
语音信号特征参数的提取
2011-08-29 05:39白瑜
科技传播 2011年24期
白 瑜
山西大学工程学院计算机工程系,山西太原 030013
1 语音学概述
1.1 汉语的音素、音节和音调
我们发现依据人类声音产生的机制,由于激励方式的不同会形成清音和浊音两种不同的语音。由这两种语音又可以组合成两种不一样音素:元音及辅音。构成语音的最小单位是音素。元音由不相同的口腔形状发声而形成,辅音的形成由发声的部位以及发声的方法决定。
音节是构成汉语的最小单位。我们所说的音节指的是一个元音加上一或两个辅音所构成的音素的组合。汉语当中包括以下4种音节,即:元音、元音+辅音、辅音+元音,辅音+元音+鼻音。一般汉语可以简单划分为声母+韵母两个部分。音节前部分的辅音称之为声母,元音和元音后面有时候出现的鼻音称之为韵母。汉语可认为是一种声调语言,根据声调的不同所表达的意思很可能完全不一样,汉语共有阴平、阳平、上声及去声四种声调。而声调的变化可以看成浊音周期的变化。声调曲线从韵母起始点至韵母的终止点。
1.2 语音信号的数学模型
语音的产生是因为声道激励发生共振,因为发声过程中声道是振动的,所以能够用一个时变线性系统来描述。可以用如图1所示描述语音生成模型。

图1 语音信号生成模型
由图1可知一个完整的语音信号模型由激励模型、声道模型、及辐射模型三个子模型串联而成。激励模型由浊音激励与清音激励组成。对清音部分来说,激励信号等同于白噪声,而对于浊音部分来说,因为声带在不断地张开与闭合,所以会有间隙性的脉冲波产生。共振峰模型是当前广泛使用的一种声道模型。声道的终端是人类口与唇,速度波通过声道输出,然而语音信号是一种声压波。
2 语音信号的前端处理
为了得到我们所需要的信号,须先对模拟语音信号进行数字化,接着进行预处理与加窗。
2.1 语音信号的数字化
为将模拟语音信号转变为数字信号,先对信号进行采样与量化。在采样与量化之前,须进行语音信号的预滤波,其目的在于:第一,滤除高频噪声;第二,防止50Hz的工频干扰。
2.2 语音信号的预处理与加窗
因为语音信号的平均功率受到鼻辐射以及声门激励的很大影响,因此在语音信号频谱的求取时,随着频率的增高相应的响应成分越小,也就是说高频部分频谱比起低频部分来不够精确,为此我们需要对信号进行预加重。为了平滑频域信号,使得信号处理的后面阶段对有限长响应不那么敏感,通常情况下让数字语音信号通过一个低阶的系统。目前广泛使用的是固定的一阶数字滤波器,即

式中a为预加重系数,通常取值0.95左右。
因为语音信号的特性是随时间变化的,而非平稳过程,但由于人的发音器官的肌肉运动速度比较慢,因此可以认为语音信号是个局部的短时平稳的信号。因此,我们对对语音信号进行分帧加窗的处理。通常情况下语音信号帧长取为10ms~30ms,每秒帧数约为33~100,分帧可以是连续的,有可以是交叠分段的,在语音信号的分析当中常用“短时分析”来表述。我们一般采用窗函数来乘语音信号,常用的窗函数是Hamming窗。
Hamming窗函数是:
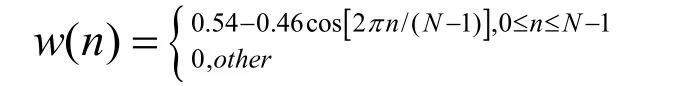
2.3 语音信号的端点检测
端点检测指的是找出语音信号中的各段落的起始点以及终止点的位置。语音信号的时域处理方法包括:短时平均幅度、短时能量、短时过零率以及短时自相关。端点检测一般要用到语音信号的短时能量以及短时平均过零率两中参数。
用En来表示第m帧的短时能量,其计算式如下:
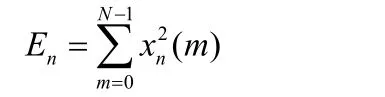
短时平均幅度M n的计算式如下:
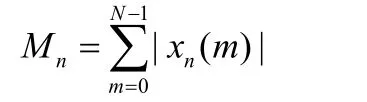
短时能量En的最主要作用是:区分清音与浊音、区分声母与韵母的分界、无声与有声的分界、连字的分界以及能够用于进行语音识别。
“过零率”指的是在单位时间内信号通过零的次数。短时过零率z(m)是用来描述频谱的简单有效的方法之一,计算公式如下:
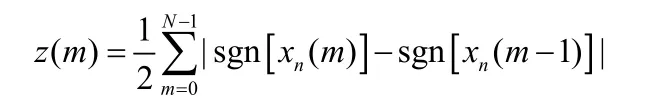
在短时处理技术中,描述一个随机信号的其中一个重要特征是自相关函数Rn,可以用自相关函数区分清音与浊音,计算公式如下:

短时频域处理作为语音信号处理的基本方法之一。短时频域处理适合缓慢变化的语音信号。第m帧的短时傅立叶变换计算式
如下:

3 语音特征参数提取
在完成语音信号的预加重、分帧、及端点检测之后,下一步关键的是提取特征参数。我们不可能直接识别原始波形,语音信号需要经过变换,提取出其特征参数后再进行识别,特征参数需要满足:反映语音的本质、参数个分量之间耦合尽量小、参数的提取方便等几方面的要求。目前语音识别中线性预测倒普参数LPCC、美尔倒普参数MFCC使两种较为常用的参数。LPCC利用线性预测编码技术求取倒普参数。MFCC则构造人的听觉模型,以语音信号经过该模型的输出值作为声学特征,直接利用离散傅里叶变换得到。
3.1 线性预测倒普参数LPCC的提取
线性预测分析是语音特征分析方法之一,能够有效的解决短时语音信号的模型化问题。LPCC的基本原理:语音信号的每个样值可以通过过去的若干个值的线性组合逼近求得,也能够用实际语音信号的抽样与线性预测的均方差值最小的方式,求出一组预测值。

其中a为加权系数,p为线性预测倒普参数的预测阶数。
LPCC系数表示的是语音信号频谱极值点的变化,用该系数来表征语音信号,能够获得比较平滑的语音频谱图。
3.2 美尔倒普参数MFCC的提取
MFCC参数与LPCC参数不同,它考虑了人耳的听觉特性,先将频谱转变为美尔频标的非线性频谱,接着再转换到倒普域上。因为MFCC比较地充分考觉特性,所以MFCC参数有很好的识别性能与抗噪能力。由测试可得,MFCC参数性能在汉语语音识别中要明显优于LPCC参数,由于人类在对1 000Hz频率以上的声音的感知能力并不遵循通常的线性关系,它遵循的是对数频率坐标上的线性关系。
MFCC计算步骤如下:

图2 MFCC计算过程
首先,语音信号在经过预处理、分帧加窗后转变为短时信号,经过FFT变换将x(n)转化为X(m),并计算出其短时能量谱P(f)。在将P(f)在频率轴上的频谱转化为在美尔坐标上的P(M)。接着在美尔频域内将在美尔坐标上加入三角带通滤波器得到滤波器组Hm(K),再计算美尔坐标上的能量谱P(M)通过该滤波器组的输出值。最后在美尔刻度谱上能够采取修改的离散余弦反变换来求取美尔倒普参数:

式中,p为MFCC阶数。
4 结论
本文主要介绍了语音学的基础知识、语音信号的数字化及其特征提取,为语音模型的训练做了很好的铺垫。在计算机普及的今天能够让计算机识别出人的自然语言是人们一直努力的一个方向,对计算机直接用语言信息发号施令,我们的双手才能真正得到解放。
[1]胡航.语音信号处理.2版.哈尔滨:哈尔滨工业大学出版社,2002:256.
[2]刘幺和,宋庭新.语音识别与控制应用技术.北京:科学出版社,2008:201.
[3]易克初.语音信号处理.北京:国防工业出版社,2000,14:363.
[4]李波,王成友,杨聪,等.基于语音频谱包络抽取的MFCC算法.长沙:国防科技大学学报,2004.
[5]桂苹,吴镇扬,赵力,等.基于VQ的说话人自动识别系统的实现[D].东南大学,2003.
猜你喜欢
知音海外版(下半月)(2022年1期)2022-02-26
考试与评价·八年级版(2021年4期)2021-08-14
时代英语·高一(2021年3期)2021-07-29
考试与评价·八年级版(2020年3期)2020-11-02
考试与评价·八年级版(2020年6期)2020-11-02
疯狂英语·新策略(2018年3期)2018-08-20
畜牧兽医学报(2015年3期)2015-07-05
湖南工业大学学报(社会科学版)(2011年6期)2011-12-28
