
基于信道模式噪声的录音回放攻击检测*
2011-08-02 05:51:14王志锋贺前华张雪源罗海宇苏卓生
华南理工大学学报(自然科学版) 2011年10期
王志锋 贺前华 张雪源 罗海宇 苏卓生
(华南理工大学电子与信息学院,广东广州510640)
随着说话人识别技术的不断发展,说话人识别系统在司法取证、电子商务、金融系统等领域得到了非常广泛的应用[1].与此同时,说话人识别系统所面临的前端攻击及传输存储等的安全问题制约了说话人识别系统的发展和应用.
说话人识别系统面临的两种常见攻击是说话人仿冒攻击[2]和录音回放攻击[3].说话人仿冒攻击是指攻击者通过模仿说话人识别系统中用户的声音对系统进行的攻击.在双胞胎语音库上的说话人识别实验表明,现有的说话人识别技术能够区分具有类似声学特性的双胞胎语音[4],因此实施说话人仿冒攻击需要有非常好的模仿技巧,使攻击者的语音能够和系统用户的语音达到高度的相似,这使得仿冒攻击的可实施性不高.录音回放攻击是指攻击者事先用高保真录音设备偷录说话人识别系统中用户的语音,然后通过高保真功放在系统输入端回放,以此对说话人识别系统实施攻击.与仿冒语音相比,录音回放语音是真实来自于用户本人,对说话人识别系统造成的威胁更大.另外,现在性能好的高保真录音及回放设备不断涌现,其价格越来越便宜,体积越来越小,便于携带不易被发现,这使得录音回放攻击越来越容易实施.
防止录音回放攻击的一种方法是通过系统随机挑选语句让用户跟读,在进行说话人识别的同时还要判断用户是否按要求来跟读.这种方法的实施需要事先准备丰富的语音库,并要求用户按照语音内容跟读,当用户按照自己的习惯发音时,将有可能通不过说话人识别系统[5],而且这种方法会牺牲说话人识别系统对于特定用户特定文本的安全保护性,产生一些其它安全问题[3].
文献[5]中以通用背景模型为基础,利用系统直接采集的用户原始数据中的静音段对信道进行建模,检测待识别语音与训练语音的信道是否相同.由于静音段幅度很小,比语音段更容易受到噪声污染,故静音中信道信息很容易被噪声掩盖.此外,以大量说话人的通用背景模型为基础,并不一定能够训练出精确的信道模型.
回放语音在进入说话人识别系统录音信道前,还经历了一次录音和一次回放的过程.不同的录音和回放设备引入不同的信道噪声(麦克风、扬声器、抖动电路、前置放大器、功率放大器、输入和输出滤波器、A/D、D/A、取样保持电路等都会引入相应的噪声[6]),这些信道噪声叠加在回放语音上,使得回放语音和原始语音存在细微的差异.文中将这些来自不同录音与回放设备中换能器和不同电路引入的噪声称为信道模式噪声.原始语音中含有系统录音设备的信道模式噪声,而回放语音中不仅含有系统的信道模式噪声,还含有偷录设备和回放设备的信道模式噪声.为此,文中提出了一种通过提取原始语音和回放语音中的信道模式噪声来检测录音回放攻击的方法.
1 录音回放攻击检测系统
基于信道模式噪声的录音回放攻击检测系统主要由5个部分组成:预处理、信道模式噪声提取、长时统计特征提取、基于支持向量机(SVM)的信道噪声建模、原始语音和回放语音的分类识别,如图1所示.
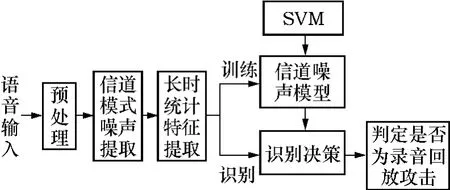
图1 基于信道模式噪声的录音回放攻击检测系统结构Fig.1 Structure of playback attack detection system based on channel pattern noise
根据录音回放攻击检测模块在说话人识别系统中所处位置的不同,录音回放攻击检测器可分为前端录音回放攻击检测和后端录音回放攻击检测,如图2所示.进行前端回放攻击检测时,输入的用户语音首先进行回放攻击检测,如果被判定为录音回放语音,则系统可直接拒绝为攻击语音提供服务.对于前端回放检测,输入语音可以来自系统中任意用户,需要为所有用户建立一个具有泛化能力且不被特定用户所影响的回放攻击检测器.对于后端回放检测,用户语音首先进行说话人识别,如果判定为合法用户,则将其输入到后端检测器进行回放攻击检测.此时,说话人识别系统可为回放检测器提供用户信息,只需为单个用户建立相应的后端回放攻击检测器.
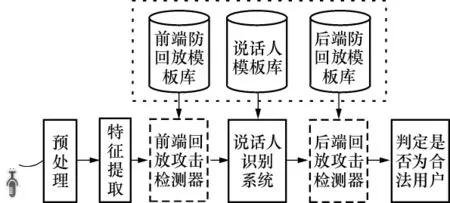
图2 具有防录音回放攻击功能的说话人识别系统结构Fig.2 Structure of speaker recognition system with playback attack detector
1.1 基于统计帧的对数功率谱
一般认为,信道噪声是均匀地作用在整个发音之上[7],不同录音及回放设备的信道模式噪声是和语音信号同时产生的.因此,考虑采用具有统计意义的长时特征来描述信道模式噪声,进而获得稳定的信道噪声分布.统计帧是语音信号中所有短时帧的相同频率成分的平均值,设X={x1[n],x2[n],…,xT[n]}表示有T帧的语音信号,则第i(1≤i≤T)帧信号xi[n](0≤n≤N-1)的离散傅里叶变换为

那么统计帧的表达式为
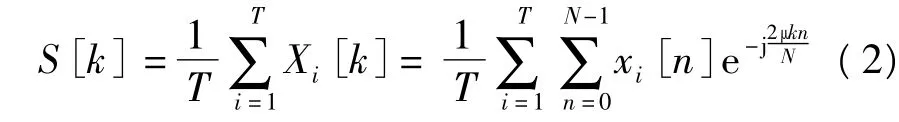
统计帧的具体提取过程如图3所示.

图3 统计帧的提取过程Fig.3 Procedure of extracting statistical frames
统计帧具有以下优点:1)统计帧是将大量短时语音帧在频域进行叠加,从而可获得稳定的信道模式噪声分布;2)统计帧具有归一化的作用,它可以将时域中不同长度的语音信号映射为在频域具有相同帧长的信号,以降低特征提取和建模的计算复杂度.
因为换能器和各种电路引入的信道噪声为时域的卷积信号[7],所以考虑在对数谱域来提取信道模式噪声,将非线性噪声转换为线性噪声.如图4所示,在基于统计帧的对数功率谱上,原始语音与回放语音(原始语音与回放语音都来自同一个说话人,且文本为同一数字串“5940247874”)在低频部分存在差异,这是由原始语音和回放语音所包含的信道模式噪声不同引起的,表明信道模式噪声主要集中在信号的低频部分.与信道引入的卷积噪声主要集中在信号的低频部分[8]一致.
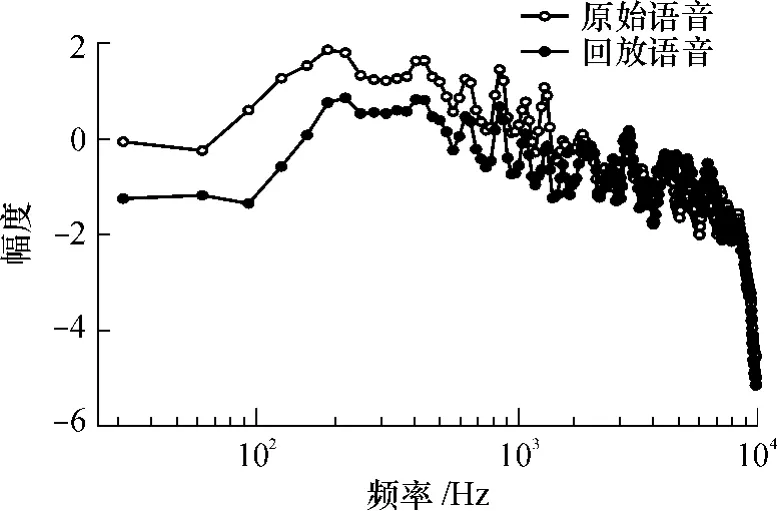
图4 基于统计帧的对数功率谱Fig.4 Logarithm power spectrum based on statistical frames
1.2 信道模式噪声及特征
由于信道模式噪声主要集中在信号的低频部分,故文中采用去噪滤波器来提取信道模式噪声,即
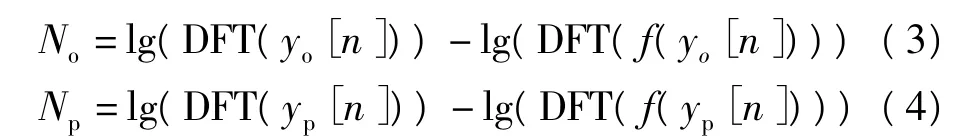
式中:yo[n]、yp[n]、No和Np分别为原始语音、回放语音、原始语音的信道模式噪声及回放语音的信道模式噪声;DFT为离散傅里叶变换;f为去噪滤波器,文中采用高通滤波器来过滤掉信号中的信道模式噪声.通过对多个去噪滤波器的实验,最终采用文献[9]中的滤波器.
基于信道模式噪声的长时统计特征提取的流程如图5所示,在信道模式噪声的基础上提取了两组长时特征:6阶Legendre多项式系数和6个统计特征.
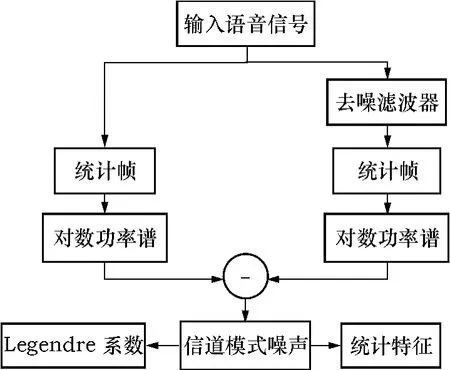
图5 基于信道模式噪声的长时统计特征提取流程图Fig.5 Extraction flowchart of long-term features based on channel pattern noise
1.2.1 Legendre多项式系数
Legendre多项式是一组完备正交基,可以很好地进行参数拟合,已在语种识别和一些实际问题的解决中成功应用[10].Legendre多项式的形式如下:

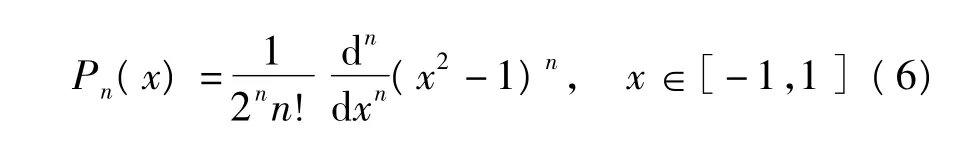
信道模式噪声变化缓慢,在实际应用中Legendre多项式系数的阶数不高,实际上使用6阶的系数就能够进行信道模式噪声的参数拟合.其中,L0为信道模式噪声的直流部分,L1为信道模式噪声分布曲线的斜率,L2为信道模式噪声分布曲线的曲率,L3、L4、L5分别为信道模式噪声分布曲线的细节信息.
1.2.2 统计特征
因信道模式噪声一直伴随着语音信号并且变化缓慢,故文中采用6种统计特征来描述信道模式噪声:信道模式噪声的最小值 PN_min、最大值 PN_max、均值 PN_mean、中值 PN_median,最大值和最小值的差PN_diff、标准差PN_stdev.
1.3 基于SVM的信道噪声模型
SVM是一种基于结构风险的统计学习方法,具有很好的泛化和分类能力,已在说话人识别中取得了很好的效果[11].SVM可以看成由多个内积K(xi,xj)求和构成的二类分类器.录音回放攻击检测实质上是一个二分问题.对于输入矢量x,支持向量机的输出为
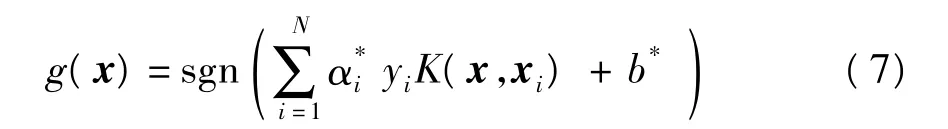
式中:α*为分类的最优化解,α*=(,,…,);b*为分类阈值;yi为分类标签,yi∈{-1,1}.
文中将两组长时特征组合成一个12维的特征矢量,并作为训练和识别的特征,选择径向基函数作为核函数.然后采用自组织映射(SOM)算法[12]和格形搜索算法[13]找到最优的惩罚因子C和γ参数,并将最优参数用来训练信道噪声模型.
2 APSD数据库
由于没有现成的数据库,文中建立了原始语音和回放语音数据库(APSD)进行录音回放攻击检测的研究.考虑到语速、文本类型、朗读语音和自然语音等的影响,该数据库的语料设计如下:1)20个孤立词短语;2)10个连续数字串,每个数字串包含10个数字;3)60个音素和音节分布均匀的句子(每句5~16个字),其中15句选自863连续语音库,15句选自863四大方言库,15句选自《人民日报》,15句选自“新华网”;4)两篇音素和音节分布均匀的短文,共223个字,以正常的语速朗读;5)第三部分和第四部分的语料以慢速和快速朗读各一遍;6)从5个话题中选取一个进行即兴演讲,长度约为2min.
数据库录制历时6个月,有9男4女参与录制,用统一标准的普通话进行录音.经统计,本语料库的字频和《现代汉语频率词典》提供的汉字字频基本保持一致,包含1473个中文汉字、345个音节、汉语中所有的60个音素.
原始语音与回放语音的录制模拟了实际录音回放攻击产生的整个物理过程.原始语音是通过固定的麦克风和数据采集卡(创新5.1声卡,设置为16kHz,16位)进行采集.在采集原始语音的同时,用高保真的数字录音笔录制说话人语音,模仿偷录过程(偷录者会尽量采用高保真的录音设备获得高品质的偷录语音,文中采用高保真数字录音笔三星yep120,采样率为22.05kHz,并用16位采样),然后通过便携高保真直流功放(奥特蓝星iMT237)在数据采集卡的输入端回放录音,从而采集回放语音.
3 实验结果与讨论
从APSD数据库中选取了12220个语音样本,包含了13个说话人的数据,每个人的数据为940个(470个原始样本Au_R和470个回放样本Pb_R),实验数据的分布如表1所示.文中采用FRR(错误拒绝率)和FAR(错误接受率)作为评价录音回放攻击检测系统性能的指标,同时采用十折交叉验证进行实验,结果为10次实验结果的平均值.统计帧的帧长取512点,Legendre多项式取0~5阶系数.

表1 选取的实验样本数Table 1 Numbers of selected data samples
实验1 组织了10名志愿者(7男3女)参与听觉实验,要求每个志愿者听100个语音样本(50个原始语音样本和50个回放语音样本),然后做出选择(志愿者事先不知道语音样本的类别).总共进行了1000次听觉实验,正确识别率为58.6%,说明人耳对原始语音和回放语音的分辨能力很低.
采用Au_R和Pb_R数据集分别在基于混合高斯模型(GMM)和隐马尔科夫模型(HMM)的说话人辨识系统上进行说话人识别实验.实验时,GMM说话人辨认系统的高斯个数设为256,HMM说话人辨认系统的状态个数设为4,每个状态下的高斯个数设为64.原始语音和回放语音在GMM系统上的正确率分别为97.7318%和93.6966%,在HMM系统上的正确率分别为87.2781%和81.0897%,即回放语音的说话人正确识别率和原始语音保持在同一个水平上,这说明录音回放语音对于说话人识别系统的攻击是真实存在的.
实验2 利用13个人的数据建立前端录音回放攻击检测器,采用文中方法和文献[5]中方法在APSD数据库上进行实验.实现文献[5]中方法时,采用双门限法提取静音,并用谱减法滤波,采用39维的Mel倒谱系数(MFCC),建立信道模型时GMM的高斯个数设为512.文中方法的FRR和FAR分别为2.861 9%和2.450 7%,与文献[5]中方法的15.6732%、15.6732%相比,下降了近13%.
将回放攻击检测模块加载到GMM-UBM说话人确认系统(该系统的高斯个数为1024)的前端进行对比实验,同一用户的回放语音归为不是该用户的语音,实验结果如图6所示.对于含有回放攻击语音的数据,未加载回放攻击检测模块时,说话人确认系统的错误率很高,系统的等错误率(EER,即FAR=FRR时)为40.1709%,此时,系统的安全性能很低;加载文中回放攻击检测模块后,系统的 EER为10.2564%,下降了约30%;加载文献[5]中的回放攻击检测模块后,系统的EER为29.0598%,下降了约11%,表明文中方法的检测效果优于文献[5]中方法.
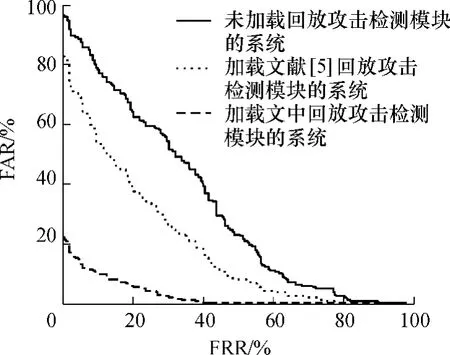
图6 加载录音回放攻击检测模块前后说话人确认系统的错误率对比Fig.6 Comparison of error rates between speaker verification systems with and without playback detector
为每个说话人建立后端录音回放攻击检测器,其中F01-F04为4位女性说话人,M01-M09为9位男性说话人,F03、M03及M04的FRR和FAR都为0,结果如表2所示.由图6、表2可知,后端回放检测的效果比前端检测好.
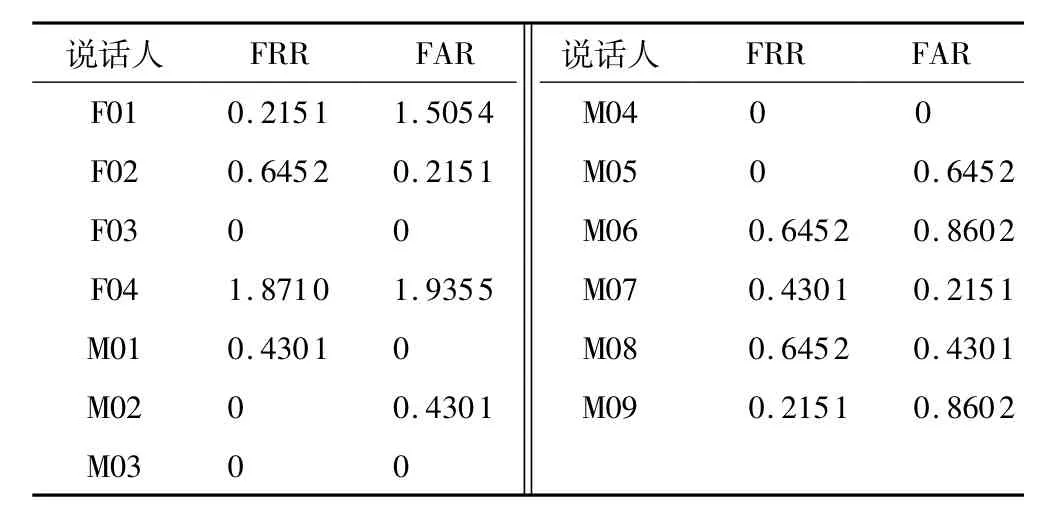
表2 后端录音回放攻击检测器的检测结果Table 2 Detection results of back-end playba ck attack detector
实验3 以录音回放攻击检测系统为基础,将传统的倒谱特征和文中的长时统计特征进行对比实验,结果如表3所示.从表3中可知,由6阶Legendre系数和6个统计特征组成的基于统计帧的12维长时特征比其它特征有更好的识别性能.信道模式噪声主要集中在语音信号的低频部分,MFCC和线性预测倒谱系数(LPCC)等倒谱特征中低频部分所占比重很小,不能很好地体现信道信息,而文中采用的长时特征是基于信道模式噪声提取的,可凸显出信道信息,因此具有更好的识别性能.
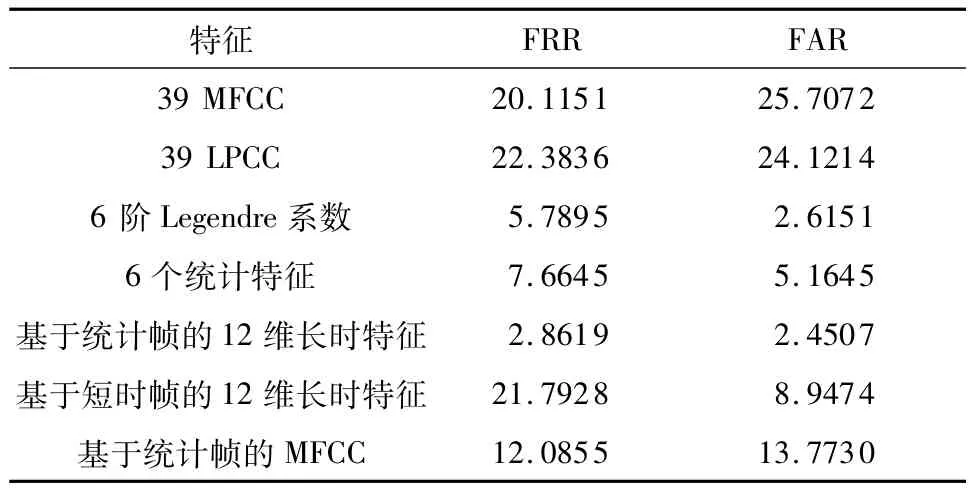
表3 基于不同特征的回放攻击检测结果Table 3 Playback attack detection results based on different features
与基于短时帧的12维长时特征相比,基于统计帧的12维长时特征有更好的检测效果和识别性能.这说明基于统计帧的分析方法对于回放攻击检测是有效的.
实验4 考察不同语速、不同文本类型、不同说话人等因素对录音回放攻击检测系统的影响,结果如表4、5所示.表4表明,语速对录音回放攻击检测系统有一定的影响,但影响不明显.
表5表明,不同类型文本对录音回放攻击检测性能有较大的影响,段落文本的FRR和FAR最低,主要是因为段落的时长最长,为3min左右(数字串和句子的长度为5~8s,而短语的长度为2~3s),可以提供更多的信道噪声信息,获得更稳定的信道噪声分布.在实际应用中,可以考虑采用数字串作为用户进入系统的口令(数字串的FAR低,可保证系统的安全性).
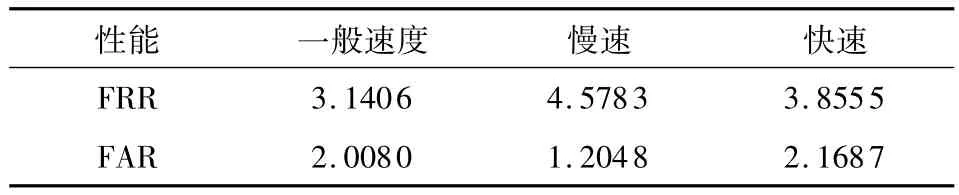
表4 语速对回放攻击检测性能的影响Table 4 Influence of speech rate on playback attack detection performance
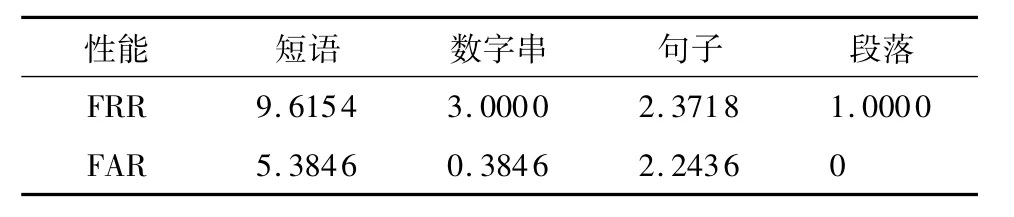
表5 文本类型对回放攻击检测性能的影响Table 5 Influence of text type on playback attack detection performance
从表2可知,录音回放攻击检测系统对不同说话人的回放攻击检测性能也是不一样的,不同说话人对文中录音回放攻击检测系统的性能也会产生影响.
4 结语
文中通过提取信道模式噪声来检测说话人识别系统中的录音回放攻击,实验表明,回放攻击检测的FFR和 FAR分别为 2.861 9%、2.450 7%,与文献[5]中方法相比,均下降了近13%.加载了文中的录音回放攻击检测系统后,说话人确认系统的EER下降了约30%.
目前,文中只使用了一种录音和回放设备,获得了一些初步结果,还需要扩展其它类型的录音和回放设备,以及包含更多说话人的数据来验证文中方法的鲁棒性;另外,还将对信道模式噪声的性质做进一步的研究,并利用信道模式噪声来解决语音识别和说话人识别中的信道不匹配问题.
[1]Vale E E,Alcaim A.Adaptive weighting of subband classifier responses for robust text independent speaker recognition [J].Electronics Letters,2008,44(21):1280-1282.
[2]Wah Lau Yee,Wagner M,Tran D.Vulnerability of speaker verification to voice mimicking[C]∥Proceedings of Intelligent Multimedia,Video & Speech Processing.Hong Kong:IEEE,2004:145-148.
[3]Shang Wei,Stevenson M.Score normalization in playback attack detection[C]∥Proceedings of Acoustics,Speech and Signal Processing.Dallas:IEEE,2010:1678-1681.
[4]Campbell J P,Shen W,Campbell W M,et al.Forensic speaker recognition [J].IEEE Signal Processing Magazine,2009,26(2):95-103.
[5]张利鹏,曹犟,徐明星,等.防止假冒者闯入说话人识别系统[J].清华大学学报:自然科学版,2008,48(增刊):699-703.Zhang Li-peng,Cao Jiang,Xu Ming-xing,et al.Prevention of impostors entering speaker recognition systems[J].Journal of Tsinghua University:Science and Technology,2008,48(S1):699-703.
[6]Pohlmann K C.Principles of digital audio[M].6th ed.New York:McGraw-Hill,2010.
[7]赵力.语音信号处理[M].2版.北京:机械工业出版社,2009.
[8]Hermansky H,Morgan N.RASTA processing of speech[J].IEEE Transactions on Speech and Audio Processing,1994,2(4):578-589.
[9]Hanson B A,Applebaum T H.Subband or cepstral domain filtering for recognition of Lombard and channel-distorted speech[C]∥Proceedings of Acoustics,Speech and Signal Processing.Minneapolis:IEEE,1993:79-82.
[10]Lin Chi-Yueh,Wang Hsiao-Chuan.Language identification using pitch contour information[C]∥Proceedings of Acoustics,Speech and Signal Processing.Philadelphia:IEEE,2005:601-604.
[11]You Chang Huai,Lee Kong Aik,Li Haizhou.GMM-SVM kernel with a Bhattacharyya based distance for speaker recognition [J].IEEE Transactions on Audio,Speech,and Language Processing,2010,18(6):1300-1312.
[12]Tasşdemir K,Milenov P,Tapsall B.Topology based hierarchical clustering of self-organizing maps[J].IEEE Transactions on Neural Networks,2011,22(3):474-485.
[13]Hesterman J Y,Caucci L,Kupinski M A,et al.Maximum-likelihood estimation with a contracting grid search algorithm[J].IEEE Transactions on Nuclear Science,2010,57(3):1077-1084.
猜你喜欢
阅读(快乐英语中年级)(2021年10期)2021-03-08 14:23:24
阅读(快乐英语中年级)(2020年10期)2020-12-09 05:42:47
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
阅读(快乐英语中年级)(2017年3期)2017-05-30 10:48:04
阅读(快乐英语中年级)(2017年5期)2017-05-30 10:48:04
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
