
基于语料库的中国高级英语学习者过程词汇使用研究
2010-12-07 07:19:12张霞
当代外语研究 2010年5期
张 霞
(1. 上海交通大学外国语学院,上海,200240 2. 山西大学外国语学院,太原,030006)
1. 概念
过程词汇源于长期存在的“共核词汇”(common core vocabulary)概念。早期的共核词汇研究以词频为基础,典型的有West(1953)编制的英语常用词总表(General Service List of English Words)。后续研究发现,某些高频词不仅频率高,分布范围也很广,因而得出下列结论:频率高分布广的共核词汇不受“图式”限制,因此意义也趋于多样化,就像化学反应中活泼的高价位金属元素,这些词在语言使用中的用途在于引出与话语图式有关的特殊概念,也就是图式词汇(Widdowson 1983:92-93)。Widdowson这样区别过程词汇与图式词汇:“过程词汇支持和确立了图式词区别图式和语用域的地位”。
过程词汇频率高、分布广且平均、意义多样化,一直受到语言和教学研究者的关注,但其意义多样化特征也使之成为二/外语习得的难点。本文的目的就在于设计一套有效的过程词汇抽取方案,来考察外语学习者和本族语者过程词汇使用的不同,并进一步提出教学方面的建议。
2. 抽取
过程词汇的抽取研究远远落后于图式词汇。但是鉴于两者分布特征上的互补性,图式词汇的抽取对过程词汇的抽取有重要参考价值。我们首先回顾三个有代表性的图式词汇抽取方案及其对过程词汇抽取的启发。
2.1 Strzalkowski指数
Strzalkowski(1994)提出一个用于计算特定术语对语料库中特定篇章重要性的指数tf·idf。这个指数与术语在特定篇章中出现的频率tf和术语在语料库中出现的篇章数的倒数idf成正比。而过程词汇与篇章数是成正比的关系,频率和分布范围的结合指标如tf·idf应能粗略区分出与篇章或话题无关的过程词汇,但还是无法捕捉过程词汇的全部分布特征。
2.2 关键词
关键词从功能和统计特征上都类似于上文提到的图式词汇和术语。一个词的“关键性”是建立在下列概念上的:如果特定词在特定篇章中的出现频率高于由参照语料库频率信息生成的预期频率(expected frequency),那么它就是该篇章的关键词(Scott 1999;李文中1998)。在Mike Scott开发的Wordsmith软件中,一个关键词要满足两个条件:
a. 它在特定篇章中的出现频率必须高于或等于一个指定的最低频率;
b. 它在特定篇章中与参照语料库中的频率必须在统计意义上显著不同,软件中使用的统计标准有卡方值(chi-square)和对数似然率(log -likelihood)。
以上方案的核心是参照语料库和预期频率概念的引入,参照语料库频率信息的加入是抽取过程词汇的又一项启发。
2.3 科技术语
科技术语和次技术词汇(sub-technical words)是图式词汇和过程词汇在学术篇章条件下的另一个翻版。杨惠中(1986:98)设计了一套参数以区分科技英语(EST)语料库中不同类型的词汇,前提是该语料库按学科分类。其中,distribution(D)是特定词在不同学科中的分布范围,average frequency(F)是该词在不同学科子库中出现频率的均值,relative standard deviation(SD)即上文均值与标准差的比值用以测量该词在子库中的频率分布情况,peakratio(P)和rangeratio(R)分别代表该词在子库中的最大频率与平均频率和最小频率的比值。杨惠中(1986)的研究显示,功能词和次技术词的SD值、P值和R值都相对较低,而科技术语的D值很低,P值和R值很高。这些信息都给本文的过程词汇抽取方案以很大启发。
3. 方法
3.1 过程词汇抽取方案的重要性
在此我们要再次强调过程词汇抽取方案设计的双重重要性:首先,如上文提到图式词汇的抽取过程研究相对成熟,如关键词和科技术语等,而过程词汇作为具有最普遍用法的最普遍词,其抽取工作的研究却远远落后于图式词汇;其次,过程词汇因其意义和使用的多样化是二/外语习得中的难点,设计一个行之有效的抽取方案可以帮助我们发现英语学习者使用过程词汇的特点和问题,对语言教学大有裨益。
3.2 本文采用的语料库
本文的研究对象是中国高级英语学习者的过程词使用,主要采用的英语学习者语料库是COLSEC(College Learners’ Spoken English Corpus)和CLEC(Chinese Learner English Corpus)的非英语专业大学生部分COLEC(College Learner English Corpus)。这两个语料库是英语学习者口语和笔语产出的姊妹库,也是目前为止最具代表性的中国非英语专业大学生英语产出的语料库。由于采用Granger(1996)的中介语对比分析法(CIA),本文采用的本族语对比语料库是BNC(British National Corpus)的会话部分和LOCNESS(Louvain Corpus of Native English Essays),后者是比利时Louvain大学建立的本族语大学生作文语料库,也是ICLE(International Corpus of Learner English)系列研究中常用的本族语笔语参照库。在经过“去码”(clean text)等一系列处理后,两个口语语料库均为560,000词左右,两个笔语语料库均为280,000词左右。
3.3 本文的过程词汇抽取方案
基于Widdowson(1983)的过程词汇概念并参考前人经验,本文的过程词汇抽取采取了3个统计标准:初选标准是频率,过程词必须在语料库中频繁出现,本文的标准是每个语料库的前150个高频词;第二和第三个标准分别考察词的分布范围和分布均匀程度。实现过程如下:
a. 把要研究的语料库尽量均匀和随机地分成7等分。以COLSEC为例说明随机标准的实现,COLSEC由302个独立篇章构成,编号从1到302;然后用一个随机数生成工具把这302个编号尽量平均地编为7组;再用随机生成的7组编号把原语料库编为7个子库。
b. 在随机生成的7个子库上用Wordsmith软件做详细的一致性分析(detailed consistency analysis)①分析,取得每个子库中都出现的前150个高频词在每个子库中的频率信息,这样取得的150个词满足了本文过程词汇的两个初选标准,分布范围广且出现频率高。
c. 把高频词在7个子库中的频率信息“统一化”(normalization②)处理之后,可以计算得到每个词的变异系数CV(coefficient of variance③),CV值小则意味着该词在7个子库中分布均匀,反之CV值大则意味着该词在7个子库中分布不均匀。将150词按CV值从小到大排列后取得的前100词即本文要研究的过程词汇样本。
以LOCNESS为例,建成的数据库大致如表1所示:

表1 LOCNESS过程词汇数据库示例
这样我们就尽可能地满足了Widdowson(1983)提出的高频、分布广且平均的判断标准。
4. 结果和分析
这部分中,我们将在两个层面上对比分析外语学习者与本族语者的过程词汇使用:较泛层面的过程词等级信息和更细一层的实虚词分布。前者使用的统计工具是秩相关和聚类分析,后者使用的是单因变量多因素方差分析。
4.1 过程词等级信息
我们已按照频率、分布范围和变异系数从各个语料库中抽取了100个过程词并加以排序,以表明特定词对特定语言使用的“共核”程度。然后编写了一个能够返回各词在各语料库中等级的小程式,对得到的等级信息进行秩相关分析,应用的系数是spearman’s rho。并在此基础上进行等级聚类分析,以揭示过程词汇等级信息在各语料库之间的相互关系。结果如表2和图1所示:

表2 四库100个过程词的秩相关分析
注:**在0.01水平上显著;*在0.05水平上显著.
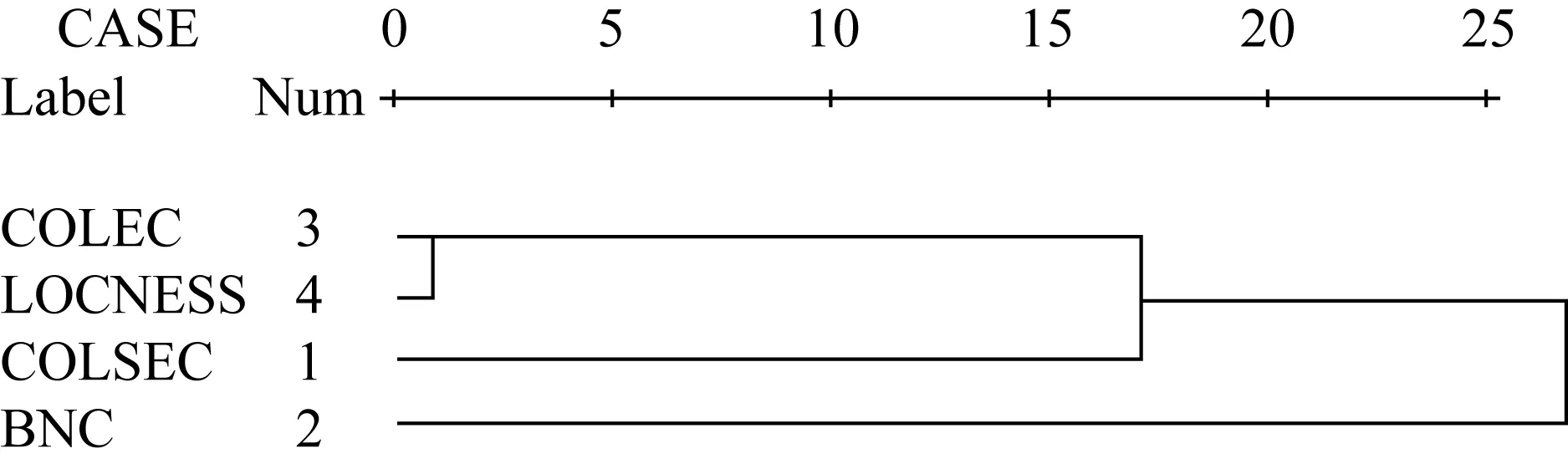
图1 100个过程词等级信息的四库聚类分析
从表2的相关系数矩阵和聚类分析树形图1中可以看出,英语学习者和本族语者的笔语在过程词汇使用上最为相近,相关系数为0.595;而英语学习者口语中的过程词使用与本族语口语相比,更为接近笔语簇的用法。
为进一步确认和丰富以上结论,我们又引入两个语料库抽取并建立了过程词数据库,FLOB(Freiberg LOB Corpus of British English)和COLEN(College English Corpus),与以上四库对比过程词汇的使用。与LOCNESS的本族语大学生笔语相比,前者代表更大范围和更多场景下本族语的笔语产出,后者则是Xue(2004)编辑的目前中国通用的四种大学英语教材语料库,用以检验英语学习者用法受教材用法的影响,两库大小均为1,000,000词左右。秩相关分析中除Spearman’s rho系数外我们还引入了另一考虑结点影响的系数Kendall’s tau_b,得出结果如图2和表3所示:
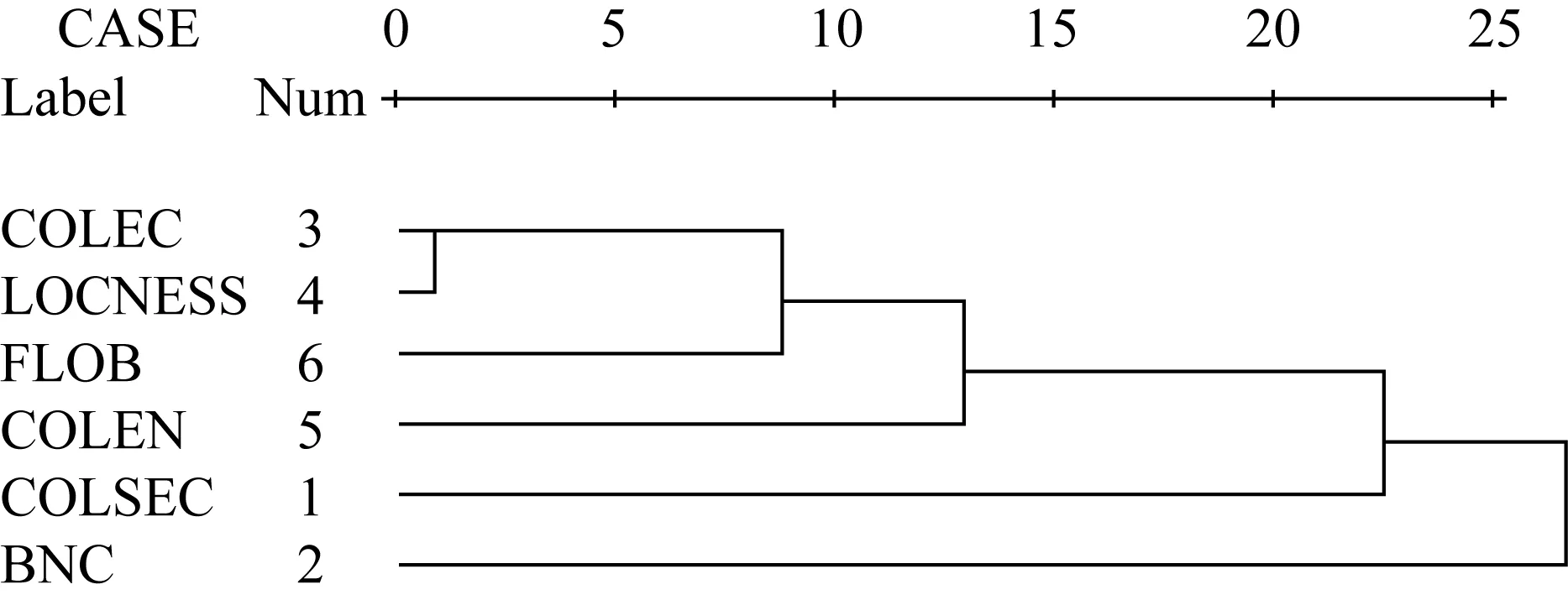
图2 100个过程词等级信息的六库聚类分析
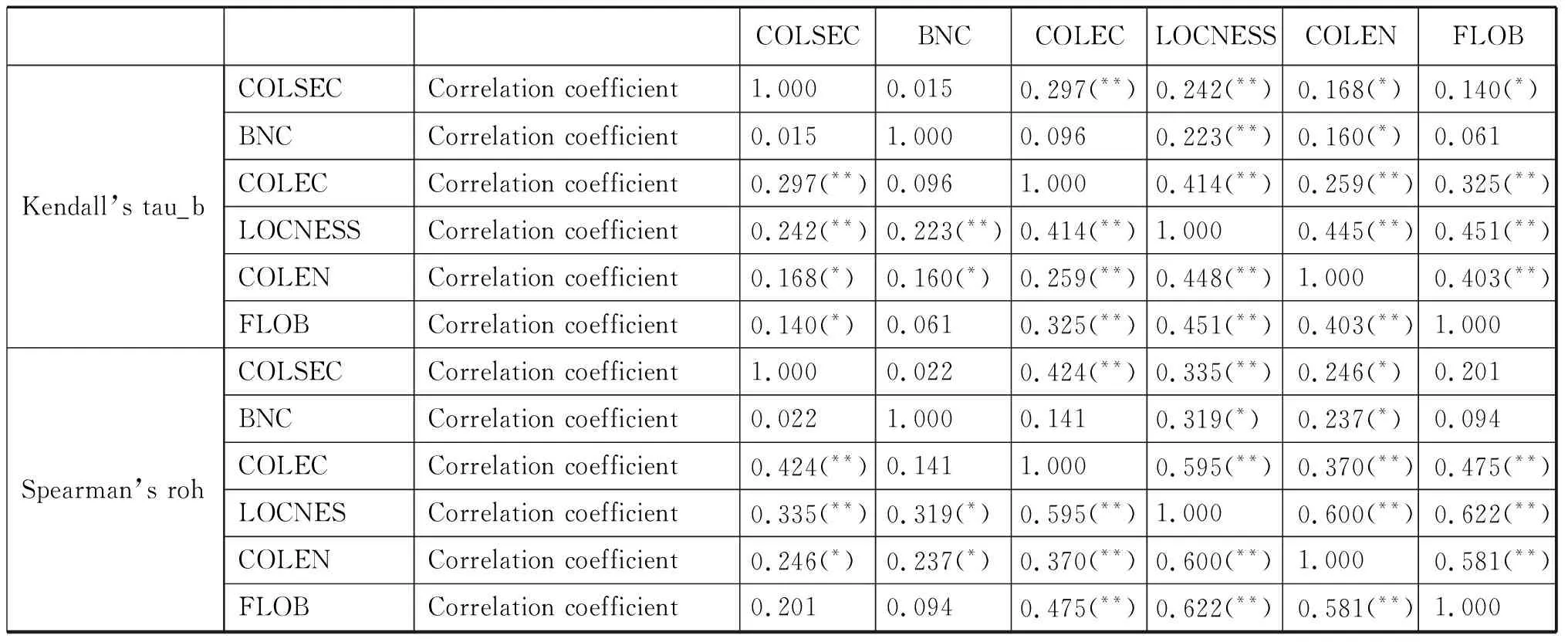
COLSECBNCCOLECLOCNESSCOLENFLOBKendall’s tau_bSpearman’s rohCOLSECCorrelation coefficient1.000 0.015 0.297(**)0.242(**)0.168(*)0.140(*)BNCCorrelation coefficient0.0151.0000.0960.223(**)0.160(*)0.061COLECCorrelation coefficient0.297(**)0.0961.0000.414(**)0.259(**)0.325(**)LOCNESSCorrelation coefficient0.242(**)0.223(**)0.414(**)1.0000.445(**)0.451(**)COLENCorrelation coefficient0.168(*)0.160(*)0.259(**)0.448(**)1.0000.403(**)FLOBCorrelation coefficient0.140(*)0.0610.325(**)0.451(**)0.403(**)1.000COLSECCorrelation coefficient1.0000.0220.424(**)0.335(**)0.246(*)0.201BNCCorrelation coefficient0.0221.0000.1410.319(*)0.237(*)0.094COLECCorrelation coefficient0.424(**)0.1411.0000.595(**)0.370(**)0.475(**)LOCNESCorrelation coefficient0.335(**)0.319(*)0.595(**)1.0000.600(**)0.622(**)COLENCorrelation coefficient0.246(*)0.237(*)0.370(**)0.600(**)1.0000.581(**)FLOBCorrelation coefficient0.2010.0940.475(**)0.622(**)0.581(**)1.000
注:**在0.01水平上显著;*在0.05水平上显著.
表2相关系数矩阵和聚类分析树形图2再次确认了以上结论,即笔语用法成簇。在0.01的显著水平下,三个笔语库(COLEC,LOCNESS,FLOB)的最低相关系数Spearman’s rho达到了0.475,而结点影响系数Kendall’s tau_b也达到了0.325。与本族语一般的笔语产出相比,本族语大学生的笔语产出更接近中国高层英语学习者的笔语产出。一个新的发现是,COLEN与其它各库的相关都显著,与LOCNESS相关系数最大,为0.600,与BNC相关系数最小,也达到了0.237。也就是说教材中的过程词使用是介于笔语簇和口语簇之间的一个独特变体,没有明显的聚类特征。
4.2 实虚词的分布
为了进一步考察不同语言社团中的过程词汇使用,我们又把四库中的过程词区别为实词和虚词两大范畴,并加以标注和统计。COLSEC和BNC即英语学习者和本族语口语中实虚词的比例分别为2∶3和1∶3,COLEC和LOCNESS即英语学习者和本族语笔语中实虚词的比例分别约为2∶3和1∶4,结果如表4所示:

表4 四库中过程词汇实虚词的统计信息
为进一步确认由实虚词比例得到的直观印象的统计显著性,我们首先作了2(英语学习者和本族语者)×2(实词和虚词)单因变量多因素方差分析(ANOVA)。结果显示,就过程词汇的实虚词分布而言,英语学习者和本族语者这两个语言使用团体有显著差别(F(1,3977)=23.997,p=0.000),这从统计意义上证实了我们的初步印象。
与本族语用法相比,英语学习者的过程词汇更可能是实词。可能的原因包括:第一、中国英语学习者不习惯使用虚词,因为作为母语的中文虚词极少;第二、英语学习者的用法不如本族语用法多样化,他/她们对于概念和语言形式的对应关系或语言使用因循性(conventionality)的掌握没有那么丰富的层次,导致他/她们的语言产出有时过于重复,有时又用已掌握的语法规则“过分生成”一些非母语式的用法。这些导致英语学习者用法的单调性,因此其统计意义上的过程词汇中出现高比例的实词。如果本族语者对于实词的过程化使用可以看做词汇的虚化或语法化过程,那么英语学习者对于实词的过多使用则有多重原因,如中介语的、二语内的和语际的原因等等;如果说本族语对实词的过程化使用是全社团的使用共性,那么英语学习者对实词的过度使用则更有可能是个人策略的规模化反映。
为进一步考察口笔语文体对过程词汇实虚词分布的影响,我们又做了4(COLSEC,COLEC,BNC和LOCNESS)×2(实词和虚词)单因变量多因素方差分析,结果再次显示语料库对过程词汇实虚词的分布具有显著影响(F(1,399)=13.557,p=.000)。
进行库与库之间的两两比较,我们发现,英语学习者的口笔语中过程词汇的实虚词分布模式相似,在两两比较统计意义上不显著(p=0.344),而其它各对都有显著不同(p<0.01)。本族语的口笔语比较实虚词分布有显著不同,笔语虚词使用更多,进一步证明英语学习者的文体意识还是有待发展。
5. 结论和展望
本文在Widdowson(1983)提出的过程词汇概念基础上提出了一套过程词汇的抽取方案④,并将之应用于英语学习者和本族语者的过程词汇使用考察中。较泛层面的秩相关和聚类分析结论如下:英语学习者和本族语的笔语在过程词汇使用上最为相近,相关系数为0.595(p=0.000);COLSEC与BNC,即英语学习者口语中的过程词使用与本族语口语相比,更为接近笔语簇的用法。更细层面的各库过程词汇实虚词分布的方差分析结论如下:就过程词汇的实虚词分布而言,英语学习者和本族语者这两个语言使用团体有显著差别,英语学习者的过程词汇更可能是实词,这可能是英语学习者用法单调和母语中虚词用法较少导致;英语学习者的口笔语中过程词汇的实虚词分布模式相似,而本族语的口笔语比较,笔语虚词使用更多,英语学习者的文体意识有待发展。
当然,抽取出的过程词汇数据库的应用还不止这些,还可以做更深层次的比较分析,如围绕各具体词的词块(lexical chunk),词性码串(POS tag sequence)和搭配(collocation),类联结(colligation)的研究。过程词汇的分布模式决定了它与语言使用因循性的密切联系,以上各个层面的研究一定会有更丰富的成果,揭示英语学习者过程词汇使用和语言使用因循性掌握的特点和问题,对语言教学实践的启示也会更加具体。
附注:
① 一致性分析是Wordsmith的一项功能,可以找到在特定语料库所有子库中都出现的词,分为简单和详细两种模式。详细的一致性分析能显示特定词在各子库中的频率信息。
② 统一化处理就是把不同规模语料及其生成的频率信息按比例统一到相同的基础上,以使频率信息有可比性。本文
的统一化标准是100,000词,即7个子库的频率信息都按比例调整为相应的100,000词语料中的预期比例。
③ 在概率理论和统计学中变异系数(CV)是一个用以测量概率分布的统一化尺度,定义为标准差σ与平均值μ的比值:CV=σ/μ。
④ 需要获取从四库中抽取的过程词汇范例者请与作者联系。
Scott, M. 1999.WordsmithV3.0Manual[M]. Oxford: Oxford University Press.
Strzalkowski, T. 1994. Document Representation in Natural Language Text Retrieval [R]. Human Language Technology Conference, Plainsboro, New Jersey.
West, M. 1953.AGeneralServiceList[M]. London: Longman.
Widdowson, H. G. 1983.LearningPurposeandLanguageUse[M]. Oxford: Oxford University Press.
Willis, D. 1990.TheLexicalSyllabus:ANewApproachtoLanguageTeaching[M]. London: Collins COBUILD.
Xue, X. 2004. The Pedagogic COLEN Corpus and Corpus-orientated Website Construction [R]. The 4th International Symposium on ELT in Beijing, China.
李文中.1998. An Analysis of the Lexical Words & Word Combinations in the College Learner English Corpus [D]. Ph.D. dissertation, Shanghai Jiaotong University.
杨惠中.1986. A new technique for identifying scientific/technical terms and describing science texts: an interim report [J].LiteraryandLinguisticComputing(2): 93-103.
猜你喜欢
河北画报(2021年2期)2021-05-25 02:06:18
中文信息学报(2019年7期)2019-08-05 02:28:16
艺术评论(2017年12期)2017-03-25 13:48:00
文贝:比较文学与比较文化(2016年1期)2016-11-14 05:00:41
外语教学理论与实践(2016年4期)2016-06-11 06:05:18
新疆大学学报(哲学社会科学版)(2015年6期)2015-10-12 03:00:00
亚太教育(2015年23期)2015-08-12 02:30:07
外语教学理论与实践(2015年1期)2015-06-11 02:51:06
语文教学与研究(2014年8期)2014-02-28 21:54:53
中国文学研究(2012年4期)2012-01-19 13:42:55
