
语言技术平台
2011-06-28 07:23:32车万翔李正华
中文信息学报 2011年6期
刘 挺,车万翔,李正华
(哈尔滨工业大学 社会计算与信息检索研究中心,黑龙江 哈尔滨 150001)
1 引言
中文信息处理的研究不仅需要基础数据平台(如北大语法词典、《知网》等)的支撑,而且需要基础技术平台的支撑。研制中文信息处理基础技术平台的意义包括以下几个方面。
(1) 支撑各类应用课题的研究
越来越多的研究者在研究其所在应用领域的课题时,迫切需要中文信息处理基础技术的支持,这些应用领域包括搜索引擎、Web挖掘、多媒体检索、电子商务、数字图书馆等。他们没有精力自行研发中文处理的基础技术,并且从学术分工的角度,也不应该由他们去研究这些技术。因此,如果能够研制一整套的中文处理基础技术平台,将有利地推动各应用课题的研究。同时,如果平台能够提供可视化功能,也会使上层应用者更直观地理解平台,如句法分析等深层自然语言处理技术,方便他们更好地将平台在实际系统中进行应用。
(2) 便于基础技术的协作研究
中文信息处理领域内,很多家单位,甚至一家研究单位内部的各个研究组都有自己的分词、词性标注技术,大多数这样的技术性能指标差距不大,但标准不一接口不一,各自为战无法相互借鉴,重复开发浪费人力物力。一些从事中文处理基础研究的单位在研制句法、语义分析技术,这些技术更是需要耗费大量的精力,如果能够较为清晰地定义各层处理技术之间的数据交换规范,则有利于同行们联合研究,使各项技术能够有效地积累。
(3) 便于多项基础技术的系统化研究
以往每家单位往往着重研究某一项基础技术,但语言处理的各项技术具有分层协同的特点。例如,分词的一个小错误可能导致句法分析的严重错误,而词性标注对分词结果又有一定的纠错功能,如果能够在一个统一的平台中涵盖各项基础技术,则有可能借助一些可视化工具更清楚地看到语言处理中各项技术之间的复杂关系,从而推进语言处理技术的系统化研究,还可以将技术指标最高的各单项技术集成起来,打造性能最优的语言处理系统。
本着以上目标,我们从2003年开始建设“语言技术平台LTP(Language Technology Platform)”,LTP是一套包括分词、词性标注、命名实体识别、依存句法分析、词义消歧和语义角色标注6项中文处理技术的基础技术平台。LTP使用XML作为底层数据表示,提供了丰富、高效的中文处理技术、丰富的应用程序接口、可视化工具和语料库资源,并能够以网络服务(Web Service)的形式进行使用。为了促进自然语言处理研究的发展,我们免费将LTP共享给学术界并开放了源代码。迄今为止,国内外很多研究机构基于LTP发表了学术成果。基于以上贡献,LTP获得了中国中文信息学会2010年颁发的“钱伟长中文信息处理科学技术奖”的一等奖。
2 相关研究工作
自然语言处理平台的开发一直是很多关注应用的研究人员的目标,国外已有一些著名的自然语言处理平台,典型的如: GATE、UIMA和NLTK。
GATE(General Architecture for Text Engineering)*http://gate.ac.uk/,是英国谢菲尔德大学自然语言处理组开发的自然语言处理平台,包含一个统一的基于Java的开源体系结构和图形化的开发环境[1]。GATE采用了基于组件的体系结构,语言处理、语料及可视化资源都被表示为组件,从而可以促进资源的重用。GATE提供了大量可重用的组件,被用来进行自然语言处理的相关教学和研究。另外,GATE提供了一组集成的图形化工具,帮助使用者建立、修改和调试各种资源。
UIMA(Unstructured Information Management Architecture)*http://www.research.ibm.com/UIMA/是一个用于开发、部署非结构化信息管理应用的软件架构[2]。它通过对文本、视频、音频、图片等非结构化信息的内容进行分析和组织,从而获取相关知识,产生结构化的、易于获取的数据,交付给终端用户使用。分析技术包括: 基于统计的、基于规则的自然语言处理技术,信息检索、机器学习、本体知识、自动推理等。UIMA和GATE类似,都采用了基于组件的设计模式,将语言处理核心算法和其他系统服务如数据存储、组件间通信、结果可视化等分离。UIMA强调对已有技术的利用、可扩展性、中间件和平台无关性。
NLTK(Natural Language Toolkit,自然语言处理工具包)*http://www.nltk.org/是一套用于自然语言处理的Python程序库[3]。NLTK包含图形化的演示和样本数据。它还包含一整套扩展文档,支持这套工具集在自然语言处理中相关概念的解释。NLTK被广泛应用于自然语言处理的教学和研究中。
以上各平台的一个共性问题是它们都强调系统的体系结构,但缺乏精准的语言分析技术,尤其是缺乏中文分析技术,这些系统多采用常规的自然语言分析方法,而没有使用学术界最新的研究成果。因此,有必要开发一套针对中文的高精度的自然语言处理平台。
3 语言技术平台
2006年4月,哈工大社会计算与信息检索研究中心推出了语言技术平台(Language Technology Platform, LTP)*http://ir.hit.edu.cn/ltp/。LTP是一个中文处理的集成平台,囊括了词法分析(包括分词、词性标注和命名实体识别)、句法分析(依存句法分析)、语义分析(词义消歧和语义角色标注)三方面六项语言处理基础技术。其系统框架如图1所示。最基础的是知识资源和数据资源,基于这些资源,我们构建了词法、 句法和语义分析技术,各项技术的数据表示和交换均基于我们自定义的XML数据格式,最终的分析结果通过应用程序接口(API)或者网络服务(Web Service)的方式向上层应用程序提供,或以可视化的方式直接呈现给用户,供其分析。下面我们展开介绍LTP的各个部分。

图1 语言技术平台系统框架
3.1 语言处理基础技术
LTP提供了6项中文处理技术,由底层到高层依次为: 词法分析(包括分词、词性标注和命名实体识别)、句法分析(依存句法分析)和语义分析(词义消歧和语义角色标注),这些技术均在国际评测中取得优异成绩。
对于中文信息处理的各单项技术,目前主流的都是基于统计的方法,所采用算法、训练数据以及所选择的特征对于一个基于统计的自然语言处理系统都起到至关重要的作用,其中任何一项的改进,都会推动某项技术的进步。因此对于LTP中的各项技术,我们都试图从算法、数据和特征等方面加以改进,在保证分析效率的前提下,有多项技术达到目前已知的最好水平。下面我们分别加以介绍。
1) 分词(Word Segmentation)
中文分词将一个汉字序列切分成词的序列,是中文信息处理最基础的技术之一。其中歧义(包括组合型歧义和交集型歧义)和未登录词是困扰分词系统的主要问题[4]。自Nianwen Xue首次提出将分词问题看作序列标注问题以来[5],各种基于统计的序列标注模型,如条件随机域(Conditional Random Field,CRF)[6]等,便被应用于中文分词,其不但能够很好的解决分词歧义问题,而且能够解决部分未登录词问题,因此该方法成为目前分词的主流方法。LTP也采用了基于CRF的分词方法。
然而,基于序列标注的分词方法依赖大规模标注的语料库,如果将其应用于特殊的领域,如金融等,则需要标注该领域的语料库,这将消耗较大的人力物力成本,不利于领域的移植。我们针对这个问题,提出了兼容外部词典的序列标注分词方法[7],即提供一个通用领域训练的序列标注模型,而当切换到一个新的领域时,仅需提供一个该领域的词典(相对较容易获得),就能够将该领域所特有的词识别出来。这种分词技术不但能够利用统计模型较强的处理歧义的能力,而且能够方便的利用外部词典,进一步提高了未登录词的识别能力,从而使得LTP具有较强的领域自适应性。
2) 词性标注(POS Tagging)
词性标注指对于句子中的每个词都指派一个合适的词性,如名词、动词、形容词等。词性标注是典型的序列标注问题,早期采用如隐马尔科夫模型[8]等生成模型(Generative Model)加以解决。然而,这类方法需要较强的独立假设,因此最终系统的准确率并不高。以最大熵马尔科夫模型(Maximum Entropy Markov Models,MEMM)[9]为代表的判别模型(Discriminative Model)可以利用更丰富的特征,而且不需要假设这些特征是独立的,很好的解决了生成模型所面临的问题,使得词性标注准确率有了大幅度的提升。在LTP中,我们使用准确率更高的支持向量机[10]作为基本的分类器,进一步提升了词性标注的准确率。与此同时,针对数据稀疏问题,特别是分词阶段识别的未登录词,我们首次引入了汉字特有的偏旁部首特征,进一步提高了词性标注泛化能力[11]。
3) 命名实体识别(NE,Named Entity Recognition)
命名实体是指文本中出现的专有名称和有意义的时间或数量短语,主要包括人名、地名、机构名、时间、数量等。NE识别的任务就是将这些名称和短语识别出来并加以归类。目前主要有两类方法: 基于规则的方法和基于统计的方法。对于规律性比较强的命名实体,规则的编写高效而准确,如时间表达式等。而基于统计的方法常被应用于规律性不强的命名实体识别,如地名、机构名等。通常基于统计的命名实体识别被看作是序列标注问题,常用的机器学习算法包括隐马尔可夫模型[12],最大熵马尔可夫模型[13],条件随机域[14]等。
LTP采用了统计和规则相结合的方法,统计模型采用MEMM,能够识别人名、地名、机构名、时间、日期、数量和专有名词7类实体。然而,该方法仍然依赖大规模的训练语料,人工标注成本较高。为此,我们提出了一种借助英文命名实体识别系统从双语平行语料中自动生成大规模中文命名实体识别训练语料的方法[15],扩展了系统的覆盖范围,提高了识别能力。
目前的命名实体,多限定为人名、地名、机构名等有限类别,这虽然在一定程度上满足了上层应用的需要,然而对于更多的应用,需要处理更开放的命名实体类别,如影视、文学作品,菜名等等。如何处理这类开放信息抽取(Open Information Extraction)问题,是自然语言处理学者需要进一步考虑的问题。
4) 词义消歧(Word Sense Disambiguation)
一词多义是自然语言固有的特征,也是语言应用中十分普遍的现象。汉语多义词(歧义词)在词典中只占总词语量的10%左右,大约8 000多个多义词。比例虽然很低,但是歧义词多为常用词,在语言应用中出现的频率很高。根据对大规模语料库的统计数据发现,汉语歧义词在语料中出现的频度达到42%左右。如何确定歧义词的词义是进行自然语言各高层处理的前提,可以说词义消歧是自然语言处理领域不可回避的问题。基于统计的词义消歧技术是当前词义消歧研究领域的主流方法,但该方法需要有词义标记的训练语料,而获得规模足够大的高质量标注语料,需要代价高昂的人力、物力,而且数据的一致性也很难保证。如果语料规模偏小,数据稀疏问题就会十分严重。所以目前学术界多是针对个别多义词,人工标注较多的样本进行词义消歧的实验。然而该方法很难应用于全部多义词的消歧。为了能够标注更大规模的语料库,我们提出了一种利用双验证码进行语料库标注的方法[16],该方法基于人本计算的思想,巧妙的利用互联网背后用户的知识,在其自然使用网络的状态下,自动的获取词义消歧语料库。词义消歧的另外一个问题就是小概率词义的训练数据难以获得,多义词的词义分布很多情况下非常不均衡,为了解决这个问题,我们提出了等价伪词的方法[17],解决了数据不均衡的问题。有了大规模词义消歧语料库,我们采用支持向量机作为分类器,基于多种特征,实现了词义消歧系统[18],并在2007年SemEval Task 11词义消歧评测任务中获得第一名。
另外,随着语言的发展,尤其是互联网的出现,有越来越多的词被赋予了新的含义,甚至出现新的词,如何将这些新词以及新的含义识别出来,是词义消歧所面临的新的挑战。
5) 依存句法分析(Dependency Parser)
依存句法分析将句子由一个线性序列转化为一棵结构化的依存分析树,通过依存弧上的关系标记反映句子中词汇之间的句法关系。与短语结构相比,依存结构具有形式简洁、易于标注、便于应用等优点,逐渐受到学术界和工业界的重视。目前主要有基于转移和基于图两种依存句法分析方法。其中基于图的方法由于进行的是全局最优解的查找,获得了更高的准确率,因此在LTP中,我们也采用了基于图的方法,并使用了高阶的特征,以获得更高的准确率。与通常的采用动态规划算法进行解码的句法分析器不同,我们采用了基于柱状搜索的解码算法[19],以及基于标点的两阶段句法分析方法[20],在不损失分析精度的情况下,较大的提高了句法分析的效率,使得句法分析能够满足一般的互联网信息处理应用对处理速度的需求。我们参加了CoNLL (Conference on Computational Natural Language Learning) 2009多语种(包括中文、英文在内的7种语言)依存句法分析和语义角色标注评测,在21家参赛单位中获得句法分析第3名*http://ufal.mff.cuni.cz/conll2009-st/results/results.php。
对于中文依存句法分析,目前最主要的问题是词性和句法角色不对应,也就是说相同的词性串会表示不同的句法结构,这给句法分析带来了很大的困难,尤其是中文的复合名词短语结构复杂多样,其内部词性无明显约束,因此可以首先识别复合名词短语然后再进行句法分析来降低句法分析的难度,提高其准确率。
6) 语义角色标注(Semantic Role Labeling)
语义角色标注是目前浅层语义分析的一种主要实现方式,其具有问题定义清晰,便于人工标注和评测等优点。该方法不对整个句子进行详细的语义分析,而只是标注自然语言短语为给定谓词的语义角色,如施事、受事、时间、地点等。通常,人们将语义角色标注问题看成是分类问题。也就是说,可以使用各种分类算法逐一判断一个语言单元(词、短语或句法成分)是否是语义角色,然后预测其属于何种具体的语义角色。对于分类器输出的结果,还需要根据语义角色标注的多种约束条件进行一些后处理操作,形成最终的语义角色标注结果。数据稀疏仍然是困扰语义角色标注的主要问题之一,如何充分利用泛化能力更强的特征,是目前亟待解决的问题。基于Kernel方法是解决这一问题的较好途径[21],例如,对于句法特征较为稀疏的问题,可以使用Convolution Tree Kernel,泛化路径、位置等特征。LTP中的语义角色标注采用最大熵分类器[22]识别谓词和语义角色,在解码阶段采用基于整数线性规划(ILP,Integer Linear Programming)的方法[19],该方法可以较为方便的融合多种语义角色标注所具有的约束信息,最终进一步提高了系统的精度。同样参加了CoNLL2009评测,最终获得了第1名。
然而,语义角色标注问题定义本身仍存在一些问题,其定义一个语义角色一般为一个句法成分,而成分内部词语之间的关系并没有明确定义。另外,语义角色不够丰富和统一。以标注规模最大的PropBank语料库为例,目前谓词仅限于动词或者动名词,与之相关的语义角色也被粗略的分为核心角色(Arg0~5)或者附属角色(时间、地点等)。而对于不同的谓词,相同的核心角色往往含义又不一致,虽然在其提供的词典中对每个谓词的角色进行了解释,但是这种解释比较随意,没有统一。以上问题制约了语义角色标注自动分析性能的提高和实际应用。因此我们有必要定义一种更深层、更精确的语义表示形式。
最后,我们在表1中给出了LTP中各项技术的具体性能指标。

表1 LTP各项技术性能指标
其中多项技术参加各种国内和国际评测,并获得优异成绩,特别是句法和语义分析工作,在CoNLL2009国际评测中获得总成绩第1名。优异的评测成绩说明LTP已达到国际领先水平。
3.2 数据表示
综合的语言技术平台,需要一套清晰的数据表示方法,以及基于这套表示方法的各种相关处理和应用。XML作为一种清晰的数据表示方式,已经被大家所接受,并且逐渐成为一种标准的数据表示方式。基于XML我们设计了一整套中文内部表示体系,从词处理到句子处理,到篇章处理,直至篇章集合的处理,都能够用这套XML表示方法进行表示。这套表示方法我们称之为语言技术置标语言LTML(Language Technology Markup Language)。

图2 LTML示例
图2展示了一个LTML的实例。LTML以词(word)为基本单元,每个词的属性包括cont(词内容)、pos(词性)、ne(命名实体)、wsd(词义)、parent(父节点),relate(依存关系类型)、arg(语义角色标注)等,词构成了句子(sent),句子又构成了段落(para)等等。
各种编程语言,都提供了丰富的XML操作库。LTML作为语言技术平台的底层数据表示,对各项技术之间进行信息传递、 信息融合以及最终结果的可视化都提供了诸多便利。
3.3 语料资源
目前的自然语言处理系统多采用基于统计的方法,除了统计算法外,还需要较大规模的料库资源作为系统的支撑。因此我们在提供丰富的分析工具的同时,还对外共享了我们自主标注的两种与LTP相关的语料库资源。详细情况如表2所示,这些语料库对于其他研究机构重新构建相应的自然语言处理系统有重要的意义。

表2 LTP语料资源
3.4 处理结果可视化
清晰的将处理结果可视化可以帮助研究人员方便的进行错误分析等各项工作。我们在LTML的基础上,开发了一套跨平台、跨浏览器的可视化工具。一篇文本经过LTP处理后,可以从不同角度、粒度去观察处理的结果,如图3和图4所示。图3显示的是命名实体识别的处理结果。我们使用不同的颜色标识不同的命名实体。图4显示的是句子级处理结果的可视化。其中第一行为分词信息;第二行为词性信息;第三行为词义信息;第四行为命名实体信息;第五行之后为语义角色标注结果,每一个谓词占一行。最上面的弧表示依存分析结果。
基于这种可视化的结果,上层用户可以更清晰的了解LTP能够实现哪些功能,这样便于用户理解自然语言处理系统的功能, 以便更合理的使用。另外,自然语言处理的研究人员也能通过直观的可视化结果,分析目前系统的问题到底出在哪儿。很多时候上层分析的错误并非其自身的问题,而是下层错误导致的,通过LTP的可视化结果能够方便的找到问题的根源,从而促进研究工作的发展。
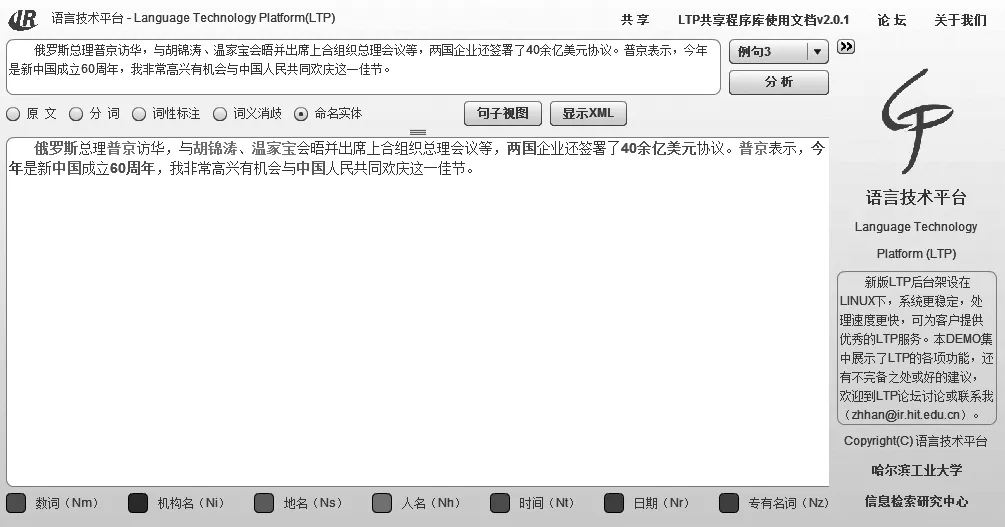
图3 LTP命名实体识别可视化

图4 LTP句子级处理结果可视化
3.5 网络服务(Web Service)
现在的互联网上处于一个提供“内容”和“服务”的时代,大量出现的网络服务使我们可以非常方便的利用别人的成功构建自己的应用。
因此LTP提供了Web Service,对用户而言,LTP Web Service有四方面好处: 1)无需安装调试LTP。目前用户首先需要下载LTP程序库和数据,然后在本地配置好数据路径及各单项技术所需的参数。整个过程比较复杂,并且平台移植性不好;2)不需要负担额外的LTP运行需要的硬件资源;3)更新及时。只要服务器端做相应的更新,客户端不需要额外的操作,即可使用最新的分析技术,得到更好的分析结果;4)跨平台、跨编程语言。用户可以在各种操作系统上,使用不同的编程语言,访问LTP Web Service。
自2010年9月正式对外服务以来,共有约500位用户申请注册了LTP网络服务账号,查询数达350多万次,平均每天的查询次数近1万次。
4 语言技术平台升级及共享情况
我们一直在不断的改进和完善语言技术平台,包括提高各个语言处理技术的性能,优化整个系统架构,完善可视化程序。截止2009年9月,LTP已经升级至3.0版本。
为了进一步促进中文信息处理的研究,尽可能为大家提供一个方便直接进入高层研究的语言处理平台,我们于2006年9月开始对学术界免费共享整套LTP*http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm。截止2011年8月,LTP的共享单位达到400多家,包括国内外众多大学及科研机构,如美国卡耐基梅隆大学、美国伊力诺依大学香槟分校(UIUC)、日本信息通信研究机构(NICT)、新加坡国立大学、北京大学、清华大学、中科院、香港科技大学等。
很多单位已经在LTP的基础上进行研究并且发表论文,据不完全统计,目前基于LTP发表的论文超过100篇。另外,我们于2011年6月正式将LTP开源,至今已有500余位用户正式注册并下载了LTP的源代码。图5和图6分别显示了国际和国内LTP的使用者分布图。
同时,LTP也已授权百度、华为、金山、讯飞等企业付费使用,产生了一定的经济效益。

图5 国际上LTP使用者分布图

图6 中国大陆LTP使用者分布
5 结论与展望
语言技术平台,简称LTP,是哈尔滨工业大学社会计算与信息检索研究中心历时8年多时间研制的一整套自然语言处理平台。LTP集分词、词性标注、命名实体识别、词义消歧、依存句法分析和语义角色标注等6项自然语言处理任务于一体。我们免费向学术界共享LTP,很多研究单位已经在LTP基础上做出了卓有成效的科研成果。LTP以其技术的领先性,内容的全面性,使用的便捷性,结果的易读性以及成果的开放性等优势,得到了用户的肯定。
未来我研究中心在中文基础技术方面将对以下问题进行重点研究。
(1) 各项语言分析技术的互动反馈机制
语言各个层面之间的关系是错综复杂的。但一般来说,高层的技术要建立在底层技术的基础上,同时又可以指导底层技术。目前为止,LTP只是一个分层的语言处理过程,各层之间没有任何反馈或者信息传递。下一步我们将在LTP上尝试各种互动反馈机制,如一体化[25-26]、重排序等策略*我们曾经尝试按照多层结果分数总和进行排序,然而由于各层的分数并没有可比性,这种方法取得的效果有限[27],从而提高整个语言处理系统的性能。
(2) 句法语义相互结合的语义依存分析
语义分析默认要建立在句法分析的基础上,中文的句法是从西方引进来的,而中文严重缺乏形态的变化,词类与句法成分没有严格的对应关系,导致中文句法分析的精度始终上不去。目前英文在标准测试集的句法分析准确率达到90%,而中文只能达到80%,距离实用还有很远的距离。中文是意合的,在形式分析上有劣势,是否可以跨越句法分析阶段直接分析语义,这一直是我们感兴趣的问题。近两年来,我们在研究“语义依存分析(Semantic Dependency Parsing,SDP)”,SDP超越了依存句法分析和语义角色标注,能够分析出一棵完整的语义依存树,属于一种深层的语义分析,目前我们已经联合北京城市学院标注了1万句中文语义依存分析树[28],将组织相应的国际评测,且已经有初步的实验结果,欢迎对此感兴趣的学者一起交流探讨。
(3) 向各个领域移植
目前的中文基础技术不少是以新闻语料为训练测试语料的,句法分析在这个领域可以接近80%的准确率,但一旦切换到其他领域,准确率可以锐减至60%~70%,甚至更低。如何能够以最低的成本向各领域移植是未来工作的重点之一。
(4) 群体智慧的运用
中文语言处理的基础技术发展到今天遇到了瓶颈,特别是知识获取的瓶颈。由于Web 2.0时代每个用户成为可以参与计算的节点,为利用群体智慧获取语言学知识创造了条件。如何巧妙地设计“傻瓜化”的大众能够参与的带有趣味的语言标注系统是获取群体智能的关键,而这样的系统一旦设计出来就能够以很小的成本在很短的时间内获取大量的知识。
今年是中国中文信息学会成立30周年,衷心祝愿我国中文信息领域繁荣昌盛,我们愿意虚心地向前辈学习,与广大的同仁多交流协作,为中文信息处理的发展做出新的贡献。
[1] Hamish Cunningham, Diana Maynard, Kalina Bontcheva, et al. GATE: an Architecture for Development of Robust NLT Applications [C]//Proceedings of ACL, 2002: 168-175.
[2] David Ferrucci, Adam Lally. Building an Example Application with the Unstructured Information Management Architecture[J]. IBM Systems Journal, 2004, 43(3): 455-475.
[3] Steven Bird, Edward Loper. NLTK: The Natural Language Toolkit [C]//Proceedings of the ACL demonstration session 2004: 214-217.
[4] 刘挺, 王开铸. 关于歧义字段切分的思考与实验[J]. 中文信息学报, 1998, 12(2): 63-64.
[5] Nianwen Xue. Chinese Word Segmentation as Character Tagging[J]. International Journal of Computational Linguistics and Chinese Language Processing, 2003,8(1): 29-48.
[6] John Lafferty, Andrew McCallum, Fernando Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data [C]//Proceedings of ICML 2001: 282-289.
[7] 张梅山, 邓知龙, 车万翔, 等. 统计与词典相结合的领域自适应中文分词[C]//第十一届全国计算语言学学术会议, 2011.8.
[8] Chris Manning, Hinrich Schütze. Foundations of Statistical Natural Language Processing[M]. MIT Press. Cambridge, MA: May, 1999.
[9] Andrew McCallum, Dayne Freitag, Fernando Pereira. Maximum Entropy Markov Models for Information Extraction and Segmentation[C]//Proceedings of ICML-2000.
[10] Vladimir Vapnik. The Nature of Statistical Learning Theory[M]. Springer-Verlag, 1995.
[11] 王丽杰, 车万翔, 刘挺. 基于SVMTool的中文词性标注 [J]. 中文信息学报, 2009, 23(4): 16-21.
[12] Guodong Zhou, Jian Su. 2002. Named entity recognition using an HMM-based chunk tagger[C]//Proceedings of the 40th Annual Meeting of the Association of Comparative Linguistics (ACL): 473-480.
[13] Hai Leong Chieu, Hwee Tou Ng. 2002. Named Entity Recognition: A Maximum Entropy Approach Using Global Information[C]//Proceedings of the 19th International Conference on Computational Linguistics (COLING): 190-196.
[14] Burr Settles. 2004. Biomedical Named Entity Recognition Using Conditional Random Fields and Rich Feature Sets[C]//Proceedings of COLING 2004, the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA), Geneva, Switzerland.
[15] Ruiji Fu, Bing Qin, Ting Liu. Generating Chinese Named Entity Data from a Parallel Corpus[C]//Proceedings of the 5th International Joint Conference on Natural Language Processing (IJCNLP 2011).
[16] Wanxiang Che, Ting Liu. Word Sense Disambiguation Corpora Acquisition via Confirmation Code[C]//IJCNLP. 2011.
[17] Zhimao Lu, Haifeng Wang, Jianmin Yao, et al. An Equivalent Pseudoword Solution to Chinese Word Sense Disambiguation[C]//ACL, 2006.
[18] Yuhang Guo, Wanxiang Che, Yuxuan Hu, et al. HIT-IR-WSD: A WSD System for English Lexical Sample Task [C]//SemEval 2007.
[19] Wanxiang Che, Zhenghua Li, Yongqiang Li, et al. Multilingual Dependency-based Syntactic and Semantic Parsing [C]//Proceedings of CoNLL 2009: 49-54.
[20] Zhenghua Li, Wanxiang Che, Ting Liu. Improving Dependency Parsing Using Punctuation[C]//Proceedings of the International Conference on Asian Language Processing of IALP 2010. Harbin, China.
[21] Wanxiang Che, Min Zhang, Ai Ti Aw, et al. Using a Hybrid Convolution Tree Kernel for Semantic Role Labeling[C]//ACM Transactions on Asian Language Information Processing. 2008, 7(4).
[22] Adam L. Berger, Stephen A. Della Pietra, Vincent J, et al. A Maximum Entropy Approach to Natural Language [J]. CL 1996, 22(1): 39-71.
[23] 梅家驹, 竺一鸣, 高蕴琦, 等. 同义词词林 [M]. 上海. 上海辞书出版社. 1983.
[24] Ting Liu, Jinshan Ma, Sheng Li. Building a Dependency Treebank for Improving Chinese Parser [J]. Journal of Chinese Information Processing. 2006, 16(4): 207-224.
[25] Zhenghua Li, Min Zhang, Wanxiang Che, et al. Joint Models for Chinese POS Tagging and Dependency Parsing[C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Edinburgh, Scotland, UK.2011,08:1180-1191.
[26] Wanxiang Che, Ting Liu. Jointly Modeling WSD and SRL with Markov Logic[C]//Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010). Beijing, China.2010,08: 161-169.
[27] Wanxiang Che, Ting Liu, Sheng Li. A New Chinese Natural Language Understanding Architecture Based on Multilayer Search Mechanism[C]//Third SIGHAN Workshop on Chinese Language Processing, 2004, 7.
[28] 邵艳秋,邱立坤, 梁春霞, 等.中文语义依存关系资源建设及分析技术研究[C]//第十一届全国计算语言学学术会议. 洛阳, 2011, 8.
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
西夏研究(2020年1期)2020-04-01 11:54:26
智富时代(2019年6期)2019-07-24 10:33:16
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
电脑与电信(2018年12期)2018-03-23 02:37:20
高中生·天天向上(2016年9期)2016-11-22 09:10:34
语言与翻译(2014年3期)2014-07-12 10:31:59
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
中文信息学报(2012年4期)2012-06-29 06:29:14
