
基于自然语言处理的文本泄密自动检测技术
2011-09-07 10:17王利鑫耿焕同
计算机工程与设计 2011年8期
王利鑫, 耿焕同, 孙 凯, 张 茜
(南京信息工程大学计算机与软件学院,江苏南京210044)
0 引 言
信息的生产、存储、获取、共享以及传播已越来越方便,但与此同时,信息泄密随着信息化程度的提高而日益加剧。近年来,各级党政机关门户网站普及的同时,非法披露国家秘密信息事件呈上升趋势,在泄密事件中所占比例也迅速攀升,信息公开的同时导致了信息的泄密[1]。在各种信息安全威胁所造成的损失中,企业和政府机构因重要信息被泄密所造成的损失排第一位。所以,信息泄密检测已成为一项十分艰巨而重要的任务。目前针对各级党政机关网站的信息泄密检测主要采用人工检测方式,效率低、安全性差。主要原因有3点:一是网络信息量大。工作人员需访问大量网页,下载大量文档逐一查看比较,通过人工判断是否存在涉密信息。二是泄密程度存在差异。泄密一般可分为全文与部分泄密。全文泄密检测相对容易,部分泄密的检测则难度高、工作量大。原因是泄密部分可能是涉密原文的部分段落,或是调整顺序的段落,或是调整语序的段落,或是对某些段落的合并、扩充、压缩等情况,更有甚者仅仅为涉密原文的某些语句。工作人员在检测时需逐段逐句的进行比较并定位疑似泄密信息,否则会出现漏检。三是安全性差,易造成二次泄密。由于人工检测需查看涉密文件,为信息的泄密多了一份可能与危险。针对以上问题,提出了一种基于自然语言处理的文本泄密自动检测技术,实验结果证明该方法是有效可行的。
1 相关技术
1.1 Web信息抽取技术
网络是巨大的数据库,同时也是信息泄密的重要渠道,从Internet或Intranet上获取信息,查看其是否含有涉密信息。目前人们主要通过人为打开网页或下载相关文档进行逐一查阅,费时费力,效率低。利用Web信息抽取技术[2](web information extraction),就是从Web页面中所包含的无结构化或者半结构化的信息中识别用户所感兴趣的信息数据,并将其转化为结构和语义更加清晰的数据格式。论文仍采用原先提出的一种基于视觉分块的Web信息抽取方法[3],自动抽取相关网站的信息。
在此基础上,又对具体网页进行深层抽取,即对某一具体网页的文本内容进行抽取。首先获得初次抽取的网页的网址集合,然后分析某具体网页源文件,最后采用基于正则表达式的方法自动将网页中的文本内容抽取出来,将此文本内容用作泄密检测的数据来源。
1.2 中文分词与文本加密技术
中文分词是汉语自然语言处理的第一步,也是最重要的环节。在中文信息处理中,信息检索、抽取、Web文本挖掘、文本分类等都主要以中文分词为基础。文中主要是利用中文分词技术,对文本进行分词,在分词的基础上,去除停用词,为相似度计算做好准备。
由于泄密检测的涉密文件,为防止其二次泄密,需对涉密文本进行加密;且保证加密过程不可逆,确保无法从加密后密文再得到明文,这样就很好地保证了涉密文件在泄密检测中的安全性。著名的MD5算法可以很好地满足加密要求。MD5算法[4]是由美国教授RonaldRivest于1992年对MD4做改进的基础上提出的HASH算法,就是把一个任意长度的字节串变换成一定长的大整数,并且是不可逆的字符串变换算法。
论文是利用MD5较好的安全性、不可逆性,对分词后的文本逐个词加密,每个不同的词加密后得到唯一的MD5信息摘要,相同的词必得到相同的信息摘要,这样保证加密后不影响比较结果。
2 主要流程与算法
2.1 相似度比较算法
相似度定义:A与B之间的相似度一方面与它们的共性相关,共性越多,相似度越高;另一方面与它们的区别相关,区别越大,相似度越低;当A与B完全相同时,相似度达到最大值。对于文本相似度的度量一般将其定义在[0,1]范围内,0值最小,表示完全不相似,1值最大,表示两者相同。
计算文本的相似度算法主要有基于马尔科夫模型[5]、基于属性轮[6]、基于语义理解[7-9]、基于向量空间模型[10-13]等几种经典的算法。论文采用的是基于向量空间模型的文本相似度算法。
向量空间模型(vector space model,VSM)是近年来使用较多且效果较好的一种模型。在VSM中,将文本看作由相互独立的词条组(T1,T2,…,Tn)构成,对于每个词条Ti,统计其个数,计算其词频,得到i词条在整个文本中所占的权重Wi,文本间的相似度就可以转化为向量之间夹角的余弦值来表示,夹角越小,表示越相似,对应的相似度值(余弦值)也就越大。需比较的两篇文档为P1,P2,相似度计算公式如下
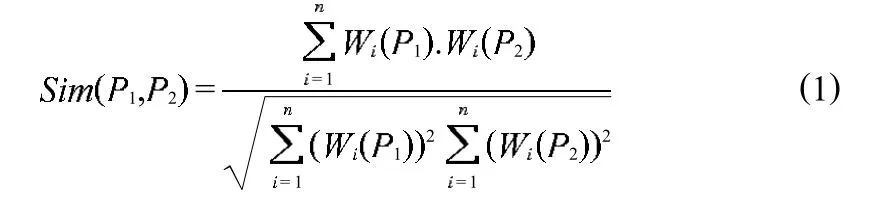
2.2 基于自然段落的相似度计算
(1)对待比较的文档P1与P2进行自然分段,对每段进行分词、去除停用词等预处理,并计算每段中词的权重;
(2)设定一个阈值(论文中设为0.5),将待检测的文档P1的段落P1i(i为P1的段落数)与P2中的所有自然段利用式(1)计算相似度Sim,当Sim大于设定的阈值时,则记录P2的段落数以及对应的相似度值,否则跳到步骤3;
(3)重复步骤2,直至P1中所有的段落与P2中的段落比较完成;
(4)统计记录的段落数,并进行标记,得到相似段落;
2.3 工作流程与步骤
泄密检测系统主要有4方面工作:一是文本信息源的获取(信息抽取),二是文本信息预处理(中文分词、文本加密等),三是相似度计算,四是基于自然段落的相似度计算。其模型与流程如图1所示。

图1 系统模型与流程
(1)对涉密文本A预处理,包括:中文分词、MD5加密得到每个词的密文,并计算每个密文的权重Wi(i为某词条);
(2)提供需检测的网站网址,利用基于视觉分块的Web信息抽取方法,得到一组列表网页的网址集合H;
(3)在步骤2的基础上,获得网址Hj,分析该网页的源文件,自动获取网页中文本内容Bj(j为某网页);
(4)对步骤3中获取的文本内容进行预处理,包括:中文分词、MD5加密得到第j篇文本分词后每个词的密文,计算每个密文的权重Wk(k为某词条);
(5)利用式(1),计算文本A与文本Bi的段落相似度Sim;
(6)重复步骤(3~5),得到文本A与文本集合B的相似度集合AllSim;
(7)根据设定的阈值,当AllSimj>0.5时,则认为第j网页泄密;否则进入步骤8;
(8)为了防止漏检,对涉密文本A与待检测的网页文本Bm(AllSimm<0.5)进行自然分段,采用基于自然段落的相似度比较方法,计算段落间的相似度,当相似度值大于阈值时,则认为段落相似;
(9)重复步骤8,直至所有小于阈值的文本比较完成,得到相似段落;
3 实验与分析
为了验证方法的可行性以及算法的正确性,设计了一篇文档test1.txt,由南京信息工程大学网站信息公告的最近50篇公告中的30篇内容组成,其中包括整段复制、部分段落复制、调换段落中语句顺序、调换段落顺序、对某些段落扩充或者压缩等多种情况,从而达到验证的目的。图2为文档与50篇信息公告初次比较的效果,粒度较大。所显示的网页为南京信息工程大学信息公告第24篇,与test1.txt相似度为0.96121,大于设定阈值0.5,直接判定该网页泄密。系统能定位到该网页,方面工作人员查看以及做好泄密报告。其中“B59CE2C0BB5 AAA86AB8B87C4EEA5EA79”为某一字符串加密后的密文,“【】”为分隔符,“0.00299”是其在文中所占的权重。

图2 初次比较结果
对于相似度值小于阈值的网页,也有可能存在泄密的信息。为了防止漏检,需对其进一步的检测。图3是根据初次比较结果,细化比较粒度,采用基于自然段落的相似度比较算法进行检测,设定阈值为0.5。为了显示比较的效果,所以将涉密文件以明文来显示。
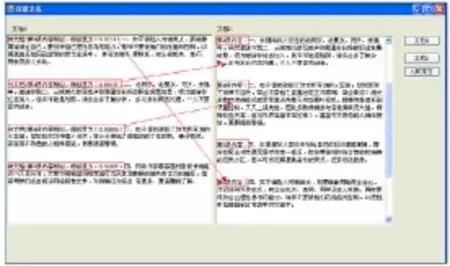
图3 基于段落相似度比较
图3中,左侧文档1为涉密文本的某些段落,右侧文档2为某网页文本内容。可以看出,文档1的第1段与文档2的第6段相似,相似度为0.9214,段落中语句顺序有调整;文档1的第2段与文档2的第3段相似,相似度为0.88177,区别在于少部分修饰的词语;文档1的第3段与文档2的第4段相似,相似度为0.68096,其主要摘取了文档2的部分语句;同样,文档1的第4段与文档2的第7段内容相似,相似度为0.92097,其主要是调整了部分语序以及摘取了部分语句。
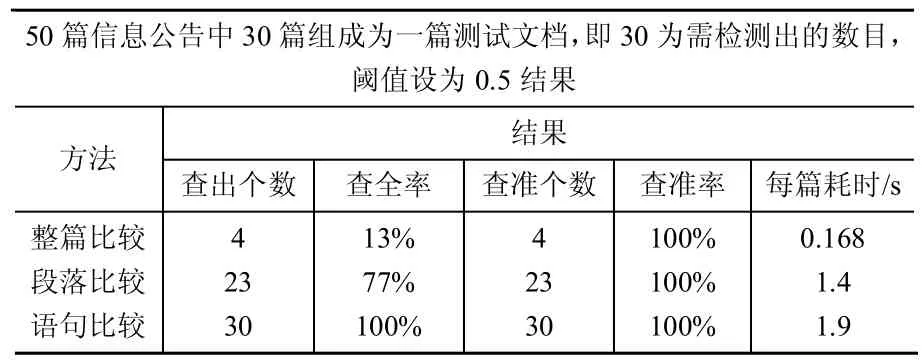
从以上实验可以看出,粗粒度比较只能计算出整体相似度,易出现漏检的可能。采用基于自然段落的相似度检测方法后,细化了比较的粒度,能定位到具体泄密的段落,而且无须考虑段落的顺序,段落语句顺序的调整,段落的扩充或者压缩等情况,能有效的检测出信息泄密。
基于自然段落的相似度比较主要有以下3种情况,如图4所示:假定涉密段落为P1,待检测的段落为P2。
(1)P1≈P2:P1与P2中内容大小相当(如图4中A情况所示);
(2)P1>P2:P1的内容远大于P2中涉密的内容,其中P2的内容仅仅是P1中的一小部分(如图4中B情况的红色部分);
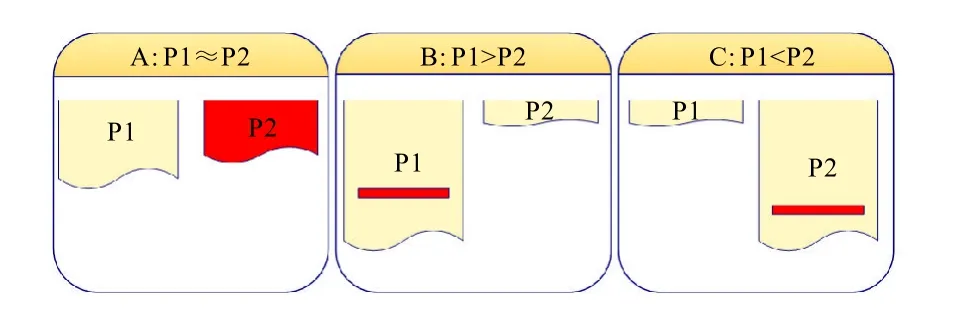
图4 段落相似度比较3种情况
(3)P1 在设定的阈值(论文中设为0.5)前提下,对于情况1,目前的算法能较好的计算其相似度并定位相应的疑似相似段落,对于情况2与情况3,由于基于VSM的相似度算法是利用词频统计来计算的,所以会出现漏检问题,即存在涉密的内容,但是由于计算所得的相似度值远远小于阈值而无法检测出泄密的内容。 针对情况2与情况3,论文提出两种解决方案。一是调整相似度阈值,即根据检测粒度的需要,将相似度阈值调小,从而提高检测的查全率,这种方法的局限在于要不断的调整阈值大小,而且易出现误检的可能。二是继续细化比较粒度,即段落的分块。对于大段落,将一定字数分为一块,然后与之比较得到相似的块,这样细化了段落,但同样存在问题,即块的大小确定为多大合适,另外一旦分块,易出现将涉密信息分块,导致漏检。 针对以上问题,论文又提出采用基于语句的相似度检测的方法。即在段落的基础上,根据段落中标点符号(主要是句号)对段落进一步细化,然后采用相似度计算方法,得到疑似的句子,效果如图5所示。段落中的语句顺序有所改变,部分词语有所增删,但不影响比较效果。算法步骤如下: (1)对待比较的段落Para1与Para2根据句号来分句,然后对每句进行分词、去除停用词等预处理,并计算每句话中词的权重; (2)设定一个阈值(论文设为0.5),将Para1的句子Si(i为句子数)与Para2中的所有句子利用式(1)计算相似度Simi,当Simi大于设定的阈值时,则记录Para2的语句数以及对应的相似度值,否则跳到步骤3; (3)重复步骤2,直至Para1中所有的句子与Para2中的句子比较完成; (4)统计记录的语句数,并进行标记,得到相似语句; 图5 基于语句的相似度计算 最后,对3种方法进行了性能比较,主要考虑查全率、查准率以及检测耗时3方面因素。比较效果如表1所示。 表1 3种方法性能比较 从表1可以看出,采用自然语言处理技术对文本进行泄密检测,效率高,50篇检测仅需8.4s,每篇耗时仅0.168s,采用段落和语句检测耗时也在2s以内。同时,采用段落和语句的比较后,在保证查准率的前提下,大大提高了查全率。 针对目前文本泄密检测采用人工方式检测,效率低、易泄密等问题,论文提出了一种基于自然语言处理技术的文本泄密自动检测方法。采用基于相似度比较方法,检测文本是否泄密。为了防止漏检与误检,设计了一种基于自然段落和语句的相似度比较算法,实验表明该方法是可行的。 从待检测的文本信息源的获取、信息加密、相似度比较到最后疑似泄密段落的定位都是自动的,并且改变以往人工一对一的比较方式,实现了一对多的比较,改变传统的明文比较,在加密后对密文进行比较。该方法具有效率高,安全系数高,人工参与少等优点。但不能完全替代人工检测,一是会存在误差,二是毕竟泄密是很严重的事,最后需要人的判定,但作为一种辅助的信息泄密检测技术,该方法能达到较好的效果。从完全人工的检测到现在只需人工最后的判定,一定程度上减轻了人的工作量与负担。 目前仍存在值得改进的地方,如对文本的预处理,没有考虑同义词问题,通过同义词转化,能提高相似度比较的精确度等,这将是下一步需要解决的问题。 [1]益阳保密网[EB/OL].http://www.yiyang.org/yybm/html/xuanchuan/20100318100838.html,2010. [2]Chang Chia-Hui,Mohammed Kayed.A survey of web information extraction systems[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(10):1411-1428. [3]耿焕同,宋庆席,何宏强.一种基于视觉分块的Web信息抽取方法研究[J].情报理论与实践,2009,32(3):106-109. [4]张裔智,赵毅,汤小斌.MD5算法研究[J].计算机科学,2008,35(7):295-297. [5]苏振魁.基于马尔科夫模型的文本相似度研究[D].大连:大连理工大学,2007. [6]袁正午,李玉森,张雪英.基于属性的文本相似度计算算法改进[J].计算机工程,2009,35(17):4-6. [7]金博,史彦军,滕弘飞.基于语义理解的文本相似度算法[J].大连理工大学学报,2005,45(2):291-297. [8]李鹏,陶兰,王弼佐.一种改进的本体语义相似度计算及其应用[J].计算机工程与设计,2007,28(1):227-229. [9]黄果,周竹荣.基于领域本体的概念语义相似度计算研究[J].计算机工程与设计,2007,28(10):2460-2463. [10]郭庆琳,李艳梅,唐琦.基于VSM的文本相似度计算的研究[J].计算机应用研究,2008,25(11):3256-3258. [11]Elsayed Atlam.A new approach for text similarity using articles[J].International Journal of Information Technology&Decision Making,2008,7(1):23-34. [12]khaled M Hammouda,Mohamed S Kamel.Document similarity Using a phrase indexing graph model[J].Knowledge and Information System,2004,6(6):710-727. [13]Xu Yong-Dong,Xu Zhi-Ming,Wang Xiao-Long,et al.Using Mulitiple features and statistical model to calculate text units similarity[C].Guangzhou:Proceedings of the Fourth International Conference on Machine Learning and Cybernetics,2005:18-21.
4 结束语
猜你喜欢
小学阅读指南·低年级版(2022年5期)2022-05-09
校园英语·月末(2021年13期)2021-03-15
小学阅读指南·低年级版(2020年9期)2020-10-12
新世纪智能(语文备考)(2020年4期)2020-07-25
阅读(快乐英语高年级)(2020年9期)2020-01-08
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
散文诗(2017年17期)2018-01-31
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
