
基于改进的视觉关注模型和MVSC的图像拼接算法
2011-01-04 02:00郑艳飞李业伟
山东开放大学学报 2011年1期
郑艳飞,李业伟
(1.日照广播电视大学,山东 日照 276826;2.山东师范大学,山东 济南 250358)
基于改进的视觉关注模型和MVSC的图像拼接算法
郑艳飞1,李业伟2
(1.日照广播电视大学,山东 日照 276826;2.山东师范大学,山东 济南 250358)
图像拼接的实质是将针对同一场景的相互有部分重叠的一系列图片拼结成大幅的、宽视角的、与原始图像接近且失真小、没有明显的缝合线的高分辨率图像。本文首先概述了图像拼接方法中四类典型的方法,并分析各自的特性;介绍了传统视觉关注模型,并进行了改进,利用改进的视觉关注模型算法获取图像的具有重复的显著区域;利用图像配准算法对重复的显著区域进行匹配,并确定源克隆域和目标克隆域;利用均值无缝克隆(MVSC)算法对源克隆域和目标克隆域进行融合;最后,利用基于改进的视觉关注模型和MVSC的图像拼接算法完成图像拼接。实验结果表明:该算法不仅自动准确地获取显著区域,而且降低了图像配准的复杂性,提高了图像拼接的质量。
视觉关注模型;显著区域;图像配准;MVSC;全景图像
一、引言
目前在许多全景图拍摄过程中,普通相机无法获取超宽视角甚至360°的全景图,即使能够拍摄,但因为相机的分辨率一定,拍摄的场景越大,得到的图像分辨率就越低。因此,为了解决这一难题,图像拼接技术就起了关键的作用。图像拼接是将一组重叠图像的集合拼接成一幅较宽视角的无缝高分辨率图像或全景图像的技术,其本质是对待拼接图像重叠部分进行图像配准和图像融合的过程。图像配准是图像融合的基础,而且图像配准算法的计算量一般非常大,因此图像拼接技术的发展很大程度上取决于图像配准技术的创新。按照图像配准方法对图像拼接技术进行分类可分为两大类:一类是基于特征的图像拼接,它是利用图像的明显特征来估计图像之间的变换,而不是利用图像全部的信息,其中图像明显的特征主要有角点、轮廓和尺度不变特征变换(SIFT)三种。第一种是基于角点检测的图像拼接,其中Harris角点检测算法[1]和SUSAN角点检测算法[2]是角点检测中的经典算法。这些算法应用于图像拼接的优点是计算量小,配准精度高;缺点是边缘信息少的图像、大旋转和大尺度缩放的图像和多光谱图像不能很好地进行拼接。第二种是基于轮廓特征的图像拼接,其中LI Hui等人[3]在1995年提出了基于轮廓特征的图像配准算法,它为图像拼接提供了新的思路和方法。基于轮廓特征的拼接算法优点是适用于光照不一致、存在尺度关系及旋转的图像;缺点是对于轮廓特征不明显或噪声干扰较大的图像不适用。第三种是基于SIFT的图像拼接,SIFT算法由 Lowe于1999年提出,2004年完善总结[4]。SIFT算法被应用于图像拼接的优点是对旋转、尺度缩放、亮度变化的图像具有一定的鲁棒性,但是算法复杂度较高。第二类是基于区域的图像拼接,其代表是基于对数极坐标变换的图像拼接。最早由Reddy等人利用对数极坐标变换提出了一种频域相位相关算法[5],其优点是对数极坐标变换和相位相关法能有效解决平移、旋转和尺度缩放问题;缺点是要求待配准的图像间有较高的重合度。近年来,有关视觉关注模型[6]理论和均值无缝克隆算法[7]的提出,分别在显著区域提取和图像融合领域中初显身手,尤其改进的视觉关注模型算法在获取显著区域的同时获得其区域的轮廓、灰度级等信息,在图像配准时,只需图像配准算法对其判断,降低了图像配准的复杂度,减少了图像配准的计算量。均值无缝克隆算法虽处在发展当中,但其对图像融合的性能有效地克服了小波分析的缺陷,为图像修复提供了新的思路和解决方案。本文也正是基于上述理论提出了一种基于改进的视觉关注模型和MVSC的图像拼接算法。其算法的基本步骤可归纳用图1的流程图所表示。

图1 本文图像拼接算法流程图
图像预处理,就是对输入图像进行去噪以及对图像进行某种几何变换(如傅里叶变换、小波变换等)等一系列的操作过程。在全景图拼接中,由于图像配准的初始配准范围广,数值计算量大,造成配准的效率和精度都很低。利用图像预处理可以有效地实现图像预定位,以便粗略确定配准位置,缩小图像拼接时的搜索范围,提高拼接速度。
图像配准,就是采用一定的匹配策略,找出待拼接图像中的显著区域在参考图像中对应的位置,进而确定两幅图像之间的变换关系。图像配准是图像融合的基础,也是图像拼接的关键。图像配准的精确程度直接关系到图像拼接的质量。
MVSC是由区域匹配算法提供的源克隆域和目标克隆域进行复制融合,融合之后的图像能够得到一幅完整、新的全图像,并且在视觉上被认为是合理的。
二、视觉关注模型
近年来,显著区域的提取已经成为计算机视觉研究的一个热点。最早由Itti等人提出了视觉关注模型[8],该模型利用图像颜色、亮度和位置三个视觉特征突出图像的显著区域。其原理是对输入图像先过滤,再进行视觉特征提取得到视觉特征图像[9],并将视觉特征图像进行线性组合,得到显著区域。视觉关注模型如图2所示。
视觉关注模型模拟了人类视觉注意的转换过程,视觉关注的区域往往是视觉显著的区域。Itti的视觉关注模型算法是一种受环境影响的从下而上的视觉显著性区域算法[10],也是当前计算机视觉中的一个主要研究方向,其最具有代表性。该算法在多种类型、多种尺度的视觉空间中将图像通过“中心-周边”算子得到的特征图线性组合成为一幅显著区域图像,利用人工智能中的动态神经网络方法从显著区域图像中选择显著区域[11]。
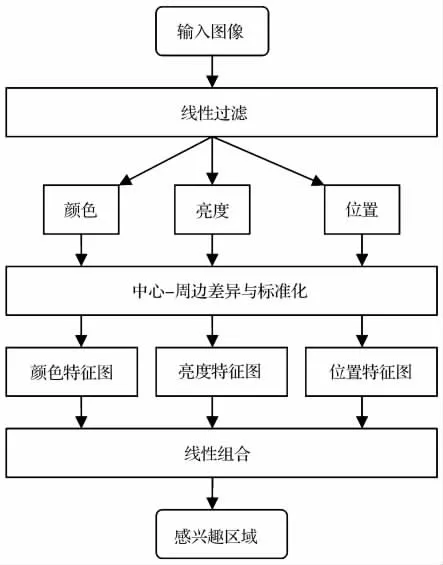
图2 视觉关注模型
(一)视觉特征提取
视觉关注模型中的输入图像必须是彩色图像,并且将输入图像分别通过高斯金字塔[12,13]和Gabor滤波器[14]获得颜色、亮度和位置[15]三种视觉特征。设r,g和b分别为颜色空间的值,且(r,g,b)∈[0,1,…,255],则亮度I=(r+g+b)/3,红色R=r-(g+b)/2,绿色G=g-(r+b)/2,蓝色B=b-(r+g)/2,黄色Y=(r+g)/2-|r-g|/2-b,位置O。输入图像中c的像素点与其s的像素点在视觉特征上的差值I(c,s),RG(c,s),BY(c,s)和O(c,s,θ)分别由公式(1)、(2)、(3)和(4)得到。
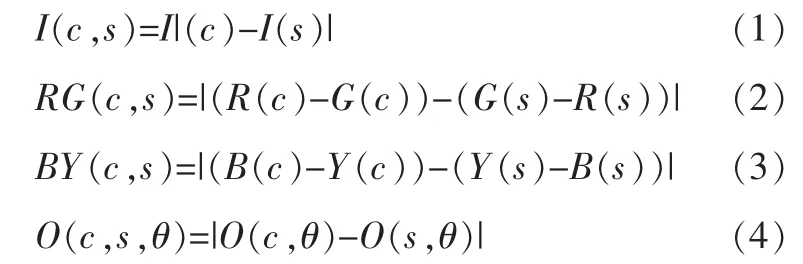
其中:角度θ∈{0°,45°,90°,135°},c是中心-周边模型中显著区域的中心,s是其它区域的周边。
(二)显著区域
视觉特征通过高斯金字塔和Gabor滤波器提取后,其亮度特征图I,颜色特征图C和位置特征图O由公式(5)、(6)、(7)得到。

其中:N为标准化操作。
设显著区域为S,其由公式(5)、(6)、(7)分别得到的亮度特征图、颜色特征图和位置特征图经过线性组合成一幅显著区域图像。S可通过公式(8)得到。
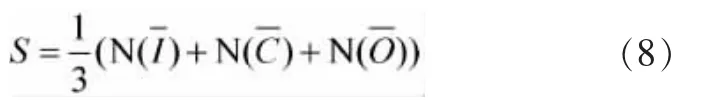
三、改进的视觉关注模型
视觉关注模型是在原有Itti的视觉关注模型基础上进行改进,改进之处是将视觉特征颜色、亮度和位置改为图像灰度级和图像边缘进行提取。本文提取图像灰度级和边缘特征的优点是既能改进原有的视觉关注模型,又利于图像拼接,尤其为本文中的图像重复显著区域配准提供依据。改进的视觉关注模型如图3所示。
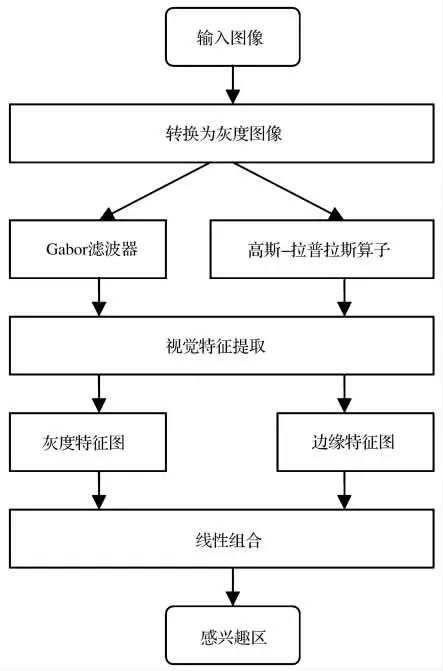
图3 改进的视觉关注模型图
首先对输入图像进行灰度变化得到灰度图像[16],再通过高斯-拉普拉斯算子[17]和Gabor滤波器[18]分别提取图像灰度级和图像边缘特征,并得到灰度特征图和边缘特征图,最后,将灰度特征图和边缘特征图进行线性组合,得到显著区域图像,并利用人工智能中的动态神经网络方法从显著区域图中选择显著区域。
(一)视觉特征提取
改进的视觉关注模型首先需要将输入图像转换为灰度图像,再分别通过Gabor滤波器和高斯-拉普拉斯算子获得灰度级和边缘两种视觉特征。输入图像中c的像素点与其s的像素点在视觉特征上的差值G(c,s)和E(c,s)分别由公式(9)和(10)得到。
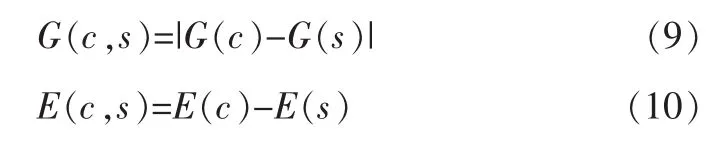
(二)显著区域
视觉特征通过Gabor滤波器和高斯-拉普拉斯算子提取后,其灰度特征图Gc和边缘特征图Ec由公式(11)、(12)得到。

其中:G(c,s)和E(c,s)分别由公式(9)和(10)得到。
设显著区域为S,其由公式(11)、(12)分别得到的灰度特征图和边缘特征图经过线性组合成一幅显著区域图像。S可通过公式(13)得到。
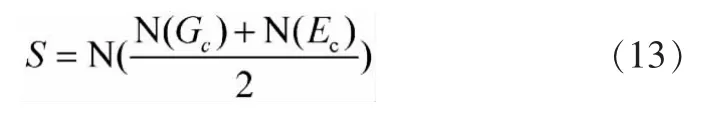
其中:N为归一化操作。
显著区域的确定为下一步图像配准奠定基础,是图像拼接的前提。
(三)基于显著区域的图像配准
图像拼接的质量主要依赖于图像的配准精度。图像配准是指依据一些相似性度量来决定图像间的变换参数,使从不同传感器、不同视角、不同时间获取的同一场景的两幅或多幅图像,变换到同一坐标系下,在像素层上得到最佳匹配的过程。在图像匹配过程中,本文方法通过迭代过程实现图像显著区域的寻优过程。首先,由改进的视觉关注模型算法得到输入图像的像素灰度值和确定显著区域S,并通过建立均值坐标确定显著区域内各像素的坐标,再将所有输入图像的显著区域进行图像配准,从备选拼接图像中挑选出与待拼接图像配准最佳的一幅。设图像A的显著区域为SA,图像B中的显著区域为SB,则两幅图像的显著区域匹配相关度由公式(14)判断。
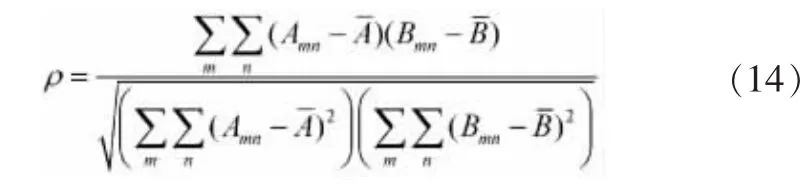
如果ρ越大,说明SB和SA的重叠概率越大,配准精确度越高。SB则被认为是待拼接图像的最佳匹配对象,从而实现兴趣区域的配准。
四、均值无缝克隆
传统的图像融合方法主要在时间域通过算术运算实现融合,而MVSC算法是直接利用一幅图像A的显著区域SA设为源克隆域和另外一幅图像B的待配准的显著区域SB设为目标克隆域进行融合,完成光滑无缝、浑然一体的图像拼接,这个过程加快了图像拼接速度和提高了图像拼接质量。
(一)融合区域的确定
利于改进的视觉关注模型算法分别确定图像A和图像B的显著区域SA和待配准的显著区域SB,对图像A中的显著区域SA设为源克隆域,图像B中的待配准的显著区域SB设为目标克隆域,确定源克隆域和目标克隆域之后,利用均值无缝克隆算法执行融合,使SA=SB,最后,完成两幅图像的无缝拼接。
(二)利用均值无缝克隆算法进行图像拼接
设SA⊂R2是图像 的源克隆域,SB⊂R2是图像B的目标克隆域。我们可以记为:
g:SA→R,f*:SB→R。
无缝克隆目的是将源克隆域SA与目标克隆域SB融合,使SA=SB。
无缝克隆实质是计算一个函数f:SB→R,并求解泊松方程:
换句话说,无缝克隆是寻求函数f与目标克隆域的∂SB一致,其梯度场边界是尽可能接近源克隆域g。
解决上述泊松方程等价于求解拉普拉斯方程,即:
△f′=0 狄利克雷边界条件:f′|∂SB=f*-g
假设目标克隆域内一点xϵSB与边界∂SB=(s0s1,…,sm= s0)。均值插值获得的值 是在边界∂SB在点x给出:
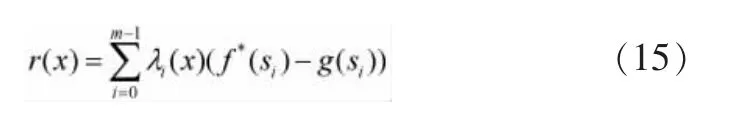
其中,
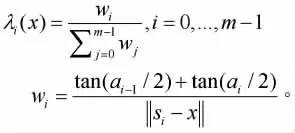
克隆的最终结果,用公式表示为:

无缝克隆算法
1:{预处理阶段 }
2:for每个像素xϵSAdo
3:{计算均值坐标λi(x)和∂SA}
4:λ0(x),…,λm-1(x)=MVSC(x,y,∂SA)//计算和存贮均值坐标
5:end for
6:for每一个新的SBdo
7: {计算差异边界}
8: for∂si的每个顶点si do
9: h=f*(si)-g(si)
10: end for
11: for每个像素xϵSBdo
12: {均值插值x}
14: f(x)=g(x)+r(x)
15: end for
16:end for
最后利用无缝克隆算法完成两幅图像的拼接。
五、基于改进的视觉关注模型和MVSC的图像拼接算法
利用改进的视觉关注模型算法确定拼接图像的显著区域,该方法能有效地从图像中提取视觉特征,并得到图像的像素灰度级和显著区域的轮廓。利用图像配准算法从备选拼接图像中检测出最为相似,最佳重叠的显著区域。最后,利用均值无缝克隆算法使其两幅图像的显著区域融合,完成两幅图像的拼接。基于改进的视觉关注模型和MVSC的图像拼接算法步骤如下。
1.输入图像并进行预处理。
2.利用改进的视觉关注模型算法分别对待拼接图像和备选图像提取视觉特征,得到显著区域和像素灰度值。
3.建立坐标分别确立待拼接图像和备选图像的显著区域坐标。
4.利用图像配准算法对待拼接图像和备选图像的显著区域进行配准,选出最佳配准图像。
5.根据得到的配准信息对计算出图像的变换参数,为下一步的均值无缝克隆提供依据。
6.根据配准算法提供的显著区域信息和最佳配准区域信息分别确立MVSC的源克隆域和目标克隆域。
7.利用本文中MVSC算法对源克隆域和目标克隆域进行融合,完成两幅图像的拼接,最后,得到全景图像。
六、实验
为了验证本文提出的基于改进的视觉关注模型和MVSC的图像拼接算法的有效性,分别进行三组实验,并采用三幅不同程度拍摄的自然景物图像。如图4所示,选择在室外拍摄的三幅图像(a)、(b)和(c),且它们分别两幅具有重叠区域的图像。图5中三幅图像(a)、(b)和(c)是利用传统方法基于模板匹配的图像拼接,虽然图像拼接效果很好,但与原始图像对照之后,会发现拼接后的图像存在信息重复,不能完整的反映原始图像。图5三幅图像(d)、(e)和(f)是利用本文中的算法实现的拼接结果图,与原始图像对照之后,拼接后的图像不存在信息重复。可见,本文算法与传统方法对比之后,本文算法拼接后的全景图能够完整的、平滑无缝和自然的反映原始场景,并成功做到了将配准后的图像合二为一,构成一幅整体的全景图像。


图4 待拼接图像

图5 (a)-(c)基于模板匹配的图像拼接(d)-(f)本文方法
实验结果表明本算法不仅能够实现图像拼接,还能准确实现图像中显著区域的融合,并很好的解决了传统方法遗留下的问题,实现了自动完整平滑的图像拼接,提高了图像拼接的质量。
七、结论与展望
本文提出了一种基于改进的视觉关注模型和MVSC的图像拼接算法,既能得到显著区域的精确配准,又能实现图像的完美融合。本文算法中改进的视觉关注模型有利于图像中显著区域的自动识别和提取。基于MVSC的图像克隆融合方法是目前一种新的、快速的融合方法,利用显著区域配准后的结果图像能快速完美的实现图像拼接。展望未来,图像拼接技术应该在提高算法的运算速度、拼接精度、自动化程度和鲁棒性等方面进行深入研究。
[1]Harris Chris,Stephens Mike.A combined corner and edge detector[C]//Proceedings of the Alvey Vision Conference, University of Manchester,Manchester,August 31-September 2,1988.Sheffield:University of Sheffield Printing Unit,1988:147-152.
[2]Smith S M,Brady J M.SUSAN:A new approach to low level image processing [J].International Journal of Computer Vision (S0920-5691),1997,23(1):45-78.
[3]L I Hui,Manjunath B S,Mitra S K.A contourbased approach to multisensor image registration[J].IEEE Trans on Image Proces-sing,1995,4(3):320-334.
[4]Lowe D G.Distinctive image features from scaleinvariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[5]Reddy S,Chatterj B N.An FFT-based technique for translation,rotation,and scale-invariant image registration [J].IEEE Trans on Image Process,1996,3(8):1266-1270.
[6]Itti L,Koch C and Niebur E 1998.A model of saliency-based visual attention for rapid scene analysis IEEE Trans.Patt.Anal.Mach.Intell.20 6.
[7]1:45pm-3:30pm-Visual,Cut,Paste,and Search - CoordinatesforInstantImage Cloning ; Farbman,Zeev;Hoffer,Gil;Lipman,Yaron;Cohen-Or,Daniel;Lischinski,Dani ACM Transactions on Graphics-TOG;07300301;2009;28(3):67-67.
[8]Itti L and Koch C 2001.Feature combination strategies for saliency-based visual attention systems J. Electron.Imaging 10 161-9.
[9]A.M.Treisman and G.Gelade, “A Feature-Integration Theory of Attention,”Cognitive Psychology,vol.12,no.1,pp.97-136,Jan.1980.
[10]Itti L 2000 Models of bottom-up and topdown visual attention PhD Thesis California Institute of Technology,Pasadena p 216.
[11]J.K.Tsotsos,S.M.Culhane,W.Y.K.Wai,Y. H.Lai,N.Davis,and F.Nuflo, “Modelling Visual Attention via Selective Tuning,”Artificial Intelligence,vol.78,no.1-2,pp.507-545,Oct.1995.
[12]Greenspan H,Belongie S,Goodman R,Perona P, RakshitS and Anderson C H 1994. Overcomplete steerable pyramid ?lters and rotation invariance IEEE Computer Vision and Pattern Recognition(Seattle,Washington).
[13]Adelson E H,Anderson C H,Bergen J R,Burt P J and Ogden J M 1984.Pyramid methods in image processing RCA Engineer 29 pp 33-41.
[14]Weber,D.M,Casasent,D.P.Quadratic Gabor filters for object detection [J].Image Processing,IEEE Transactions on,Volume:10,Issue:2,Feb.2001:218-230.
[15]M.I.Posner and Y.Cohen, “Components of Visual Orienting,”H.Bouma and D.G.Bouwhuis,eds. Attention and Performance,vol.10,pp.531-556. Hilldale,N.J:Erlbaum,1984.
[16]Itti L and Koch C 2000.A saliency-based search mechanism for overt and covert shifts of visual attention Vis.Res.40 1489-506.
[17]Burt P J and Adelson E H 1983.The Laplacian pyramid as a compact image code IEEE Trans.Commun. 31:532-40.
[18]Peifeng Hu,Yannan Zhao,Zehong Yang,Jiaqin Wang.Recognition of gray character using gabor filters [J].Information Fusion,2002.Proceedings of the Fifth International Conference on,Volume:1,8-11 July 2002 Pages:419-424 vol.1.
TP312
A
1008—3340(2011)01—0056—06
2010-05-26
郑艳飞,女,日照广播电视大学教学处助教。
李业伟,男,山东师范大学计算机学院。
猜你喜欢
环球时报(2022-09-20)2022-09-20
今日农业(2022年15期)2022-09-20
中等数学(2022年2期)2022-06-05
今日农业(2020年24期)2020-12-15
小学生学习指导(低年级)(2020年6期)2020-07-25
中国生殖健康(2019年11期)2019-01-07
小学生学习指导(低年级)(2018年9期)2018-09-26
疯狂英语·新读写(2018年2期)2018-09-07
辽宁经济(2017年3期)2017-05-04
空中之家(2017年3期)2017-04-10
