qi
(School of Media and information Engineering,Yunnan Vocational College of National Defense Technoeogy,Kunming 650223,China)
Data publishing provides support for better decision making,but it might also deprive the people of their privacy.This research adopts the k-anonymity model to control the process of the student-score publishing and uses the k-anonymity technology in the school management system to protect the students’privacy in the student-score publishing.
data mining;privacy protection;k-anonymity;student-score publishing
TP 311
A
1672-8513(2011)02-0144-05
10.3969/j.issn.1672 -8513.2011.02.017
2010-03-06.
龙琦(1974-),女,硕士,讲师.主要研究方向:计算机应用与数据库技术.
猜你喜欢
芜湖职业技术学院学报(2022年2期)2022-11-24
计算机应用(2022年8期)2022-08-24
上海理工大学学报(2022年2期)2022-05-05
台湾农业探索(2020年4期)2020-10-29
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
计算机系统应用(2020年8期)2020-03-22
台湾农业探索(2019年5期)2019-09-10
新教育时代·教师版(2017年30期)2017-09-12
