
基于GPU通用计算的分析与研究
2011-02-19 07:49田立国杜君
制造业自动化 2011年2期
田立国,杜君
TIAN Li-guo1,DU Jun2
(1.汉中职业技术学院,汉中 723000;2.北京装甲兵工程学院 装备指挥与管理学院,北京 100072)
0 引言
最近几年来,受游戏市场和视景仿真需求的牵引,GPU(Graphic Process Unit图形处理单元)得到了迅速的发展,主流GPU的单精度浮点处理能力和外部存储器带宽都远远高于同期的CPU,而且GPU已经从以往的固定流水线操作模式发展成可编程流水线模式;另一方面,受工艺、材料和功耗的物理限制,处理器的频率不会在短时期内有飞跃式的提高,新的摩尔定律已经演化为“未来的计算机硬件不会更快,只会更宽”,相应的现代CPU也采用了多核的架构用来提高CPU的并行处理能力。但GPU与生俱来就是一种众核并行处理器,在处理单元的数量上还要远远超过CPU,因此GPU在未来的高性能计算中将发挥越来越大的作用。
1 GPU通用计算概述
1.1 GPU通用计算
[1]从系统架构上看,GPU是针对向量计算进行了优化的高度并行的数据流处理器,其中包括两种流处理单元:顶点处理流水线(Vertex Shader)和像素处理流水线(Pixel Shader),其中顶点流水线是多指令多数据流(MIMD)的处理单元,而像素处理流水线(Pixel Shader)是单指令多数据流(SIMD)的处理单元。这种以数据流作为处理单元的处理器,在对数据流的处理上可以获取较高的效率,因此最近几年,很多研究人员开创了一个新的研究领域:基于GPU的通用计算(GPGPU:General-Purpose Computation on Graphics Process),其主要研究内容是除了在图形处理方面外,如何利用GPU来进行更为广泛的应用计算。GPGPU计算通常采用CPU+GPU异构模式,由CPU负责执行复杂逻辑处理和事务管理等不适合数据并行的计算,由GPU负责计算密集型的大规模数据并行计算。这种利用GPU强大处理能力和高带宽弥补CPU性能不足的计算方式在发掘计算机潜在的性能,在成本和性价比方面有显著的优势。
1.2 GPU通用计算的特点
在GPU上运行的图形应用程序的算法存在如下几个特征:算法密集、高度并行、控制简单、分多个阶段执行以及前馈(Feed Forward)流水线等,因此,符合这些条件或者是可以改写成类似特征的应用程序,就能够在GPU上获取较高的性能。
1.3 GPU通用计算平台
GPU从其诞生之日起就是专门为图形处理设计的处理器,它具有自己的存储单元,在数据存取方式上也存在一定的特殊性,而且通常对GPU进行开发的是一些游戏厂商,他们几乎都使非标准编程模式,如果要实现通用计算需要花费很大的程序开发能力,为了便于开发人员使用GPU的通用计算能力,世界上一些知名的软硬件厂商先后推出了一些开发平台和工具,极大地推动了GPU通用计算的发展和进步。目前使用比较广泛的是NVIDIA的CUDA,主要有以下两个原因:
1)硬件方面,支持CUDA的GPU在构架上有了显著的改进,一是采用了统一的处理架构,可以更加有效地利用过去分布在顶点渲染器和像素渲染器的计算资源;二是引入了片内共享存储器,支持随机写入和线程间通信。这两项改进使得CUDA架构更加适用于GPU通用计算。
2)软件方面,CUDA不需要借助于图形API,并采用了比较容易掌握的类C语言进行开发。开发人员能够从熟悉的C语言比较平稳地从CPU编程模式过渡到GPU编程模式,而不需要去学习特定的显示芯片指令或者特殊的结构。CUDA的最大优势在于它极大降低了利用GPU进行编程的入门门槛。只要编程人员掌握C语言,就可以利用CUDA所提供的编程环境和SDK基于GPU进行软件开发。
2 GPU通用计算的应用领域
2.1 GPU与CPU硬件架构比较
从硬件架构上看,CPU和GPU是按照不同的设计思路设计的:如图1所示。
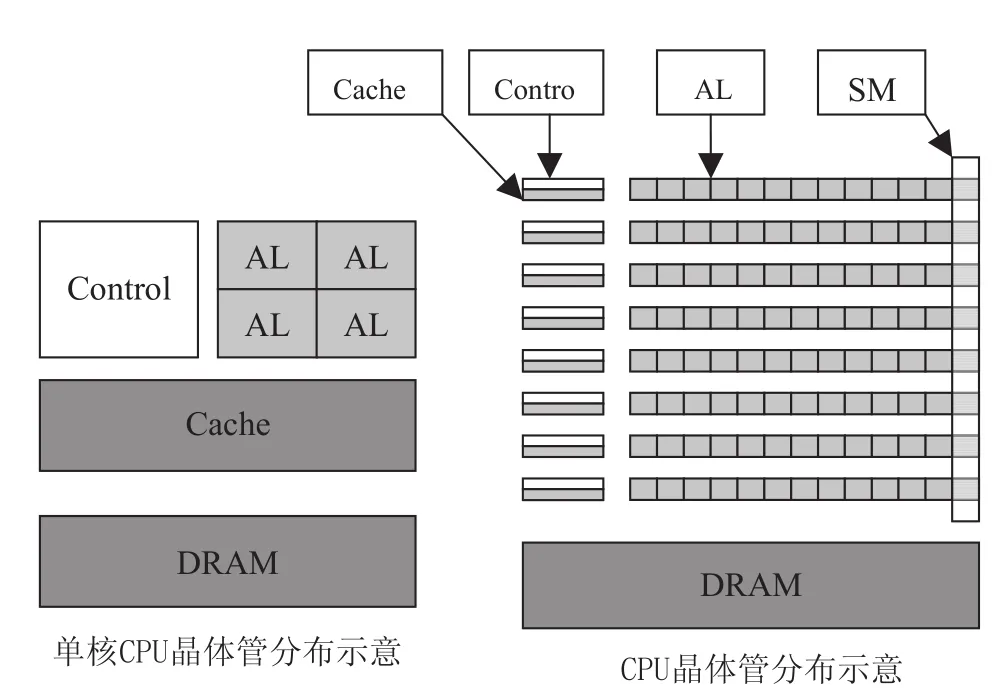
图1 CPU和GPU硬件架构示意图
CPU的架构是按照兼顾“指令并行执行”和“数据并行运算”的思路而设计,即兼顾程序执行和数据运算的并行性、通用性以及它们的平衡性。因而CPU是计算机中设计最复杂的芯片。和GPU相比,CPU核心的重复设计部分不多,这种复杂性来自于实现:如程序分支预测,推测执行,多重嵌套分支执行,并行执行时候的指令相关性和数据相关性,多核协同处理时候的数据一致性等等复杂逻辑。
GPU其实是由硬件实现的一组图形函数的集合,这些函数主要用于绘制各种图形所需要的运算。这些和像素,光影处理,3D 坐标变换等相关的运算由GPU硬件加速来实现。图形运算的特点是大量同类型数据的密集运算—如图形数据的矩阵运算,GPU的架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算—大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
2.2 GPU与CPU计算能力分析
GPU拥有自己独立的子存储系统—显存,它拥有比系统主存高得多的带宽。GPU在工作时,工作负载经PCI-E总线从CPU传入GPU显存,按照体系架构的层次自顶向下分发。PCI-E 2.0规范中,每个通道上下行的数据传输速度达到了5.0Gbit/s,这样PCI-E2.0×16插槽能够为上下行数据各提供5.0×16Gbit/s=10GB/s的带宽,有效带宽为8GB/s,但是由于PCI-E数据封包的影响,实际可用的带宽大约在5-6GB/s(PCI-E 2.0×16)。
CPU在浮点运算和并行计算方面的性能远不如GPU强大,所以将GPU的作为CPU的浮点运算协处理器可以使普通PC的运算能力提高到一个全新的高度。如果从更深层面考虑,目前CPU的发展已经遇到了瓶颈,无论是核心架构的效率还是核心数量都很难获得大幅提升,而GPU则是新的突破点,它的潜力很大。
2.3 GPU通用计算的应用领域
GPU通用计算的发展迅速,特别是“CPU+ GPU”模式的提出,使得GPU通用计算的应用领域逐步深入到科学计算的各个领域,如FFT(快速傅里叶变换)[2]、串匹配算法[3]、科学计算可视化[4]、实时红外图像生成[5]、遗传算法加速[6]、数据库操作[7]、等。随着软硬件技术的进一步发展,以及越来越多的研究人员和工程技术人员的参与,GPU通用计算的研究和应用领域将进一步拓宽。
3 GPU加速性能验证及分析
GPU在处理大量的没有逻辑关系的数值计算时,理论上具有明显的加速效果,为了对GPU通用计算的加速性能进行原理性的分析和验证,构建了以下的实验环境:
硬件采用2.2GHz Intel Core2Duo处理器和GeForce G210M显卡(娱乐级显卡),软件环境采用NVIDA的CUDA SDK 2.0及C语言编译器。
3.1 海量浮点数求和运算
选取0~512*21056的浮点型数据,每个整型数据执行k次累加和运算。
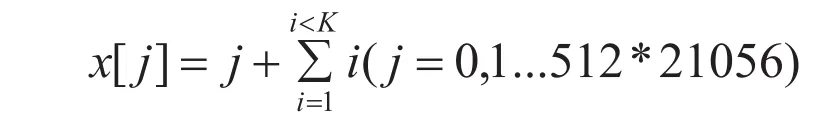
试验中,通过不断增大k的值,来调浮点数的运算量,试验的结果如图2所示。其中GPU程序执行时间包括数据在显存和主存之间的传递时间。
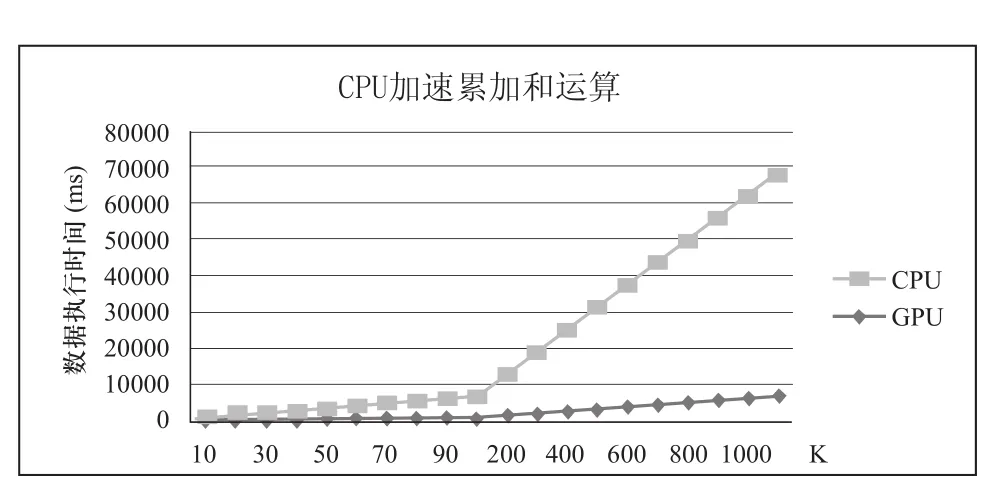
图2 海量浮点数运算
从试验结果可以看出,随着计算量的增加,CPU和GPU执行时间都在增加,但到达一定的计算量后,CPU执行时间成线性增加,而GPU基本保持不变,原因是高密度计算隐藏了GPU访存和数据传输带来的延迟。
3.2 龙格-库塔法解算弹道方程
龙格-库塔算法是一种常用的微分方程的数值解法,具有较高的精度,相应地其运算量也相对较大。

实验中通过改变解算弹道数,比较分析CPU和GPU的执行时间,如图3所示。
图3 龙格-库塔解算弹道方程
由试验数据可知,在弹道数小于1024的时候,GPU执行速度没有CPU快,GPU的加速性能没有充分发挥。当弹道数大于1024时,GPU加速优势开始显现,随着弹道数增大,GPU加速优势越来越明显,主要原因是大规模高吞吐量的数据运算也可以隐藏GPU访存和数据传输带来的延迟。
4 结束语
随着GPU 计算能力的飞速提高,以及相关软件平台的支持,高性能计算逐步进入桌面领域,对于普通的科研和技术人员而言,高性能计算(High Performance Computing,HPC)不再可望而不可及,在这种高性价比的计算资源的支持下,许多以往看起来无法解决的运算问题都可以迎刃而解。
[1]吴恩华.图形处理器用于通用计算的技术、现状及其挑战[J].软件学报.2004,15(10):1493-1504.
[2]冯煌.GPU图像处理的FFT和卷积算法及性能分析[J].计算机工程与应用.2008,44(2).
[3]张庆丹,戴正华,冯圣中,孙凝晖.基于GPU的串匹配算法研究[J].计算机应用.2006,7(26):7.
[4]郑杰.基于GPU的高质量交互式可视化技术研究[D].西安电子科技大学.2007.
[5]李勇.基于GPU的实时红外图像生成方法研究[D].西安电子科技大学,2007.
[6]杨正龙,金林,李蔚清.基与GPU的图形电磁计算加速算法[J].电于学报.2007,6(35):6.
[7]杨正平.基于GPU计算的直接体视化和遗传算法研究[D].中国地质大学文.2005.
猜你喜欢
小哥白尼(趣味科学)(2022年3期)2022-06-09
净水技术(2022年1期)2022-01-13
科技资讯(2021年10期)2021-07-28
环境卫生工程(2021年3期)2021-07-21
小学科学(学生版)(2020年2期)2020-03-03
电子制作(2019年7期)2019-04-25
汽车实用技术(2016年10期)2016-11-21
制导与引信(2016年3期)2016-03-20
中国资源综合利用(2016年9期)2016-01-22
弹箭与制导学报(2015年1期)2015-03-11
