
基于语义的监控系统的应用研究
2010-10-17 07:47:04邱泽国唐季华
哈尔滨商业大学学报(自然科学版) 2010年2期
邱泽国,唐季华
(哈尔滨商业大学计算机学院,哈尔滨150076)
基于汉语主题词表和各学科或专业主题词表,建立一个以主题词为骨架、辅以全面的自由词面的自由词,并标示出包括所有主题词和自由词之间的用、代、属、分、参关系,可形成内容比较完善的后控词表[1].它不仅可以适应用户输入的非规范化用词,提高查全率和检索效率,通过词间概念等级关系和族性关系,方便地进行上、下位词的检索从而实现扩检和缩检,还可在一定程度上实现语义关联检索,充分发挥主题词检索的优越性.但是,建立后控词表是一项技术难度和工作量都比较大的工作,而且随着时间的推移,新词不断呈现,词表如何自动更新,即词表自学习功能也一直是一个难题.
目前,后控制词表中的参照关系,主要是依据汉语主题词表或各学科专业的主题词表中收录的“参”关系设置的[2].此种设置方式有两大不足:一是收入的参照关系有限,二是词间的参照关系过于严密,无论是主题词之间或是主题词与自由词之间,被参照的词往往还是不够“自由”,带有比较重的书面色彩[3].这就给概念的相关检索和参照检索带来一定难度.
1 整体结构
为了满足安全和访问要求等相关需求,必须在每个生产主机的产品用户下部署UserAgent,用于对产品进程的直接操作,这样不用考虑提供主机系统用户/密码等;
同时在生产环境中独立部署服务器(独立的物理主机),并在其上部署通讯中间件和运维服务进程等;
服务器上不部署DB,需要存取的数据记录为数据文件方式,同时考虑到平台支持,应该可做快速移植;
需要的所有配置信息(操作主机配置、操作员用户/密码、任务计划定义等)都可以存放到其中的配置数据文件中;
UserAgent,服务Server和终端Terminal都通过通讯中间件相互连通,见图1.

图1 整体结构示意图
UserAgent和服务都必须要求可以7×24小时运行,同时自身非常稳定,另外UserAgent因为被直接部署在生产主机上为此必须十分稳定且资源消耗小和平稳;
在Windows平台下,UserAgent应该是以Service方式运行的,并可随机器一道启动;
在UNIX平台下,UserAgent应该是以DAEMON方式运行的,并可随机器一道启动.
2 软件设计与实现
由于UserAgent可直接访问当前用户下的资源,所以为了方便开发和管理维护,在UserAgent上需要开发一系列可靠简易的调用接口,建议做法是:
Shell脚本调用接口,定义Shell脚本的名称和调用要求,并要求Shell脚本将输出结果或信息反馈到某确定文本(结果日志)中,调用者UserAgent可以在Shell脚本调用结束后,通过读取结果信息日志文本获得最可靠的结果回应[4].
回应结果的解读必须是严格可靠的,为此需要设定严谨的消息格式,这样可以保证解析的结果信息准确可信.而对结果的实际解析可以不由UserAgent负责,可以回应给服务的模块来完成.
UserAgent的开发必须完全统一,即在不同平台或主机下,只能有一种UserAgent的实现,尽量不要开发不同个性功能的Useragent实现,这样才能很好保证其可靠和稳定性,同时也能大大简化开发工作量,为此UserAgent不能过于关心功能的差异性细节[5],见图2.
为此在功能设计方面我们可以借鉴Ant的思路,在服务模块规划和定义Target,每个Target包含若干需要顺序执行的Task,而每个Task需要定义如下信息:UserAgent的标识,即AgentID或请求功能号;任务参数,可能需要的请求参数;每个任务调用都有返回结果,为了统一调用接口,建议各种任务的请求参数和返回结果都使用固定字段.
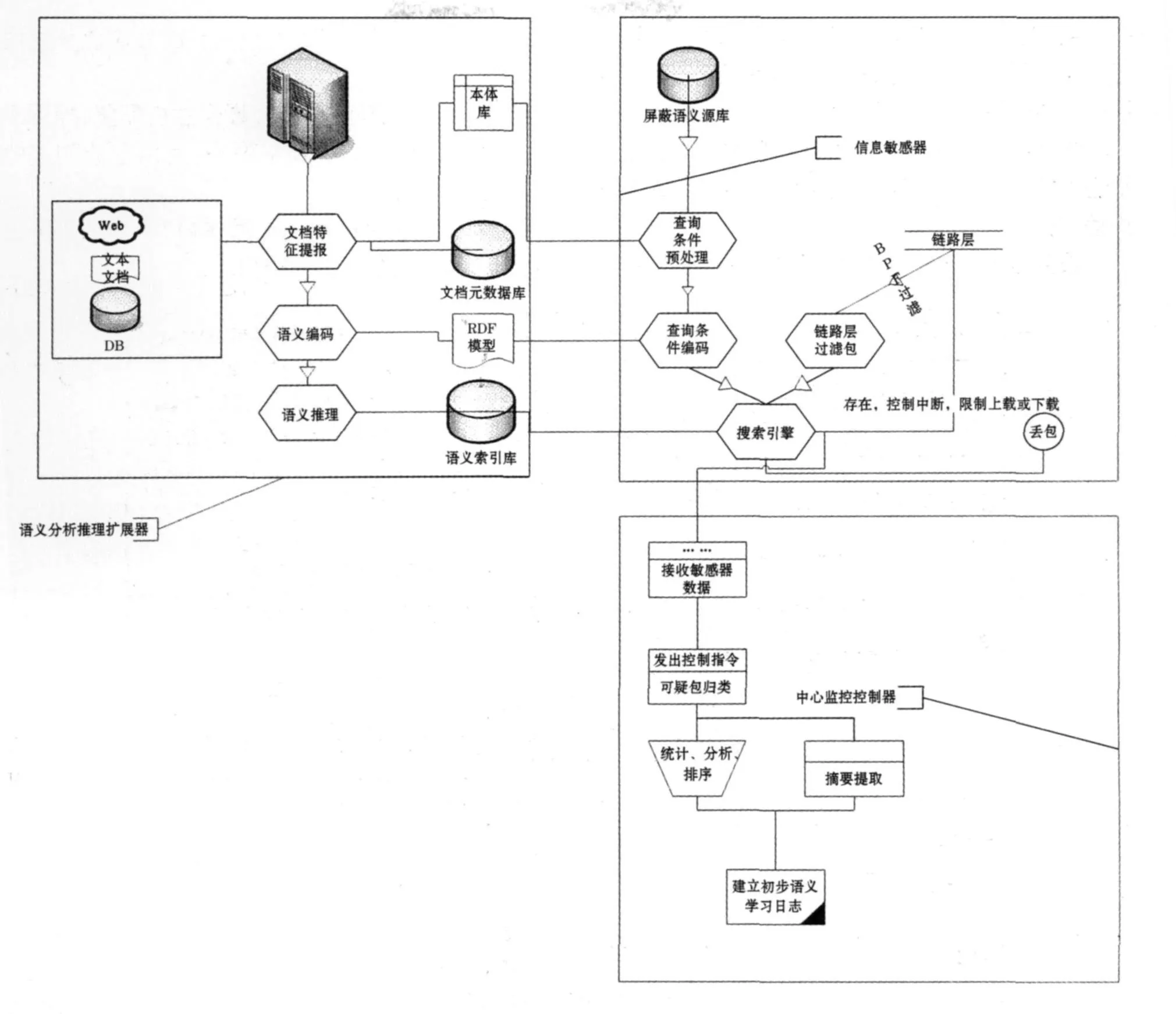
图2 软件设计与实现示意图
这样在服务模块里,任何操作就是一个Target,而执行Target时就是顺序执行其下的一系列事先定义好的Task,每个Task都有请求和应答,如果在一个Target的执行过程中,任何一个Task失败,那么整个Target就失败.
3 目标任务调用模式
对于每个被调用Task,其UserAgent都会转化为一个实际的Shell脚本的运行,由于执行Shell脚本存在时间周期等待的可能,而等待时间也会有很多差异,为此如果采用请求/应答的完全同步模式可能不够稳定,所以可以考虑将一个任务的完成过程分为两步骤来进行:
第一阶段为任务发起准备,由服务发送任务准备执行指令(一般需要设定一个惟一的任务流水号,便于未来做跟踪和检查)给某UserAgent,UserAgent收到后,做执行Shell脚本前的准备和检查工作,如果可以执行就应答给服务为准备就绪,如果有问题则应答准备失败;这个应答由于检查和准备工作很少,所以可以快速给予回应;服务受到相应应答后就可以作出该任务的执行状态更新或相关工作;
第二阶段为任务执行和结果汇报,由UserAgent在准备完成后可迅速开始进行Shell脚本的执行,待脚本执行完成后,同时对执行结果收集好后,获得当前该执行任务的反馈结果信息,就把该信息发服务(返回信息里必须包含当前任务的唯一流水号),服务通过该回馈信息可以迅速更新对应任务状态,这样可以驱动任务所在目标流程的后续任务驱动;
通过这种两阶段异步模式,可以使目标流程和各个任务的执行情况得到迅速跟踪,并且可以避免请求/应答方式下长时间等待,为此还需要UserAgent提供一些相关的任务查询接口,如按任务流水号查询某任务的执行状态或情况.任务流水号可以由UserAgentID+任务标识+日期+时间值等来全局惟一表示,而且该号可以用于其他用途.
另外对于一个任务,其对象状态大致可以为:初始Init、执行中Running、执行成功Success、失败Failure;如图3所示.

图3 目标任务调用模式示意图
在任务对象执行管理的基础上,目标流程的定义管理就相对清晰了.一般可严格要求,任何流程都是没有分支的,就象以前用Ant脚本编写的Target一样,而且不允许服务同时执行多个目标流程,这样便于我们隔离错误和问题,防止出现不可预估的情况.
本实验选用Protégé3.0作为本体建模工具,Protégé3.0是由斯坦福大学的Stanford Medical Informatics开发的一个开放源码的本体编辑器[6],它是用Java编写的.其界面风格与普通Windows应用程序风格一致,易学易用[3].在Protégé3.0编辑器中,本体结构以树形的层次目录结构显示,用户可以通过点击相应项来编辑或增加类、子类、属性、实例等本体元素,另外,用户可以不用考虑具体的本体描述语言,而在概念层次上设计领域本体模型.
在构建本体和组织存储实例数据之后,就需要在应用程序中对其进行解析和应用.在本体数据读取、语义推理和信息检索时,ISearch系统主要采用了惠普实验室开发提供的Jena 2.1API接口方法.
Jena是一种用来构建语义万维网应用的Java框架,它提供了有关操作RDF、RDFS和OWL的接口方法以及基于规则的推理引擎编程环境,而且Jena还是一个开源项目,目前由惠普语义网络实验室负责开发,在Jena框架中主要提供了以下的一些Java包、接口和方法.
◦RDF应用编程接口;
◦提供读写各种语法形式的RDF文件,包括RDF/XML、N3等格式;
◦提供操作OWL文件的应用编程接口;
◦提供基于内存和持久存储两种方式;
◦提供了一种RDF实例数据查询语言——RDQL;
在ISearch系统中主要使用了Jena中的如下两个包中的方法:
◦com.hp.hpl.jena.rd f.model——其中提供了大量有关创建和操作RDF图的方法;
◦com.hp.hpl.jena.vocabulary——其中包含了在RDF和OWL规范中,所定义的Resource对象和Property对象,如RDF类和OWL类等[5].
为了实现系统中表示层和逻辑处理层之间的分离,在设计人机界面时,ISearch系统采用Velocity模板语言.
Velocity是一个基于Java的模板引擎(temp late engine).它允许任何人可以通过简单的使用模板语言(temp late language)来引用在Java代码中所定义的对象实例.当Velocity应用于Web开发时,界面设计人员可以和Java程序开发人员同步开发一个遵循MVC架构的Web站点,也就是说,页面设计人员可以只关注页面的显示效果,而由Java程序开发人员关注业务逻辑编码.Velocity真正的做到了系统控制层和人机交互界面的分离,这种分层的设计模式有利于web站点的长期维护.
◦采用Servlet、HTML、JavaScript、Applet、XML实现界面表示层功能.
◦采用Session Bean实现业务逻辑层功能.
◦利用应用服务器的JDBC(Java Database Connectivity)驱动实现数据访问层功能.
◦采用JMS(Java Messaging service)实现消息服务.
4 结 语
根据用户检索需求的特点并结合了语义网的相关知识,提出了一种基于特定问题的概念关联检索思路,目前从技术上实现起来主要有以下难点:
相关领域本体的构建.本体是共享概念模型的明确的形式化规范说明,而领域本体的目标是捕获相关的领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇,并从不同层次的形式化模式上给出这些词汇(术语)和词汇之间相互关系的明确定义.而构建具有良好的概念层次结构和对逻辑推理的支持,能在基于语义的检索中有广泛应用的领域本体是一个复杂的工程,检索领域目前应用较多的还是比较初级的词表等形式.
扩展参照检索的算法.由于参照的是一个主题模式而不是几个相关的词,因此对模式的匹配需要有新的策略,而模式本身的复杂的概念体系也要求检索过程必须采取一定的策略,如关联层级限制,来保证输出结果集的精练.
结果排序.由于不再是基于关键词的匹配,其输出结果需要按照语义相关度来排序.文中目前提供的排序方式还只是一种基于位置的简单处理,很难从语义层面体现相关性的重要程度.
概念检索主要包含了两个方面的内容,即同义扩展检索和相关概念联想.因此,相关概念的关联和参照检索是概念检索的重要研究内容.基于问题的语义关联的扩展参照检索,实际上是一种概念关联检索.要构建出实用的概念关联检索系统,还必须进一步结合语义网、本体论以及AI领域的NLP等语义层面的表示及推理技术
[1]HANAN U.Information Filtering:Overview of Issues,Research and Systems[J].User Modeling and User-Adapted Interaction 2001,11:203-259.
[2]COHENW.Fast effective rule induction[C]//Machine Learning:Proceedings of the Twelfth International Conference,Lake Taho,California,Mongan Kanfmann,1995:115-123.
[3]QUINLAN JR.Induction of decision trees[J].Machine Learning,1986,(1):81-106.
[4]于 玲,吴铁军.集成学习:Boosting算法综述[J].模式识别与人工智能,2004,17(1):52-59.
[5]王海川,张丽明.一种新的Adaboost训练算法[J].复旦学报:自然科学版,2004,43(1):27-32.
[6]黄萱菁.基于向量空间模型的文本过滤系统[J].软件学报,2002,13(4):15.
[7]郭 耸,洪炳镕,陈凤东.基于嵌入式Linux和Web服务器的网络视频监控系统[J].哈尔滨商业大学学报:自然科学版,2005,21(6):736-738.
猜你喜欢
作文小学中年级(2022年11期)2022-11-25 09:52:08
英语世界(2021年13期)2021-01-12 05:47:51
课堂内外(小学版)(2020年11期)2020-12-04 06:38:44
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
电子测试(2018年14期)2018-09-26 06:04:24
中学生(2017年19期)2017-09-03 10:39:07
信息安全研究(2016年4期)2016-12-01 06:07:05
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
中国信息化·学术版(2013年1期)2013-05-28 05:53:24
