
一种使用GPU加速地震叠前时间偏移的方法
2011-05-12 02:46谢海波赵开勇王狮虎迟旭光褚晓文
网络安全与数据管理 2011年10期
张 清 ,谢海波 ,赵开勇 ,,吴 庆 ,陈 维 ,王狮虎 ,迟旭光 ,褚晓文
(1.浪潮集团 高效能服务器和存储技术国家重点实验室,北京100085;2.香港浸会大学 计算机系,香港;3.中国石油集团 东方地球物理勘探有限责任公司,河北 涿州072751)
1 PSTM技术
1.1 PSTM简介
PSTM是复杂构造成像最有效的方法之一,能适应纵向速度变化较大的情况[1],适用于大倾角的偏移成像[2]。PSTM经过多年研究,20世纪 90年代初期开始初步应用,中后期在不少探区的地震勘探中发挥了重要作用,进入21世纪后开始了较为广泛的应用,目前部分处理公司和计算中心已把该技术作为常规软件加入到常规处理流程中,成为获取保幅信息实现属性分析、AVO/AVA/AVP反演和其他参数反演的重要步骤和依据。
PSTM方法主要分为两类,即用于准确构造成像的PSTM和振幅保持PSTM,每一类方法都有两种实现方式:Kirchhoff型和波动方程型,而目前工业界最成熟的是 Kirchhoff型 PSTM[3]。PSTM每输出一个地震道,就是一次海量运算。以1 ms采样、6 s数据为例,一个地震道的输出需要至少1 000万道甚至更多(偏移孔径决定)的输入道,每一个点要做两次均方根运算以及两次加法运算,振幅补偿两次乘法运算。如此计算下来,实现一道偏移需要 1 000 000×6 000×2×(平方+加法+乘法)次数学运算,计算量和需要处理的数据量都极其巨大[4,5]。 目前,人们往往使用大规模的服务器集群来进行叠前偏移处理,其原理是将数据先分配到各个CPU核上,然后由各个CPU核单独进行计算,最后将结果汇总输出。这种做法消耗了大量的时间、电力和维护费用。而且,随着人们对石油勘探地震资料处理的周期要求越来越短,精度要求越来越高,服务器集群的规模越做越大,在系统构建成本、数据中心机房空间、内存和I/O带宽、功耗散热和电力限制、可管理性、编程简易性、扩展性、管理维护费用等方面都面临着巨大的挑战。
1.2 PSTM研究现状
自从20世纪90年代以来,叠前时间偏移在国外取得了很大发展。在理论研究方面,Bleistein、Bortfeld和Hubral等进行了一系列有关真振幅叠前时间偏移理论的研究工作[6],Schneider给出了 Kirchhoff型真振幅偏移权函数的一般公式。Graham A.Winbow(1999)推出了控制振幅的三维叠前时间偏移的权函数的显式公式,并且利用真振幅权函数估计进行了振幅补偿。另外,在权函数改进的基础上,提出了高精度的弯曲射线法绕射走时计算方法。在应用方面,最近几年,在常规叠前时间偏移基础上,研究开发了多种保幅型叠前时间偏移软件,尤其是Kirchhoff保幅型叠前时间偏移软件取得了巨大成功。随着GPU的出现,利用GPU的多核计算资源,实现对PSTM的并行处理,加速PSTM的执行时间,成为一个研究热门,国内外多家研究及工程机构皆针对此技术进行了研究。
1.3 GPU通用高性能编程技术
多核技术已经代替单纯CPU频率的提升而成为计算机性能发展的主流。除了CPU技术之外,采用GPU、FPGA加速并与CPU异构并行的方式在这两年大放异彩。使用这种架构的技术如ClearSpeed的FPGA加速方案、AMD的Stream方案、Mercury的Cell BE加速方案和NVIDIA的CUDA方案。
GPU已经体现了较CPU更高的晶体管密度和计算能力,相较FPGA等的实现,GPU是一种非常成熟的商业芯片,有利于应用的快速部署,并表现出更好的性价比。从2000年左右开始,有部分研究者开始采用GPU强大的图像处理能力来进行通用计算[7]。传统的GPGPU(General-Purpose Computation on Graphics Processing Units)的处理方法是把通用的计算问题转换为GPU中能处理的图形问题,然后通过图形编程语言来进行编程。这样的编程模式使得开发难度很高,开发者必须掌握强大的图形处理能力。
从2006年开始,NVIDIA开始研究通用的GPU处理架构并推出计算统一设备架构CUDA(Compute Unified Device Archetecture),使得开发者不需要有很强的图形开发能力,而是采用扩展了的C语言对GPU进行直接编程。NVIDIA把顶点处理和面处理整合到同一个处理芯片上,从而获得GPU硬件在架构上的通用性。经过几年的发展,CUDA架构更加灵活,更适合通用计算。这使得CUDA方案成为异构并行模型中的佼佼者。该方案入门门槛低,程序移植效率高,加速比好。图1描述了CUDA技术体系结构。
2 PSTM热点分析
通过分析PSTM,不难发现整个程序分为两个部分,一是FFT计算部分(以下简称 FFT),二是 PSTM计算部分(以下简称 PSTM_Kernel)。FFT为 PSTM_Kernel作数据准备,它主要是对输入地震道数据进行FFT计算,在这里只对PSTM的实际运行情况进行定量分析,找到PSTM中的热点计算部分。
2.1 测试环境及数据
测试环境包括硬件环境、软件环境、运行软件;测试数据为输入地震道数据集;对于成像空间而言,它是四维的,其中第一维为X轴方向的大小NX,第二维为Y轴方向的大小NY,第三维为炮点与接收点的偏移范围大小NOFF,第四维为Z轴方向的大小NZ。为准确测试出热点,特选择一个线偏成像空间和一个体偏成像空间进行热点测试,具体各项参数如表1所示。

2.2 分析结果
为了保证数据的准确性,对线偏和体偏分别进行10次测试,计算10次PSTM运行的平均CPU使用时间和它的两个计算部分平均执行时间,测试结果如表2所示。不难发现,PSTM_Kernel是整个PSTM的核心计算部分,占到整个运行时间的90%以上,所以PSTM_Kernel为PSTM的热点计算部分。
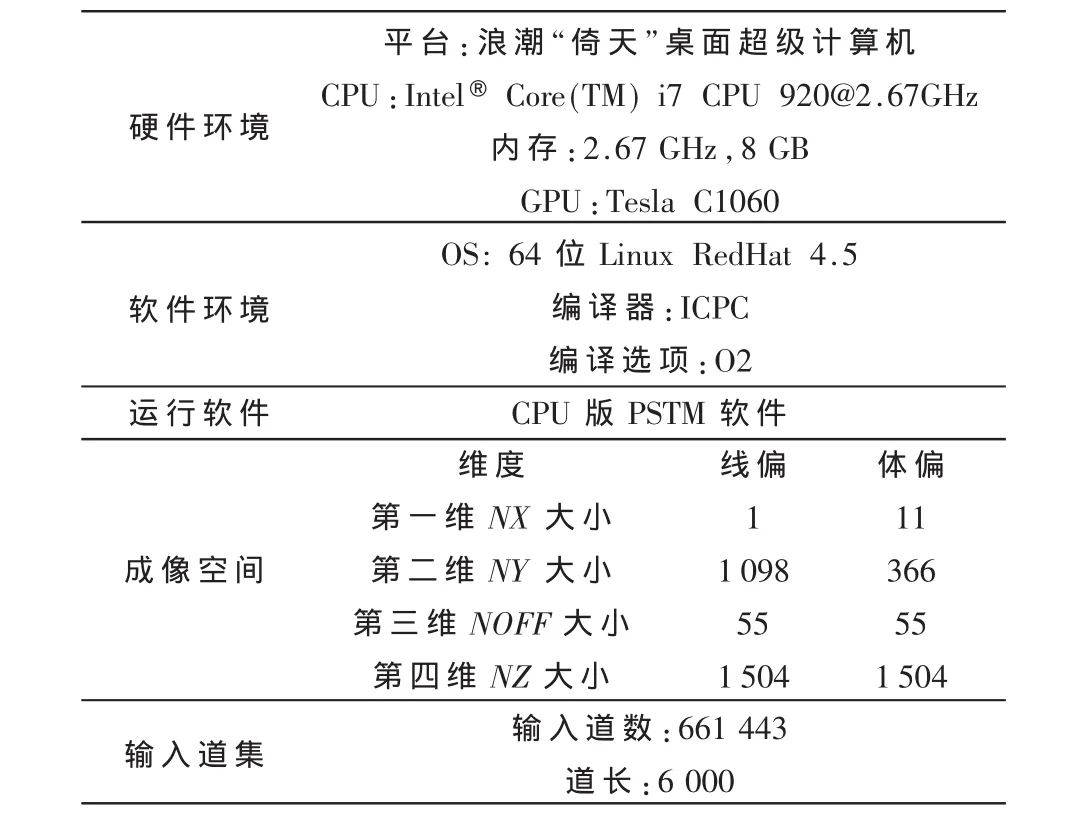
表1 测试环境和测试数据
既然PSTM_Kernel为PSTM的热点计算部分,如果对PSTM_Kernel进行并行化改造,它的运行时间将大大减少,则整个PSTM的运行时间将也随之明显减少,其性能将大大提高,所以在本文的研究中,将对PSTM_Kernel进行并行化的改造,以加速PSTM的运行效率。
3 PSTM_Kernel并行化改造
3.1 PSTM_Kernel串行算法分析
PSTM_Kernel串行算法的基本思想是:对于每一道地震道数据而言,PSTM_Kernel都循环计算成像空间中每一个点的走时,即每一个成像点到此道地震道数据对应的炮点的走时,和每一个成像点到此道地震道数据对应的接收点的走时[7]。然后根据这两个走时之和取出对应的地震道数据,更新此成像点的数据,实现叠前时间偏移计算。
PSTM_Kernel串行算法的核心是按照成像空间X轴方向、Y轴方向、Z轴方向三层循环进行实现的,其具体过程如下:
(1)循环取出每个成像点在成像空间中对应的 X、Y、Z坐标,确定成像点位置;
(2)根据成像点位置计算出其到炮点和接收点的走时;
(3)根据这两个走时之和取出对应的地震道数据,然后更新此成像点在成像空间中的数据,实现叠前时间偏移计算。
从以上串行算法分析,每一个成像点到炮点和接收点的走时计算是数据独立的,并不存在依赖性,因此存在较好的并行性,适合GPU等细粒度并行体系结构的加速。在此采用CUDA技术进行实现。
3.2 CUDA并行实现
3.2.1线程计算粒度选择
应用CUDA模型加速通用计算,涉及线程模型及对应的计算粒度问题。如果线程计算的粒度太小,例如成像空间的每一个点对应一个线程进行计算,则线程总数为成像空间四个维度数值的乘积,即NX×NY×NOFF×NZ。由于每道道数据并非对成像空间的所有点都有贡献,因此细粒度的并行会产生较多无效计算线程。这种情况下,线程计算粒度太小反而会导致线程的并发度不高。如果线程计算粒度太大,一个线程进行多点的循环计算,则线程数过少,不能使流处理器满负荷运行,性能同样不能达到最优。通过性能测试发现,最佳计算粒度为:32个线程负责计算NZ个点,即32个线程负责计算成像空间Z方向上一条线上的所有点,此时计算性能最为理想。
3.2.2线程模型选择
线程模型是用来明确CUDA程序内核的执行配置。根据GPU硬件资源,定义网格和线程块,好的线程模型能大大提升程序的性能。
(1)网格(grid)的定义:即把所有线程如何进行分块,定义线程块数和线程块的组织方式,这里根据成像空间的X-Y平面来划分线程块,其具体定义为dimGrid(NX,NY/10);
(2)线程块(block)的定义:即定义一个线程块有多少个线程和线程的组织方式,根据内核所需的寄存器数和共享内存数量,定义一个线程块为320个线程,其具体定义为 dimBlock(32,10);
(3)线程模型描述:grid和block都是定义为二维的,线程总数为 NX×NY×32,线程块数为(NX×NY)/10。 每个block的 320个线程处理 10个(x,y)坐标所对应的 Z轴的所有点,即处理Z轴的10条线。如果把每个block的320个线程按照32个线程进行分组,每一组为一个warp,则整个 block有 10个 warp,第 0个 block的第 0个warp,即 threadIdx.y等于 0的线程处理第 0个(x,y)坐标对应的Z轴的第一条线;第0个block的第1个warp,即threadIdx.y等于 1的线程处理第 1个(x,y)坐标对应的 Z轴的另一条线,依此类推,第0个block的第9个warp,处理第9个(x,y)坐标对应的Z轴的一条线。同理,其他block处理另外10个(x,y)坐标对应的Z轴的10条线。10条线并行进行走时计算,可以使计算更均衡,性能更高。

表2 PSTM软件各部分运行时间表

图2 异步IO逻辑结构图
3.3 CPU与GPU的异步IO实现
基于上述的CUDA并行化改造,显著提升了计算性能。而随之带来的问题是GPU加速所必然造成的IO传输问题。PSTM_Kernel执行之前,需要FFT计算模块对输入道进行预处理,之后这些数据需要从系统内存传递至GPU显存。这是GPU计算的引入所带来的额外IO开销。如果采用同步方式进行数据传输,即:对一道地震道数据而言,完成一道FFT的计算,就将数据传输给GPU再进行叠前时间偏移计算,那么IO开销将会很大,对性能造成很大影响。
本文采用CPU与GPU的异步传输方式来试图减少上述PSTM执行的总时间。采用CUDA的流(stream)技术,利用双流双缓冲,实现CPU与GPU的异步IO传输,其逻辑结构图如图2所示。
4 地震资料测试
4.1 测试环境及数据
通过一套小规模集群系统测试GPU加速PSTM的效果。具体各项参数如表3所示。

表3 测试环境及测试数据
4.2 性能结果
为了保证测试性能结果的稳定性,对上述体偏作业进行了3次测试,CPU多线程版PSTM在集群上运行3次的平均时间是110 908 s,而GPU版PSTM在集群上运行上述同样体偏作业3次的平均时间是21 454 s,GPU版PSTM运行的性能是CPU多线程版PSTM的110 908/21 454=5倍。
4.3 成像效果图比对
通过上述作业,从获得的效果图来看,图像不存在明显差异,证明GPU加速PSTM运行结果的正确性。
通过对PSTM算法的性能剖析,分析算法的热点函数,并对该热点函数进行GPU并行化改造。初步改造移植结果说明,使用GPU进行加速可显著提高叠前时间偏移计算速度,实验数据证明了加速效果。测试数据表明,对于一个完整的PSTM体偏作业,一个GPU节点的运行时间是一个采用最新双路CPU节点,并运行商用多线程CPU版PSTM时间的1/5。由此可见,PSTM高并行度、无数据依赖性等特征使得其较适合GPU类设备的加速。
[1]张占杰.叠前时间偏移技术及其在东海复杂地震资料处理中的应用[J].海洋石油,2007,27(3):22-26.
[2]王余庆.叠前偏移技术探讨及应用[J].西北油气勘探,2006,18(2):31-39.
[3]王棣.叠前时间偏移方法综述[J].勘探地球物理进展,2004,27(5):313-320.
[4]罗银河.Kirchhoff弯曲射线叠前时间偏移及应用[J].天然气工业,2005,25(8):35-37.
[5]洪钊峰.GPU计算:在石油勘探领域的革命[EB/OL].[2009-5-13].http://server.it168.com/a2009/0513/276/000000276186.shtml.
[6]张丽艳.相对振幅保持的转换波叠前时间偏移方法研究[J].石油地球物理勘探,2008,43(2):30-36.
[7]李博.地震叠前时间偏移的一种图形处理器提速实现方法[J].地球物理学报,2009,52(1):245-252.
猜你喜欢
小天使·初中版(2021年9期)2021-09-18
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
当代陕西(2019年17期)2019-10-08
环球市场(2017年36期)2017-03-09
股市动态分析(2016年24期)2017-01-07
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年4期)2016-09-29
股市动态分析(2016年25期)2016-07-23
意林(2007年20期)2007-05-14
