
一种基于加权投票的术语自动识别方法
2011-06-14 03:45游宏梁沈钧毅
中文信息学报 2011年3期
游宏梁, 张 巍, 沈钧毅, 刘 挺
(1. 西安交通大学 电子与信息工程学院,陕西 西安 710049;2. 北京文献服务处,北京 100142; 3. 哈尔滨工业大学 计算机学院, 黑龙江 哈尔滨 150001)
1 引言
术语自动识别(Automatic Term Recognition,ATR)也称为术语自动抽取(Automatic Term Extraction),是指从文本中自动发现领域术语的过程。术语所形成的术语表或术语库是信息抽取、文本挖掘领域诸多任务的重要辅助知识。中文分词、实体识别等任务,对术语词表具有很强的依赖性。
术语是某领域中反复使用的,形式较为固定、又表达某特定概念的词语。汉语中,术语可以由一个字或多个字组成;英语中,术语可以由一个词或多个词组成。术语具有一定的结构特点: (1)边界特点(按照概念词汇的前后界标记,概念词汇可分为三类: 有前后界标记的、有前界或后界标记的、无前后界标记的);(2)长度特点(中文概念词汇长度主要是2~6个字);(3)词性特点(概念词汇大多是名词性的短语)和词性模式特点(如Noun+Noun、(Adj |Noun)+Noun等)。另外,在特定领域的自然语言文本中,术语也服从一定的统计规律: (1)在某一领域中出现频率较高或只出现在某个领域中;(2)在不相关领域中出现频率相对较低。术语的以上特点是实现术语自动抽取的主要依据。
从C-value[1]系列方法的出现以来,术语自动识别技术取得了较大突破。随后对C-value方法做了多次改进,还陆续提出了NC-value方法、SNC-value等方法。C-value方法实际上是一种统计方法,其主要思想是计算术语的单元性(Unithood)[2]。后来提出的NC-value方法引入了上下文信息,目的是将词语本身的统计特征和词语出现的上下文环境特征相融合,提高术语识别的准确性。
除了借用单元性外,Kageura等人还提出了术语度(Termhood)[2]的概念。术语度的思想是通过候选术语与领域的相关性强弱来判断其成为领域术语的可能性。C-value方法之后出现了很多衡量术语度的方法,但是术语度很少单独使用,而通常是和其他衡量方法一起使用。具有代表性的有Term Extractor[3]、GlossEX[4]、ATRACT[5]等。
目前,多特征融合的趋势越来越明显。特征融合由起初的单元性和上下文特征的融合,再到Term Extractor的单元性、领域一致性、上下文特征、结构特征的融合,有效性不断得到验证。但是,综合所有特征不一定比使用一个或者部分特征表现更好。因此,如何选择和融合特征值得深入探讨。
本文尝试将Tf-idf、C-value、Term Extractor进行比较,并采用加权投票算法进行融合。第2节简述相关的研究工作和研究方法;第3节介绍了候选术语抽取方法和候选术语排序方法;第4节比对了单独指标和加权投票算法的结果;第5节是总结和未来工作的展望。
2 相关研究工作概述
目前,术语自动识别主流方法都遵循“先预选,再排序”的流程,即首先挑选出候选术语;再利用某个指标衡量其成为术语的可能性,并按照可能性的高低进行排序。
在挑选候选术语方面,中文一般先进行分词,再抽取候选术语。英文候选词的挑选依据是术语的词性特征。Frantzi[6]、Ismail Fahmi[7]等人认为,术语的词性具有一定的规律。他们首先对文本进行词性标注,接着通过观察分析,提炼出术语的词性规律,得出词性过滤规则;最后,利用这些规则与已标注好词性的文本进行匹配,如果词性串匹配,则提取出相对应的词或词组。这些词或者词组就是候选术语。但问题是,如果词性规则过于严格,容易导致候选术语个数不足,从而降低了术语的“召回率”;如果词性规则过于宽松,容易引入“噪音”词,从而降低术语抽取的“准确率”。因此,人为地制定词性模板会影响规则的准确性。为了获取更加严谨的词性规则,需要借助程序对大规模术语的词性规则进行提取,并为这些词性规则定制优先级(不对规则进行归并,仅对规则进行优先匹配排序)。目前,很多信息抽取系统(如General Architecture for Text Engineering, GATE) 都提供了更加灵活的平台,允许定制模板,并设定模板的优先级*http://gate.ac.uk。
在候选术语的排序方面,目前采用的指标大多基于术语的统计特征、上下文特征、领域相关性、结构特征等。Salton提出的Tf-idf[8]方法综合考量了术语在一篇文档中的频率和不同文档中的分布;Frantzi等人的C-value方法侧重对具有包含关系的字串进行统计,并按照频率进行排序;Frantzi等人还提出了融合上下文词汇权重的NC-value[2]方法;Term Extractor还综合领域相关度(Domain Pertinence)、领域一致性(Domain Consensus)、领域凝聚度(Lexical Cohesion)等指标,并采用了结构相关性(认为候选术语出现在标题、摘要中就更有可能是术语)来度量术语性。

表1 人工启发式规则
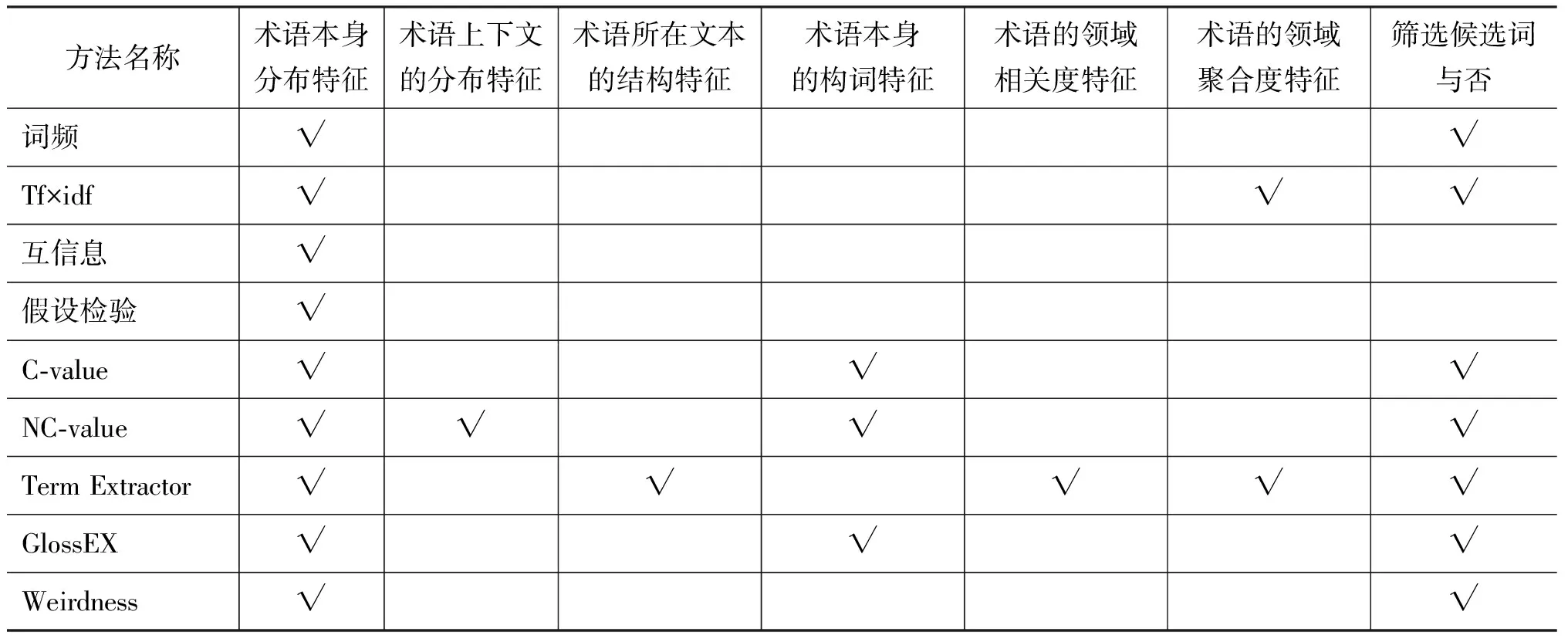
表2 各种方法所采用的特征
3 候选术语的生成与排序方法
本文所采用的术语自动抽取流程与通用流程大致相同,也有所改进。一般流程如图1所示。首先对文本进行预处理,如中文分词、词性标注、英文词根还原等;接着利用过滤规则匹配出候选术语,如名词短语(例如复合词、“形容词—名词”短语和“介词—名词”短语)等;随后利用统计、规则匹配或机器学习等方法对候选术语进行排序;最后按照某个阈值T截取前N个词,评估其抽取质量。
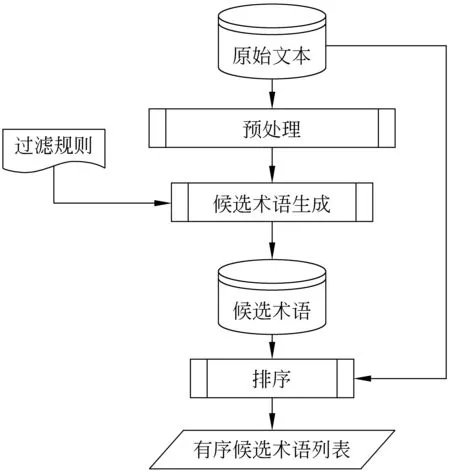
图1 术语自动抽取的一般过程
本文的过程与传统术语抽取流程的不同之处有两个: 一是在候选术语生成阶段,采用了词性规则自动生成算法,来解决规则的准确性差和领域适应性差问题;二是在候选术语排序阶段,采用了多方法的加权投票,解决排序方法的领域适应性问题。下面将介绍这两方面的改进工作。
3.1 基于词性规则自动获取的候选术语的生成
为了彻底掌握某领域中术语的词性特点,本文对大规模术语的词性构成进行了统计,试图得到一个较为真实的适应领域特点的术语规则集合。
这种方法的主要障碍是大规模的准确词性规则如何获取。但是在自由文本中,获取精确的词性模板较为困难。幸运的是,科技文献中存在大量的半结构化元数据,其中大量关键词都经过了文献作者的详细推敲,准确性十分可靠。而且这些关键词就是该领域的术语。因此获取这些关键词的词性构成规则,就是获取了术语的词性规则。
值得一提的是,有人会提出疑问,既然单独用关键词作为术语就可以满足需要了,而且大量文章的关键词其形成的术语表也会具有一定的规模,可以被应用系统使用,就没有必要进一步从自由文本中抽取。但后来实验证实,关键词虽然可以构成术语集,但是这个术语集是不完全的甚至还没达到近乎完全的地步*导致这种不完全性的原因是,一般的科技文献关键词数量都被限定在一定范围内,因此多数研究者不会也不可能将出现在文章中的细节术语都列为关键词。。这种不完全性对于某些对术语具有极强依赖性的应用系统来说,将是致命性的(如自动标引、分类等无法发现能准确代表新文章主题的的术语)。为了一定程度上克服这种不完全性,就需要术语抽取系统能够发现关键词以外的“新”术语,因此,采用本文描述的过程来抽取术语还是十分必要的。
提取关键词的过程比较简单,通过分隔符(如逗号、分号)就能对关键词串进行简单的切分提取,对应于图2中的模块(1)。为了消除关键词在“关键词”域和“摘要”域中形态不一致情况(由于关键词在“关键词”域中没有句法特征),我们对“摘要”和“关键词”的文本进行了词根还原。但在此之前,摘要文本已经完成了词性标注,对应于步骤(2)。我们采用的标注工具是Stanford的POSTagger*http://nlp.stanford.edu/software/tagger.shtml。上述预处理完成工作后,获得了三个集合: 规范化的关键词、规范化的文本以及和文本相对应的词性标注。
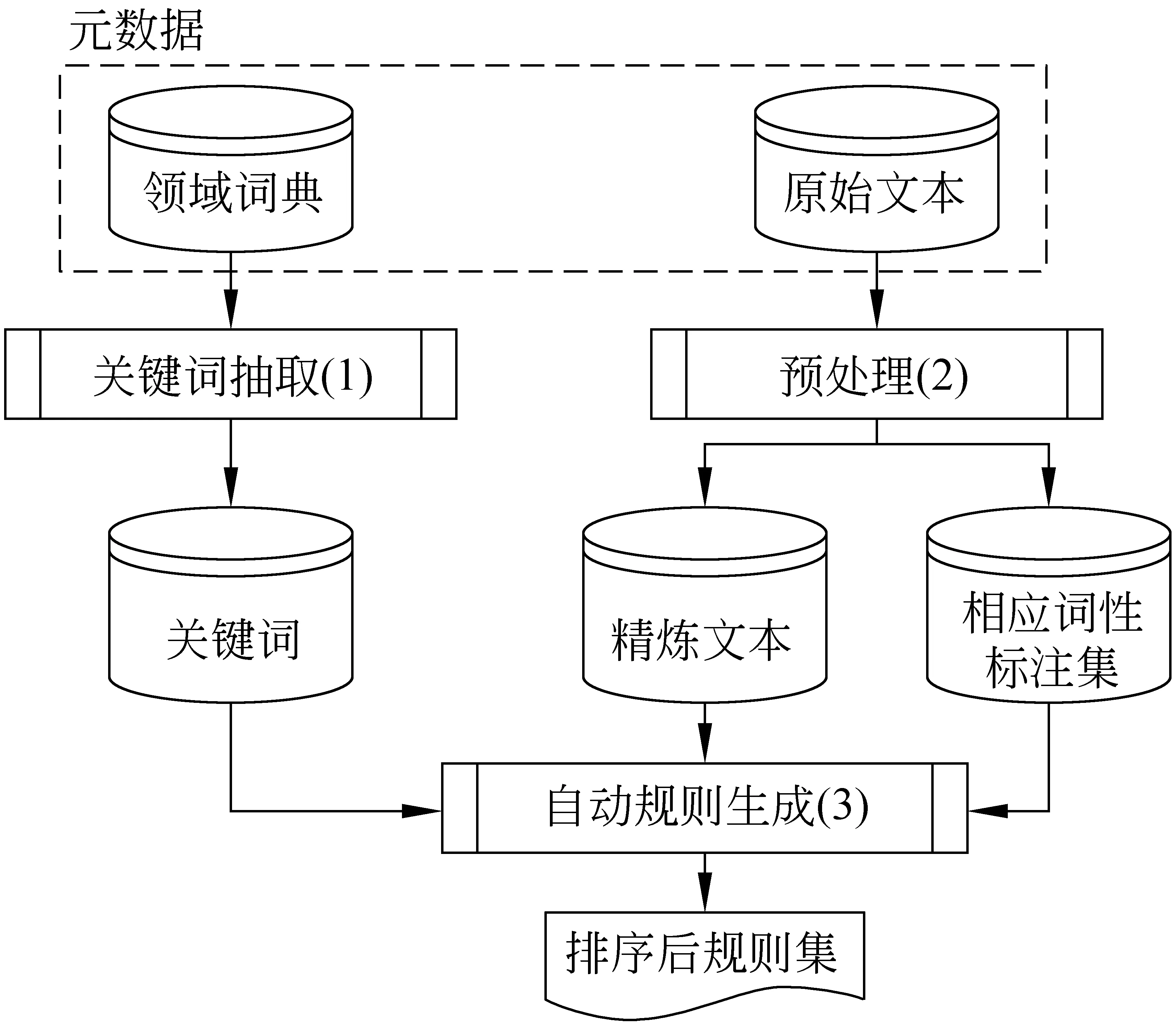
图2 词性规则的自动生成
步骤(3)是模板生成的核心算法。其思想是: 首先在文本中搜索关键词的出现位置,一旦搜索成功,就提取出该关键词的对应词性串。接着对词性串进行频率统计,并确定规则的优先级*确定优先级的目的是解决模板的冲突问题。例如具有包含关系的两个词性串,如A=JJ+NN+NN,B=NN+NN,A的优先级要高于B。如果遇到词性串JJ+NN+NN,其对应的词串为“sudden death testing”,那么就首先触发模板A匹配出这个词,然后,再触发B模板匹配出“death testing”,但是二者权重要根据模板的严格程度有所区别。A更严格,因此A的匹配更加“难得”,因此其可信度也可能高。但是,这并不绝对。。
模板生成后,剩余工作就是利用带有优先级的模板去匹配文本所对应的词性序列。为了提高搜索效率,笔者采用了先定位名词、再寻找名词前后字符串的方法。这样做的依据是,术语的最后一个词都是名词词性。随后,每一个匹配出的候选术语的边界被标示出来。
3.2 基于加权投票算法的候选术语排序
候选排序方法涉及到两个问题: 指标的选择和指标的加权投票算法。
3.2.1 选择的指标
本文选择三个指标: Tf-idf、C-value和Term-Extractor。在表2中已经列出了各种方法所采用的特征。选用方法的依据是特征之间的互补性: Tf-idf用到了单篇文档中的术语频率以及在文档集合中术语的分布特征,一般是作为各种方法的基准评判指标;C-value不仅考察了词汇的频率,还引入了具有包含关系的词串的频率对比(例如,information作为术语的出现次数 和information retrieval进行比较,如果information单独出现的频率小于information retrieval的频率,则后者的C-value值更高),是具有代表性的基于词形特征的方法;Term-Extractor是综合特征较多的一种方法。从表2中可以看出,三种方法所采用的特征类型重叠不多,将三种方法进行融合能够覆盖大多数的特征类型。
3.2.2 加权投票算法
另一个关键问题是加权投票算法。目前的投票算法有两种[9]: 少数服从多数投票和加权投票。少数服从多数的方法过于机械,本文不予采用。由于本文采用的各个方法的输出值都是实数,采用加权投票方法更适合于本文的这种指标性结果。而且,可以通过调整权重影响各个方法的作用发挥。过程如图3所示。候选术语用T表示,指标用Mi表示;每个指标的预定义权重为wi.。对于任一指标Mi来说,先计算T的得分R(T);然后将
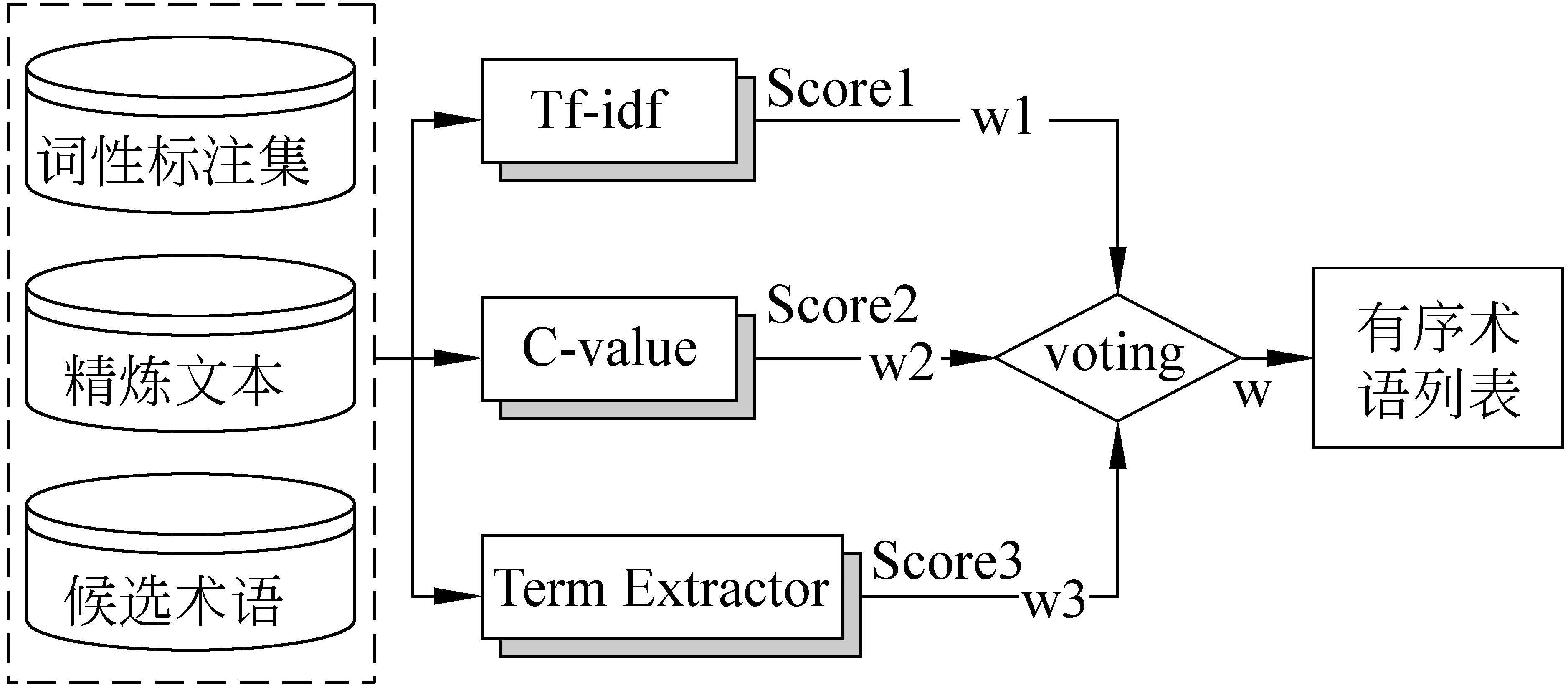
图3 加权投票算法
用ranki代表投票算法计算第i个词得出的指标值。其公式如下:
其中,k代表算法的个数,用R(ti)代表候选概念词汇t在第i个算法的排序;wi代表算法i的权重,它根据如下公式计算:
其中,Pi代表算法i的准确度。该权值的确定方法沿袭了Klein[10]的思想: 如果某个指标的准确性高,则权值wi就高,其作用就更明显;Pi值既参考每个指标在权威文章中公布的实验结果,还可通过实验确定每个权值的大小。前提是结果需是各指标根据同类型或相似类型数据得到的。今后还要研究如何通过自动验证方法确定Pi值的大小。
4 实验设计及结果分析
4.1 实验设计
本文使用了IEEE2006-2007年的5.5万条科技文献元数据。经过筛选,最后确定采用元数据中的摘要和关键词作为处理对象。经过统计发现,5.5万条元数据中,关键词总共出现了39.4万次。经过了去重、同义词消解之后,惊奇地发现,这39.4万个词实际上只包含了11.1万个互不相同的关键词,即每一个关键词大概出现了三次。
为了了解这些词汇的分布特点,我们对词汇出现的频率特征进行了简单的统计。令人惊奇的是,关键词在文本中的分布规律与Zipf 法则*http://en.wikipedia.org/wiki/Zipf’s_law十分相似,“长尾效应”十分明显: 出现1次的概念词汇共有9万个,占总数的80%,出现2次的约8 000个,占7%,而3次的占2.7%。其规律如图4所示。
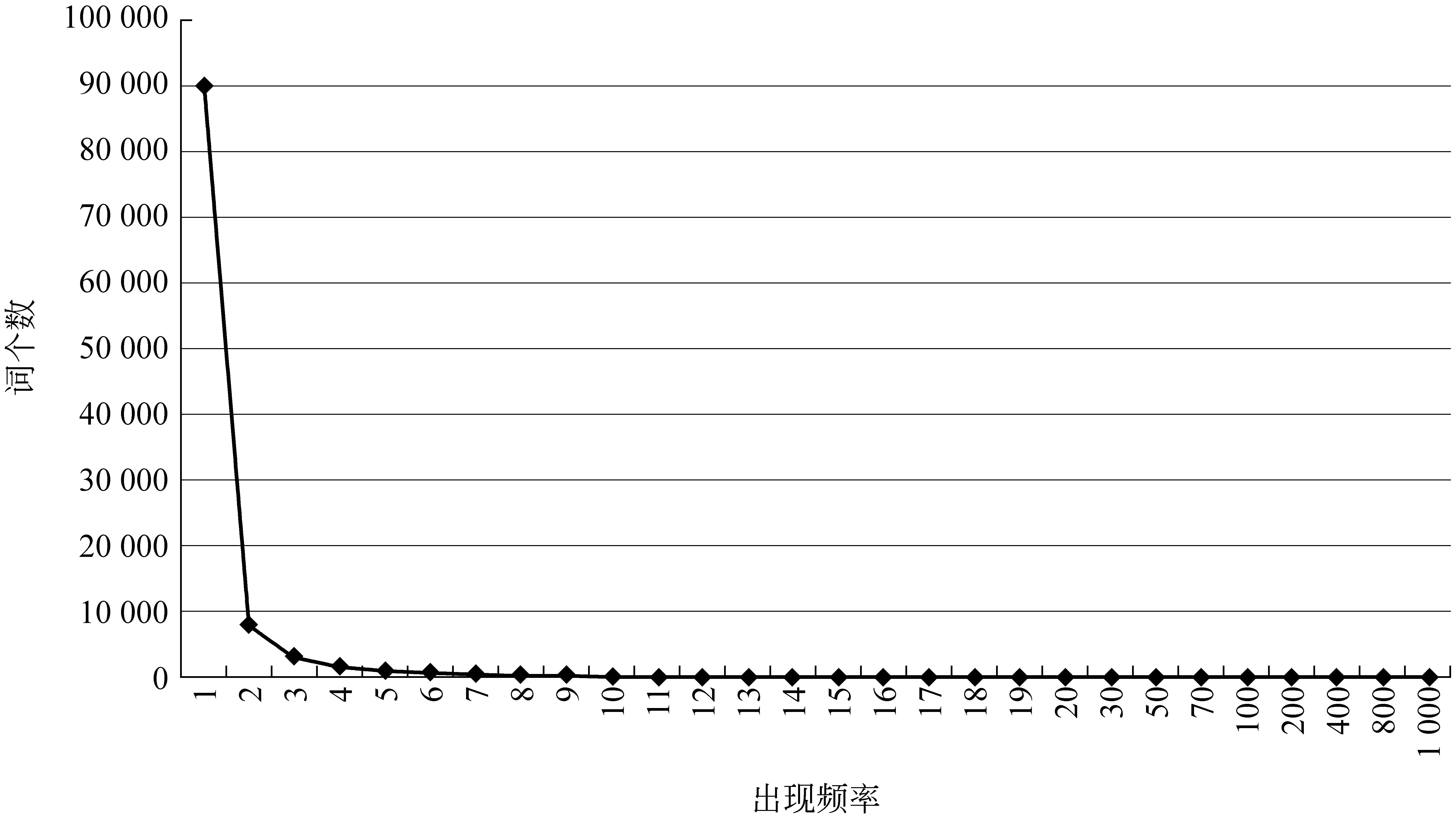
图4 关键词的分布规律
Zipf法则是自然语言文本中所有词汇的规律总结;而关键词的分布规律仅是对特定的具有一定信息量的领域术语进行统计得到的规律总结。二者的词汇范围不同,但规律却惊人的相似。这可能说明,在特定领域的文本集合中,有意义的概念的分布也可能遵循某一个类似Zipf定律的分布法则。将来可能指导更加深入的研究。在本文中暂且不做探讨。
自动抽取系统主要分为三个处理模块: 预处理模块,用来进行词根还原、同义词消解、词性标注;模板生成模块,用来自动获得词性模板,并确定模板的匹配优先级;排序算法,用于对候选术语进行排序。
在预处理方面,为了使词汇的词根还原更准确,我们选定了外部词典WordNet*http://wordnet.princeton.edu/作为词根还原的主要依据。
另外,还应用了WorldNet的同义词集(一个同义词集表示同一个概念)来识别同义词。其办法是,遇到任意两个词,如果他们被收录在同一个同义词集中,则认为他们是用来表达同一个概念的同义词。该假设的前提条件是两个词出现在相同领域中。因为笔者认为,在特定领域中,词汇表达的概念单一,歧义性较弱,因而词义可以由同一个词代替。
本文还选择了POSTagger作为词性标注的工具。面对本领域,我们尚未构建自己的训练样例,因此,POSTagger使用Wall Street Journal样例训练出的标注模型完成本文的词性标注工作。结果发现,标注的结果很好。原因可能是科技文献中的语言较为严谨,错误较少,IEEE科技文献中的词语虽然专业,但算不上生僻。
投票算法对三个算法采用相同的权重进行加权,即每个权重值都是1/3。
结果的评价采用的是P@N和UAP(Un-interpolated Average Precision)[11]。
4.2 实验结果及分析
表3反映了经过统计之后的部分高频和低频术语。从结果中可以看出,高频术语通常具有更加广泛的含义,属于较为宽泛、 涉及面较广的高层概念;而低频术语由于其限定多、意义窄,经常出现在某些特定环境中,而这种特定环境属于个例,并不多见,因此,这些词汇的意义通常非常具体,属于较低层的概念。这个规律也启示了作者,传统的基于词频的方法有可能忽视80%的低频词群体,因而我们应该采用多种特征,更加客观和全面地考察候选术语。
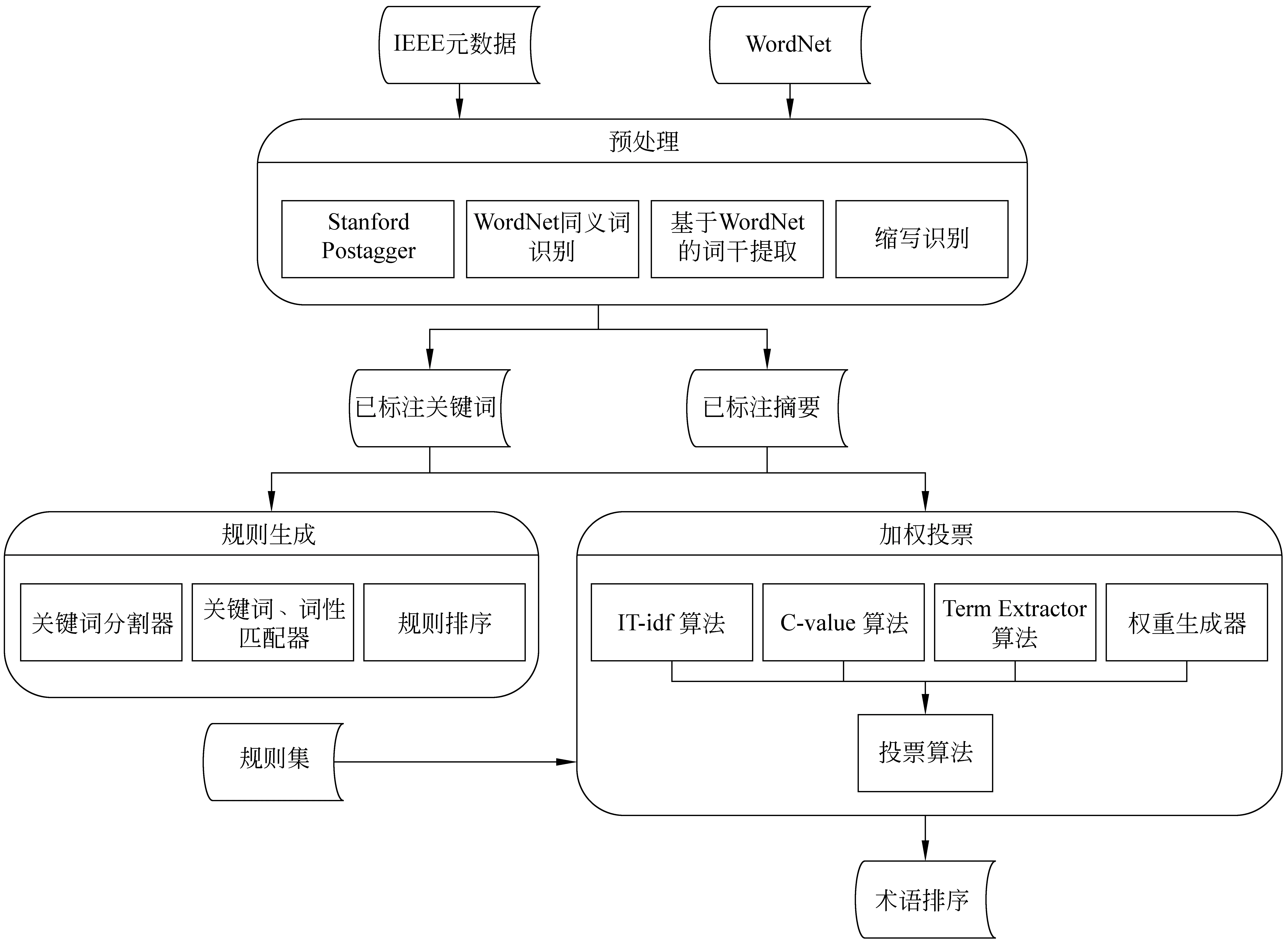
图5 自动术语抽取系统框架
表3高频和低频术语举例
表4显示了部分自动获取的高频词性规则。按照规则的频率由高到低排序为: (NN NN)>(JJ NN NN)>(NN NN NN)>(JJ NN)>(JJ NN NN NN)>(JJ JJ NN)>(NN NN NN NN)。可见,关键词中术语模式以名词性短语为主。该条规律同Frantzi[6]和Fahmi[7]的人工指定的词性规则基本一致。但是,由于他们采用的规则集合是由正则表达式生成的,没有对模板进行优化筛选,因此错误地引入了很多噪音词。本文提出的自动获取方式克服了人工指定规则的不准确性影响,减少了噪音规则的个数。
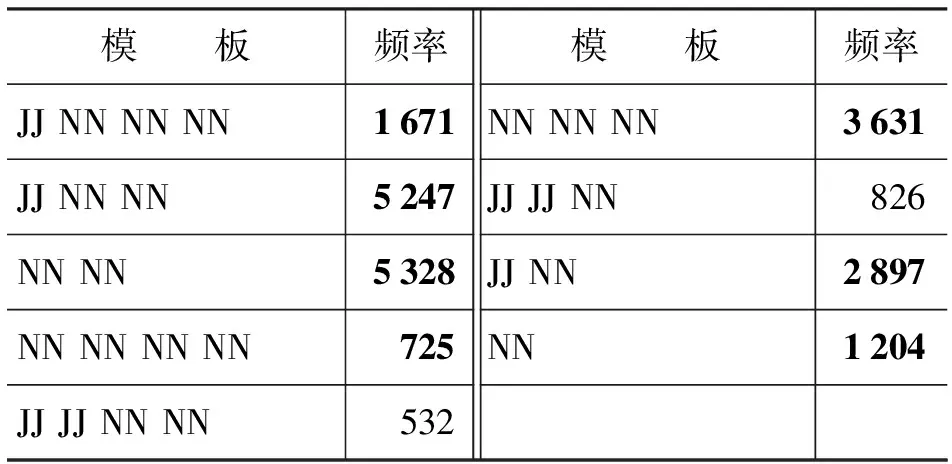
表4 自动生成的词性模板
实验结果生成的词性规则数量很多,达到了700多个。但是并不是所有规则都被用来进行候选概念词汇抽取,而是通过频率截断来筛选高可信度规则。而且,模板集合也由于词性标注的不准确性引入了噪音。这些噪音一般是偶然事件,因此也可以通过频率筛选过滤掉。
表5显示了在摘要中命中的部分候选术语。规则匹配方法命中效果较好,候选术语的质量比较高,但是,不可避免地产生了噪音和错误,例如Indian Market虽然满足”JJ NN” 词性模式,但不是术语;又“如JJ JJ NN”虽然是合理的词性模板, 但词性标注的不准确性导致“random key predistribution” 中的“key”被错误标注为形容词JJ。但是,这尚未影响抽取结果的准确性。接着我们采用了三种指标混合的方法对候选概念词汇进行可信度排序,还与各种单独指标进行了比较,结果如表6所示。
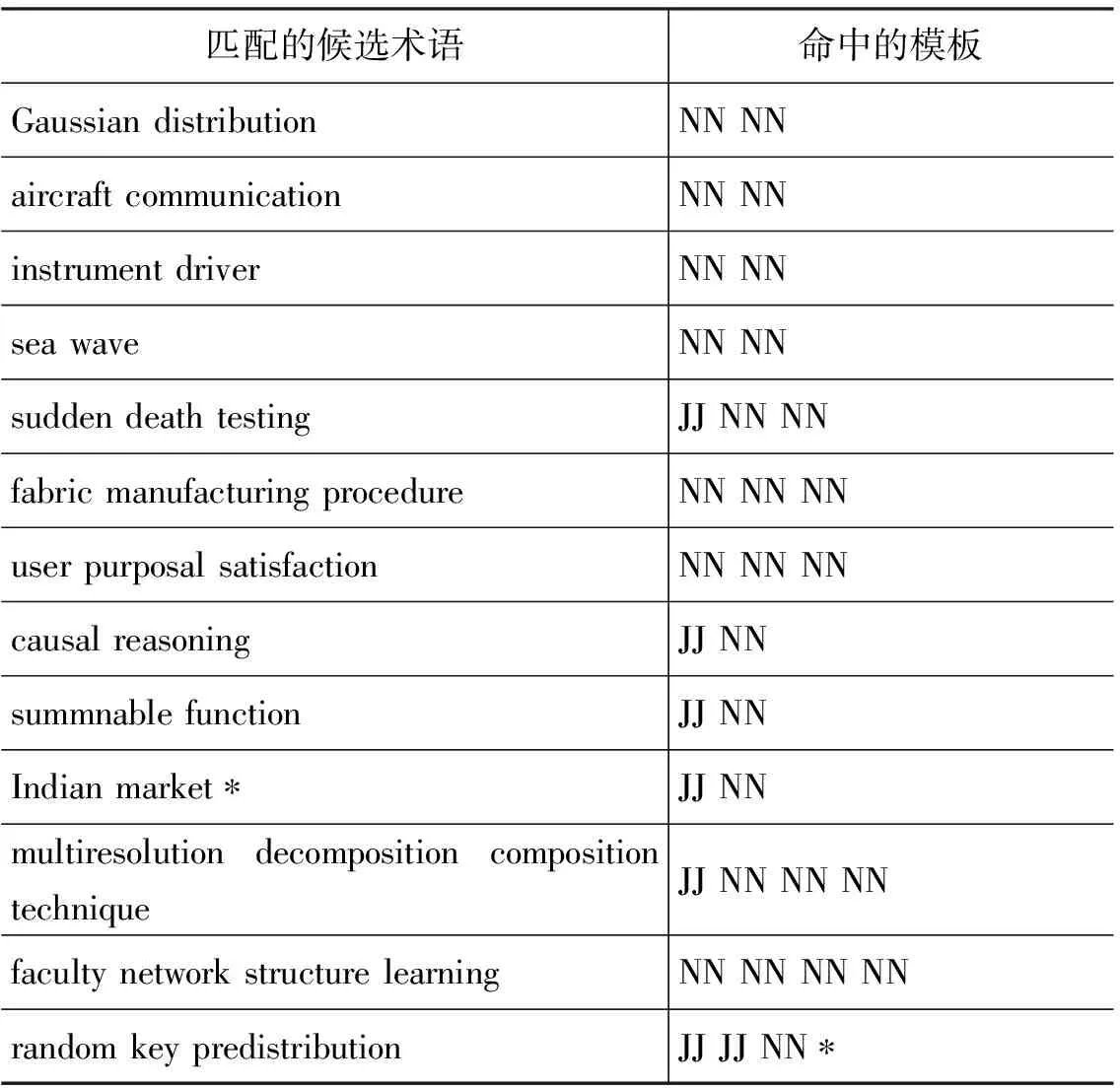
表5 命中模板及候选术语举例

表6 识别算法的比较/%
比较表6 中的不同方法可以看出,Tf-idf、 C-value和 Term Extractor在前100个词汇的准确率都能达到90%以上。但在前1 000个词汇中,其准确率下降速度不同,C-value的衰减速度最慢,而Term Extractor的衰减速度最快,准确率比前两种要低。基于加权平均的方法虽然衰减速度一般,但是随着截取的词汇的数量的增加,准确率衰减速度很慢,能够保证在大规模关键词提取时具有较高的可用性。可以看出,基于加权投票的识别算法是一种可用的方法。
经过观察,发现新抽取出的词汇与关键词、自由词中的某些词汇具有一定的语义相似性,因此可以考虑将相似性判断作为提高结果准确率的方法。该方法将在以后详细阐述。
5 结论与展望
本文通过实验,证明了基于多指标加权投票方法的有效性,也验证了多特征融合思路在术语识别任务中的正确性。从实验结果中可以看出,C-value仍然是综合效果较好的一种方法。投票算法本质上是对C-value方法进行了特征补充。
一般来说,在加权算法中,某种效果较差的方法能够降低整个算法的效果。导致这种情况产生的前提是评价结果集中的所有输出的正确数比例,而不考虑结果中的排序。而本文的评价策略采用的是P@N(结果数量巨大,难以评价整个候选术语列表),而不是评价整个结果集。因为正确的结果在排序中更加靠前而且紧凑,所以经过投票,抽取效果看上去还是得到了提升。
分析实验的中间结果,还说明利用WordNet进行同义词识别具有一定实用性。而基于准确关键词的模板自动生成方法,确实能够得到足够准确的词性模板,经过与人工定义模板简单比较发现,模板的带来的词汇噪音较少。
本文的ATR方法仍然有改进空间。投票算法目前采用的是等权重加权,将来还会尝试多种权重组合,并改进现有的基于准确率值的权重确定方法。本文尚未明确比较人工模板和自动模板的抽取效果。未来还要将本文所采用的三种方法所涉及的所有特征融合为一体,形成一个新算法,并充分考虑特征之间的关系,来完成识别任务。相信特征的有机结合将会促进识别效果获得进一步提高。
[1] Frantzi K. T., Ananiadou S. The C/NC-value: domain independent method for multi-word term extraction[J]. Journal of Natural Language Processing. 1999, 6(3):145-180.
[2] Kageura Kyo, Umino Bin. Methods of Automatic Term Recognition: A Review[J]. Terminology,1996,3(2): 259-289.
[3] Sclano, F., and Velardi, P. Termextractor: a web application to learn the shared terminology of emergent web communities[C]//Proceedings of the 3rd International Conference on Interoperability for Enterprise Software andApplications[C] (I-ESA 2007). 2007.
[4] Kozakov L., Park Y., Fin T. H., Drissi Y., Doganata Y. N., Cofino T. Glossary extraction and knowledge in large organisations via semantic web technologies[C]//Proceedings of the 6th International Semantic Web Conference and the 2nd Asian Semantic Web Conference (Se-mantic Web Challenge Track), 2004.
[5] Mima H., Ananiadou S. and Nenadic G. ATRACT Workbench: An Automatic Term Recognition and Clustering of Terms, in Text, Speech and Dialogue[M]. Lecture Notes in AI. Springer Verlag, 2001:2001-2166.
[6] Frantzi Katerina,Ananiadouy SoPhia, MimazHideki. Automatic Recognition of Multi-Word Terms: TheC-Value/NC-Value Method[J]. International Joumal on Digital Libraries,2000.
[7] I. Fahmi. Incorporating dependency relation for multi-word term extraction[J]. TABU Dag, 2005.
[8] Salton G, McGill M. J. Introduction to modern information retrieva[J]. McGraw-Hill, 1983.
[9] Sinha R., Mihalcea R. Unsupervised graphbasedword sense disambiguation using measures of word semantic similarity[C]//ICSC ’07: Proceedings of the International Conference on Semantic Computing. Washington DC, USA: IEEE Computer Society, 2007:363-369.
[10] Z. Zhang, J. Iria, C. Brewster, F. Ciravegna. A Comparative Evaluation of Term Recognition Algorithms[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation.Marrakech, Marocco, 2008.
[11] Schone, P., and Jurafsky, D. Is knowledge-free induction of multiword unit dictionary headwords a solved problem?[C]//Proceedings of Empirical Methods in Natural Language Processing.2001.
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年12期)2022-08-19
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
中国卫生(2015年9期)2015-11-10
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
