
一种改进的汉字骨架提取算法
2011-07-25 00:33侯立斐霍玲玲
网络安全与数据管理 2011年17期
侯立斐,张 静,霍玲玲
(辽宁师范大学 计算机与信息技术学院,辽宁 大连 116081)
骨架是一种重要的图像目标几何特征,利用骨架表示原始图像,可以在保持图像重要拓扑特征的前提下,减少图像中的冗余信息。因此,骨架被广泛应用于图像目标的形状分析、信息压缩、特征提取、模式识别等领域。
自1967年Blum等[1]首先采用中轴表示连续平面上的图形以来,人们已经相继提出了许多图像骨架提取算法。吕岳等[2]提出了一种使用并行细化算法,该细化算法提取出的图像骨架避免了过度腐蚀,虽然具有良好的连通性,但此方法获得的骨架宽度往往大于一个像素。张若文等[3]提出了一种快速简便的图像骨架变换方法,该算法利用起飞、着陆法对图像进行距离变换,利用局部方向最大值搜索法进行骨架提取,此方法既可操作于二维图像,也可操作于三维图像,但对于不同的图像可能会得到相同的骨架结构。杨义军等[4]提出了复杂带状图像的快速三角剖分与骨架化算法,但该算法不适合提取宽度变化不规则图像的骨架。
本文基于李小军[5]提出的TrueType字体中心骨架线提取算法研究,提出一种新的基于内切圆的中心骨架线提取算法。该算法首先获取字体的边缘,将字体的边缘像素点按顺时针方向存储于数组I_edge中,以任意一点为起点按特定步长取点,迭代计算每个步长范围内的内切圆,最后将各内切圆的圆心连接起来得到汉字的骨架。该算法不仅适用于TrueType字体,对其他的字体(如隶书、楷体、宋体、黑体等)同样适用,而且提取的骨架具有良好的连通性和对称性。
1 边缘提取和边缘点的选取
欲提取书法汉字的骨架,首先需要检测书法汉字的边缘,提取边缘信息,然后迭代计算每个步长范围内的内切圆。
1.1 边缘提取
边缘是在已有的书法汉字图像中提取出来的。本文中用到的字体是Windows系统字体中的华文隶书、黑体、华文楷体和华文新魏等,如图1所示。

图1 Windows输入的字体
有了字体图像,首先标记出图像中的前景点、背景点和边界。为了提取出汉字的边缘,需先对汉字进行边缘检测。现有的边缘检测方法很多,如Roberts算子、Sobel算子、Laplacian算子、Canny算子、Prewitt算子等。本文的目的是为了得到汉字的边界,待处理的字体图像为灰度图像,所以本文采用Canny算子[6]进行边缘检测,具体步骤如下:
(1)用高斯滤波器对汉字图像进行平滑处理;
(2)用一阶偏导的有限差分计算梯度的幅值和方向;
(3)保留局部梯度最大的点,抑制非极大值,确定边缘;
(4)用双阈值算法检测和连接边缘。
得到汉字的边缘检测结果如图2所示,将所得的汉字边缘存入数组I_edge中。

图2 对原始字体进行边缘检测的结果
1.2 边缘点的选取
采用本文的算法提取汉字的骨架,提取出汉字的边缘。首先按特定步长选取边缘点,在存放边缘的数组I_edge中,从任意一点开始,以n个点为一个步长取点(n为整数,n取的越小,所得的骨架越接近汉字的真实骨架,本文取n=10),在曲率变化比较大的点处断开,保留该点,然后从这一点开始继续以10个点为一个步长取点,直到取完所有的点。
2 内切圆的计算
图3所示为与直线AB相切的内切圆,假设从A点开始选取点,下一个满足条件的点为B,曲线AB可以近似用直线AB表示,过直线AB做半径为R0的圆与直线AB相切于直线AB的中点M,圆的圆心C在过直线AB的中点M的垂直线上,改变圆半径R0的大小 (圆始终与直线AB相切于M点并且圆心在过M点的垂线上)并计算其他边缘点到圆心C的距离,直到找到边缘点到圆心C的距离无限接近R0的点,此时圆即为所求的此步长范围内的内切圆。保存圆心C和半径R0,继续计算下一个步长范围内的内切圆,依次找到所有步长范围内的内切圆后,所有内切圆的圆心所连成的直线即为汉字的骨架。
汉字骨架提取的主要实现步骤为:

图3 与直线AB相切的内切圆
(1)提取汉字的边缘,并将边缘点保存到数组I_edge中;
(2)在数组I_edge中,从任意一点开始以 10个点为一个步长取点;
(3)取前两个点 A和 B,连接 A、B两点,在直线 AB上取中点M;
(4)求过直线AB中点M点的法线;
(5)做内切圆,圆心在法线上并与直线AB相切于点M;
(6)使内切圆的半径为最小半径 R0(设 R0=0.5);
(7)增大圆半径R0(R0=2R0),计算出圆半径为 R0时的圆心C;
(8)计算书法汉字边缘所有的点到圆心C的距离,如果距离小于圆半径R0,则保存该点到一个列表内;
(9)如果计算完所有的边缘点后列表为空,返回步骤(7)重新执行;
(10)如果列表不空,则令 R0=R0/2;
(11)微调R0(R0=R0+△r)的大小并计算圆半径为 R0时的圆心C,计算列表内所保存的每个点到圆心C的距离。重复步骤(11)反复调整圆半径R0,直到找到边缘点到圆心的距离无限接近圆半径R0。此时圆即为所求的其所在步长范围内的内切圆。
(12)保存所求的圆心和半径,返回步骤(3)重新计算下一个步长范围内的内切圆和半径。
按照以上算法迭代计算完一个汉字的所有边缘的内切圆后,将所有内切圆的圆心依次连接起来即得到汉字的骨架。
3 汉字模糊区域骨架点计算
所谓汉字的模糊区域是指汉字笔划交叉或相连的地方。在模糊区域处用内切圆的方法提取骨架会出现局部骨架偏离原始骨架的情况。图4所示笔划交叉的区域用基于内切圆的方法可能会产生一些微小的偏离中心的骨架,所以模糊区域需要特殊处理。标记曲率变化大的四个点 A、B、C、D,图 5(a)所示为过任意三点做与这三个点相切的内切圆,使这个内切圆的圆心到另一个点的距离与其他三点到圆心的距离的差值最小,标记所找到内切圆的圆心。标记曲率变化大的两个点E、F,然后过这两个点做与这两点相切的内切圆,如图5(b)所示。逐渐改变内切圆的半径,找到第三个点到圆心的距离无限接近以上两点到圆心的距离,标记此时圆心的位置。找到圆心之后,将此圆心与分支区域的圆心相连便得到了书法汉字的骨架。
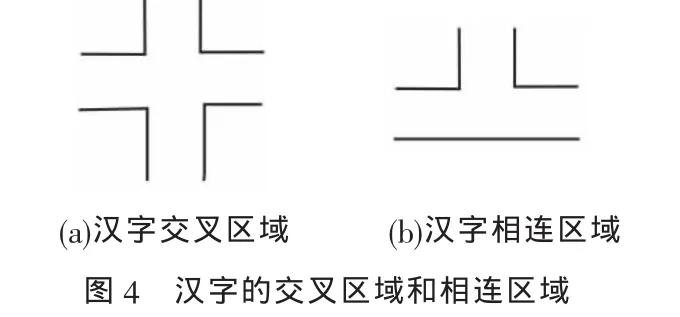
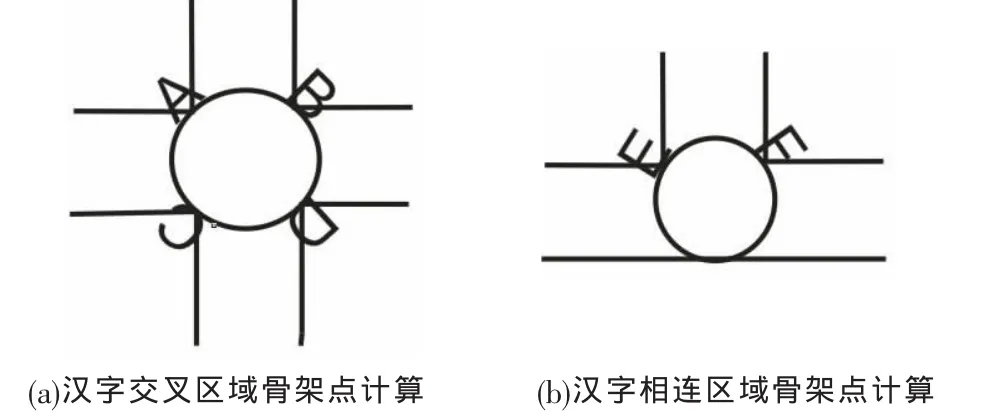
图5 汉字交叉区域和相连区域骨架点计算
4 实验结果分析及讨论
采用本文方法计算的汉字骨架提取的结果。如果不考虑模糊区域,对所有的边缘按特定步长计算内切圆得到的骨架(以王和女为例)如图6所示。
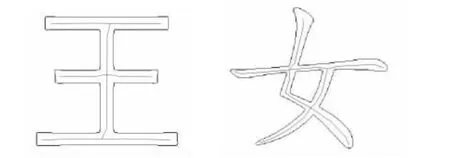
图6 基于内切圆方法得到的字体骨架
由于在字体的模糊区域,边缘点不能总是按特定步长选取。于是在曲率变化较大的点处断开,所以计算得出的模糊区域的骨架不能保证对称性,经过对模糊区域进行特殊处理之后,所得到以上Windows字体的骨架如图7所示。

图7 模糊区域经特殊处理之后所得的骨架提取结果
从图7可以得出,使用基于内切圆的方法以及对汉字模糊区域进行特殊处理之后,所得到的汉字骨架能基本保持与原字体结构一致,并且在汉字的模糊区域能够保持平滑与连通。
本文的算法源于参考文献 [6],但该方法仅适用于TrueType字体。由于TrueType字体是一种矢量字体,由一系列直线、二次贝塞尔曲线和三次贝塞尔曲线组成,具有无级缩放而不失真的优点,所以曲线段上的坐标点可通过求解一定的参数方程获取。而本文的算法不仅适用于TrueType字体,而且也适用于其他字体,如隶书、楷体、宋体、黑体等,并且在笔划交叉区域计算所得的骨架也最终得到了满意的效果。
本文以TrueType字体中心骨架线提取算法研究为基础,由于其局限性提出了一种适合于多种字体的一种基于内切圆的骨架提取算法。常规的基于像素剥离的细化算法虽然能快速获取骨架,但获取的骨架不携带原始书法汉字的线宽信息,且拐角信息容易丢失。而本文的算法简单灵活、易于实现,并且计算所得的骨架不仅携带汉字的原始线宽信息,而且骨架具有良好的对称性和连通性。
[1]BLUM H.A transformation for extracting new description of shape[A].Model for the Perception of Speech and Visual[C].Cambride, Massachusetts: MIT Press, 1967.362-380.
[2]吕岳,施鹏飞.一种使用并行细化算法及其实现[J].计算机工程与设计,2000(4):53-56.
[3]张若文,滕奇志,孙晓刚,等.一种快速简便的图像骨架变换方法[J].信息与电子工程,2003(1):1-5.
[4]杨义军,孟祥旭,等.复杂带状图像的快速三角剖分与骨架化算法 [J].计算机辅助设计与图形学学报,2003(10):1270-1274.
[5]李小军,方江龙,蒋知峰.TrueType字体中心骨架线提取算法研究[J].机械制造,2010,48(1):19-21.
[6]陈宏希.基于边缘保持平滑滤波的canny算子边缘检测[J].兰州交通大学学报,2006,25(1):86-90.
猜你喜欢
中等数学(2021年2期)2021-07-22
中等数学(2020年9期)2020-11-26
娃娃乐园·综合智能(2020年2期)2020-03-12
中等数学(2018年7期)2018-11-10
中等数学(2018年1期)2018-08-01
中学数学杂志(高中版)(2018年1期)2018-01-27
小雪花·成长指南(2014年10期)2014-10-31
数学教学通讯·初中版(2014年1期)2014-02-14
数学大世界·初中生辅导版(2010年2期)2010-03-08
移动一族(2009年3期)2009-05-12
