
浅谈三维建模的几种方法
2011-01-23 09:57李洁琼薛玉芳李亚军
中国新技术新产品 2011年3期
李洁琼 薛玉芳 李亚军
(1,2.安徽理工大学计算机科学与工程学院,安徽 淮南 232001;3.宁夏青铜峡68242部队 751601)
浅谈三维建模的几种方法
李洁琼1薛玉芳2李亚军3
(1,2.安徽理工大学计算机科学与工程学院,安徽 淮南 232001;3.宁夏青铜峡68242部队 751601)
介绍了从二维坐标空间转化到三维坐标空间所要遵从的对极几何限制,并通过数学推导得出坐标转化表达式。在此基础上重点讨论了三维物体主动还原重建方式,特别是结构光还原的方法,通过结构光的引入,能够较好地解决像素匹配问题,可以提高还原确定性、减少拍照的次数、有利于动态物体的重建。
计算机视觉;三维建模;主动还原;结构光
1 三维物体建模的几种方法
三维物体的建模是指通过一定的方法,建立物体几何表面的点云,这些点可以通过插补的方法形成物体的表面形状,点云越密集所建立的模型就越精确。物体的建模方式可以根据所用仪器的类型分为接触式与非接触式两类。接触式建模方式需要实际触碰物体的表面,如使用测径器、尺子和坐标测量机等。虽然坐标测量机可以精确地获得重建物体的数据,但由于必须接触物体,有可能对待测物造成污染、变形或损坏,用于一些价值较高的物体如遗迹古文物和古文物等的重建则不太合适。非接触式建模方式可以分为主动式和被动式两种。主动视觉系统一般采用结构光的方法,该方法通常包括一台摄像机和一个投影仪,投影仪向物体投射一些人工设计的图案,摄像机拍摄被照物体得到这些结构光图案在物体表面形成的变形图像,利用结构光的编码技术和三角测量方法,来恢复物体的三维结构。这种方法借助结构光的信息,从而简化了图像匹配问题。被动视觉方法即立体视觉方法,用多台摄像机或一台摄像机在不同位置拍摄多幅物体图像来恢复场景深度信息,但这类方法有在不同图像间寻找匹配关系的问题,图像匹配是计算机视觉领域的一个经典难题,从而限制了这类方法的广泛应用。两种方法的本质都是根据立体视觉法重建图像。被动式重建方式,其本身不发射辐射线,而是通过测量由待测物表面反射周边辐射线的方法获取图像,再通过辅助方法实现还原。其还原方法可分为:明暗法,是把图像像素的亮度值代入预先设计的色度模型中,再通过表面可微分性、曲率限制及光滑度的限制求解方程;立体光学法,为了弥补明暗法中单张照片提供的信息不足,立体光学法是在同一个相机、同一场景下,采用不同的照明条件拍摄多张待测物的照片,通过处理得到物体表面的梯度向量,然后再经过向量场的积分得到三维模型;界提取法,重建的对象一般是一些简单形状的物体,通过拉普拉斯和高斯滤波等提取物体的边界信息以还原图像,在该法中利用到了物体的仿射不变性和尺度不变性算法;还有纹理识别和法轮廓法等。主动还原重建方式是指将额外的辐射能量投射至物体上,借助反射能量所得到额外信息计算出待测物体的深度信息。常使用的辐射能量有可见光、高能光束与激光。被动还原的各种方法相似,是以立体视觉法为基础的。但立体视觉法的缺点是,在还原过程中不能确定两幅照片中的对应点是否来自空间中的同一点,这就是像素匹配问题,给还原增加了难度。采用主动视觉系统建模将解决这一问题,首先必须对系统进行标定。现有的标定方法大致可以分为2类,即结构光标定法和转换矩阵法。其中,结构光标定法是最常用的一种方法,它对摄像机和投影仪分别标定,求出投射的光条所在光平面的模型。转换矩阵法对每一个投影光条求解一个4x3的变换矩阵,通过变换矩阵求解图像上的光条所对应的空间三维信。这两类方法都假定被照亮的物体表面上的点恰好在光平面上,当投影仪镜头存在畸变时,光平面的模型无法精确描述投影关系。当主动视觉系统的某个部件发生位置变化,或内部参数调整时,必须对系统重新进行标定。以上这些标定方法,其标定过程都比较繁琐,而且需要一个可以精确控制其运动的移动机构来完成。为了提高建模的速度和效率,大多数系统都采用同时向物体投射各种结构光图案的方法,需要利用结构光编码技术来解决结构光的匹配问题。对此,文献[3]给出了一个较好的综述。第一类方法是采用颜色编码策略,假设物体表面颜色为中性,不改变投影仪投射的彩色信息;第二类方法是基于时间连续性假设,即物体相邻像素在不同时刻是相同的,投影仪按照编码策略,在不同时刻,控制像素的亮灭,由摄像机检测这些特别的灰度图案,从而实现匹配。第一类方法投影仪投射条纹的顺序与其在图像上的顺序是一致的每一种编码策略均有其局限性,第二类方法不适合对运动物体的模。
2 结构光
2.1 点和线的投影。先考虑两种比较简单的情况。如果仅有一个点投影到物体上,则它在投影仪和照片上的相对位置是确定的,通过上面计算三维物体坐标公式的方法就可以求解该点的坐标。如果是一条线,比如,一条平行于x轴方向的线,则该线在y轴方向的投影仍是一个点,仍然可用上面的坐标公式进行计算。点和线的投影可以很好地匹配。但是,由于单独的点和线的投影可能会超出照相机的拍摄范围,投影到物体的背面,有时需要对整个物体进行扫描拍照,需要不断地移动照相机,这是很耗时的,并且在移动过程中会引入机械误差,大大降低了效率和还原的可靠性。
2.2 网格。有人提出了网格的方法,它兼有点和线的优势,线的突变意味着边界的变化,交叉的点可以对物体进行定位。网格的覆盖增大了物体的探测范围,消除了机械误差。网格线的粗细变化可以产生平滑效果。J·L·Mogen等人在此基础上进行了改进,如图2所示。在网格中增加方块点,用来初始化标记图像和作为识别图像的依据。经过优化,使得方块点在网格中的数量最少,且所有的垂直线都能与方块点中的一个或者多个相连。投影仪和相机的特殊放置使它们的横轴(x)相互平行,纵轴(y)在一条线上。因此,对于网格线来说,垂直线的投影基本不会变形,变化不会很大,在后期可以使用垂直线来辅助水平线的提取,而水平线投影到物体上会出现扭曲或断裂。扭曲包含了物体的深度(z)信息,断裂则是由于线比较细。相反,粗线会对图像进行平滑,改变图像的分辨率。重建中,根据需要,可以适当调节线的粗细来得到不同的精细程度(分辨率)。对于得到的图像,先进行高斯滤波,然后用拉普拉斯算法提取垂直线。扫描垂直线的左右两边得到垂直线与水平线的交点和方块点,通过这些交点把水平线恢复出来,如果恢复不出来,说明水平线细了,需要重新选择水平线的宽度。得到网格后,对方块点的左右两边进行扫描,标记各交点并与原图进行匹配。因为有些线在投影中被截断了,使得有些点不能与交点相连,因此从不同的方块点开始会得到不同的结果,通过把这些不同结果合并,可以得到一个较好的网格图,这也是选用了几个方块点的意义所在。
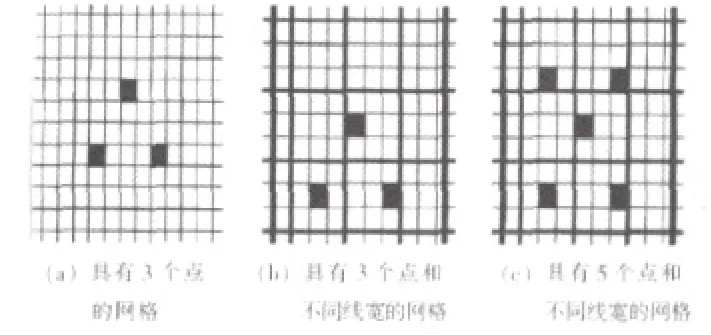
图1
结语
本文讨论了这几年来三维物体建模的几种方法,其关键之处在于找到物体的深度信息。几种方法从本质上来说还是基于人眼的双目视差,双眼视物时,主观上可产生被视物体的厚度以及空间的深度或距离等感觉,即同个物体从两个或多个不同的角度观察,通过视差信息得到深度信息。基于此原理,首先发展起来的是被动还原的方法,它能够重建三维物体,但存在匹配问题,不能够确定两张照片上的对应点是否来自同一个三维空间点的投影。在此基础上提出了主动还原重建方法,能够较好地解决像素匹配的问题。
[1]三维扫描仪[EB/OL].(2010-04-08)[2010-05-20].http://zh·Wikipedia·org/zh-cn/三维扫描仪.
[2]MIKOLAJCZYK K,ZISSERMAN A,SCHMID C.Shape Recognition with edge-based features[C].//Proceedings of The British Machine Vision Conference.Norwich,UK,2003:1-8.[3]REMONDINO F,EL-HAKIM S.Imagebased3D modeling:a Review[J].The Photogrammetric Record,2006,21(115):269-291.
Z
B
猜你喜欢
数学物理学报(2021年1期)2021-03-29
发明与创新(2020年46期)2020-12-24
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
学生天地(2019年15期)2019-05-05
小学生学习指导(中年级)(2018年10期)2018-10-10
课程教育研究·新教师教学(2015年5期)2017-09-27
