
基于核方法的文本极性分类研究
2011-05-25 03:36陈发鸿
海峡科学 2011年8期
陈发鸿
基于核方法的文本极性分类研究
陈发鸿
中共福建省委党校
该文研究文本极性分类算法优化问题。目前算法多以计算词的极性进行文本极性分类,由于不能保证词的主题相关性,导致文本情感分析准确率较低。为了提高分类精度,该文提出一种新的文本极性分类方法,首先用tf/idf算法抽取主题词确定文本主题句,然后对句子进行句法分析,并利用核函数设计基于词特征、词义特征以及句法特征等多特征融合的句子极性计算方法,通过分析情感主题句的极性进行文本情感倾向的判断。新方法不仅考虑了词本身的极性,还根据核函数区分词的动态极性,同时避免与主题无关的句子对分析结果的影响,进行实验与其它分类算法作比较,证明新方法能够有效提高文本情感分析的准确率,可为设计提供实用有效的算法。
核函数 句法分析 主题句 极性分类 情感分析
1 引言
文本极性分类主要是指利用计算机自动分析带有主观性的句子或文档,对它们的情感倾向进行分类,从而判断出用户的态度[1]。文本极性分类近年来已经成为自然语言处理领域的热点问题,目前所采用的方法主要有两种。第一种是基于机器学习的方法,首先将具有情感色彩的词分成是正例和负例,然后以词频统计基础,建立一个二元的分类器,从而进行简单的情感分类;另一种是基于语义的情感分析方法,首先进行相关词的语义倾向分析,然后计算整个文本的情感倾向指标。例如,文献[2] 计算文本中词汇与HowNet中已标注褒贬性词汇间的相似度,获取词汇的极性。在此基础上,选择极性明显的词汇作为特征值,用SVM分类器分析文本的褒贬性。最后采用VSI否定规则匹配文本中的语义否定,以提高分类效果,以及处理程度副词附近的褒贬义词,以加强对文本褒贬义强度的识别。文献[3] 通过标记语料库获得文本中的极性元素,然后采用极性元素的分布、极性元素的密度和极性元素的语义强度三个度量指标来对每个文本进行统计,得出文本褒贬分类和强度大小的结果。文献[4]通过分析文本中的情感词以及由这些情感词构造的短语模式,作为文本的情感特征,并利用这些特征实现文本的情感判别。文献[5]利用HowNet提供的语义相似度和语义相关场计算功能,计算词语间的相似程度,根据所得的语义倾向度量值判别其褒贬倾向,进而进行文本的倾向性分析。
这些方法多是单纯从词的倾向性分析入手,但是以词为粒度的情感分析,不能保证所有被分析的词汇都是主题相关的,这种不确定性将直接影响文本情感分析的准确性。如果在进行文本的情感分析时,将与主题无关的词语或者句子剔除,仅仅只对与文本主题相关的句子或词语进行分析,将有助于提高情感分析的准确率。
基于以上的分析,本文以句子为例,主要研究如何有效提取文本中的主题情感句,设计并利用核函数通过计算相似度对情感主题句进行情感倾向判断,从而获得文本的情感倾向,排除与主题无关的情感句对判断准确率的影响。
2 系统的原理依据
本文实现了文本情感主题句的自动抽取和基于核函数的多特征融合句子倾向性分析,最后进行文本倾向性的判断。主要通过以下几步进行:首先,用tf/idf算法抽取主题词,然后对主题词进行语义逻辑推理,将包含语义含义主题词的句子作为候选主题句子,通过公式计算各个候选句子的重要度,最终确定文本情感主题句;然后对主题句子进行句法分析,通过多特征融合的核函数计算得出主题句倾向度;最后累加主题句倾向度进行全文的文本倾向性判断。具体框架如图1所示。实验结果表明,由于考虑了词、词义、句法等特征,句子倾向性分析的召回率和精确率有显著的提高,并且计算整个文本情感倾向时排除了与主题无关的句子,从而也提高了算法的准确率。
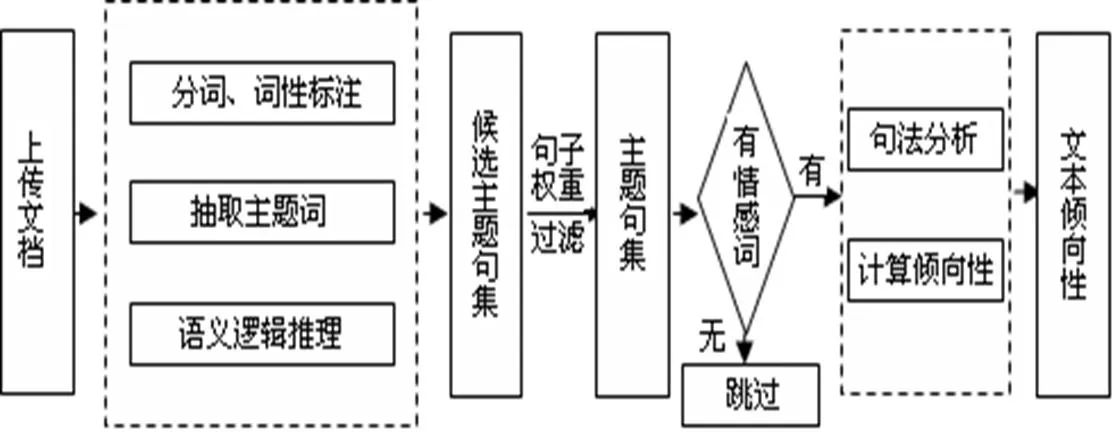
图1 系统框架图
3 系统的实现步骤
3.1 主题词提取
主题词即指能够体现某个文本的主题属性,并具有使之与其它主题有明显分别的作用的词。本文对所有训练语料进行分词、词性标注后,提取所有的名词,接着采用类似TF-IDF的词频统计方法计算每个词条Ti的权重Wi,公式如下:
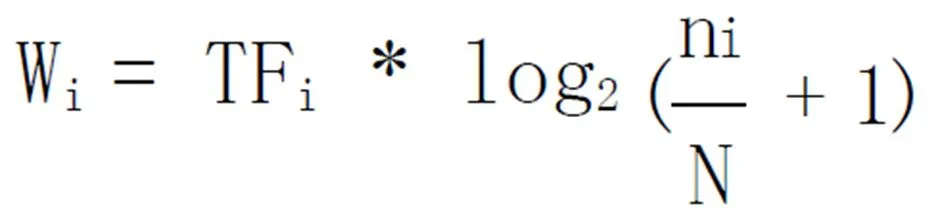
其中TFi是词条Ti在文档中的词频,在统计词语出现次数时,考虑到文档中不同位置内容的重要性各不相同,因此通过分配适当的比例因子来对词频进行加权调整。N为文档中的句子总数目,ni是文档中包含Ti的句子数目。
采用上述方法计算出文档中所有词条的权重,并进行归一化处理,使得词条权值介于0和1之间。权值越大,则越能反映文档的主题。将词条按权值从大到小的顺序排列,依次选取前面适当数目(文中选前15个)的词条作为该文档的主题词,然后结合领域背景,构建概念语义网络,对所得到的主题词进行语义逻辑推理,最后将所有包含符合语义含义的主题词句子作为候选主题句子。
3.2 句子重要度计算
为了从候选集合中最终确定文本的主题句子,需要对句子重要程度进行评估计算。本文以抽取的主题词义项建立向量空间模型(VSM),并对所有待处理的候选主题句子建立对应的向量S(T1,W1;T2,W2;...;Tn,Wn),其中Ti为句中包含的主题词,Wi为词条Ti的权重值。文档中句子的重要性主要受以下几个因素的影响:(1)句中所含主题词的重要性。若主题词权重之和越大,则认为句子的重要性也越大。同时为了消除句子长度的影响,本文采用了平均权重以避免句子越长、权重越大的现象。(2)句子在文档中的位置。研究表明,95%以上的科技文献和大多数的其他文献的标题能很好地反映主题,因此一个词如果出现在标题中,那么它成为文献主题词的可能性就大得多,并且根据汉语的习惯,在首段或末尾段通常会对主题做一个总结,因此标题、段落开头和结尾处的句子应该有较高的重要性。(3)句中是否包含提示词。对于一些议论或评述性的文章,常包含“综上所述”、“总之”等提示性短语,这些句子往往是对文章主题进行的概述,因此重要性相对较高。
综合考虑上述因素,本文定义句子权重的计算方法如下:
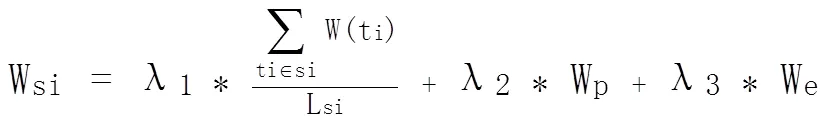
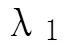
3.3 基于核的情感主题句极性分析
核方法的基本思想就是在非线性可分的情况下,使用一个非线性变换φ(∙)将样本空间R中的数据映射到高维线性空间F中,即R→F,在F中基于准则构造新的分类函数,达到线性可分的目的。若算法中各模式矢量间的相互作用仅限于内积运算,则不必显式计算从样本到高维线性空间的映射,只要利用样本空间中预先定义的核函数直接计算映射空间中的点积即可,从而解决非线性变换带来的“维数灾难”问题。
在自然语言处理领域中,核函数的本质是计算两个样本间的相似度,相同类别的样本具有较高的核函数值,不同类别的样本具有较低的核函数值。本文从词语、词性、语义以及位置等方面考虑了输入样本的特征,定义了词语核函数,词序列核函数,路径核函数,通过核函数计算样本间的相似度以完成句子极性的判断。
3.3.1相关概念
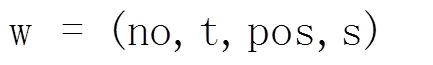
其中,no代表当前词在句中的位置;t代表原始词语字符串输入;pos代表词性;s代表词汇的极性(1代表褒义,-1代表贬义,0代表中性)。
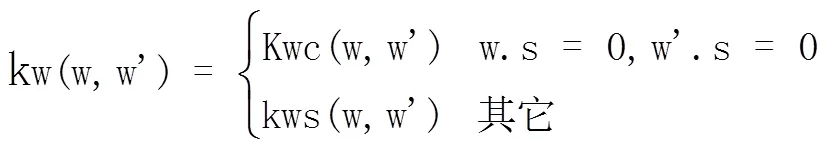
其中,
,为词语内容相似度;
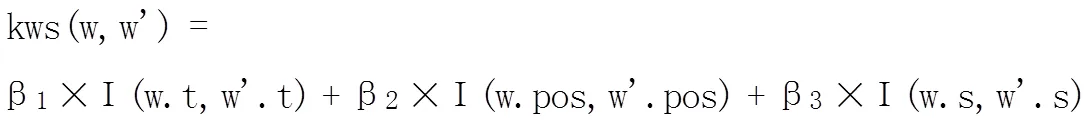
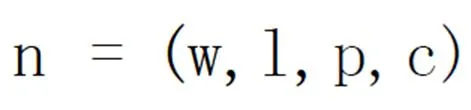
其中w是该节点中的词;l是该节点与父节点的依存关系;p是父节点;c是当前节点的子节点集。
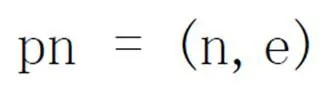
其中n代表该路径节点所包含的当前句法分析树节点;e代表当前节点与下一个节点的依存方向(1代表当前节点依存于下一个节点,0代表下一个节点依存于当前节点)。
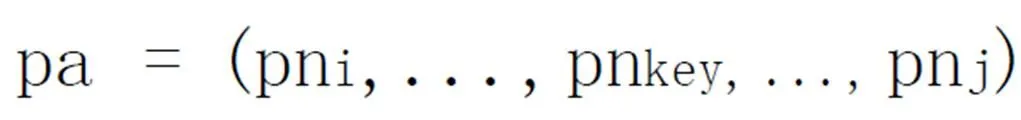
其中,pnkey代表路径中的一个极性词,相对于其它节点,该节点将更大程度地影响两条路径的相似性。
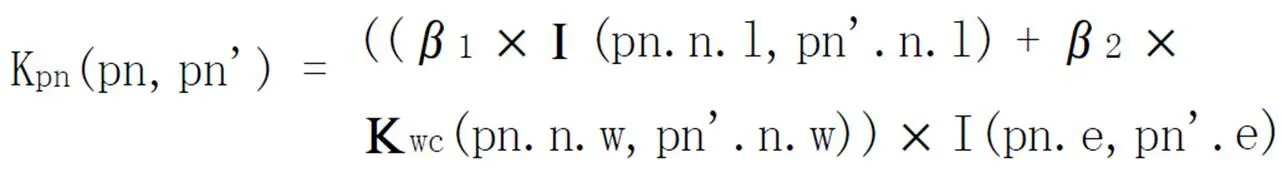
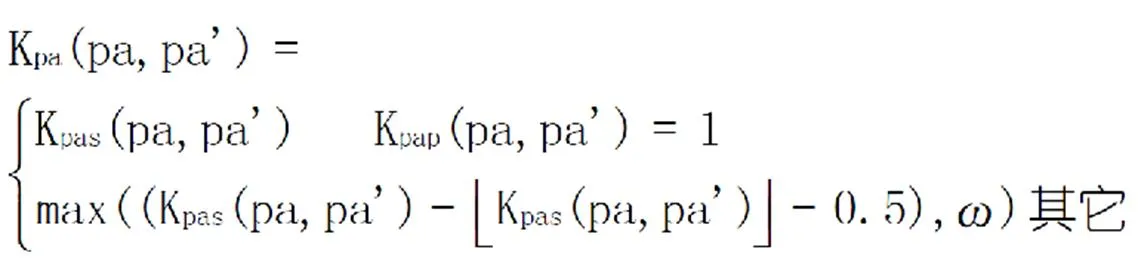
其中,

其中,wkey代表极性词,相对于其它词而言,wkey更多地影响seqn之间的相似度。
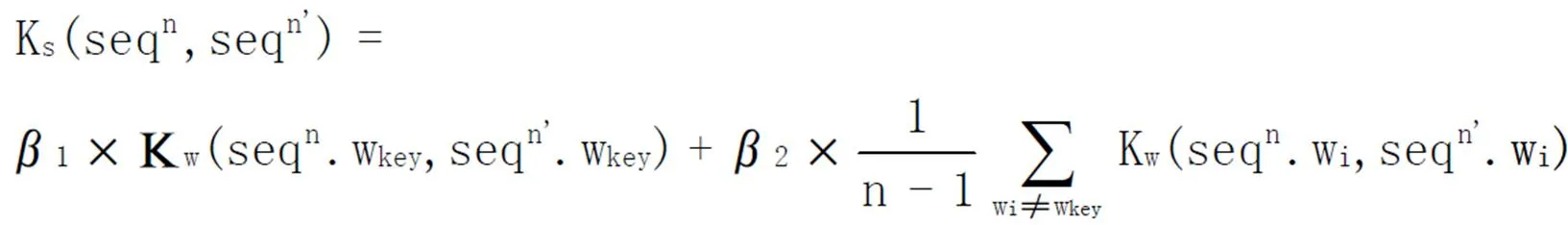
例如:句子“奥迪外观漂亮,性能好,我喜欢”根据定义10有三个极性词,其所对应的2元词序列及其3条句法路径如表1所示。图1是例句句法分析的结果。
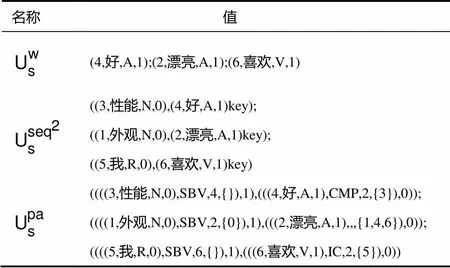
表1 例句的极性词以及2元词序列、句法路径集合
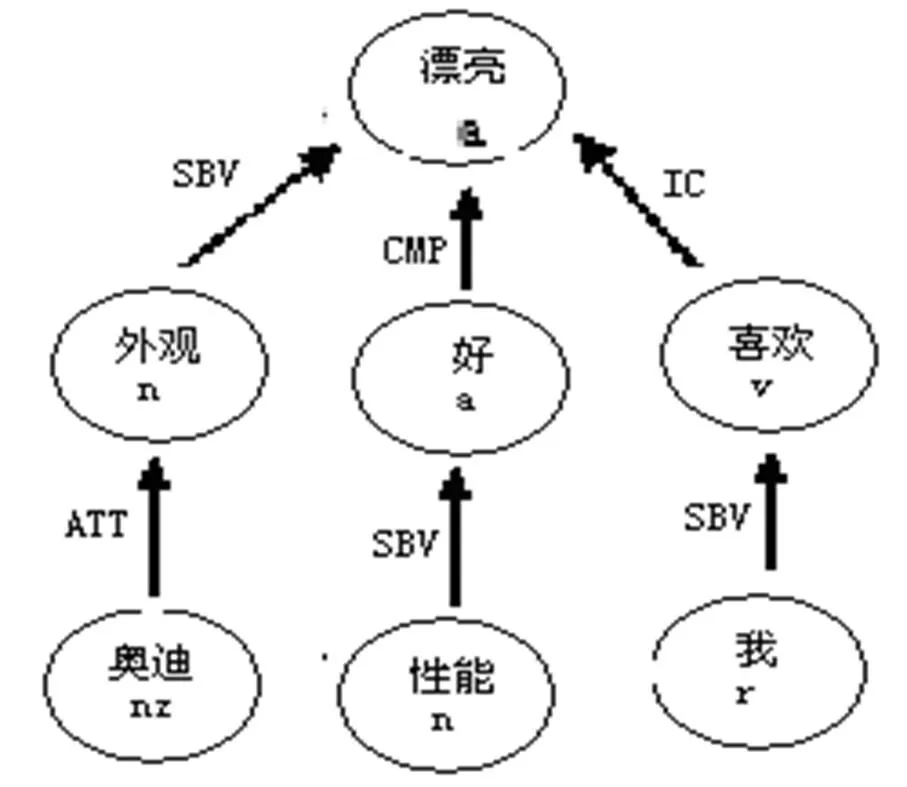
图1 例句句法分析的结果
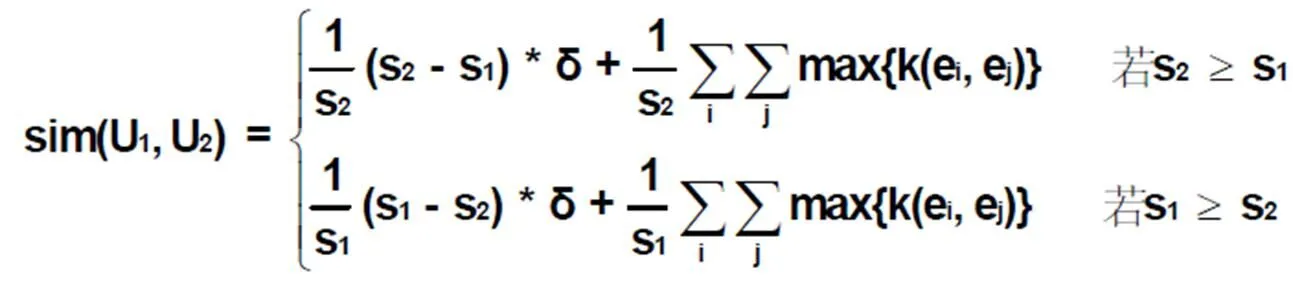
其中,ei∈U1, ej∈U2,s1代表集合U1的元素个数,1≤i≤s1;s2代表集合U2的元素的个数, 1≤j≤s2;δ是一个很小的正整数,它代表一个非空元素和空元素的相似度。K(ei,ej)代表集合中两个元素之间的相似度,根据元素类型的不同分别按公式(4)、公式(9)和公式(11)计算。
3.3.2基于核的多特征融合极性分类算法
为了从文本的主题句集合Q中提取情感主题句,本文借助情感词词典,逐一找出具有极性词的句子,同时利用Deparser对句子进行句法分析,并设计词语核函数,词序列核函数,路径核函数,分别从词法、语义、句法层方面对情感主题句进行倾向性的判断。三个核函数分别表示如下:
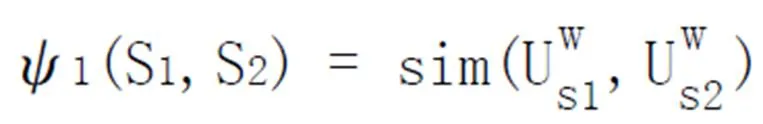
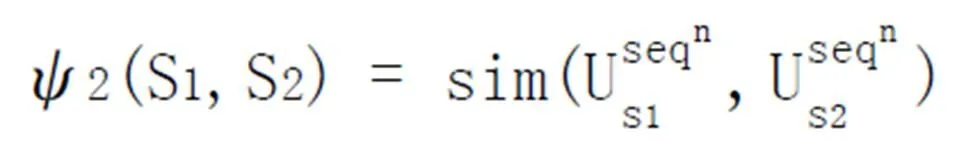
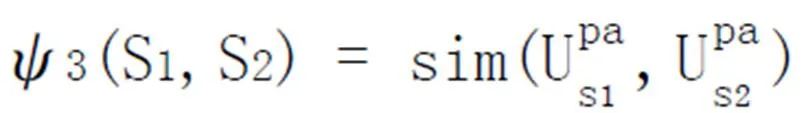
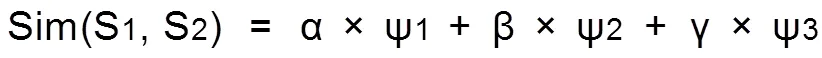
本文实验根据经验并结合实验结果调整,选取α=0.5,β=0.4,γ=0.1作为相似度的计算权值。
例如,句子S1“我很喜欢苹果”和句子S2“我非常喜欢苹果”的极性相似度计算如下:
同理,句子S1和句子S3“我不喜欢苹果” 的极性相似度计算为(因为句子S3的极性词前出现了否定词,所以需要对极性词“喜欢”极性取反后再按公式计算):
4 实验
4.1 实验语料
本文实验从新浪汽车论坛(http://bbs.auto.sina.com.cn/)有关汽车评论的主题贴中,去除语言不规范的文本,最终选出文本1200篇。将所有语料分为2个部分,其中800篇作为语料,其余400篇作为测试语料集合T。手工对测试语料集中的所有文本提取情感主题句,并标注情感倾向(正面或反面),同时标注每个文本的全文情感倾向,标注结果中,218篇为正面倾向文本,182篇为反面倾向文本。
4.2 实验分析
本文进行2次实验。
实验1:目的是评估本文提取情感主题句方法的性能。首先对训练文档集中的文本进行人工聚类,筛选出正、负两个类别共162个句子作为基句,然后从测试文本集中选出3190个句子作为测试句子(正面句子2134个,反面句子1056个),对每一个测试句子分别按公式(16)和基句计算极性相似度,选取相似度最高的基句极性作为该句的极性。评价指标采用标注精确率(P)、召回率(R)和F值。为了说明方法的有效性,本文还与文献[6]所介绍的基于极性词词频统计的方法进行了比较,实验结果如表2所示。

表2 本文方法和文献[6]方法的比较
实验结果表明,本文方法的查准率达到了72.8%,F值达到了74.3%,和文献[6]方法相比F值提高了近15%,性能提高显著。
上述实验数据及分析表明,文献[6]召回率较低,原因是该方法只是通过简单的极性词正负叠加来计算句子的情感类别导致一些反面倾向句子标注错误,如:句子“凯越HRV驾驶的时候,门窗是不会自动上锁的,这是一个很不安全的设计。”和“存放备胎的地方也发现了不和谐的声音”。而本文方法不仅考虑了极性词本身,还根据句法分析从上下文和句法层面捕获极性信息,能从一定程度上区分词的动态极性,从而提高了分类准确率。例如,“我为我们的祖国感到骄傲!”中“骄傲”为褒义词,“这个人很骄傲!”中“骄傲”为贬义词。
但是,考虑到算法的复杂性,本文没在整棵句法树上定义核函数,而是从句法子树来分析极性,因此对一些中性语句不能很好地识别,如:句子“奥迪A6的价格既不高也不低”。该句的局部带有极性,情感“不高”的极性为正,“不低”的极性为负,本文算法认为该句为正极性,但事实上该句总体极性为中性。此外,算法也没处理语气问题,其分类准确率还有进一步的提升空间。
实验2:目的是评估本文方法对文本情感分析判断的影响。首先采用本文方法提取文本的情感主题句,将提取的结果应用到传统SVM分类器,对文本的情感进行分析。同时,采用传统SVM分类器直接对文本进行情感分析,将这两种方法的情感分析结果进行比较。

表3 本文方法和SVM方法的比较
由于本文方法首先去除了与主题无关的句子,排除了这些句子对整个文本情感判断的影响,直接对与主题相关的情感句子进行判断,因此与传统SVM分类器相比,其准确率提高了近11%,F值提高了9%,实验结果证明了本文方法的有效性。
5 结束语
本文提出了基于核函数的多特征融合中文文本极性分类方法。通过语义逻辑推理确定文本主题概念,结合句子重要度计算,确定文本的主题句子。并定义核函数,融合词、词义及句法特征对情感主题句进行倾向性的判断。情感主题句的提取研究对意见挖掘、情感分析等研究具有重要意义。在后继的研究中将对句子进行进一步的语法、语义分析,提高模型的性能。
[1] 史西兵,王浩鸣.隐马尔可夫模型解决信息抽取问题的仿真研究[J].计算机仿真,2010, 27(5): 132-134.
[2] 徐琳宏,林鸿飞,杨志豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007, 21(1): 96-100.
[3] B. Tsou, et al. Polarity Classification of Celebrity Coverage in the Chinese Press [A]. In: Proceedings of the International Conference on Intelligence Analysis [C]. McLean, USA: 2005.
[4] 宋光鹏. 文本的情感倾向性分析研究[M]. 北京:北京邮电大学, 2008.
[5] 朱嫣岚,阂锦,周雅倩,黄置普,吴立德.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):l4-20.
[6]M.Hu and B.Liu.Mining and Summarizing Customer Reviews.InProceedings of the ACM SIGKDD International Conference on Knowledge Discovery&Data Mining[C].Seattle,Washington,USA,Aug
猜你喜欢
开放教育研究(2020年2期)2020-03-31
时代英语·高一(2019年5期)2019-09-03
现代语文(2016年21期)2016-05-25
电测与仪表(2016年11期)2016-04-11
电源技术(2015年5期)2015-08-22
大连民族大学学报(2015年2期)2015-02-27
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
沈阳医学院学报(2014年4期)2014-12-27
疑难病杂志(2014年12期)2014-04-16
