
基于类半径的多类分类SVM算法
2011-08-28 08:37刘长旺
华北水利水电大学学报(自然科学版) 2011年3期
张 涛,刘长旺
(南阳师范学院 软件学院,河南 南阳473061)
1 多类分类支持向量机算法
支持向量机算法最初是针对二类别的分类而提出的,如何将其有效地推广到多类分类是当前支持向量机算法研究的重要内容之一.目前,多类分类支持向量机算法主要有2种:第1种方法是构造多个二类分类器并将它们组合起来,从而实现多类分类,例如 one-against-rest,one-against-one,DAGSVM 等;第2种方法是直接在1个优化公式中同时考虑所有子分类器的参数优化.
one-against-rest是多类分类支持向量机算法中最简单的1种.它的具体步骤为[1]:
a.设已知训练集
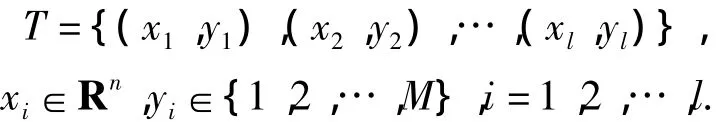
b.对 j=1,2,…,M 进行运算,把第 j类看作正类,把其余的M-1类看作负类,用某种二类分类支持向量机算法求出决策函数
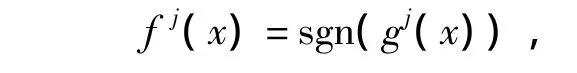
c.判定输入 x属于第 J类,其中 J是(g1(x),g2(x),…,gM(x))中最大者的上标.
这种算法遇到的问题是:①可能存在2个J值(J1或J2)使得gJ1(x)和gJ2(x)都达到最大,此时无法推断x的归属;②算法中构造的那些二类分类问题不对称.要处理这种不对称,可以对不同类别使用不同的处罚因子,对较少的类采用较大的处罚因子.
one-against-one算法的基本思想是为训练集中的任二类构造1个二类SVM分类器.在构造类别i和类别j的SVM子分类器时,在训练集中选取属于类别i和类别j的数据作为训练数据,并将属于类别i的数据作为正类,将属于类别j的数据作为负类.测试时,使用所有的子分类器处理所有的测试数据,比如1个子分类器判定x属于第i类就意味着第i类获得1票,最后票数最多的类别就是最终判定x所属的类别[2].这种方法需要构造很多的二类分类器,对M类问题就需要构造2-1M(M-1)个子分类器.这样就会使算法的训练时间较长,而且实际上可能并不需要求解2-1M(M-1)个子分类器.比如在数字识别问题中,计算了若干二类分类器之后,发现数字“7”和“8”的票都很少,已经不可能成为胜出者,这时候再计算“7-8”分类器就成了一种浪费[1].
有向无环图DAG(Directed Acyclic Graph)SVM算法在训练阶段和one-against-one算法相同,也是采用任意两两组合的训练方式,同样也需要2-1M(M-1)个子分类器.
但是在分类过程中,DAGSVM算法将所用的子分类器构成有向无环图,如图1所示.图中包括2-1M(M-1)个节点和M个叶子,其中每个节点是1个子分类器.当处理未知数据时,从根节点开始分类,只需M-1步即可完成分类.因为对于i-j分类器,如果判定某个数据属于类i,那么它就不可能属于类j,只可能属于类j以外的类.和one-against-one算法相比,在分类过程中减少了重复操作,大大提高了分类速度[3].这种分类方法的缺点是未考虑样本不平衡数据对分类速度的影响,而且没有考虑分类错误传递对后续产生的影响[4].
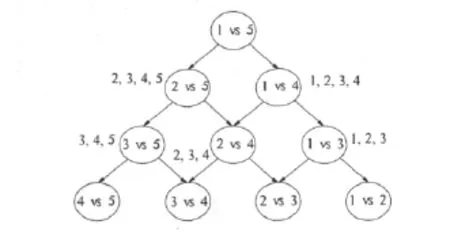
图1 采用DAG实现5类分类
上面几种算法都是构造多个二类分类器并将它们组合起来,而第2种方法是直接在1个优化公式中同时考虑所有子分类器的参数优化.
初始问题为[5]
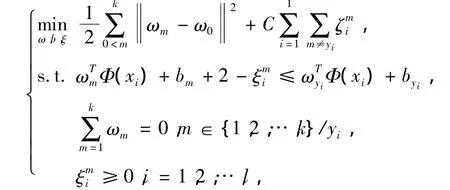
其对偶问题为
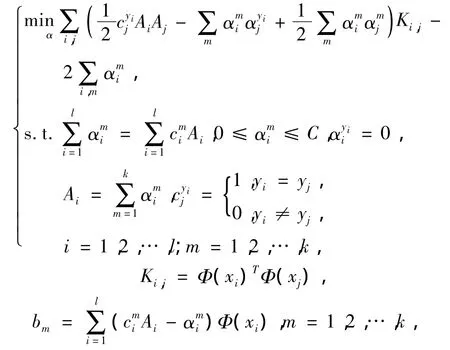
决策函数为
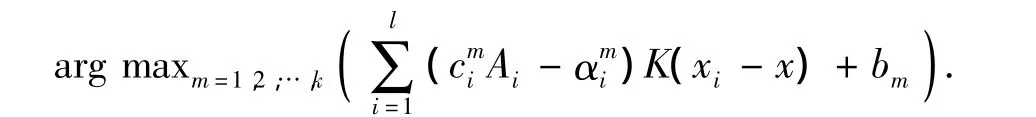
严格的讲,其思想类似于one-against-rest方法,只不过是把k个二值SVM优化问题放在1个最优化公式中同时优化,所以它也存在与one-against-rest方法相同的缺点.另外,这种思想尽管看起来简洁,但在最优化问题求解过程中,变量远远多于第1种,训练速度不及第1种,且分类精度也不占优[2].
2 基于类半径的多类分类SVM
现有多类分类支持向量机算法大多都有效率低或样本不平衡影响分类精度等不足,而且它们都没有在训练前分析训练集.笔者提出一种基于类半径的多类分类支持向量机算法,这种算法在训练前首先对训练集进行分析,然后使用one-class SVM进行分类.该算法效率较高而且克服了样本不平衡所带来的影响.
在多类分类问题中,每个类的训练样本数以及它所占的区域不同,在分类时需要区别对待.如果将所占区域小的类先分出来,而将所占区域大的类后分出来,这样就会减少误差.
根据上述思想提出了基于类半径的多类分类支持向量机算法,具体步骤如下:步骤1 设已知训练集
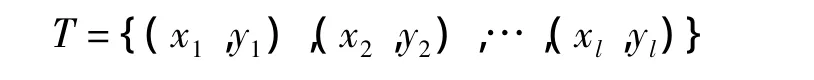
其中 xi∈Rn,yj∈{1,2,…,M},i=1,…,l;
步骤2 计算各类训练数据的中心和所占区域的半径
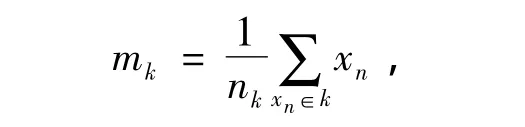
其中nk为属于第k类的样本的个数.

步骤3 对于每一类,使用one-class算法构造分类器,具体算法为:
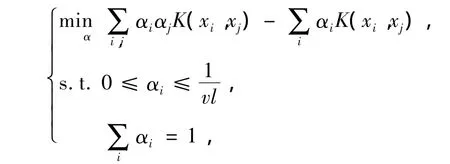
其决策函数为
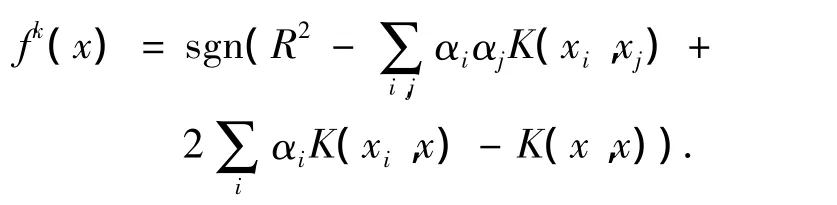
步骤4 在测试时,首先对Rk从小到大排序;然后根据Rk对所有的类从小到大排序;最后按类的顺序用各类的决策函数处理数据.若fj(x)=1,则输入x属于类 j,后面类的决策函数不再处理此数据.
在多类分类问题中,所占区域越小的类就越容易处理而且它包含其它类数据的概率也越小,而所占区域较大的类就容易包含其它的数据.所以该算法首先根据类半径对各类从小到大排序,然后再进行分类,这样不仅减少误差而且简化了算法.该算法使用one-class SVM算法构造子分类器,不仅避免了训练数据不平衡的问题,而且提高了算法的效率.
3 仿真实验
使用机器学习UML标准数据库中的数据集,对one-against-rest,one-against-one,DAG 等算法和新算法分别进行实验测试.表1列出了所用数据集的一些信息.

表1 试验数据集统计表
试验中使用的各种算法均采用MatLab R2006a实现,其中的二值SVM是在LIBSVM工具包基础上修改实现,试验中使用 RBF核函数,K(x,x')=exp(-γ‖x-x'‖2).试验平台为 P4 3.0G,512M RAM的方正PC,操作系统为Windows Server 2003.试验结果见表2.
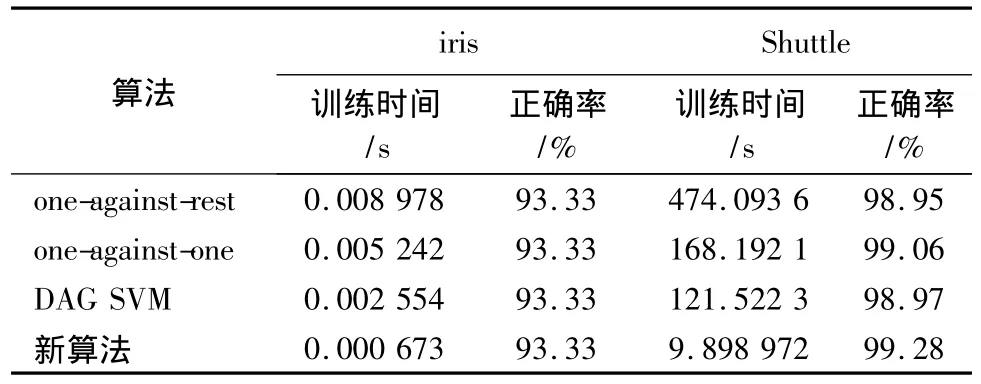
表2 试验结果
由结果可知,新算法的训练时间比其它几种算法较少.该算法虽然在训练前要对训练数据进行分析,计算各类所占区域的半径并排序,但是由于算法只用正类进行训练所以节省了时间.其它几种算法要构造很多的二类分类器,所以训练时间较长.
4 结语
提出了基于类半径的多类分类支持向量机算法.试验结果说明,该算法的分类精度较高,而且可以节省训练时间.同时也说明,将预先分析训练集的思想用于多类分类支持向量机算法,会得到较好的效果.
[1]邓乃扬,田英杰.数据挖掘中的新方法——支持向量机[M].北京:科学出版社,2004.
[2] Hsu C,Lin C.A comparison of methods for multi-class Support Vector Machines[J].IEEE Trans on Neural Networks,2002,13(2):415 -425.
[3] Boonserm Kijsirkul,Nitiwut Ussivakul.Multiclass support Vector Machines using adaptive directed acyclic graph[C]//IEEE/INNS International Joint Conference on Neural Networks(IJCNN—2002).Honolulu Hawaiian USA:Department of Information Systems Science,Faculty of Engineering,Soka University,2002:980 -985.
[4]郑勇涛,刘玉树.支持向量机解决多分类问题研究[J].计算机工程与应用,2005(23):190-192.
[5] J Weston,C Watkins.Multi-class Support Vector Machines[M].Brussels:D Facto Press,1999.
猜你喜欢
制造技术与机床(2019年6期)2019-06-25
民族古籍研究(2018年1期)2018-05-21
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
新校长(2016年8期)2016-01-10
中国海上油气(2015年3期)2015-07-01
浙江大学学报(工学版)(2015年1期)2015-03-01
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
