
苎麻纤维素含量近红外预测模型的建立与探讨
2011-08-21 12:20:32肖爱平杨喜爱廖丽萍田小兰聂晴岚
中国麻业科学 2011年4期
肖爱平,冷 鹃,杨喜爱,程 毅,廖丽萍,田小兰,聂晴岚
(中国农业科学院麻类研究所,湖南 长沙 410205)
1 引言
苎麻在我国有着悠久的生产和加工历史,我国的苎麻产量占世界总产量的90%以上,在国际上享有“中国草(China Grass)”之美誉。其纤维有着其他纤维所不具备的优良品质和特性,织成的服装更显舒适、挺括和高雅,特别是在注重环境保护、崇尚回归大自然的今天,苎麻产品将会成为人们首选的绿色产品之一,前景十分广阔。
苎麻的主要化学成分为纤维素,除含有部分半纤维素、水溶物、果胶、木质素等伴生物外,其纤维素含量在65%-75%左右。纤维素是苎麻原料应用于纺织加工的主要成分,它的含量直接决定了其原料的纺织可用价值,纤维素含量的高低是评价苎麻品质的重要指标之一,测定纤维素的方法有多种,如:浓酸水解定糖法、硝酸-乙醇法、氯化法、酸性洗涤法等。这些方法操作比较复杂、繁琐,且精度不高,有些方法危险性较大(如硝酸-乙醇法)。目前主要采用“GB5889-86苎麻化学成分定量分析方法”来分析苎麻纤维素含量,耗时长、效率极低,误差较大,给大量育种材料、优质资源的鉴定、筛选带来困难。因此迫切需要有一种快速、简便的检测方法,以满足苎麻育种、优质资源快速筛选的要求。
近红外光(Near Infrared)是指介于可见光与中红外光之间的电磁波,波长为780—2526nm。近红外光谱分析技术具有快速、高效、非破坏性等优点。
有机分子中的OH、CH等基团振动光谱的倍频及合频吸收,以漫反射方式捕获在近红外区的吸收光谱,通过主成份分析、偏最小二乘法、多元线性回归和人工神经网络等化学计量学手段,建立样品光谱与待测成分含量间的线性或非线性关系,即建立预测模型,然后根据模型和未知样品的光谱预测未知样品的成分含量。
纤维素主要是由葡萄糖基以-1,4苷键连接起来的链状高分子化合物,含有大量的C-H,O-H含氢基团使其在近红外区域具有丰富的吸收,为近红外技术应用于苎麻纤维素定量分析提供了依据。
本文通过化学分析方法(GB5889-1986)和近红外光谱法,建立了苎麻纤维素含量的预测模型,采用该模型可较好地预测出苎麻粗纤维的含量。
2 材料与方法
2.1 材料准备
实验所用材料为中国农业科学院麻类研究所国家种质长沙苎麻圃内102个样品的韧皮纤维,其中80个作为校正集样品,22个作为验证集样品对模型进行验证。用于近红外光谱采集的苎麻样品经风干后粉碎,过60目筛后备用。
2.2 化学值的测定
将准备好的80个校正集样品分别按照“GB5889-1986苎麻化学成分定量分析方法”质量损失法测定苎麻原麻的纤维素。
2.3 原始光谱的采集
用波通(Perten)公司DA7200型近红外光谱分析仪采集苎麻纤维的原始光谱。仪器工作参数:950nm-1650nm,采样间隔2.0nm,扫描次数为32次(以内部陶瓷为参考),分辨率16cm-1。每个样品扫描2次,重复装样3次,取其平均值用作近红外光谱分析。将准备好的80个校正集苎麻样品倒入直径75mm的分析杯内,表面刮平,在950nm-1650nm谱区范围内进行连续扫描,收集80个样品的近红外漫反射吸收光谱图(原始光谱图)。
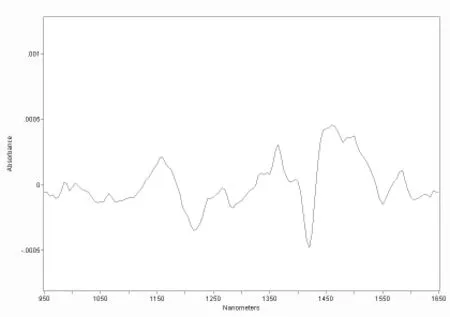
图1 苎麻样品的近红外原始光谱图Fig.1 The original near-infrared spectroscopy of ramie samples
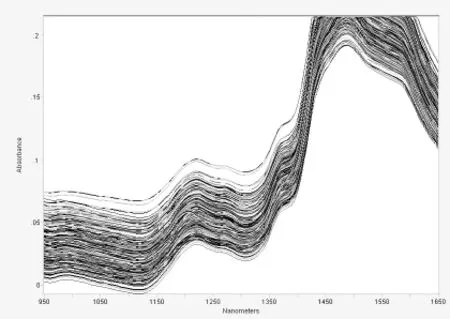
图2 中心化+附加散射+一阶导数处理后纤维素的光谱图Fig.2 The spectrogram of cellulose after being treated with MC,MSC and SGl
3 预测模型建立与验证
3.1 光谱预处理
为消除NIR光谱信号中的基线漂移、背景和光散射等各种干扰信息和噪声,提高模型的预测精度,需对原始光谱进行预处理。该处理过程由GRAMS软件进行,采用多元散射矫正(MSC)、导数包括一阶导数(SGl)和二阶导数(SG2)、标准正态变量转换(SNV)、中心化(MC)等对光谱进行预处理,预处理后的苎麻纤维素光谱图如图2所示。经过选择不同谱区、反复计算、比较优化之后,最后确定采用中心化、多元散射校正和一阶求导相结合的方式建立预测模型。
3.2 预测模型的建立
用GRAMS软件对建模光谱数据进行预处理后,采用偏最小二乘法(PLS)和完全交互验证的方式,在样品纤维素含量和光谱数据间建立预测模型,通过比较模型相关系数(R2)、交互验证标准差(SECV)考核校正模型的实用性,然后根据R2、SECV和预测标准差(SEP)确定最优模型。
苎麻纤维素含量与近红外光谱之间的相关关系可由模型建立后所得的相关系数R2和交互验证的结果来衡量,交互验证后的得到的参数为:相关系数(R2)为0.9730,预测标准差 (SEP)为0.812。NIR预测模型相关系数越高,标准偏差越小,模型的预测效果越好,预测模型的结果如表1所示。

表1 预测模型结果Tab.1 The results of prediction model
3.3 苎麻纤维素预测模型的验证
为了检验所建的预测模型实际预测效果,利用此模型对22个苎麻试样的纤维素含量进行预测,同时用化学方法(GB5889-1986)分别测定其纤维素含量,将预测值与测定值进行比较(见表2)。结果表明22个样品纤维素含量的预测值与化学测定值基本一致,最大相对偏差3.22%,平均相对偏差1.17%,说明模型的预测精度较高。

表2 GB/T5889-86法纤维素测定值和近红外光谱法预测值所得结果的对比Tab.2 Comparisons between tested and predicted values of ramie cellulose contents
为了更好地表示验证集样品纤维素含量(化学测定值)与近红外光谱模型预测值之间的相关性,通过绘制化学测定值和预测值之间的散点图来表现两者之间的线性相关性(图3)。从上图可见,苎麻纤维素近红外光谱模型的预测值和化学分析法的测定值之间具有良好的相关性,说明用近红外光谱预测模型快速预测苎麻的纤维素含量是可行的。
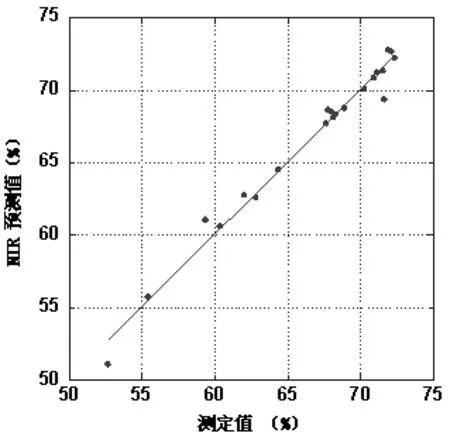
图3 苎麻纤维素预测值与测定值相关关系Fig.3 The correlation between tested and predicted values of ramie cellulose
4 结论
本文研究建立了近红外光谱测定苎麻纤维素含量的预测模型,该模型预测纤维素的相关系数为0.9726,预测值与化学测定值(GB5889-1986)的平均相对误差为1.17%,利用NIRS预测苎麻纤维素含量的方法基本接近或达到了化学分析方法的精度要求。因此在实际生产中用近红外光谱法快速测定苎麻纤维素含量是可行的,利用该研究预测苎麻纤维素含量可大大降低劳动强度,缩短检测时间,其效率是常规化学方法无可比拟的。本研究为初步探讨研究,预测模型有待进一步优化和验证。
[1]姜繁昌,邵宽.GBfr5889-1986苎麻化学成分定量分析方法[S].北京:中国标准出版社,2000.
[2]严衍禄,赵龙莲等.近红外光谱分析基础与应用[M].北京:中国轻工业出版社,2005:290,333,465.
[3]杨淑蕙.植物纤维化学[M].北京:中国轻工业出版社,2001:163.
猜你喜欢
企业界(2024年8期)2024-07-05 10:59:04
今日农业(2021年19期)2022-01-12 06:16:32
环境保护与循环经济(2021年7期)2021-11-02 08:10:54
纺织科技进展(2021年3期)2021-06-09 08:07:14
陶瓷学报(2021年1期)2021-04-13 01:33:02
国外核新闻(2020年8期)2020-03-14 02:09:19
动物营养学报(2017年2期)2017-02-28 05:04:26
中国麻业科学(2015年5期)2015-12-28 06:22:11
中国麻业科学(2015年5期)2015-12-28 06:22:07
中国麻业科学(2014年5期)2014-12-05 06:51:56
