
基于网页聚类的Web信息自动抽取*
2011-05-11 11:58:52邱韬奋杨天奇曾洪波
网络安全与数据管理 2011年4期
邱韬奋,杨天奇,曾洪波
(暨南大学 信息科学技术学院计算机系,广东 广州510632)
随着Internet技术的迅速发展,Web已经成为当今最庞大的信息库。然而Web页面中通常含有很多用户并不关心的信息(如广告链接、导航栏和版权信息等),如何从Web页面中抽取出有用的信息已经成为当前信息领域的研究热点之一。
Web信息抽取是一种从Web文档中抽取出有用信息的技术,通常用于Web信息抽取的软件又称作包装器(Wrapper)。自 1994年起,包装器生成技术经历了从手工编写包装器脚本,到利用机器学习的半自动化生成,再到自动化生成的三个阶段。目前,自动化已经成为Web信息抽取技术的一个重要特征,比较有代表性的抽取工具有 RoadRunner、IEPAD、Dela 和 MDR-2 等[1]。
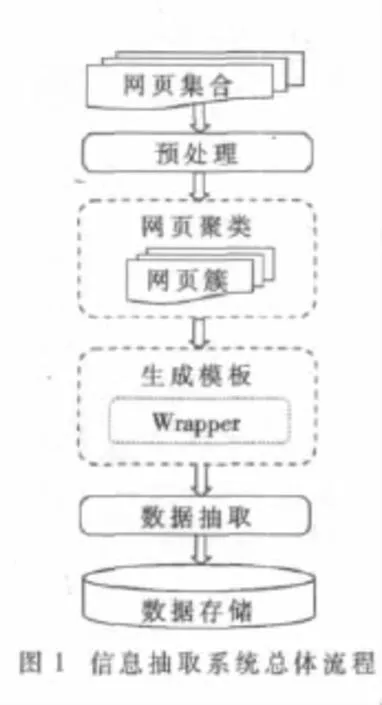
1 总体流程
本文根据数据提供网站动态网页的特点,在基于DOM的抽取技术上,根据树的相似度比较算法对网页进行聚类分析,从而分类出网页结构相似度较高的网页簇,并考虑非模板标签和模板文本改进包装器生成算法,基于这些算法实现一个高精度的Web信息自动抽取系统,并通过大量的测试网页集对这些算法进行实验和评估。整个抽取流程如图1所示。
2 算法实现
2.1 页面预处理
对于抓取的网页,并不能直接转化成一个DOM树,因为HTML网页的格式通常不是规范的XML格式,因此需要将其先转化成XHTML格式。另外,Web中很多的网页都会存在标签上的错误,由于HTML的不规范性导致代码中存在的标签不配对也不影响页面的执行,并且很多标签是多余的。对于这些问题,本文采用HTML Tidy[2]来解决。Tidy是一个开源的HTML网页净化工具,它可以将HTML转化成XHTML,并能清除网页中的明显错误。因为页面预处理不是本文的研究重点,所以不对此问题展开阐述。
2.2 树编辑距离
基于DOM模型的Web信息抽取技术的基础算法就是比较两棵HTML标签树的相似性。比较两棵树相似性的方法之一就是计算它们的编辑距离,要计算两棵树之间的树编辑距离[3],通常的做法是找到两棵树之间权值最小的一个映射(mapping),映射的定义如下:
定义 1:假设 X是一棵树,X[i]是树 X中第 i个字节点,则树Tl和T2之间的映射M满足以下条件的有序数对(i,j)的集合。
对于任何 M 中的所有有序数对(i1,j1)、(i2,j2):
(1)i1=i2的条件是当且仅当j1=j2;
(2)Tl[i1]是Tl[i2]的左邻节点的条件是当且仅当T2[j1]是T2[j2]的左邻节点;
(3)Tl[i1]是 Tl[i2]的父节点当且仅当 T2[j1]是 T2[j2]的父节点。
有了映射,就可以计算两棵树之间的树编辑距离。设两棵树Tl和T2之间的映射为M。在M包含的数据对(i,j)中 i、j分别表示 Tl和 T2的标签。令 S表示 i和 j不相同的数据对数量,即需要替换的标签;D表示Tl中没出现在M中的节点,即需要删除的标签;I表示T2中没出现在M中的节点,即需要插入的标签。则树编辑距离ed(Tl,T2)可 以 由 式(1)得 出 :

其中,p、q、r分别表示替换、删除和插入的权值。为了使得出的值介于 0与1之间,利用式(2)规范化计算结果便于计算相似矩阵,式中的 len(Tl)和 len(T2)分别表示Tl和T2的节点数:

2.3 使用代表点的聚类法
对于网页集合的聚类,传统的层次聚类方法能实现比较好的结果。层次聚类过程由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系,整个过程为一个树状结构。自底向上的层次算法称为凝聚层次算法,本文使用的凝聚层次算法是使用代表点的聚类法。
使用代表点的聚类法(Clustering Using Representatives),首先把每个单独的数据对象作为一个簇,每一步距离最近的簇对首先被合并,直到簇的个数为K,算法结束。CURE的显著特点是:(1)可以识别任意形状的簇;(2)有效处理异常数据[4]。
2.4 网页聚类算法
在聚类实验中网页的数目为500~1000,在这个复杂度上,可以采用类CURE算法。在本文的网页聚类实验中,距离定义为两个网页的树编辑距离。
定义网页集合P={P0,P1,…,Pn},根据网页间的HTML标签树的树编辑距离计算相似矩阵。将Pi和Pj利用es(pi,pj)计算出树编辑距离,在矩阵中表示为 mij,计算结果为一个 N×N 矩阵。定义 Pi和 Pj的列相似度为 cs(pi,pj),通过实验可以发现引入平均绝对误差概念的列相似度比用单纯的树编辑距离es(pi,pj)在聚类过程的计算中具有更好的健壮性。列相似度cs(pi,pj)由式(3)得出:

紧接着利用代表点的聚类算法对网页进行聚类计算。网页的聚类分析中,首先认为每个网页就是单独的一个簇,然后根据簇间的相似性不断地合并簇对,直到合并为理想的簇的个数时算法结束。这里引用了自相似度的概念以获得更好的聚类结果[5],其中集合Φ的自相似性 s(Φ)由式(4)得出:
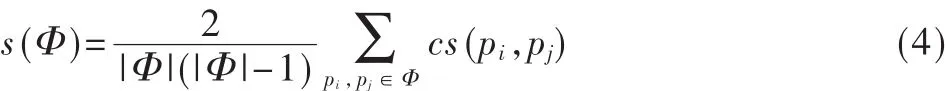
网页聚类中产生的代表簇必须满足两个阈值。首先簇的全局自相似性必须满足阈值Ωg,其次簇中两两网页间的列相似度必须满足阈值Ωe,这个阈值的设定是为了避免出现新簇,虽有较高的全局自相似性,但簇内仍然包含了一些不相似对象的情况。在本实验中,将Ωg和Ωe值分别设置为 0.9和0.8,整个过程算法的伪代码如下:

2.5 抽取模板生成
对于网页聚类后的每一个网页簇,都会生成一个对应的抽取模板,所有抽取模板组成了抽取系统的包装器。网页模板生成建立在两个网页模板生成的基础上。
2.5.1 两个网页的模板
两个网页模板的生成算法的基础也是DOM树的相似性算法,在计算距离的同时,生成一个节点映射集合,获得树节点T1和T2之间距离最小的子树匹配情况,把这些匹配情况作为一个列表返回。当T1和T2不匹配时,返回的列表为空;当T1和T2至少有一个没有子节点时,返回的列表只包含T1和T2的匹配。
返回的两个网页的节点映射集合中的节点就是模板中的必需节点,而两个网页不在映射集合中的点可以认为是可选节点,也可以认为是内容节点。如果是可选节点,就要把这些节点插入到模板中,可以把T1认为是最终模板,然后把T2的可选节点插入到T1中。插入的算法是:对于任一T2在映射中的节点P,获得它在 T1中的对应节点Q,遍历P的所有子节点C,如果节点 C在 T1中存在映射节点D,则记录D节点在Q节点的子节点列表中的位置;如果节点C在T1中不存在映射,则把节点C插入列表中最近一次记录的位置后面。
2.5.2 多网页模板生成
多网页模板生成算法建立在两个网页的模板生成算法之上。主要过程是选取一个网页作为初始模板,然后根据其他网页逐步调整模板,最后通过统计的方法得到模板,利用此模板生成抽取网页信息的包装器。
首先是初始模板的选取。结合网页聚类的算法,发现对于网页聚类结果簇集合 C={P0,P1,…,Pk},满 足 式(5)的网页Pi作为初始模板更为合理。

有了初始模板,接下来就是根据其他网页调整和修正该模板。网页的顺序从节点数最多处开始,依次往下,算法的伪代码如下所示:


2.6 数据抽取
数据字段的抽取是一个相对简单的过程。只要对要抽取的网页和包装器的相应模板做距离计算,如果模板中的所有必需节点都在最后的映射中,说明该网页满足此包装器,则把与包装器指定的内容节点对应的网页内容部分抽取出来。如果模板中不是所有必需节点都在映射中,则通过距离计算选取最相似的模板抽取网页信息。
3 实验
3.1 评价标准
对于聚类结果精确度的评估标准,采用聚类算法通用的F-Measure评估,它结合了信息抽取中的准确率(Precision)和查全率(Recall)的思想:
定义 C={C1,C2,…,Ck}为网页集合 D的一个聚类结果簇集合,C*={,C2*,…,}为网页集合 D的正确聚类簇结果集合,则簇j相对于簇i的查全率Rec(i,j)可以表示为|Cj∩Ci*|/||,簇 j相对于簇 i的准确率 Prec(i,j)可以表示为|Cj∩|/|Cj|, 簇 j相对于簇 i的 F-Measure结合这两个值:

基于这个公式,聚类结果簇集合C的F-Measure定义为:

F-Measure的值在0~1之间,为1时表示完全正确。
3.2 抽取结果分析
本 文 实 验 分 别 从 car.autohome.com、ebay.com、shopping.yahoo.com三个网站中各选取500个网页进行内容抽取,并采用信息抽取工具RoadRunner进行对比实验。实验中不断地调整阈值Ωg和Ωe,以达到最优的抽取结果,如图 2所示,当Ωg和Ωe的取值分别为 0.9和0.8时,聚类结果的F-measure值达到最优。
从三个网站的信息抽取结果可知,本文基于网页聚类的方法能取得较好的准确率和查全率,平均值分别达到80.3%和81.5%。比较RoadRunner的抽取结果,平均67.3%和66.6%的准确率和查全率,本文提出的方法明显能达到较好的抽取结果,因为RoadRunner没有考虑网页文本节点模板,而且对一个页面出现多个数据集的情况不能提取网页的主要内容。分析本文方法对个别网站抽取结果不太理想,是因为网站产品信息列表分布不均匀,主要信息块比较分散,造成准确率和查全率比较低。对于其他大部分主要信息块比较集中的数据提供网站,该方法抽取准确率和查全率在75%~85%,个别高度模板化的网站甚至可以达到90%,网页内容抽取实验结果如表1所示。


表1 抽取网页内容的实验结果
本文介绍了一种用于Web动态网站的网页聚类方法,利用生成高相似度的网页簇生成高效的包装器,并且成功地用于信息提取,取得了较好的效果,而且与同类技术相比具有算法构造简单、准确率高等优势。该方法适用于信息项内容的结构变化不是很大的Web页面,但另一方面,对于信息项的结构变化较大、数据块较多的情况准确率还有待提高。下一步主要工作就是改进抽取模板生成算法,准确识别网页中的主要数据块,提高算法的通用性,以适用于各种类型的网页。
[1]CHANG H,KAYED M,GIRGIS R,et al.A survey of web information extraction systems[J].IEEE Transactions on Knowledge and Data Engineering,2006,18(10):1411-1428.
[2]RAGGETT D.Clean up your web pages with HP's HTML tidy[J].Computer Networks and ISDN Systems,1998(30):730-732.
[3]LEVENSHTEIN V I.Binary codes capable of correcting deletions,insertions,and reversals[J].Soviet Physics Doklady,1996(10):707-710.
[4]CRESCENZI V,MERIALDO P,MIDDIER P.Clustering web pages based on their structure[J].Data and Knowledge Engineering Journal,2005,54(3):279-299.
[5]ALVAREZ M,PAN A,RAPOSO J,et al.Extracting lists of data records from semi-structured web pages[J].Data Knowledge Engineering,2008,24(2):491-509.
[6]CRESEENZI V,MEEEA G,MERIALDO P.RoadRu-nner:Towards automatic data extraction from large websites[C].In Proceedings of the 27th International Conferenee on Very Large DataBases,Rome,Italy,2001:109-118.
猜你喜欢
现代电子技术(2018年20期)2018-10-24 04:39:04
车迷(2018年11期)2018-08-30 03:20:32
电子制作(2018年10期)2018-08-04 03:24:38
海峡姐妹(2018年3期)2018-05-09 08:21:02
现代情报(2018年11期)2018-01-07 09:41:14
电子制作(2017年2期)2017-05-17 03:54:56
公民与法治(2016年10期)2016-05-17 04:12:58
电子测试(2015年18期)2016-01-14 01:22:58
计算机工程(2015年8期)2015-07-03 12:20:27
计算机与网络(2014年7期)2014-03-25 10:57:07
