
海量数据分析及处理算法实现
2011-04-13 00:59朱德新宋雅娟
长春大学学报 2011年8期
朱德新,宋雅娟
(长春大学 计算机科学技术学院,长春 130022)
0 引言
随着互联网的飞速发展,尤其是近几年来人们所掌握的数据量爆炸式增长,如何高效的处理海量数据已经得到了全世界的广泛研究。海量数据是一个形容词,它是用来形容空前浩瀚的、巨大的数据。现在很多业务部门都需要操作海量数据,如水利部门水利的数据,规划部门规划的数据,气象部门气象的数据,这些处理的数据量都非常大。它包括各种报表统计数据、空间数据、声音、文字、超文本、图像等各种环境和文化数据的信息。而这些数据又具有相当高的使用价值,高效合理地使用这些海量数据,不仅可以掌握更多用户潜在的需求,同时还可以为满足人们更多需求而开发出更好的应用。然而当人们面对具有如此庞大而且信息量继续爆炸增长的数据,想要非常高效的利用这些海量数据时才发现困难重重。在网络时代,如何对海量数据进行操作,这样越来越多的挑战需要靠卓越的算法来解决。
1 海量数据的存储
数据中蕴含着企业的财富,但是因为数据量的增长速度过快,所以首先在客观上逼迫企业必须实施海量存储的解决方案。在这个阶段过程中很多企业已经完成方案,或者正在实施。目前,各个企业对文件型数据推出了不同的存储方案,而采用文件服务器进行文件数据存储的仍然占据最多数,在总体企业中占据32.9%比例;应用服务器内置存储空间存储文件数据的企业占据21.8%的比例;16.3%的企业选择了通过NAS网关共享SAN网络存储空间进行文件数据存储;还有13.1%的企业通过NAS网络存储来进行文件存储;10.1%的企业通过集群NAS解决文件存储问题;表示应用分布式文件系统解决文件存储的企业占总体企业的9.2%;选择多协议支持的统一存储系统的企业占总体企业的3.9%;此外,还有16.9%的企业表示目前正在解决文件数据存储的问题。
2 海量数据处理的研究现状
面对着蕴藏企业财富的海量数据,在实现存储和检索之后,如何把这些有用的数据整合起来,并加以提炼和分析,最终形成支持企业业务发展的一个决策呢?这就是如何对海量数据进行处理的过程。
在过去二十年中,单机的性能有了很大的发展变化,尤其是CPU、内存等硬件技术。但是这些硬件技术在理论上的发展是有限度的。如果说硬件的发展在纵向上提高了系统的系能,那并行技术的发展就是从横向上拓展了处理的方式,例如如今的多核技术就是并行技术发展的一个实例[1]。在海量数据分析和处理上,并行数据处理方式是必不可少的。因为它的处理策略是“分而治之”,这样对于性能的延伸在理论上是没有边界的。在实际应用中,现今比较主流的两种并行数据处理技术就是MapReduce技术和并行数据库技术。
2.1 MapReduce技术
MapReduce是在2004年,Google公司的Jeffrey Dean和Sanjay Ghemawat提出来的[2-3]。谷歌的搜索引擎,每一天都要处理数量庞大的网络数据。根据客户的搜索条件将采集来的数据进行筛选,要求在一定的时间内完成。MapReduce将并行编程中复杂的业务逻辑进行抽象化。它在前面展现用于简单的计算的接口,而对负责的并行化处理、数据分布、容错、负载平衡和数据分布均进行了隐藏。这样很大程度上简化了程序员对于分布式这样程序的开发难度,每个程序只要用自己最熟练的并且能够实现数据处理的接口就可以了,而不需要考虑并行处理的每一个细节。MapReduce主要是Reduce和Map这两个操作上的概念。Reduce操作是针对键值进行简单汇总操作。通过这种方式,将现实生活中的许多任务都能描述出来。Map操作主要是对一组输入记录进行处理,处理方式是基于典型的key/value键值的方式。
2.2 并行数据库技术
并行数据库(Parallel Database System)是并行计算和数据库技术相结合的产物[4]。随着并行计算技术的发展,人们逐渐的认识到通过空间或时间上的并行处理,能够大大提高对任务的处理效率。并行计算可以分为任务并行和数据并行。任务并行处理会将任务的协调和管理变得非常复杂。而数据并行则是将一个大任务分解成多个相同的子任务,对比任务并行来说要容易处理。并行数据库实质上就是将数据并行处理的一种形式。一个数据库系统关注的更多的是吞吐量和响应时间,这两者也是衡量一个数据库系统性能的关键指标[5]。前者用于在给定的时间段里能够完成的任务数量,后者表示单个的任务从提交到完成一共需要多少时间。并行数据库主要用于提高这两点的性能。
2.3 多种数据格式支持原则
在海量数据的处理当中,对于数据格式的限制,不应该存在。因为在实际应用当中,各种格式的数据都有可能存在,比较常用的格式有:数据库、多媒体、网页、文本以及由其他应用程序生成的数据。而在海量数据的分析处理过程中,可能要面对一种或几种格式的数据。
2.4 S处理海量数据语言的选择
在实际应用中,对于一般的数据处理,往往需要使用数据库。但是如果要对复杂的数据处理,则必须要借助程序。而要在程序操作数据库和文本之间选择的话,则要选择程序操作文本。原因是该处理方法速度快;对文本处理不容易出错;文本的存储不受限制于文本的格式等。例如一些海量的网络日志都是文本或者csv格式,对它进行处理则会涉及到多余数据清除,是需要利用程序进行处理的,而不建议导入数据库再做处理。
处理数据离不开好的程序代码,尤其在处理复杂数据时,必须使用程序。程序代码对数据的处理非常重要,这不仅是数据处理准确性的问题,更是数据处理的效率问题。优秀的程序代码应该包含好的处理流程、好的算法、好的异常处理机制、好的效率等。当数据量非常大时,选择语言就需要慎重了。因为每种语言都有各自不同的特点,所以就需要在编程时间和运行时间之间进行权衡。遍历处理所有数据时,脚本语言处理就不合适了。因为脚本语言的运行时间非常长,不能够让人接受。另外,对于内存使用和文件读写,程序都没法控制。不幸的是,很少语言会为处理海量文件做优化。这时,C/C++是最好的选择。
3 处理海量数据的算法实现
该算法中,处理海量数据主要分为两部分。第一部分是对海量数据的读取。该阶段的算法可应用于任何类型的文本文件中,数据以字符为单位从文件中读取出来。第二部分是对海量数据的分析。而分析过程则需要根据文件的格式类型进行不同的处理。笔者处理数据的文件是.csv格式,文件的大小至少在25M以上,共有152049行,81列,文件的内容格式如图1所示。该算法的执行时间大约为7s。
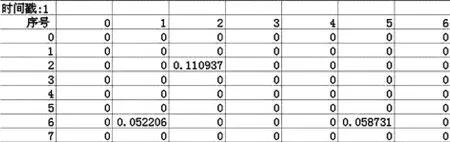
图1 文件内容形式
3.1 海量数据的读取
该阶段将文件映射对象映射到当前应用程序的地址空间中,并根据文件的大小,将数据以字符为单位读取出来。流程图如图2。

图2 读取海量数据
3.2 海量数据的分析
该阶段是图2中对视图数据处理这个过程。处理文件的格式为.csv格式,该文件的特点是数据以逗号作为分隔符,每一行结束符为回车换行。处理过程将图1中每一个时间戳内有效数据(浮点数)分析出来,并将有效数据时间戳数以及一个时间戳内的行值、列值、最左点、最右点、最上点、最下点等信息提取出来。流程图如图3。

图3 海量数据处理
该算法执行海量数据的结果如图4、图5所示。

图4 显示执行时间

图5 提取有效数据结果
4 结语
本文从现实问题出发,就当前海量数据分析处理难题,进行了方法上的简单探讨。并根据存储海量数据的文件格式,设计了算法。通过对算法在执行效率和分析有效数据上的验证,该算法快捷有效,能够比较好的对海量数据进行处理。
[1]陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.
[2]J.Dean and S.Ghemawat.MapReduce:Simplified data processing on largeclusters[M].In Proc.OSDI,2004.
[3]David J.DeWitt,Jim Gray.Parallel Database Systems[M].The Future of High Performance Database Processing,1992.
[4]Ben Lorica.HadoopDB[M].An Open Source Parallel Database.2009.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
当代陕西(2019年14期)2019-08-26
财经(2017年2期)2017-03-10
中学数学杂志(初中版)(2016年5期)2016-11-01
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
中国惯性技术学报(2015年1期)2015-12-19
