
基于在线翻译服务的集成应用框架
2011-02-26 09:16杨珺
上海电力大学学报 2011年3期
杨 珺
(上海电力学院计算机与信息工程学院,上海 200090)
随着互联网络技术的发展,人们需要在繁多的网上资源中获得想要的信息[1],现在很多人都在使用像Google这样的搜索引擎,以及Altavista,CNN,Babelfish,FreeTranslation等完成对信息的获取.在线翻译的优点很明显,它并不需要客户端,直接在网页上使用就可以了,但随着打开网页所需要的浏览器功能的逐渐增多,耗费在打开网页上的时间对用户来说常常是不能忍受的,用户每次使用在线翻译都需要寻找翻译网站,浪费了用户的时间和费用.
因此,如何在提供网上在线翻译服务的基础上进行数据的二次利用,是值得研究的问题.本文通过建立一种在线翻译服务的集成框架,实现多种在线翻译程序的集成使用,提高了用户使用此类服务的可操作性和实用性.
1 模型设计思想
当前,网上数据的提供方式大都使用Web页面形式进行用户操作,当用户为了得到相关信息时,其操作步骤为:打开网页,在网页中输入具体内容,提交,最后得到结果[2].例如,Google 的翻译页面如图1所示.
这是一种典型的网上用户信息获取方法,但这种方法对于访问频度较高的用户而言,显得不是很方便.如果能够向用户提供一种不需要通过浏览器浏览网页获取信息,而是通过简洁的客户端方式并具有一定的数据挖掘分析能力的使用方式获取信息的话,则将大大方便用户使用.两种使用模式的基本流程对比如图2所示.

图1 Google网上翻译屏幕
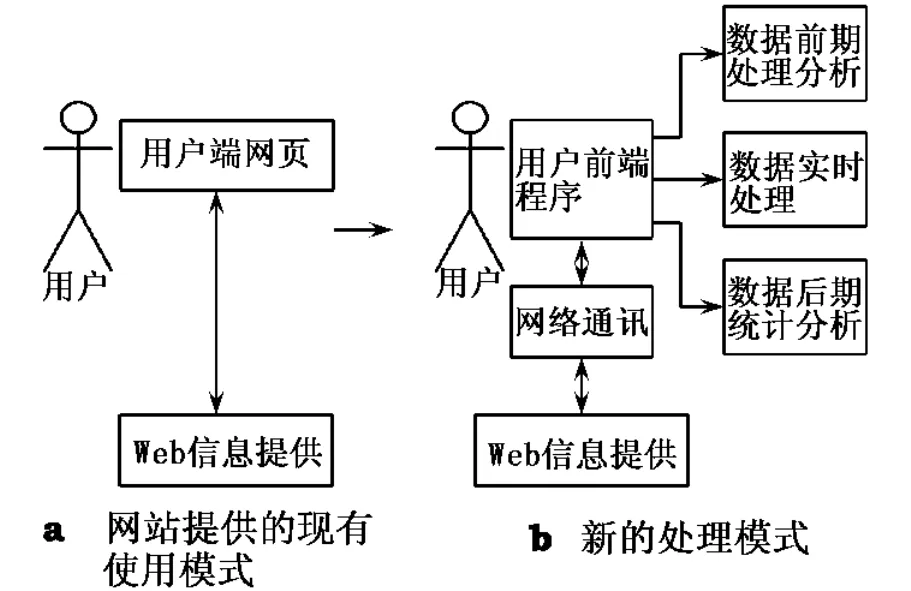
图2 两种不同的处理模式对比
图2 b通过前端的用户信息处理,对网上Web数据提供的信息在内部进行二次数据的加工处理.在此模式下,客户端实施数据统计、挖掘等处理方法,并对已有数据引擎的提供者进行数据的二次处理.但对利用他人提供的信息进行信息处理时必须考虑合法性,以及道德等相关问题.基于第3方信息提供的网络信息数据的挖掘,网络通讯可以采用定量(不返回所有搜索信息)、定期(有限时间周期)等方法来缓解Web数据信息提供服务器运行时的压力.
2 组件及相关数据流程
信息的传递通过网页数据的形式进行.网页处理的两大部分包括:网页数据内容获取;数据内容解析.网页数据内容获取主要完成具体网页内容的下载和内部网页内容的下载;数据内容解析,主要用于解析网页中感兴趣的内容[3-5].
具体的解析过程如图3所示.其数据解析大致框架流程包括以下几个方面:
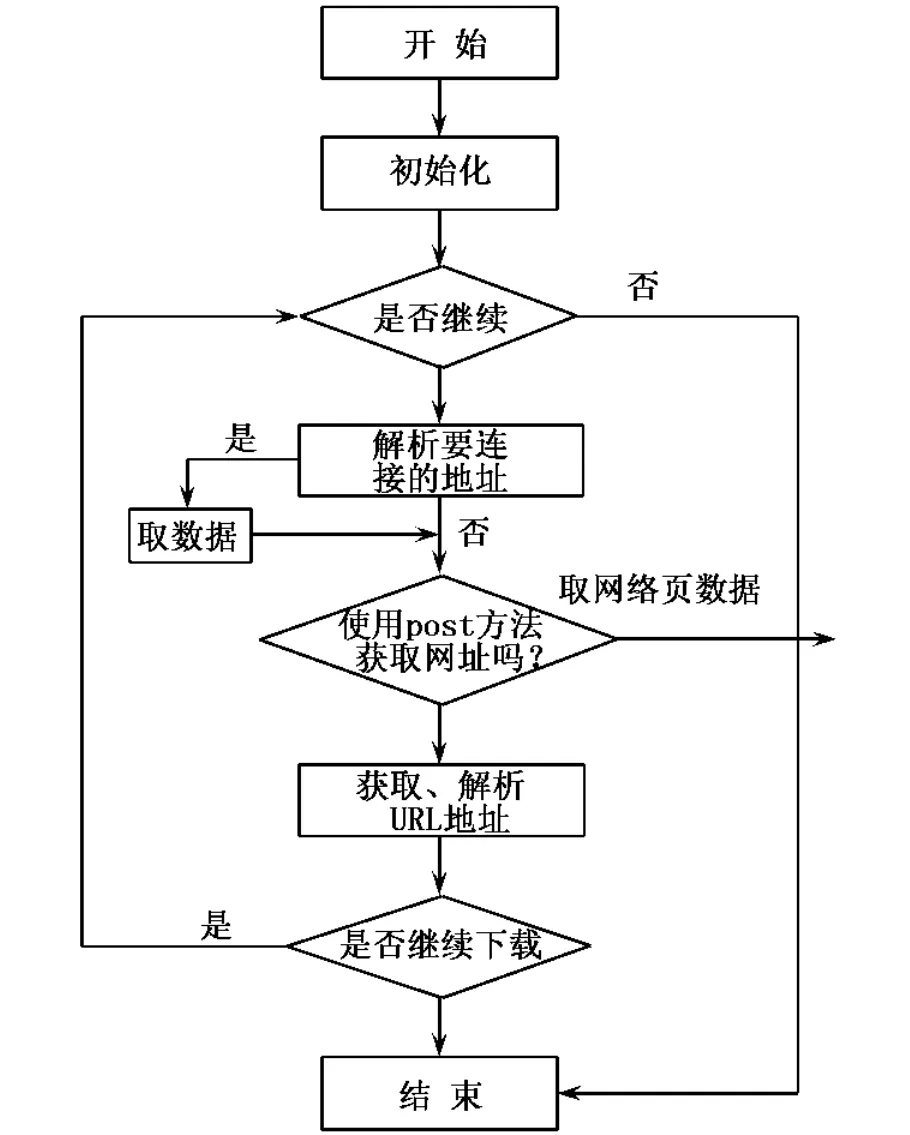
图3 框架流程
(1)初始化 包括一些特定数据信息服务的连接信息、本地功能性连接的初始过程;
(2)判断是否继续连接Web数据服务 对于向特定的Web数据提供服务,有必要判断是否为可使用数据源信息;
(3)继续解析要连接的提供信息服务的网络地址 考虑到地址树的各个数据源不同,对提供的不同信息、不同地址实施具体的数据解析工作;
(4)数据获取的post方法 对于不同的数据信息,不采用http的get方法实施数据的获取,而是使用post向数据源请求数据,并在此过程中解析网络数据源反馈的数据;
(5)继续获取下一个数据网络URL地址 一个网页中的信息可能通过URL标记到其他数据源的URL中,因此有必要通过当前的URL网页内容来获得此类完整的数据源URL树.
(6)继续下一个操作 通过迭代方法获取下一个数据源URL的数据内容.
模型的具体实现采用VC编码实现,表1描述了对于一网页内容所采用的一些关键解析方法.

表1 客户端连接时的一些典型方法
3 基于框架的一个典型翻译的应用
采用以上框架模型的设计方法可以实现网上在线翻译的集成应用.
3.1 基于框架模型翻译处理的主要方法
基本处理步骤如下:通过HTTP数据交互方法将客户端信息发送到服务器端,Google翻译时发送和接受具体标签,然后对返回数据进行数据内容解析,取得要获得的具体内容.Google翻译时发送和接受的具体标签内容描述如下.
3.1.1 发送时数据
<select name=langpair>:选择性标签.用以标记相互翻译的转换语言对,例如英文到中文的翻译,其值为en|zh,英文对法文则是en|fr等.
<text area name=text rows=5 cols=45 wrap=PHYSICAL>文本框内容,具体标记的是要被翻译的内容.
<input type=hidden name=hl value="zh-CN">隐藏域内容,用以标记具体浏览器字符,显示属性.
<input type=hidden name=ie value="UTF8">隐藏域内容,用以标记具体发送的字符编码.
3.1.2 返回时数据文本解析内容
通过以上数据包发送到数据信息提供服务器,会返回相关的状态和数据信息,要想获取相应的数据就必须解析返回的数据内容.需要解析的标签如下:
<textarea name=q rows=5 cols=45 wrap=PHYSICAL>文本框内容,为服务器返回时的具体被翻译的内容.
3.1.3 相关流程
(1)取用户端数据 用户界面输入;
(2)构造要发送的网络地址 如对应Google翻译服务的发送地址 http://translate.google.com/translate_t;
(3)构造客户端要发送的内容 取客户输入时的相应数据,构造对应的发送参数,如langpair=en|zh&hl=en&ie=UTF8&text=I am graduate student;
(4)发送数据 通过地址和地址参数发送到具体的服务器;
(5)接收返回的数据 通过解析接收到的文本内容(解析标签<textarea name=q rows=5 cols=45 wrap=PHYSICAL>),获得相应的翻译后内容;
(6)解析返回数据的内容 显示具体的翻译内容.
3.2 多个网上翻译服务的客户端集成
多个网络翻译服务的客户端界面如图4所示.主要包括了一组两个大的文本框:一个用于让用户输入原文;一个用于显示翻译结果.两个文本框都支持多行文本的输入.
下面有3个按钮:一个是“雅虎翻译”的按钮,点击此按钮可通过雅虎在线翻译处理数据;一个是“金山翻译”的按钮,点击此按钮,数据则通过金山翻译的网站来处理数据;一个是“退出”按钮,以方便用户退出.此外,还有3个网站超链接.这3个网站都是在线翻译网站,以便用户在得不到想要结果的时候直接登录网站进行查询.下面以金山翻译为例说明在线翻译服务的客户端工作原理.

图4 多个在线翻译服务的客户端集成
金山翻译主要是通过金山词霸的在线翻译网站来处理用户想要翻译的数据,其功能主要分成两个部分:一是数据请求部分,先由程序发送请求并传递参数,然后再接收返回的数据流;二是数据截取部分,根据数据流内的特定标记来截取需要的数据.
数据请求部分的代码:


该部分程序首先确定了一个url就是http://www.iciba.com/而 其 中 的 参 数 为 texts,用Webrequest类向服务端发送请求,服务端在接收请求之后便会响应客户的请求,服务端返回响应的数据流,然后对接收到的数据流进行处理,通过wireshark工具进行分析,得知服务端返回的数据流都是文本数据,因此使用streamreader类来处理文本文件,并对接收到的数据流进行编码.此时,就处理好了接收到的数据,但所得到的数据中绝大部分是不需要的,因此需要对这些数据进行筛选.

使用这段代码的主要目的是进行数据筛选,主要的工作过程如下:首先是准备工作,可以通过查看网页的源文件以及wireshark抓包工具来分析服务器响应所返回的数据,通过多次实验可以发现,需要的数据均存在于字符串<ul class="tab_c_ul font_black marginleft10 margintop10 font14"> <li>"和字符串" </span> <divclass="show_exp"style="color:#888888">"之间,再截取这两个字符串作为标记来定位光标,可以得到结果前面的光标位置begin,以及结果的长度j-begin,最后通过substring函数截取结果.
4 结语
本文建立了一种基于框架的在线翻译服务客户端应用集成,实现了多种在线翻译程序的集成使用,提高了用户使用此类服务的可操作性和实用性.如何使用已有数据信息提供引擎提供的数据,来实现具体的数据应用,以及如何利用框架进行数据的处理加工是一个很有研究价值的课题.
[1]CHANG Wei-lun,YUAN Soe-tsyr.A synthesized learning approach for Web-based CRM[J/OL].[2001-12-12].http://robotics.stanford.edu/users/ronnyk/WEBKDD2000/.
[2]谭琼,李晓黎,史忠植.一种实现搜索引擎个性化服务的方法[J].计算机科学,2002,29(1):232-235.
[3]李昌清,李艳霞.基于动态异构的Web信息集成网页分析方法[J].计算机应用研究,2007,24(12):204-206.
[4]LAENDER AH F,R1BElRO-Neto B A.A brief survey of web data extraction tools[J].SIG2MOD,Record,2002,31(2):84-93.
[5]李宝利,陈玉忠.信息抽取研究综述[J].计算机工程与应用,2003,39(10):1-5.
猜你喜欢
汽车维修与保养(2020年11期)2020-06-09
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电脑与电信(2018年12期)2018-03-23
计算机与生活(2018年3期)2018-03-12
电子制作(2017年2期)2017-05-17
中国科技期刊研究(2017年2期)2017-05-14
电子测试(2015年18期)2016-01-14
西北工业大学学报(2015年3期)2015-12-14
浙江大学学报(工学版)(2015年2期)2015-05-30
