
数据挖掘在网络入侵检测系统中的应用
2010-09-25 02:29:12鄢志辉
重庆电子工程职业学院学报 2010年3期
蔡 勇,鄢志辉
(重庆大学 软件工程学院,重庆 400019)
数据挖掘在网络入侵检测系统中的应用
蔡 勇,鄢志辉
(重庆大学 软件工程学院,重庆 400019)
探讨了网络入侵检测中应用数据挖掘技术的可行性和必要性,提出一种基于数据挖掘的入侵检测系统模型,并对该模型中数据挖掘算法进行研究,提出该系统应用Apriori算法的改进思路,实现入侵检测自动化,提高检测效率和检测准确度。
入侵检测;数据挖掘;数据库安全;Apriori算法
随着计算机网络技术不断发展,对网络上包含重要资料的数据库服务器的各种入侵问题也随之大量产生。常规防火墙只能通过限制数据库服务器部分网络功能的方法来保证安全,而对于在开放服务内的入侵却无能为力。传统的入侵检测技术有两种,即滥用检测和异常检测。其中,滥用检测是分析各种类型的攻击手段,找出可能的“攻击特征”集合,可有效检测到已知攻击,产生误报较少,缺点是只能检测到已知的入侵类型,而对未知的入侵类型无能为力,需要不断更新攻击特征库;异常检测的假设条件是通过观察当前活动与系统历史正常活动情况之间的差异来检测攻击行为,其优点是可检测到未知攻击,缺点是误报和漏报较多。针对现有网络入侵检测系统的一些不足,将数据挖掘技术应用于网络入侵检测,可实现入侵检测自动化,提高检测效率和检测准确度。
1 入侵检测系统引入数据挖掘的好处
最早将数据挖掘技术应用于入侵检测领域的是Wenke Lee研究小组,他们在1998年首次将数据挖掘技术应用于入侵检测系统。从他们提供的大量实验和测试结果表明,将通用的数据挖掘技术应用于入侵检测系统,在理论上和技术上是完全可行的。基于数据挖掘的入侵检测分析技术与其他分析技术不同之处在于,该方法是以数据为中心,将入侵检测看成一种海量安全审计记录数据的分析与处理过程,即使根本不知道各种攻击手段的作用机制,也可以从安全审计数据本身所隐藏的规律中发现异常行为,从而使入侵检测系统具有更好的自学习、自适应和自我扩展的能力。与传统入侵检测力法相比,基于数据挖掘的入侵检测分析技术有以下几个特点: (1)智能性好,自动化程度高。基于数据挖掘的检测方法采用了统计学、决策学以及神经网络等多种方法,自动地从数据中提取手工难以发现的行为模式,从而减少人的参与,减轻入侵检测分析员的负担,同时也提高了检测的准确性。(2)检测效率高。数据挖掘可以通过对数据进行预处理,抽取数据中的有用部分,有效的减少数据量,因而检测效率较高,对于现在数据库和网络庞大数据量的入侵检测系统来说,这一点在实际应用中也是至关重要的。(3)自适应能力强。应用数据挖掘方法的检测系统不是基于预定义的检测模型,所以自适应能力强,可以有效地检测新型的攻击以及已知攻击类型的变种。
2 基于数据挖掘的入侵检测系统模型构思
针对现有入侵检测系统挖掘速度慢和挖掘准确度不高的缺点,利用Snort入侵检测系统模型和Apriori算法为基础,提出一种基于数据挖掘的入侵检测系统模型,该模型的结构如下图1所示。

2.1 模块功能简述
(1)嗅探器主要进行数据收集,它是检测系统中抓取信息的接口。
(2)解码器解码分析捕获的数据包。并把分析结果存到一个指定的数据结构中。
(3)数据预处理负责将网络数据、连接数据转换为挖掘方法所需的数据格式,包括:进一步的过滤、噪声的消除、第三方检测工具检测到的已知攻击。利用误用检测方法对已知的入侵行为与规则库的入侵规则进行匹配,从而找到入侵行为,进行报警。
(4)异常分析器通过使用关联分析和序列分析找到新的攻击,利用异常检测方法将这些异常行为送往规则库。
(5)日志记录保存2种记录:未知网络正常行为产生的数据包信息和未知入侵行为产生的数据包信息。
(6)规则库保存入侵检测规则,为误用检测提供依据。
(7)当偏离分析器报告有异常行为时,报警器通过人机界面向管理员发出通知,其形式可以是E-mail。控制台报警、日志条目、可视化的工具。
(8)特征提取器对日志中的数据记录进行关联分析,得出关联规则,添加到规则库中。
2.2 异常分析器简述
异常分析器使用聚类分析模型产生的网络或主机正常模型检测数据包。它采用K-Means算法作为聚类分析算法,其异常分析流程如图2所示。

异常分析器的检测过程为:(1)网络或主机数据包标准化;(2)计算网络数据包与主类链表中聚类中心的相似度:(3)若该网络数据包与某一主类的相似度小于聚类半径R,则表明其是正常的网络数据包,将其丢弃;(4)若该网络数据包与所有主类的相似度大于聚类半径R,则表明其是异常的网络数据包,发现异常。
2.3 特征提取器简述
特征提取器用于分析未知的异常数据包,挖掘网络异常数据包中潜在的入侵行为模式,产生相应的关联规则集,添加到规则库中。该模块采用Apriori算法进行关联规则的挖掘,其工作流程下图3所示。
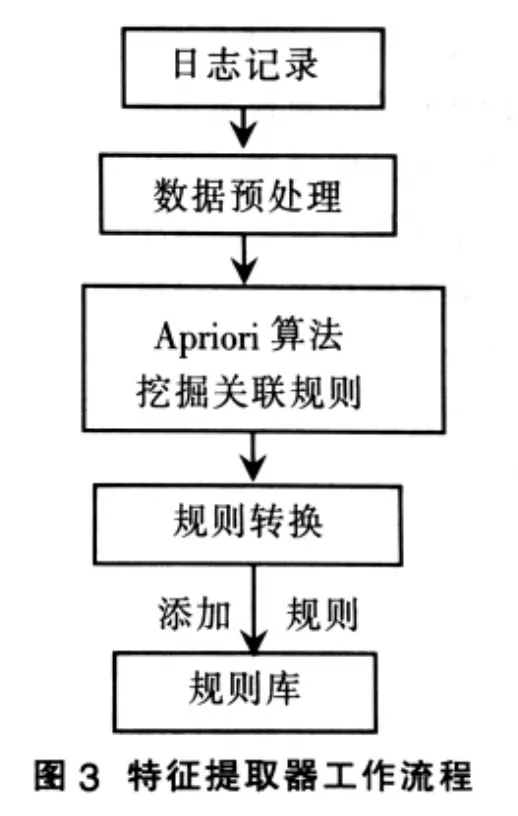
特征提取器的工作过程可分为数据预处理和产生关联规则。
(1)数据预处理特征提取器的输入为日志记录,包含很多字段,但并非所有字段都适用于关联分析。在此仅选择和Snort规则相关的字段,如SrcIP,SrcPort,DstIP,Dst-Port,Protocol,Dsize,Flags和CID等。
(2)产生关联规则首先根据设定的支持度找出所有频繁项集,一般支持度设置得越低,产生的频繁项集就会越多;而设置得越高,产生的频繁项集就越少。接着由频繁项集产生关联规则,一般置信度设置得越低,产生的关联规则数目越多但准确度不高;反之置信度设置得越高,产生的关联规则数目越少但是准确度较高。
2.4 系统模型特点
该系统在实际应用时,既可以事先存入已知入侵规则,以降低在开始操作时期的漏报率,也可以不预先存入已知规则。虽然该系统有较强的自适应性,但在操作初期会有较高的误报率。因此该系统模型有如下特点:(1)利用数据挖掘技术进行入侵检测;(2)利用先进的挖掘算法,使操作接近实时;(3)具有自适应性,能根据当前的环境更新规则库;(4)不但可检测到已知的攻击,而且可检测到未知的攻击。
3 Apriori算法的基础思想及改进思路
关联规则技术是最早应用于入侵检测中的数据挖掘技术,关联规则技术用来获得系统审计数据中各属性之间的关系,确定构造入侵检测系统所需要的合适属性,提出某种操作和入侵行为之间,或者是各种入侵行为之间的相互关系。作为分析数据间隐含的相互关联关系的有力工具,关联规则技术在入侵检测领域中已显现出极大的优越性。在该入侵检测模型中,就采用比较成熟的Apriori算法进行运算,运用到实际中,可以将该算法进行一些改进。
3.1 算法思想
Apriori算法是一种最有影响的挖掘布尔型关联规则的算法,其基本思想是将关联规则的挖掘分为如下两步:第一步,从事务数据库D中找出所有支持度不小于用户指定的最小支持度阀值的频繁项目集;第二步,使用频繁项目集产生所期望的关联规则,产生关联规则的基本原则是其置信度不小于用户指定的最小置信度阀值。第一步挖掘出所有的频繁项目集合是该算法的核心,占据整个计算量的大部分。在挖掘频繁项目集的过程中主要利用了两个性质:频繁项目集的所有非空子集也是频繁项目集;非频繁项目集的任何超集都是非频繁项目集。Apriori算法使用了一种逐层搜索的迭代方法,首先找出所有频繁1-项目集L1,L1用来找频繁2-项目集L2,L2用来找频繁3-项目集L3,如此下去,直到不能找到频繁项目集为止。具体来讲,Apriori算法的第一步是简单统计所有含一个元素的项目集出现的频率,来决定频繁1-项目集;在第k步,分两个阶段,首先调用函数Apriori-Gen,通过第(k-1)步中生成的频繁(k-1)-项目集Lk-1来生成候选频繁k-项日集Ck,其次扫描事务数据库D计算候选频繁k-项日集Ck中各元素在D中的支持数或支持度。
3.2 算法改进
可以利用数据划分技术来挖掘频繁项目集,从而只需扫描整个数据库两次。包含两个主要处理阶段第一阶段,算法将交易数据库D分为n个互不相交的部分,若数据库D中的最小支持阀值为min_sup,对于每个划分(部分),挖掘其中所有的频繁项集,它们被称为是局部频繁项集。可以利用一个特别的数据结构记录包含这些频繁项集的交易记录的TID以便使得在一次数据库扫描中就能够发现所有的局部频繁k-项集,k=1,2,…。就整个数据库D而言,一个局部频繁项集不一定就是个局频繁项集,但是任何全局频繁项集一定会出现在从所有划分所获得的这些局部频繁项集中,这一点可通过反证获得。因此可以将从n个划分中所挖掘出的局部频繁项集作为整个数据库D中频繁项集的候选项集。在第二阶段中,再次扫描整个数据库以获得所有候选项集的支持频度,以便最终确定各频繁项目集各划分大小和数目可以以每个划分大小能够整个放入内存为准,因此每个阶段只需读入一次数据库内容,而整个挖掘就需要两次扫描整个数据库。
4 结 语
借助数据挖掘技术在处理大量数据特征提取方面的优势,基于数据挖掘的入侵检测系统模型可使入侵检测更加自动化,提高检测效率和检测准确度。目前,基于数据挖掘的入侵检测已得到快速发展,但仍未得到广泛应用,虽然已经提出了基于Apriori算法的各种实施办法,但尚未具备完善的理论体系。因此,解决数据挖掘的入侵检测实时性、正确检测率、误警率等方面问题还有待大规模应用后的实践测评,通过测评数据来丰富和发展现有理论,完善入侵检测系统使其全面投入实际应用。
[1]徐兴元,傅和平,熊中朝.基于数据挖掘的入侵检测技术研究[J].微计算机信息,2007(9).
[2]朱海霞.数据挖掘在入侵检测中的应用[J].科技资讯,2009(25).
[3]刘荫铭,李金海,刘国丽.计算机安全技术[M].北京:清华大学出版社,2000.
责任编辑 王荣辉
Comment on the Application Technique of Date Mining in IDS
CAI Yong,YAN Zhihui
(School of Software Engineering,Chongqing University,Chongqing 400019,China)
The essay discussed the feasibility and necessity of applying Date Mining in intrusion detection,and advanced a IDS model basing on Date Mining,researching the basic algorithm of the model in Date Mining,putting forward the improvement approach of the system applying Apriori algorithm,which was in order to accomplish the automate of intrusion detection and improve the detective efficiency and detective accuracy.
intrusion detection;Date Mining;access security;Apriori algorithm
TP39
A
1674-5787(2010)03-0164-03
2010-03-10
蔡勇(1979—),男,重庆永川人,重庆大学软件工程学院软件工程专业2008级硕士研究生;鄢志辉(1982—),男,四川邻水人,重庆大学软件工程学院软件工程专业2008级硕士研究生。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
网络安全和信息化(2018年4期)2018-11-09 12:01:54
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
中国新通信(2014年11期)2014-09-11 19:27:52
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电子设计工程(2014年18期)2014-02-27 12:00:13
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
电子设计工程(2011年24期)2011-06-09 10:15:02
