
缓存技术在甘肃用电信息采集系统中的应用
2011-06-27 02:14甘肃电力信息通信中心李红文王蛟
电气技术与经济 2011年1期
■ 甘肃电力信息通信中心 李红文 王蛟
甘肃电力调度通信中心 庞伟
0 引言
随着电力体制市场化改革进程的不断推进,国家电网公司提出了建设“一强三优”现代公司的战略目标。根据《国家电网公司“十一五”电力营销发展规划》总体目标,为了加快营销计量、抄表、收费标准化建设和公司信息化建设,进一步提升公司集约化、精益化和标准化管理水平,必须全面建设电力用户用电信息采集系统(以下简称“用电信息采集系统”)。
用电信息实时采集系统和管理分析系统作为营销业务应用系统的重要组成部分,是实现客户现场信息采集、负荷监测、电力市场的分析预测的技术支持系统,为需求侧管理提供支持与分析服务,具有基础性和先导性的作用。但是如何建立规范统一的用电信息采集系统及主站、采集终端、通信单元的功能配置、型式结构、性能指标、通信协议、安全认证、检验方法一直是各个供电企业所关注的难题。
甘肃电力公司按照坚强智能电网建设的总体要求,为保证智能电网建设规范有序的推进,实现电力用户用电信息采集系统建设“全覆盖、全采集、全预付费”的总体目标,提出了建立具有全面规范系统功能、统一通讯规约,并能覆盖各级供电局集电能量信息采集、监控、负荷控制、电能量信息分析于一体的电力用户用电信息采集系统。
一个网省用电信息采集系统覆盖各级电力公司的用电信息数据采集,需要处理的数据量远远大于以前以地市和区县为单位的采集系统,因此采集系统各模块跟核心数据库的交互将更为频繁,因此将需要跟程序交互最为频繁的数据放在缓存中做处理,不仅方便了程序的开发,而且提高了效率。
1 系统结构简介
1.1 现场终端
现场终端部分可称为采集设备层是用电信息采集系统的信息底层,负责收集和提供整个系统的原始用电信息,如图1所示,该层有多重形式,是对应不同的需要,但是都可分为两个模块,计量模块和通信模块,计量模块是各种形式的电能表,功能是电能、电压、电流等计量,通信模块负责与上层主站和计量模块的通信。
1.2 通信信道层
通信信道层是主站和采集设备的纽带,提供了各种可用的有线和无线的通信信道,为主站和终端的信息交互提供链路基础。主要采用的通信信道有:GPRS/CDMA无线公网、光纤专网、230MHz无线专网。
1.3 前置机层
前置采集平台是实现该系统的关键。它不但能够通过多种通道同终端进行交互,还能够编码和解析多种通讯规约的报文,充当桥梁和翻译的重要工作。另外前置机还包括定时任务自动采集和采集数据入库功能,负责历史数据的采集入库。前置机部分也是应用缓存最多的部分。
1.4 应用层
应用层系统采用B/S(浏览器/服务器)体系架构,主要完成和用电信息采集业务相关的应用,包括数据采集、上层综合应用。提供统一的业务应用操作界面和信息展示窗口,是系统直接面向操作用户的部分。主要包含以下几方面的功能:自动抄表、预付费管理、负荷管理、用电监测、终端管理、运行管理。
1.5 接口层
接口层是用电信息采集系统与相关的系统进行数据的互联互通,实现数据共享,消除信息孤岛,充分发挥数据的价值。以商用数据库为载体,按照预先定义的库、表结构定义和权限配置,实现各种数据的双向交换。
2 缓存的优势
本缓存技术实现的数据库由一系列key-value对的记录构成。key和value都可以是任意长度的字节序列,既可以是二进制也可以是字符串。这里没有数据类型和数据表的概念。当作为Hash表数据库使用时,每个key必须是不同的,因此无法存储两个key相同的值。提供了以下访问方法:提供key,value参数来存储,按key删除记录,按key来读取记录,另外,遍历key也被支持,虽然顺序是任意的不能被保证。这些方法跟Unix标准的DBM,例如GDBM,NDBM等等是相同的,但是比它们的性能要好得多,因此可以替代它们。

图1. 系统结构图
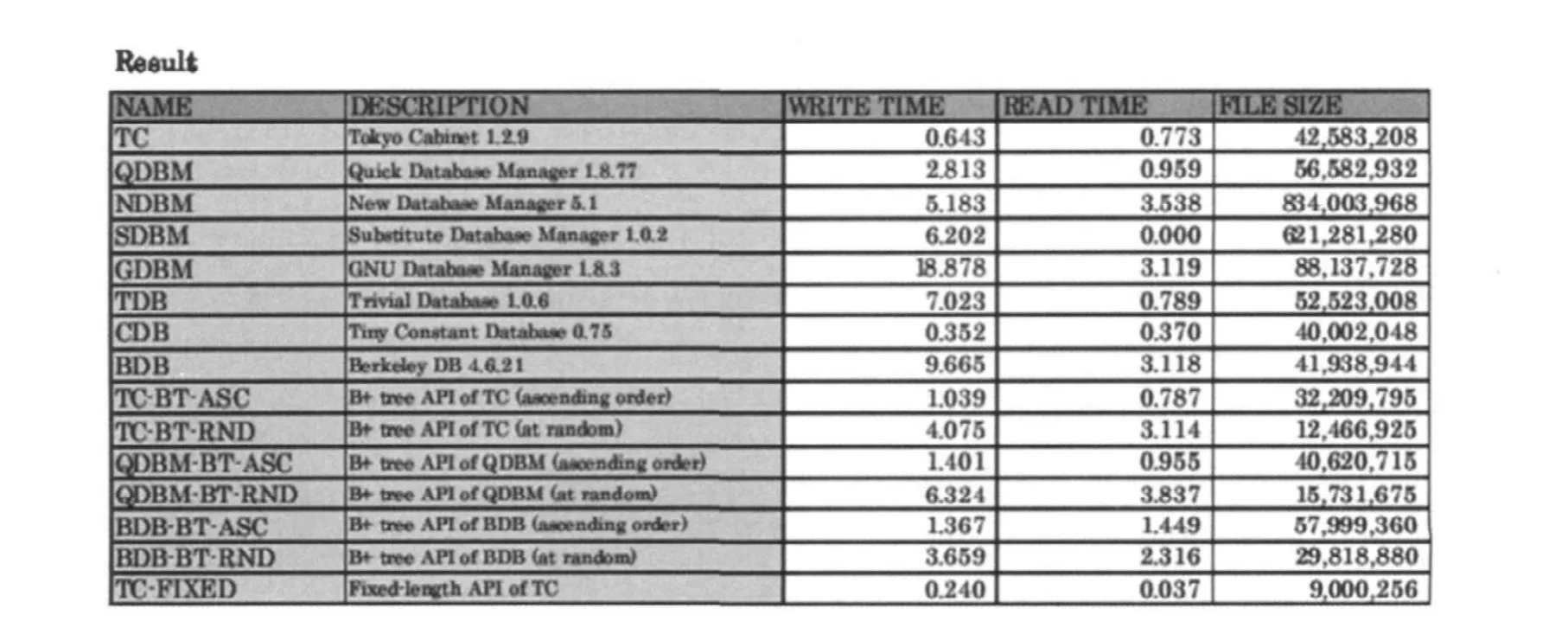
图2. DBM测试比较
传统数据库性能上的问题越发凸显,特别是单表的记录数不断增加,WEB应用的写操作越来越多,传统的数据库一主库多从库,读写分离模式作用有限,并发请求数不断增长,导致数据库性能下降。本系统使用的缓存技术读写速度非常快,哈希模式下写入100万条数据仅需要0.402s,读取100万条数据需要0.334s,并且支持双机互为主辅模式,主辅库均可读写。
在一项各DBM数据库基准测试中统计了写入,读取1000000条数据的时间和占用空间的大小,本系统使用的缓存技术在超大数据量下表现出色,不仅在读写时间上是其他DBM数据库的几倍,并且存储空间也优于其他数据库。
3 缓存的应用
在介绍完整个系统结构后,我们可以大体知道缓存在整个系统中的位置和重要作用。如图1所示,缓存共部署了三个主要环境:终端参数缓存、定时任务数据缓存、历史冻结数据缓存(入库环境)分。
参数缓存存储了现场终端和电表计量设备的简单信息,这些信息会被系统非常频繁的使用,存入缓存将大大减小数据库的压力,并且在速度上很有优势。
任务数据缓存储定时执行的任务,这些任务的特点是生成时间短,数据量大,生成时间间隔与采集时间间隔相差大,生成任务时必须存储,并且执行采集时又删除任务,因此单独为任务存储部署一个缓存是很有必要的。
部署数据缓存的原因是采集速度远远大于入库速度,因此将数据暂时存入数据缓存,入库程序循环读取数据后入库,这样可以大大提高前置机的速度。
以下从与缓存密切相关的三个功能介绍缓存的应用方法。
3.1 在线率统计功能
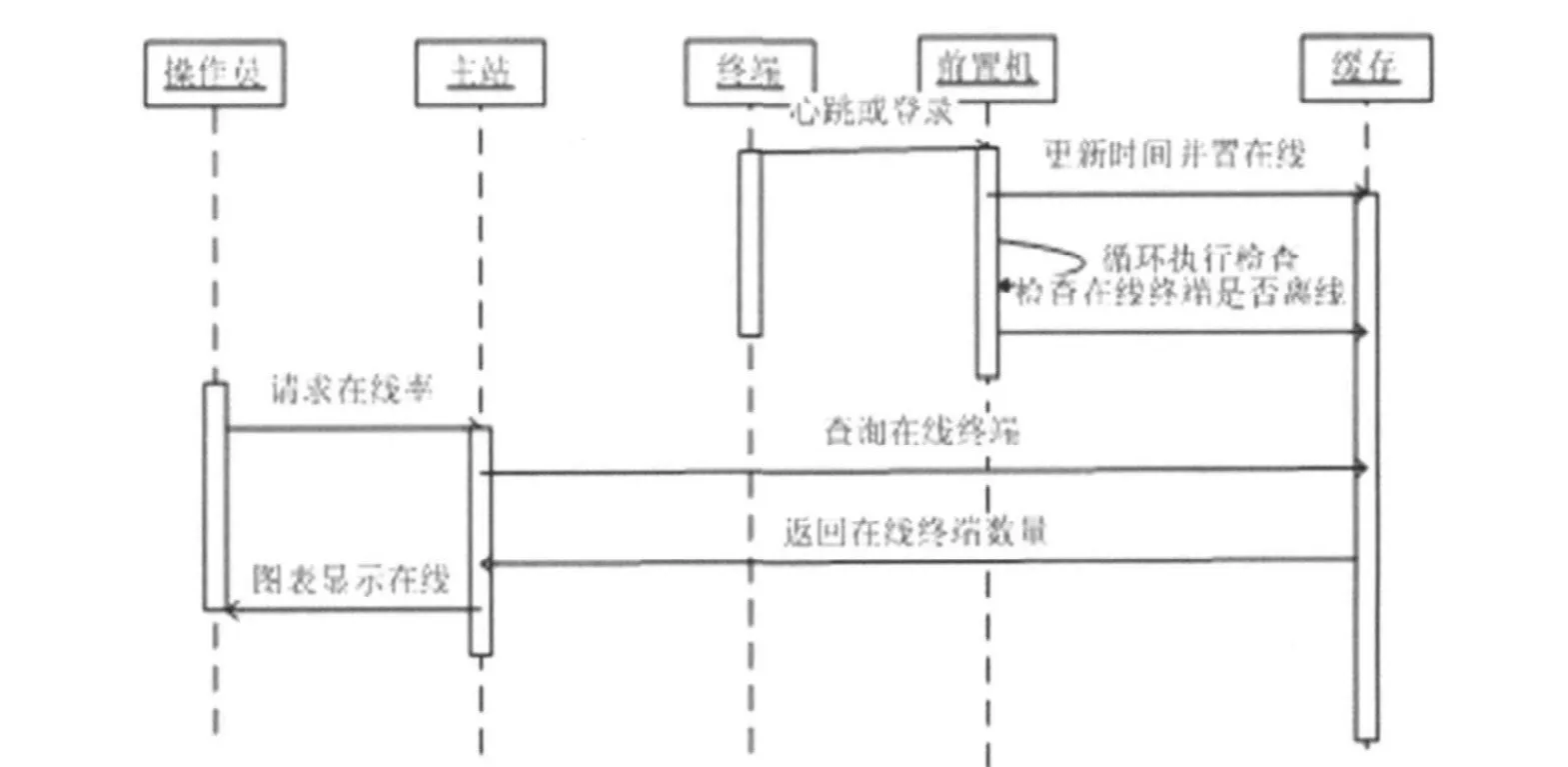
图3. 在线率统计时序图
在线率统计功能是显示当前在线的终端数量和占总终端数量的百分比,是衡量整个采集系统的重要指标。因此怎样做到最准确的统计显得尤为重要。本采集系统是按照当前时间与终端最后登录或心跳时间的差作为衡量标准。
在线率信息需要前置机维护,主站使用。在终端每次登陆和心跳时,前置机将会在缓存查询存储该终端信息的记录,更新其登陆时间和最后心跳时间,并将其在线标志位置1;另外前置机定时检查所有在线终端,并计算当前时间减去最后心跳时间的值,将该值与离线时间临界值比较,若大于临界值,则判定该终端离线,将该终端在线标志位置0,小于该值不作其他操作。该临界值视多数终端的心跳间隔而定,如果该终端实际在线,一个心跳间隔前置机未接收到,虽然置该终端离线,但是前置机不会断开与终端的通信连接。
主站操作员查看终端在线率时,由主站查询缓存,统计在线标志位为1的终端数量,可容易的计算在线率,再以图表的形式显示在界面。
3.2 定时任务的执行
数据采集功能是用电信息采集系统的重要功能,本系统有专门自动执行该采集功能的任务程序,并且与缓存关系密切,因为其需要的数据量大但是内容简单,用缓存辅助非常方便。
数据采集的流程大致是这样的,首先由操作员制定采集任务模板,该模板被存入数据库和缓存,由任务程序读取该模板,查询参数缓存的测量点等信息,生成采集原子任务,并写入任务缓存。前置机再循环读取任务缓存,将在线终端的原子任务读取出来并发送到终端。从该功能可以看出缓存起到很好的缓冲作用,比如说在采集时间段内有某些终端不在线,则前置机不会读取该终端的任务,当该终端上线时再执行采集,这样可很大程度提高采集成功率。
3.3 入库程序
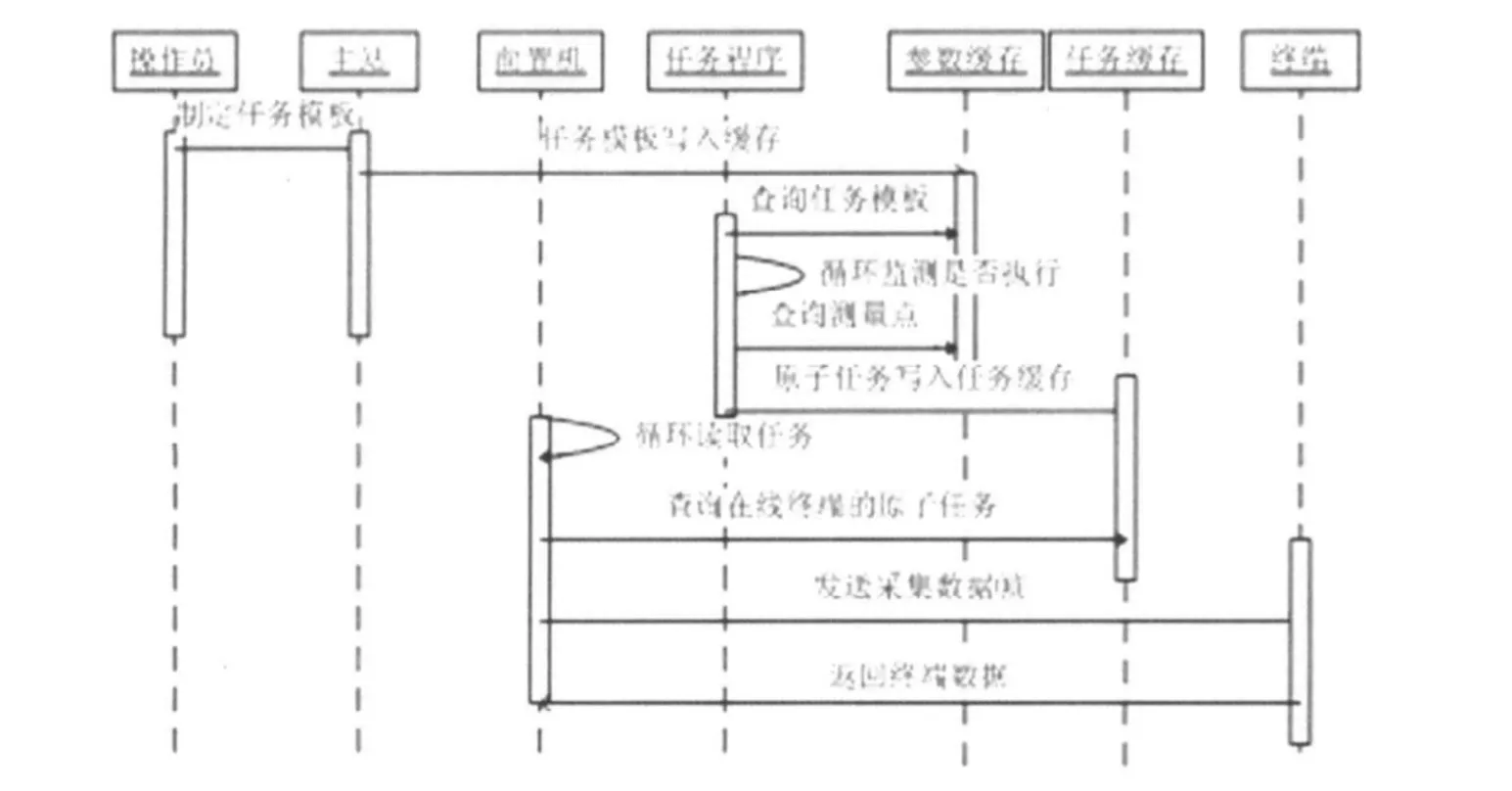
图4. 采集任务时序图
入库程序会用到参数缓存和数据缓存,主站和任务自动采集的历史数据会暂时存储在数据缓存,入库不断读取数据缓存的数据并解析,根据基础数据到参数缓存查询入数据库需要的其他信息,然后组织数据入库。
缓存在此起到的作用是暂时存储采集的数据,因为前置机在时间上对多个终端来书是并发的,入库却需要顺序的插入数据库,特别是在任务开始采集的初始阶段,在循环一次的采集过程中,每个终端都会有一条数据,入库速度远远达不到采集速度,因此将所有数据写入缓存暂时存储,前置机可继续高速采集数据。入库程序虽然开始跟不上采集速度,但是到采集后期,未采集终端数据量变小时,入库程序同样保持自己的入库速度,将前面跟不上的入库工作补上来。在此,缓存很好的解决了前置机和入库的速度差异,大大提高了程序的执行效率。如下图所示,如果没有缓存,数据采集与入数据库的速度只能相互适应,即它们使用了两者中速度较低的一者,并且采集过程中,如果速度阻塞在与入库同速,主站采集实时数据也会受到影响。缓存的引入使两者的速度互不干涉,可以发挥自己的最大速度。
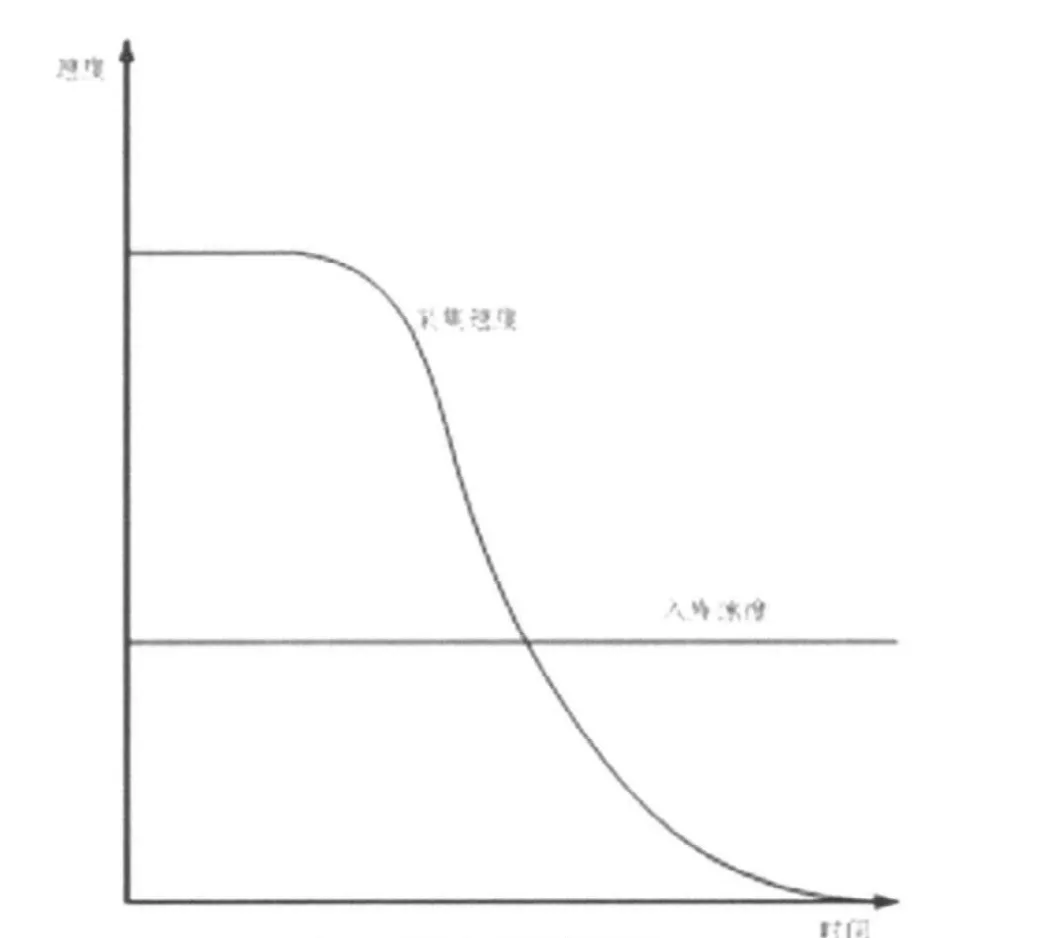
图5. 采集入库速度示意图
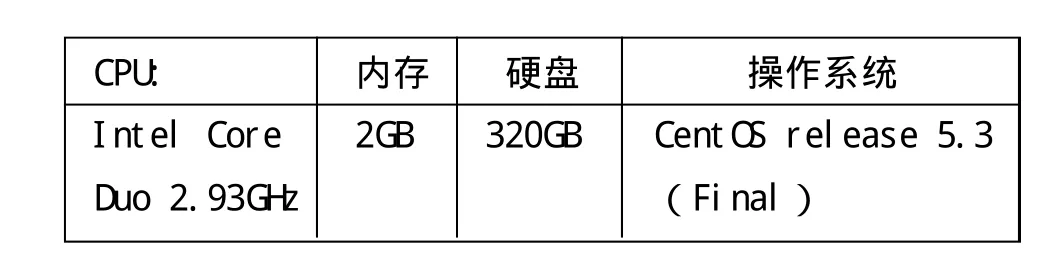
CPU: 内存 硬盘 操作系统Intel Core 2GB 320GB CentOS release 5.3 Duo 2.93GHz (Final)
4 缓存效率的测试与提高
编写一个简单的入缓存程序,循环向缓存写入数据,在实际的环境下测试其写入速度,测试用机器配置如下:
编译测试程序后执行该程序,分三次测试,分别写入100万,300万,500万条数据,记录写入使用时间,为保证写入条件一致,每次测试后清空上次缓存测试数据。分别在每次测试数据的基础上查询数据,记录查询时间。
测试结果如下表:
从测试结果可以看出,大量数据写入缓存仅需要几分钟时间,本系统只有在初始化缓存时才会这样写入,该速度可以接受,但是查询速度随着数据量增加,条件查询一次需要几秒,对于交互非常频繁的数据来说,这是不可忍受的,但是主键查询却可以立即显示结果,这才是我们使用的查询方法。
缓存存储是由一系列key-value对的记录构成,本应用中主键是key,记录是一条value值,在主键加索引后,当用主键获取该记录时,缓存可直接提取该记录的存储地址,因此无论有多少数据,查询时间都是O(1)。
在缓存的使用过程中,将最常使用的字段加索引来提高查询速度,在查询时,尽量使用有索引的字段查询数据,可有效提高查询速率。
5 结语
电力用户用电信息采集系统以建设“全覆盖、全采集、全预付费”为总体目标,系统涉及数据量大,并且操作次数频繁,缓存的使用有效减轻数据库压力,并且使用方便,数据查询速度快,有效解决了数据交互速率的瓶颈,是本系统中的一项关键技术。缓存的使用还有很大的发展空间,本系统对缓存的使用也会为将来的进一步研究有很大的帮助。
[1]Tokyo Tyrant: network interface of Tokyo Cabinet[DB/OL]. http://fallabs.com/tokyotyrant/
[2]Tokyo Cabinet: a modern implementation of DBM[DB/OL]. http://fallabs.com/tokyocabinet/
[3]张海藩.软件工程导论[M].北京:清华大学出版社.2007-5
[4]Stanley B.Lippman,Josee Lajoie,Barbara E.Moo著,李师贤,蒋爱军,梅晓勇,林瑛 译, C++ Primer 中文版:第4版[M],北京人民邮电出版社 ,2006.3
[5]刘振亚 国家电网公司信息化建设工程全书 营销业务应用篇[M]北京:中国电力出版社 2008-10

测试次数 写入数据条数 写入时间 条件查询使用时间 主键查询使用时间第一次 1000000 0’42’’30 1’’15 即时显示结果第二次 3000000 2’09’’01 2’’90 即时显示结果第三次 5000000 3’44’’20 3’’36 即时显示结果
猜你喜欢
房地产导刊(2021年10期)2021-11-22
中国食品(2021年4期)2021-03-22
中国食品(2021年2期)2021-02-24
中学生数理化·中考版(2020年12期)2021-01-18
中国生殖健康(2020年5期)2021-01-18
教书育人(2020年11期)2020-11-26
当代陕西(2020年13期)2020-08-24
活力(2019年15期)2019-09-25
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
