
意见时空元素的研究
2011-06-14 03:45姚天昉
中文信息学报 2011年3期
刘 军, 姚天昉, 仇 伟
(上海交通大学 计算机科学与工程系,上海 200240)
1 引言
伴随着Web2.0技术革命,互联网上的意见型文本[1]呈爆炸性地增长,这些文本蕴含着广大用户的喜怒哀乐。Kim和Hovy[2]将意见定义为一个四元组[Topic, Holder, Claim, Sentiment],其中Topic为意见主题,也时也称为焦点(Focus);Holder为意见持有者;Claim为意见陈述(即范围);Sentiment为情感。即,意见持有者(Holder)针对某个主题(Topic)发表了一个有意见倾向性(Sentiment)的意见陈述(Claim)。例句: N72,我挺喜欢的,很大气。例句的主题是“N72”(诺基亚手机);意见持有者是“我”;情感词是“喜欢”、“大气”;倾向性是褒义的。
人们围绕着Kim&Hovy意见模型在主题识别[3-5]、倾向性分析[6-8]等方面展开了意见挖掘技术[9]的研究,取得了许多丰硕成果。Pulse[10]、WebFoudation[11]和Opinion Observer[12]是这些成果中比较典型的意见挖掘系统。Pulse对汽车评论进行意见挖掘。它首先从评论中得到汽车制造商和汽车型号的分类树,然后分析每个车型的意见倾向性,最后以“主题,情感”的格式展现结果。WebFoudation利用NLP技术构建知识库,并应用于解决极性识别问题。Opinion Observe在提取产品的特征后,按照特征的意见褒贬分类汇总。用户输入任意两产品,系统以图形的方式展现两产品的特征褒贬数的比较。
典型意见挖掘系统对所有意见进行倾向性分析之后,简单地根据意见的褒贬性分类汇总。但是这种简单的汇总信息并不能满足许多应用的需求。例如,如果意见挖掘系统为一个产品决策者服务,系统应该能区分意见的新旧程度、权威程度以及意见的趋势;同样地,如果意见挖掘系统向消费者推荐商品,系统应该尽可能地推荐一些当前的、有一定权威的产品意见给消费者参考。在这些新的应用需求面前,除了Kim&Hovy意见模型的四元素之外,意见的时空元素具有至关重要的作用。
意见的时空元素,是指意见的时间和意见的来源。本文通过扩展Kim&Hovy意见模型,将意见时空元素引入到意见模型中并提出了意见重要因子的概念,阐述了时空元素对意见重要因子的作用和计算方法。最后,回到意见时空元素的应用上,探讨了意见趋势的挖掘方法。实验表明,意见时空元素也是意见的重要组成部分,它们有效地拓展了意见挖掘的应用范围,并得到了更多令人信服的结果。
本文的组织如下: 第2节介绍了意见模型的扩展,引入了意见时空元素;第3节阐述了意见重要因子、时空重要因子以及来源重要因子的计算方法;第4节探讨了意见趋势的挖掘方法和实验评估方法;第5节为全文的总结。
2 意见模型的扩展
2.1 主题的模型
主题(Topic)的类型包括产品、人、组织、事件等。对一个主题来说,有两个重要参数: 一是描述该主题的所有同义的词或短语;二是该主题的所有的子主题。例如,“诺基亚”和“Nokia”描述的是同一个主题,“N70”是该主题的子主题。我们将主题定义为:
Topic=[SynWordSet,subTopicSet]
式中:SynWordSet为同义词表,subTopicSet为子主题集。
2.2 情感的模型
情感的二要素为: 情感成分、情感极性。情感成分一般为包含情感词的短语,情感极性为褒义、贬义或中性。我们将情感定义为:
2.3 意见的模型
我们扩展Kim&Hovy意见模型,将时间和来源元素也作为意见的组成部分,即,
Opinion=[Holder,Topic,Sentiment,Claim,Time,Source]
意见的含义为意见持有者(Holder)在某个时刻(Time)、某个地方(Source)针对某个主题集(TopicSet)表达了一些情感(SentimentSet)。即,
对任意Topic∈TopicSet,Holder必定(1)选用了Word∈SynWordSet来描述该Topic;(2)针对该Topic表达了一些情感。
3 意见重要因子
在以往的意见挖掘中,没有区分意见的重要性。但是在意见趋势挖掘等新应用中,即使同一条意见,发生在不同的时间或来自不同的地方,其重要性也是不同的。假如我们要挖掘2008年的意见趋势,则我们可以忽略掉不属于2008年的意见。同样地,对于来自专业评论网的意见要比散布在其他论坛的意见重要性高。
为了量化意见的重要性,我们提出了意见重要因子(Opinion Important Factor)。对任何一条意见o,其重要因子OIF(o)由式(1)给出,

(1)
OIF(o)的含义为:
(1) 当意见o的时间重要因子T(o)和来源重要因子S(o)都不等于0的时候,我们可以调节T(o) 和S(o)的权重,将两者相加得到OIF(o)。
(2) 如果意见的时间重要因子或来源重要因子有一项为0,那么说明这条意见根本就不重要,可以直接忽略掉。例如: 我们有时需要忽略某个时间段的意见或忽略来自某个网站的意见,这时候我们可以设置这些意见的T(o)或S(o)等于0。
3.1 意见的时间重要因子
时间是客观世界存在的一种属性,意见也具有时间性。时间可以用来区分意见的重要程度。例如,在常见的产品评论挖掘系统中,如果要挖掘出当前最受欢迎的产品,则最新的评论的重要性更高。但这并不意味着意见的重要性与时间的关系就这一种。事实上,意见的重要性与时间的关系是随着具体的应用而不同的,需要根据具体的应用需求进行分析。假设意见o的时间为time(o),重要因子为T(o),表1为时间重要因子在一些具体应用中的取值。
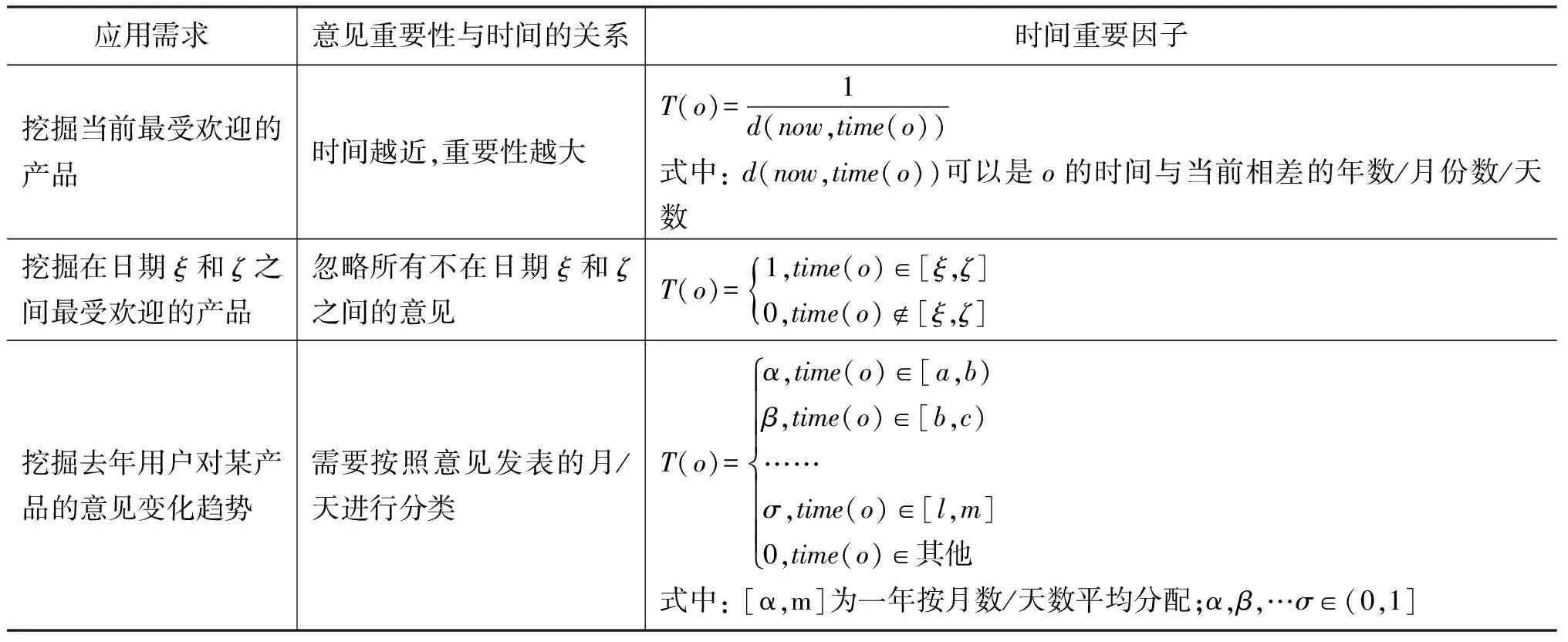
表1 时间重要因子在不同应用中的取值
3.2 意见的来源重要因子
人们常用“十大游戏网站”、“三大门户网站”、“三大搜索站点”等词语来刻画网站在某领域的重要性。同样地,在意见挖掘中,除了意见的时间元素外,我们也应考虑到意见的来源在该领域的重要性。与时间元素不同的是,意见来源的重要性与领域有重要的关系。举例来说,卓越网是以网上书店起家的,然后逐渐扩大到电子产品的在线销售网站。对于卓越网来说,在书籍方面的重要性远比它在电子产品方面的重要性更高。因为从整个中国的网站来看,卓越网在书籍方面的评论数和访问量上,都比在电子产品方面更重要。
假设语料库中的意见来源于n个论坛,论坛si在领域m上的重要因子表示为Ψ(si,m),那么属于论坛si的意见的来源重要因子S(o)就等于Ψ(si,m)。因此,我们将着重讨论如何计算Ψ(si,m)?
在信息检索领域,Google提出了PageRank算法[13]对一个网页的重要性进行量化。在PageRank算法中,一个网页的重要性由链向它的页面数(链入数)来决定。链入数越大的页面,其重要性越高。PageRank算法的思想与人的直观认识也是相符的。
在ACL08上,加州伯克利大学的Preslav Nakov[14]利用搜索引擎计算两个名词的关联度。由WordNet得到两个名词的屈折词集(屈折词是改变词尾得到的词,如worked是work的屈折词),再将两个屈折词集中的词两两组合作为关键字让Google进行搜索,抽取Google返回结果中包含两个名词的文字片段,然后将文字片段中动词、介词和并列连词作为这两个名词的特征,再根据向量空间模型得到这两个名词的向量,最后计算这两个名词的关联度。
上述工作给本文提供了重要的启示,本文将论坛si在领域m上的重要因子Ψ(si,m)分为二部分: 论坛的影响力、论坛与领域m的相关度。
3.2.1 来源的影响力
影响力主要是刻画某一论坛在同类论坛中的份量。影响力越大的论坛,用户访问的次数越多,网页内容会更丰富,被其他网站链接的机会也更多。本文对论坛的影响力用三个参数来刻画: 论坛的日访问量、链入数和被搜索引擎收录的页面数。很显然,日访问量能够很好地代表论坛的人气。日访问量越大,说明论坛的用户数多,论坛越受欢迎。与Google的PageRank类似,链入数代表了论坛被互联网其他网站的认可程度。链入数越大,说明论坛越重要。另外,因为搜索引擎已经成为人们寻找Internet上浩如烟海信息的指航灯,一个论坛被搜索引擎收录的页面数越多,越容易被访问到。
3.2.2 来源与领域的相关度
如果人们在搜索引擎中输入一个关键字K,然后通过点击搜索引擎返回的链接结果而访问了论坛si,那么我们可以确定的是: (1)关键字K肯定与论坛si有一定的相关。否则搜索引擎不会在关键字K的结果中返回论坛si的链接;(2)搜索关键字K导致访问论坛si的次数越多,则关键字K与论坛si的相关度越高。
我们可以通过搜索日志得到访问论坛si时的高频搜索关键字集KS。从某种意义上来说,高频搜索关键字集KS就是论坛si在互联网中的代名词。所以,本文将论坛si与领域m的相关度转化为论坛si的高频搜索关键字集KS与领域m的相关度。
3.3 意见来源重要因子的实验
3.3.1 实验对象
我们选了“手机”和“汽车”2个领域、在每个领域中又选了4个论坛作为我们的实验对象。一般情况下,论坛都是门户网站下的二级域名。例如,“智能手机论坛sjbbs.zol.com.cn”是“中关村在线zol.com.cn”下的二级域名。所选的8个论坛请见表2。
3.3.2 论坛影响力的计算
(1) 论坛日访问量的计算
alexa.com是比较有影响的web信息统计公司,它以一级域名为单位进行日访问量、点击流、访问时的高频搜索关键字等信息进行统计。
alexa.com对日访问量用百分比描述,即日访问量%(Daily Reach%)。其含义为alexa.com所能统计到的所有internet用户中有百分之几访问了这个网站。
假设alexa.com所能统计到的所有internet用户数为Δ,论坛si的日访问量%为di%,则论坛si日访问用户数为Δ×di%。
本文将Ψ11(si)取为论坛si占所有论坛的日访问量的比重,即式(2)。
(2)
(2) 链入数和被收录页面数的计算
利用搜索引擎可以查询论坛的链入数和被收录的页面数。在搜索引擎的高级搜索语法中,有link和site两个关键字。假设URL(si)表示论坛si的URL,则link:URL(si)返回论坛si的链入数li,site:URL(si)返回搜索引擎收录了论坛si的页面数pi。
在本文中,Ψ12(si)取为论坛si占所有论坛链入数的比重,Ψ13(si)取为论坛si占所有论坛被收录页面数的比重,分别为式(3)和式(4)。
(3)
(4)
(3) 论坛影响力的计算
综合式(2)、式(3)和式(4),就得到了论坛影响力的计算式(5),
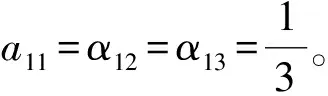
3.3.3 论坛与领域的相关度实验
我们从alexa.com获取了8个论坛的前30个频次最高的搜索关键字,然后将论坛si与领域m的相关度转化为高频搜索关键字集KSi与领域m的相关度。本文使用了已有的任意两个词汇的语义相关度计算公式Relatedness(m,ki)[15],得到关键字集KSi与领域m的相关度计算为式(6),
式中:rank(ki)是关键字ki的频次排名;m为“手机”或“汽车”。
计算出来R(m,KSi)后,论坛si与领域m相关度的计算为式(7),
3.3.4 实验结果
综合式(5)和式(7),得到意见的来源重要因子的计算为式(8),
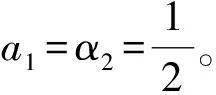
表2是意见来源重要因子的实验结果。表2的“日访问量”是三个月的日访问量,“链入数”和“收录的网页数”是百度和谷歌的总数。我们可以从实验结果得出如下结论:
(1) 日访问量和高频搜索关键字都是取自论坛的父域名的数据,实验结果验证了这种做法的合理性。“太平洋手机俱乐部”的父域名是“太平洋电脑网”,是一个多领域的网站。“太平洋手机俱乐部”的影响力Ψ1的得分是手机领域里最高的,这主要得益于其父域名的访问量大;同时,“太平洋手机俱乐部”的相关度Ψ2又因其父域名是多领域得分最低。
(2) 意见来源重要因子是一个多因素的参数,考虑的角度不同,得出的结果也会略有差别。本文从意见来源的影响力、与领域的相关度两个方面来分析,综合利用权威的统计信息进行计算。从计算结果来看,这与意见来源的统计数据所反映的情况是一致的。

表2 意见来源重要因子的实验结果
4 意见趋势挖掘
4.1 挖掘方法
人们对某事物的看法是随着时间而变化的,这是意见趋势挖掘的根本出发点。意见趋势用于刻画某事物的意见得分在时间轴上的变化情况,它较真实地记录了事物的发展变化,有利于人们把握事物的真实状况。
以产品p为例,其意见趋势就是产品p的意见得分在时间轴上的变化线。我们将时间轴分成t个时间段T,产品p在时间段Ti上的意见得分为θi,则产品p的意见趋势就是θi(i=1..t)的变化情况。意见趋势挖掘的核心问题是求出产品p在时间段Ti上的意见得分θi。
我们用“受欢迎度”来刻画产品p在时间段Ti上的意见得分。对于一条意见的得分采用strength(o)×OIF(o)表示。strength(o)是意见的情感强度[16],OIF(o)是意见重要因子。假设产品p在时间段Ti上有n条褒义的意见和m条贬义的意见,我们用式(9)来计算产品p在时间段Ti上的“受欢迎度”。
(9)
式中: 分子表示产品受褒奖的意见数越多,说明产品越热。分母表示产品受批评的意见数越少,则产品越受欢迎。
4.2 实验
4.2.1 实验主题及语料
为缩小实验主题,本文随机选用“奇瑞QQ3”、“比亚迪F0”、“昌河北斗星”、“吉利熊猫”、“长安奔奔”这五种微型车。在时间上,以季度为单位,范围限制在2008的四个季度、2009年的前两个季度。即,本实验的目标是: 挖掘五种微型车在2008年至2009年上半年的按季度的意见趋势。本实验的时间重要因子的计算为式(10),意见重要因子的计算为式(11),来源重要因子的计算结果已经在第3节的表3中。
本实验的语料来自4个汽车论坛,共包括 15 819条意见。
4.2.2 实验结果及分析
我们首先根据式(9)得到五种微型车在各个季度的“受欢迎度”值,然后画出它们的“受欢迎度”季度变化线。图1是我们绘出的五种微型车在2008年和2009年上半年的按季度的意见趋势。图2是按照传统意见挖掘系统的做法,绘出了五种微型车的6个季度的“受欢迎度”汇总。

图1 微型车的季度意见趋势
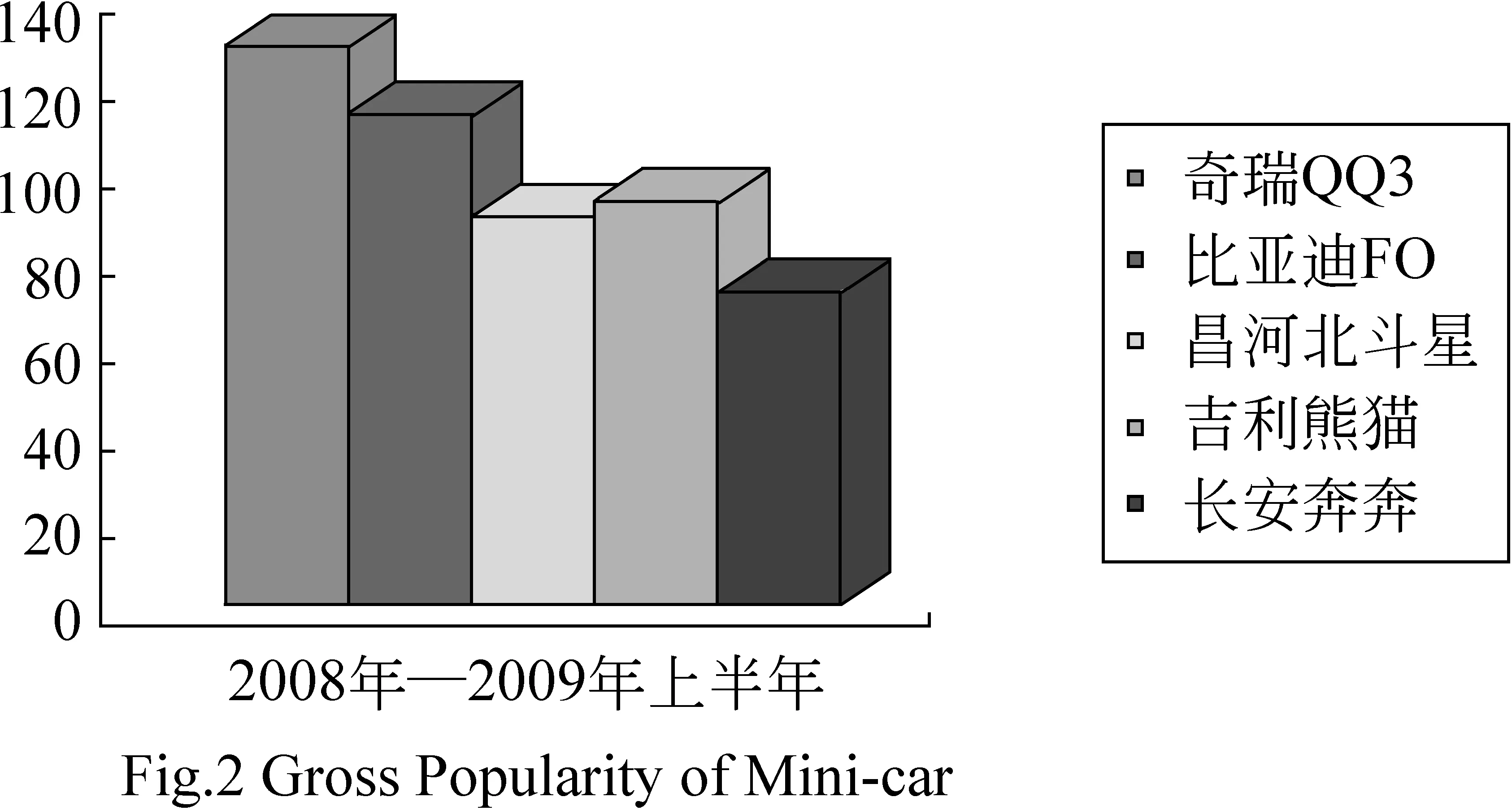
图2 微型车的欢迎度汇总
比较图1和图2,我们发现意见趋势挖掘具有如下优点:
(1) 记录了事物的发展历程。在传统意见挖掘系统的图2中,“奇瑞QQ3”比“比亚迪F0”更受好评,“吉利熊猫”比“昌河北斗星”更受欢迎。但从趋势挖掘的图1可以清楚地看到,“比亚迪F0”与“奇瑞QQ3”的差距越来越小,甚至曾经在两个季度超过了;另外,“昌河北斗星”在2008年初因为价格高等原因不受好评,但后面的发展超过了“吉利熊猫”。
(2) 对人们具有指导作用。如图1所示,“奇瑞QQ3”在2008Q4、“吉利熊猫”在2008Q3都有一个明显的下降点,这种信息可以特别提醒决策者关注原因、有目的地改进。
4.2.3 实验评估
本文将人工得到的意见趋势作为基准,实验结果与基准进行比较,差异的大小就是实验的效果度量。
首先我们用几何方法来探讨意见趋势的实验评估公式。如图3所示,红线是我们通过人工得到的某产品的意见趋势图,B点是T2时刻的意见得分,C点是T3时刻的意见得分。假设线段km、fm、fn都是BC段的实验结果,并且k点离B点的距离等于f点离B点的距离。
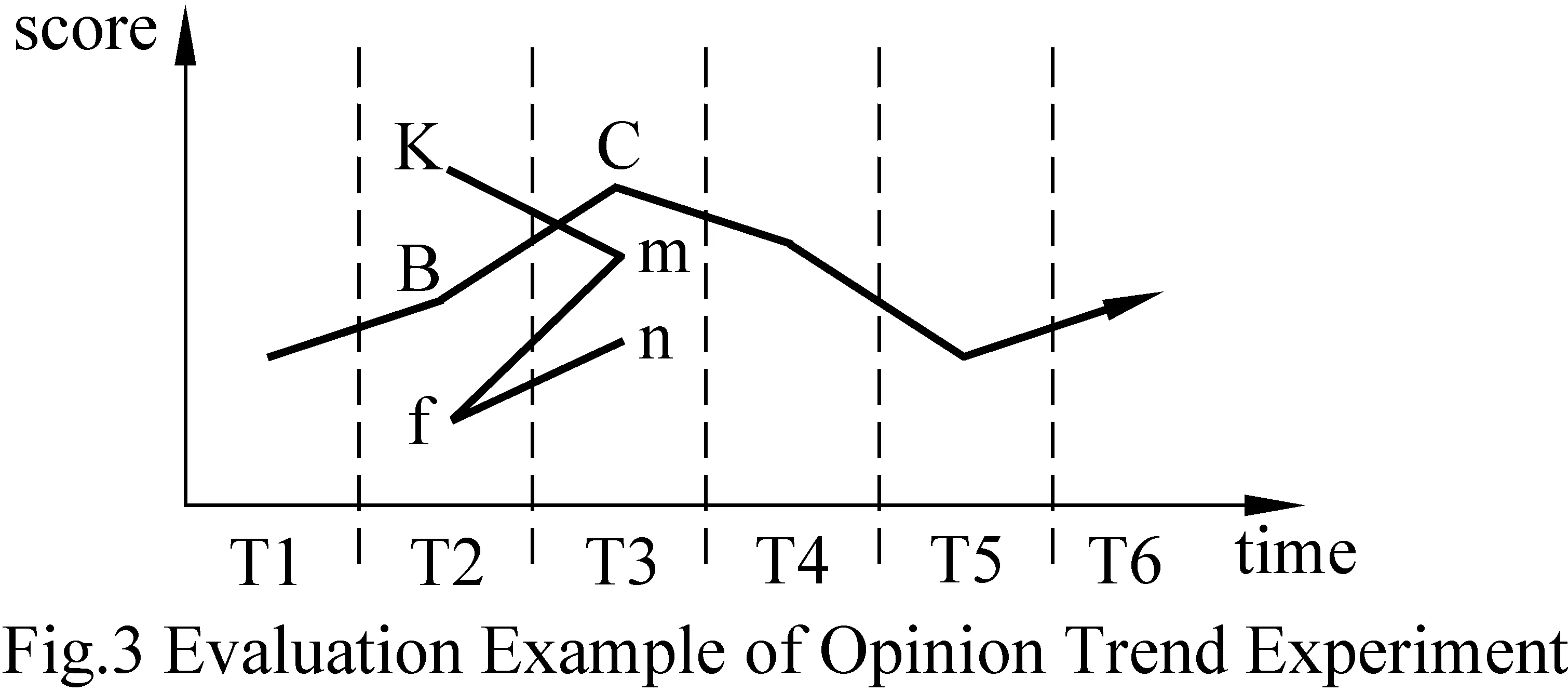
图3 意见趋势实验评估示例
我们从两个方面来分析km、fm、fn的好坏:
(1) 距离差。很显然,fm的效果比fn好。因为在T2时刻,fm的意见得分的误差与fn一样;但在T3时刻,fm的意见得分的误差比fn小。
我们采用意见得分差的平方表示距离差,即fm与BC的距离差为式(12),
式中:f.y表示f点的y坐标值。
(2) 斜率偏差。km与fm的距离差相等。但很显然,fm的效果比km好。因为BC体现了T2到T3时刻的意见得分增加趋势,fm与BC一样,但km却体现为减小趋势。
我们取x轴的每段时间为单位1,则简化后的fm和BC的斜率计算为式(13)、式(14):
我们用直线的斜率差的平方表示斜率偏差,即fm与BC的斜率偏差为式(15),
综合式(12)和式(15),我们得到在几何表示下,意见趋势直线fm与BC的误差度量为式(16)。式(16)的值越小,表明直线fm与BC越接近。
最后我们用代数方法来描述意见趋势的误差公式。假设在ti(i=1..n)时刻,产品p的真实的和实验的“受欢迎度”分别为ρi、γi,则产品p的意见趋势的实验误差为式(17)

e(p)越小,则说明实验的结果与真实的越接近。
根据式(17)计算出来的五种微型车的意见趋势误差分别为16.91、9.93、13.21、13.18、11.79。因为五种微型车的趋势相交得比较严重,为清楚起见,图4只画出了“QQ3”和“奔奔”的真实趋势与实验趋势的比较图。从实验结果可看出,我们的意见趋势的效果与人工的效果很接近,反映了微型车在论坛上的意见趋势。
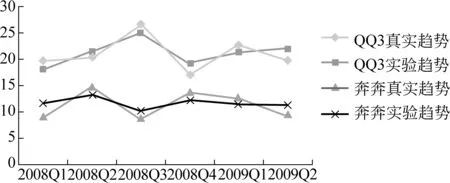
图4 真实趋势与实验趋势的比较
5 结束语
意见时空元素的研究是个全新领域。本文将时空元素引入意见模型,研究了时空元素与意见重要因子的关系,并探讨了时空元素在意见趋势挖掘中的应用。一方面,本文只研究了时空元素对意见重要性的作用,但时空元素的作用远不止于此。例如,通过分析最近一段时间内的评论,我们可以找到当前热点评论对象;通过分析某个论坛的所有评论,我们可以大概知道论坛的领域,甚至是论坛的帖子风格。另一方面,本文在分析意见重要因子时,只考虑了时空元素的影响。而实际上,意见的持有者对意见的重要性也有影响。例如,如果我们已经挖掘出了某个特定论坛的所有用户的基本信息,那么在对这个论坛进行意见挖掘时,我们可以将一些喜欢发无用帖的人的意见重要程度降低、甚至去除。我们还可以针对某个年龄段、性别等特征进行意见挖掘,这时候也会影响到意见的重要程度。以上两方面都是本文今后的研究方向。
[1] 刘全升,姚天昉,黄高辉,刘军,宋鸿彦. 汉语意见型主观性文本类型体系的研究[J]. 中文信息学报, 2008, 22(6):63-68.
[2] Soo-Min Kim, Eduard Hovy. Determining the Sentiment of Opinions[C]//Proceedings of COLING, 2004.
[3] J . Yi, T. Nasukawa, R. Bunescu, and W. Niblack. Sentiment Analyzer: Extracting Sentiments about a Given Topic using Natural Language Processing Techniques [C]//Proceedings of the 3rd IEEE International Conference on Data Mining. Melbourne, Florida:IEEE, 2003:427-434.
[4] M.Hu and B. Liu. Mining Opinion Features in Customer Reviews [C]//Proceedings of Nineteenth National Conference on Artificial Intelligence. San Jose:ACM, 2004.
[5] A.-M. Popescu and O. Etzioni. Extracting Product Features and Opinions from Reviews [C]//Proceedings of HL T-EMNLP-05, the Human Language Technology Conference/ Conference on Empirical Methods in Natural Language Processing. Vancouver, Canada:ACM,2005:339-346.
[6] V. Hatzivassiloglou and K. R. McKeown. Predicting the semantic orientation of adjectives[C]//Proceedings of the ACL Conference, 1997:174-181.
[7] P.D. Turney and M.L. Littman. Unsupervised learning of semantic orientation from a hundred-billion-word corpus [R]. Technical Report ERB-1094, National Research Council Canada, Institute for Information Technology, 2002.
[8] Peter D. Turney. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews [C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002.
[9] 姚天昉, 程希文, 徐飞玉,等. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22(3):71-80.
[10] Gamon, M., A. Aue, S. Corston-Oliver and E. Ringger. Pulse: Mining Customer Opinions from Free Text[J]. Lecture Notes in Computer Science. 2005, 3646:121-132.
[11] Jeonghee Yi, Wayne Niblack. Sentiment Mining in WebFountain [C]//Proceedings of 21st International Conference on Data Engineering, 2005:1073-1083.
[12] Hu, M. and Liu, B. Mining and Summarizing Customer Reviews [C]//Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Seattle:ACM, 2004.
[13] Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual Web search engine [C]//Proceedings of the Seventh International World Wide Web Conference. 1998: 107-117.
[14] Preslav Nakov, Marti A. Hearst. Solving Relational Similarity Problems Using the Web as a Corpus [C]//Proceedings of ACL-08: HLT, pages, Columbus:ACM, 2008: 452-460.
[15] Evgeniy Gabrilovich, Shaul Markovitch. Computing Semantic Relatedness using Wikipedia-based Explicit Semantic Analysis[C]//The 20th International Joint Conference on Artificial Intelligence. Hyderabad:ACM. 2007.
[16] 姚天昉,娄德成. 汉语情感词语义倾向判别的研究[C]//中国计算技术与语言问题研究—第七届中文信息处理国际会议论文集, 武汉: 2007.
猜你喜欢
四川党的建设(2022年8期)2022-04-28
华人时刊(2022年1期)2022-04-26
第一财经(2021年6期)2021-06-10
小学生学习指导(低年级)(2020年11期)2020-12-14
动漫界·幼教365(大班)(2019年10期)2019-10-28
作文大王·低年级(2018年10期)2018-12-06
Coco薇(2017年9期)2017-09-07
小猕猴智力画刊(2016年5期)2016-05-14
纺织服装流行趋势展望(2016年2期)2016-05-04
汽车科技(2015年1期)2015-02-28
