
基于STRAIGHT谱的非特定人数字语音识别
2011-07-18 11:44:13姚建霄张歆奕
五邑大学学报(自然科学版) 2011年1期
姚建霄,张歆奕
(五邑大学 信息工程学院,广东 江门 529020)
基于STRAIGHT谱的非特定人数字语音识别
姚建霄,张歆奕
(五邑大学 信息工程学院,广东 江门 529020)
介绍了STRAIGHT算法的原理,并选择STRAIGTH谱作为语音识别的特征参数. 采用对应点映射方法以提高同一发音不同样本参数间的匹配效果,在特征匹配的方法上选择差别子空间法,将二者结合应用于非特定人汉语数字0~9的语音识别,实验结果表明,基于STRAIGHT谱的非特定人数字语音识别可以达到97%的识别率.
语音识别;STRAIGHT谱;差别子空间;对应点映射
语音识别研究如何采用数字信号处理技术自动提取以及确定语音信号中的信息,时域分析和频域分析是分析语音信号的2种重要方法,但都有局限:时域分析对语音信号的频谱特性没有直观的了解,而频域特性中没有语音信号随时间变化的表现. 语谱图分析综合了频谱图和波形图的优点,集中显示了大量的与语音特性有关的信息,能直观地分析语音信号幅度、频率与时间的关系,一直以来人们都注意用语谱图来描述语音信号,并将其应用于语音识别和说话人识别[1]. 日本学者Hideki Kawahara等[2-4]提出的STRAIGHT算法(Speech Transformation and Representation by Adaptive Interpolation of weiGHTed spectrogram)将语音信号分解成独立的激励源参数和滤波器参数,并将其中的滤波器参数以谱图的形式表示. 由于STRAIGHT谱保留了语音要表达的语义内容,并在很大程度上抑制了其中与说话人相关的个性信息,因而可以很好地满足语音识别特征选取的要求. 本文尝试将STRAIGHT算法应用于非特定人汉语“0~9”的语音识别.
1 STRAIGHT算法的原理
STRAIGHT算法以Dudely的VODER理论为基础,用源—滤波器的思想表征语音信号,并将语音分解为相互独立的频谱参数(STRAIGHT谱)和一系列脉冲的卷积. STRAIGHT算法最早应用于语音合成领域,整个算法分为3部分:抑制周期性影响的谱估计,可靠的基频检测,有效的语音合成控制. 下面介绍抑制周期性干扰的方法.
1.1 基音同步分析
语音信号短时平稳性和动态通带带宽所造成的频谱失真会引起基音频率F0的估计误差,常引入边界连续性好的时窗以减少失真,这里通过高斯加权的方法来实现.

以式(1)Bartlett窗为例,对其进行高斯加权,得到ωP(t)作为原始窗,并用来计算语谱图P0(ω,t).式(2)中,η为增加频谱分辨率的一个临时系数,*代表与基音同步的卷积;ωP(t)的补偿窗ωC(t)=ωP(t )sin(πt/T0),其中T0为原窗函数的周期,由ωC(t )计算得到的语谱图记为PC(ω,t). P0(ω,t)和PC(ω,t)有大致相同的谐波结构,二者的合成频谱,其中ε为混合参数.对ε的选定标准是确保PR(ω,t)的时域波动最小,一般情况下取ε=0.13655.
1.2 自适应平滑内插
用二维B样条卷积法生成的线性谱对基音频率F0的估计误差不敏感. 原线性语谱图PR(ω,t)经滤波后的语谱PS(ω,t)形式如下:
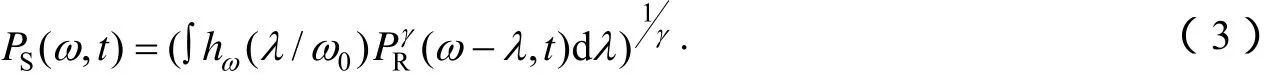
其中,ω0即F0,γ表示非线性程度,一般定为0.3,滤波核hω是一种三角映射关系,定义域为[-1,1].其STRAIGHT谱PST(ω,t)为:
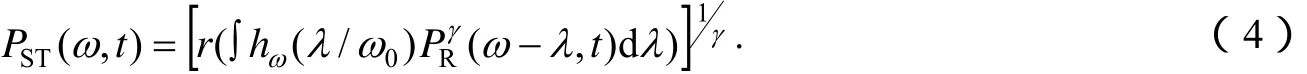
引入r(x)是为确保语音谱在各处均为正值,取r(x)=βlog(ex/β+1). 通过自适应平滑内插,频谱进一步被光滑化,消除了边缘不连续性.[3]
2 对应点映射方法
对应点映射方法用以提高同一发音不同样本间的匹配程度. Hideki Kawahara[3]用这种方法对STRAIGHT谱和对应激励参数进行操作,再将其合成出声音,以此改变一个发音的长度、语气、情绪等内容. 本文举例说明对应点映射方法的使用,图1为2个不同语气Hai发音的STRAIGHT谱图,我们将这2个发音标定锚点、融合后,得到同时包含二者信息的中性发音.
2.1 锚点标定
在图1上分别标定一些有意义的锚点,这些锚点将在样本间的映射过程中用于时域和频域上的对应. 选取锚点的规则:对所有样本来说,它应该是稳定的、有代表性的. 在频域上,锚点一般选在共振峰的位置. 在时域上,一般选取这些位置:1)发音的始末位置,以此保证融合时2个发音时间上的一致. 2)元音和辅音的过渡点,这是对应语音频谱变化的地方. 3)元音中点,这是发音中最稳定的部分. 对图1分别标定锚点得到图2.
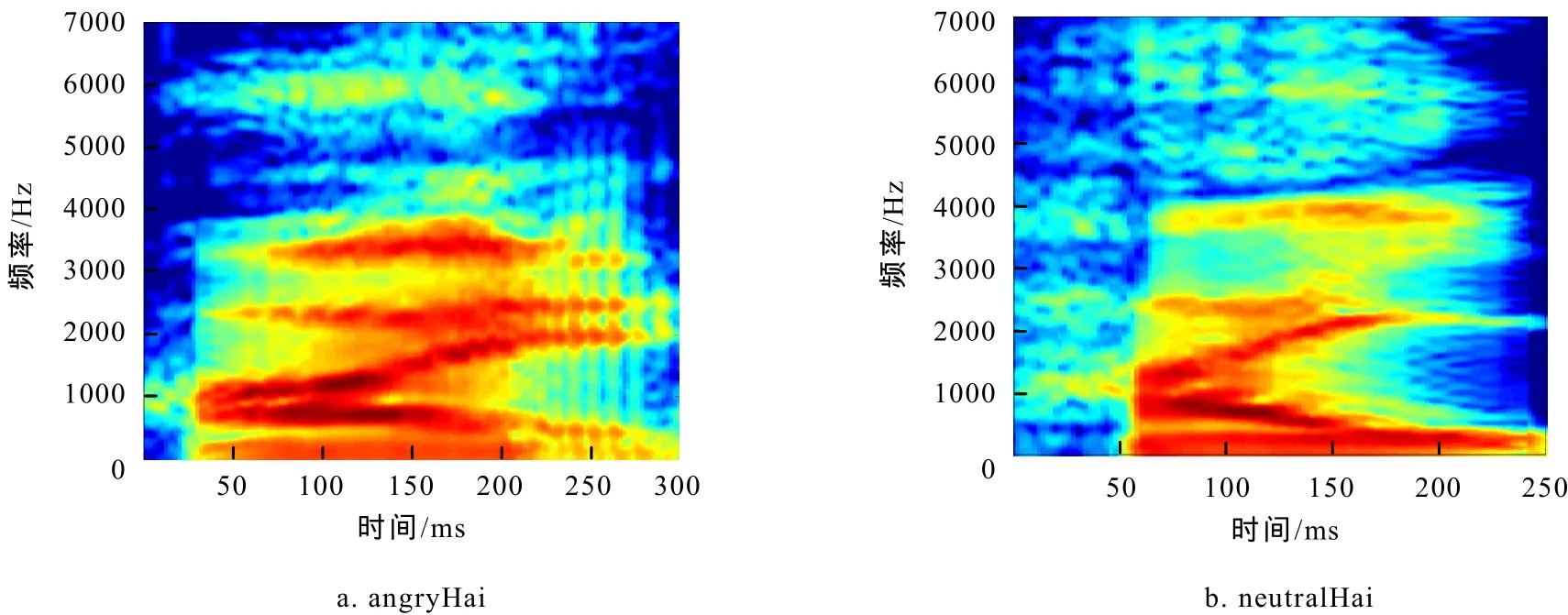
图1 angryHai和neutralHai的STRAIGHT谱图
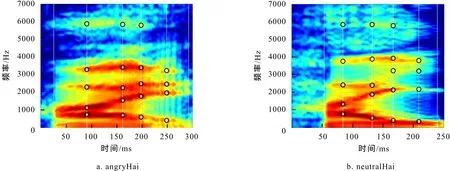
图2 标定锚点后的STRAIGHT谱
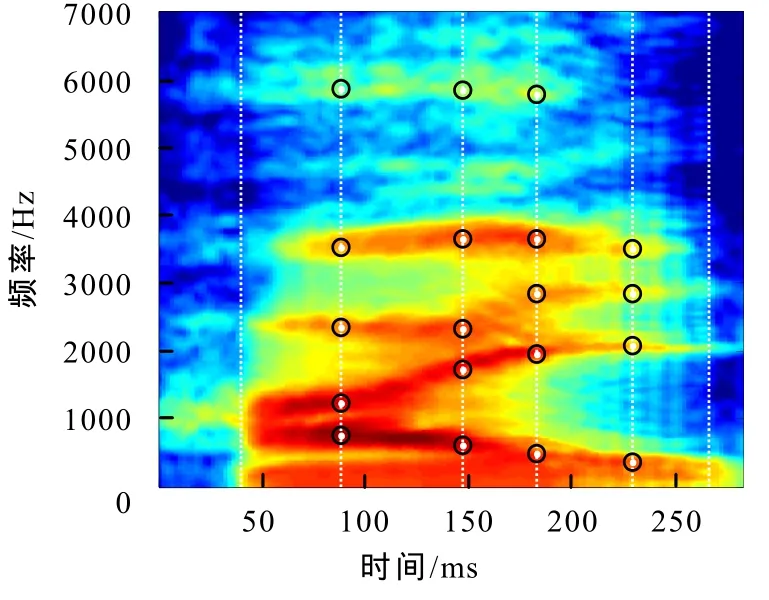
图3 对数插值方法得到的morphHai谱
2.2 融合
利用锚点信息从neutralHai和angryHai分别向融合morphHai进行映射,然后将二者映射的结果按比例叠加(该比例可自由确定,若希望生气的成分多一些,可以把angryHai的比例设为70%). 具体的映射是一个插值的过程,这里以neutralHai向morphHai进行映射为例. 先由二者锚点的时域坐标确定时域上的插值系数,各段内样点的插值系数再由段末端点处的锚点频域坐标确定,以此完成整个谱的映射. 图3为对数插值方法得到的morphHai谱. 在STRAIGHT算法中,为了得到效果更好的合成音,可以在更细的层次(如音素)上对源音进行校准.
3 基于STRAIGHT谱的语音识别实验
文献[5]提出了基于差别子空间的语音识别算法,并证明基于差别子空间的识别算法要优于基于动态时间归正技术(DTW)的识别算法.
3.1 语音识别实验
用非特定说话人汉语 “0~9”的发音进行测试. 实验方案:0~9每个数字录音25次(分别由3男2女,每人录5次),即为25个样本;25个样本中,15个用于训练(每人3个),另外10个用于识别;所有样本都标记相同维数的锚点.
图4是上述录音集中任意2个不同说话人数字9发音的STRAIGHT谱,比较发现:在锚点时域中间段、频域800~2 000 Hz,这两个谱有比较大的差别. 为了说明锚点信息的重要性,笔者对录制语音分2种情况进行训练:只利用锚点中的端点信息和利用全部锚点信息,每种情况下都先统计全部训练样本的锚点信息和谱矩阵大小,由此确定模板的对应信息. 用上述5个人共15个样本训练后,得到的模板谱如图5所示(图5-a使用全部锚点信息训练,图5-b只利用端点信息). 将时域70~220 ms、频域800~2 000 Hz的谱与图4的样本谱比较,可以发现:使用全部锚点信息得到的模板谱和实际样本谱更接近.

图4 数字9两个样本的STRAIGHT谱
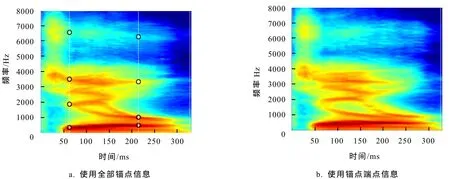
图5 数字9在不同锚点信息下的模板谱
3.2 实验结果
经过对锚点的多次调整,得到结果:共100个测试样本,每个数字10次,训练时,只利用锚点端点信息的情况下,不用差别子空间法时错了20个(实验1),用差别子空间法错了12个(实验2);利用全部锚点信息,不用差别子空间法时错了4个(实验3),用差别子空间法错了3个(实验4). 具体结果如表1所示,该结果证明了对应点映射方法和差别子空间法的有效性.
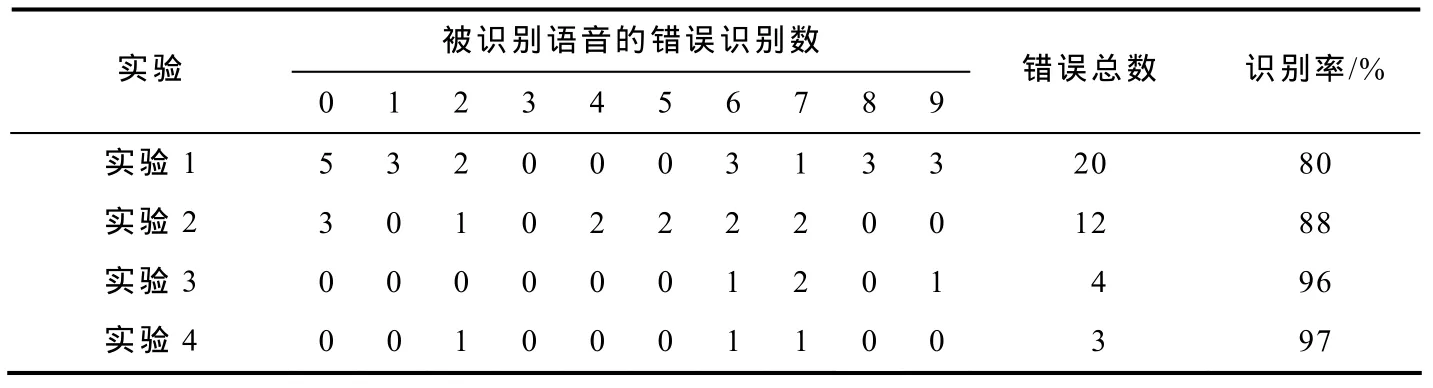
表1 不同实验方法时非特定人数字语音识别结果
4 结论
选取STRAIGHT谱作为特征参数,用对应点映射方法和差别子空间法进行非特定人数字识语音别可以达到较高的识别率. 锚点信息对识别很重要,选取合适的锚点位置,可以有效提高识别效率;因此,确定一套合理的规则用于选择锚点位置是需要迫切解决的问题. 从STRAIGHT谱特征出发,找到维数更低的特征来描述不同词、不同说话人之间的差别,是我们今后工作的重点.
[1] 阮伯尧. 脉冲耦合神经网络(PCNN)在基于语谱图的说话人识别中的应用[D]. 江门:五邑大学,2008.
[2] KAWAHARA HIDEKI, IKUYO Masuda-Katsuse, ALAIN de Cheveigne. Restructuring speech representations using a pitch adaptive time-frequency smoothing and an instantaneous-frequency-based F0 extraction: Possible role of a repetitive structure in sounds [J]. Speech Communication, 1999, 27: 187-207.
[3] KAWAHARA Hideki. STRAIGHT, exploitation of the other aspect of VOCODER: Perceptually isomorphic decomposition of speech sounds [J]. Acoust Sci & Tech, 2006, 27(6): 349-353.
[4] KAWAHARA Hideki. Speech representation and transformation using adaptive interpolation of weighted spectrum: vocoder revisited [C]// ICASSP-97. Munich: [s.n.], 1997, 2: 1303-1306.
[5] 张歆奕,吴今培,张其善. 一种基于差别子空间的语音识别算法研究和实现[J]. 五邑大学学报:自然科学版,2002, 16(1): 17-20.
Research on STRAIGHT Spectrum in Speech Recognition
YAO Jian-xiao, ZHANG Xin-yi
(School of Information Engineering, Wuyi University, Jiangmen 529020, China)
The principle of the STRAIGHT algorithm was introduced and the STRAGHT spectrum as feature index for speech recognition was chose. Corresponding point mapping was used to improve the effect of matching different sample parameters and the difference subspace was used for feature matching. These methods can be applied to digital identification of non-specific persons. The result shows that the STRAIGHT spectrum-based digital voice recognition can achieve a high recognition rate.
speech recognition; STRAIGHT spectrum; difference subspace; corresponding points mapping
TN912.34
A
1006-7302(2011)01-0056-05
2009-04-25
姚建霄(1980—),男,山西临猗人,硕士研究生,研究方向是语音识别;张歆奕,副教授,博士,硕士生导师,通信作者,主要从事信息与信号处理研究.
猜你喜欢
数理化解题研究(2022年5期)2022-03-12 09:49:58
初中生学习指导·中考版(2022年1期)2022-02-09 11:46:09
通信电源技术(2021年2期)2021-05-21 02:33:46
电子技术与软件工程(2020年22期)2021-01-30 05:29:42
数字技术与应用(2020年12期)2021-01-22 13:40:40
初中生学习指导·中考版(2020年2期)2020-09-10 07:22:44
移动通信(2020年5期)2020-06-08 15:39:51
雷达学报(2018年3期)2018-07-18 02:41:34
中学生数理化·七年级数学人教版(2016年8期)2016-12-07 07:21:54
火控雷达技术(2016年1期)2016-02-06 02:17:55
