
基于自然语言理解的智能化多媒体信息检索系统研究*
2011-05-17 09:09师东生
网络安全与数据管理 2011年6期
师东生
(内蒙古科技大学信息工程学院,内蒙古 呼和浩特 014010)
信息检索 IR(Information Retrieval)是指把用户所需信息按一定的方式组织起来的过程和技术[1]。传统的方式是用户通过输入关键字,从大量的文本库中检索出满足需求的文本,来判别文本是否相关并对相关文本进行排序的数学模型。然而随着网络的发展,信息资源不再以单一的纯文本传递为主,越来越多的信息资源以其他多媒体形式存储,如图像、视频、音频等,针对多媒体信息的检索近年来逐渐成为多媒体信息检索领域的研究热点[2]。参考文献[3]提出了基于本体信息检索系统的框架,该系统能够提取和利用网络上的语义信息,根据用户的检索条件进行推理,进而得出较为准确的结果;参考文献[4]提出了基于方法聚类的Web服务检索技术,该技术充分利用Web服务的描述信息生成基于方法层的Web服务建模方法,通过服务类聚算法产生基于方法层的服务检索模型及其相关算法;参考文献[5]提出了基于Web的智能信息采集处理系统,采用高效的URL去重和基于模版的下载机制,提高了采集Web资源的性能,并应用自然语言处理技术,对采集信息做智能分类和摘要,在发布上突出个性化的信息服务;参考文献[6][7]阐述了多媒体信息检索技术的发展现状。然而其研究仍存在以下不足:(1)搜索方式单一,信息相关性差;(2)不能准确地把握用户需求,容易产生搜索歧义;(3)搜索技术不具备智能化,搜索效率不高。为了解决上述问题,提出了基于自然语言理解的智能化多媒体信息检索系统IMIRSTNLU(Intelligent Multimedia Information Retrieval System based on The Natural Language Understanding)。
1 IMIRSTNLU模型概述
在该模型中,对多媒体信息的检索效果由词语分析和搜索服务共同决定,只有对多媒体信息词语分析准确,搜索服务才能够快速查找到与多媒体信息资源库中最贴近的资源,从而提供最贴近用户需求的多媒体信息。
该系统首先基于多媒体信息的资源分类,即通过对多媒体信息资源的自然理解,结合语言学和语义学学科知识、专家知识及信息资源管理模式等,对多媒体信息资源在语义和知识层面上进行挖掘,训练成文本、视频、图像和音频四种常见格式的知识库[8]。
检索服务开始时,首先对用户输入的词语进行词语分析,挖掘出与用户输入词语相关度高的辅助语义,并提供给用户以确定最终检索语句。开始检索时,针对词语分析确定的语义条件,对知识库中的知识元采取相似度匹配方法,对多媒体信息的所有知识库启动二级搜索模式,即精确搜索和模糊搜索相结合。精确搜索某一模式知识库时,对另一模式知识库进行模糊搜索,若查找无结果,模糊搜索快速启动成为精确搜索,同时产生模糊搜索对未搜索知识库进行搜索。该方法针对用户输入词语进行词语分析,有效地提高了检索的准确率;对知识库的二级模式搜索,有效地提高了检索的效率。
检索结束后,对检索结果进行综合处理,去除无效链接、空链接及冗余数据等,依据与用户检索词语关联度的高低排列知识库中的资源记录,用户也可设定排列模式,如时间等。同时对检索情况的处理结果,如某一知识元按照用户检索习惯,应分类于哪一类知识库,更新多媒体信息资源的知识库。与此同时,保存用户的检索记录于用户资源列表,以便于下次检索生成更为确切的辅助语义。
2 IMIRSTNLU定义
2.1 基础定义
定义1 相似度匹配
数据以矩阵的形式存储于数据库表中,数据之间存在矩阵的相关性以及存储距离,因此根据不同形式的数据,其存储距离的大小不同,可以判定其相似度的大小。设数据信息E与X和Y的相似度为P,则:

其中PE的相似度为式(1)和式(2)的最小值,且 PE∈P[0,tA],t为知识库阀值。
定义2 贴近度
若PE的相似度值超过阀值tA,选择与之最贴近的阀值知识库进行相似度匹配。假设 PE>tA,且 PE<tB<tC<tD,则对知识库B进行搜索。
定义3词语分析
对词语经过解释处理,形成便于用户理解、有利于搜索的查询条件。设词语分析为M,则它包括M同义词分析、M近义词分析、M语义分析和 M歧义分析4个步骤。 设数据信息E,对其进行词语分析,首先会派生数据信息E关键词语相类同的多种信息,其中筛选与数据信息E的关键词描述意思相同的数据信息E同义,然后对其进行近义词分析,扩大数据信息 E的查询范围,生成数据信息E近义,然后对数据信息E同义和E近义进行语义分析,筛选与搜索词语相贴近的数据信息E语义,最后经过歧义分析,形成搜索查询条件。
定义4辅助语义
在词语分析的基础上,根据用户使用习惯、个人兴趣爱好、搜索历史等条件对用户搜索查询条件给予一定的参考,帮助其提交合适、完善和更加准确的搜索查询条件。
3 模型介绍
该系统由以下几部分组成:(1)人机交互层。当用户输入检索词语后,系统提供相应的辅助语义提交给用户参考,用户确定满足实际需求的最终检索条件。信息检索结束后,搜索内容输出,显示给用户。(2)词语分析层。当用户输入搜索词语时,系统首先进行词语分析,对输入词语进行数据挖掘,分析与之相关联的数据信息,进行同义词分析、近义词分析、语义分析、歧义分析等,然后将挖掘的与之相关联的辅助语义推荐给用户,以供用户参考。(3)信息检索层。用户确定检索词语后,根据数据相似度匹配原则,启动精确搜索和模糊搜索相结合的模式,对多媒体信息资源知识库中满足检索条件的知识库记录进行查找。当相似度值确定后,属于某一知识库,即对该知识库启动精确搜索,同时启动模糊搜索对其余知识库进行搜索。如果搜索为空,则返回该搜索没有答案。否则输出该知识库中的信息记录。(4)搜索处理层。对搜索结果进行综合处理,去除无效链接,重复链接等,对信息的关键程度进行排序,保存搜索记录于知识库,并对知识库进行更新[9],同时把用户的搜索习惯添加进用户习惯资源列表,以供下次搜索参考。通过不断收集用户搜索习惯和搜索结果,更新用户习惯资源列表和知识库,实现了用户个性化搜索。通过对搜索词语的自然理解解释,对知识库的动态更新、对搜索的二级模式设置、对辅助语义的记录等,实现了智能化,为以后快速定位搜索,创造了条件。具体框架图如图1所示。
4 算法分析
IMIRSTNLU模型采用自然语言理解技术,结合数据挖掘方法,对用户搜索的数据信息进行检索。
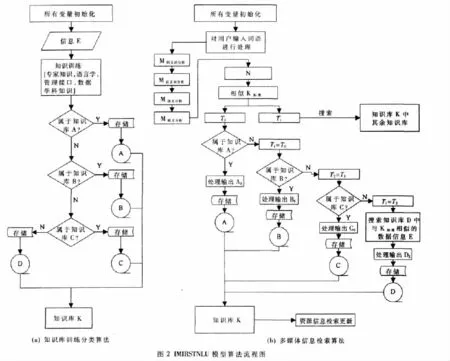
知识库训练分类算法:




//辅助语义添加到用户习惯资源列表队列;算法流程图如图2所示。
5 性能分析
由于目前针对多媒体信息检索研究还没有公认的数据集,所以本实验设计的数据库为文本、音频、视频和图像各10 000份所组成的实验数据库。实验平台为服务器一台 IBM3650,基本配置为 2×4 core 2 GB CPU;8 GB内存;500 GB硬盘;操作系统为WIN2003 SERVER标准版;编程环境为VC++2005。由于事先设定了各知识库的文件数量,所以知识库的组成已经得知,如表1所示。

表1 IMIRSTNLU系统知识库组成
对实验结果的评测,采取信息检索中常用的三个指标:检全率 Recall、检准率 Precision和 F1-measure值,其定义如下:

其中I为检索到的满足检索方法的检索数,R为检索结果数,W为可供选择的检索数。实验时分别输入针对4种知识库检索的检索条件,经由IMIRSTNLU系统对其进行搜索,经过式(3)、式(4)和式(5)对实验数据进行处理计算,结果如表2所示。
同时该实验对多媒体信息检索的效果与参考文献[10]的检索效果进行了对比,具体如图3所示。其中星号表示该实验的F1-measure值,圆圈表示参考文献[10]的F1-measure,通过对比可知,该系统的检准率与参考文献[10]相比有明显的提高,能够基本实现智能化理解用户检索需求,同时由综合评价F1-measure值可以看到,该系统的检索服务是高效和准确的。

表2 IMIRSTNLU系统实验数据分析

本文经过对自然语言和数据挖掘技术的理解,提出了一种智能化多媒体信息检索系统,通过对用户输入词语进行词语分析,生成辅助语义帮助用户参考搜索查询条件,启动二级模式搜索,对知识库实现全面和准确的搜索,同时对搜索结果进行综合处理,对知识库实现不断更新,对用户使用习惯进行存储记忆,有效地解决了检索语义模糊不清,查找范围不全和准确率不高的问题。
[1]Liu Ying,Tang Yonglin,Zeng Yuan.A study on improving information retrieval effectiveness for scientific and technical novelty retrieval[C].Proceedings of International Forum on Technological Innovation and Competitive Technical Intelligence’2008,2008:338-347.
[2]JAIN P.Intelligent information retrieval[C].SETIT 2005 3rd International Conference:Sciences of Electronic,Technologies of Information and Telecommunications,2005,3:27-31.
[3]KANNAN R.Topic map:an ontology framework for information Retrieval[C].Proc.of National Conference on Advances in Knowledge Management 2010:195-198.
[4]Peng Dunlu,Zhou Aoying.Web service retrieval technology based on the method of clustering[J].Computer Applications,2007,27(10):2365-2368.
[5]Zhang Fan,Li Linna,Yang Bingru.The intelligent information collection and processing system design and implementation based on the Web[J].Computer Engineering,2007,33(18):265-267.
[6]GOYAL P,BEHERA L,MCGINNITY T M.Application of bayesian framework in natural language understanding[J].IETE Tech Rev,2008,25(5):251-269.
[7]TANENHAUS M K,SARAH B S.Language processing in the natural world[J].Phil’s Trans R Soc Lund B Boil Sic.2008,363(1493):1105-1122.
[8]LEE C,LEE G, JANG M.Dependency structure language model for information retrieval[C].ETRI,2006,28(3):337-346.
[9]CAO G,NIE J,BAI J.Integrating word relationships into language models[C].Proc.28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Brazil.2005:298-305.
[10]Liu Wei,Chen Junjie.A framework for intelligent metasearch Engine Based on Agent[J].Computer Engineering end Application,2005,3:137-211.
猜你喜欢
国际比较文学(中英文)(2019年1期)2019-11-12
制造技术与机床(2019年6期)2019-06-25
东方教育(2016年4期)2016-12-14
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
中国交通信息化(2016年9期)2016-06-06
现代计算机(2016年11期)2016-02-28
图书馆研究(2015年5期)2015-12-07
中国校外教育(下旬)(2014年10期)2014-11-20
图书馆界(2013年5期)2013-03-11
