
分层聚类算法在文本挖掘中的应用
2010-08-07 08:20:56刘卓徐斌
网络安全技术与应用 2010年7期
刘卓 徐斌
苏州科技学院电子与信息工程学院 江苏 215011
0 引言
自20世纪80年代以来,随着Internet技术的高速发展,信息化的浪潮席卷全球,社会的每个角落都有了数字化信息的身影。其中尤其以Web页数量最为庞大,并且大约以每4至 6 个月翻一倍的速度增加。巨量的 Web页在为我们提供了海量的信息同时,又给我们提出了新的挑战,即如何从这些浩瀚的Web页信息中快捷准确地得到我们想要的信息。自然我们不能够采用人工的方式完成这项任务,借助于计算机采用数据挖掘的方法是目前广泛使用的技术。
1 Web文本挖掘概述
数据挖掘(data mining)习惯上又称为数据库中知识发现(Knowledge Discovery in Database, KDD),简单的说就是利用计算机,从浩瀚如海的信息资源中找出真正具有价值的信息。数据挖掘可以按以下不同角度分类:从挖掘的数据源分类,一般可以分为关系数据库、事务数据库、空间数据库、时间数据库、面向对象数据库、文本数据库、多媒体数据库、主动数据库、Internet信息库挖掘等。从挖掘出的知识分类,一般情况下,数据挖掘可以分为关联规则、特征规则、分类规则、聚类规则、序列模式、数据综合和概括、总结规则 、趋势分析、偏差分析、模式分析、孤立点分析挖掘等。按照挖掘所采用的技术分类,数据挖掘一般可以分为统计分析方法,遗传算法、粗糙集方法、决策树、人工神经网络、模糊逻辑、规则归纳、聚类分析、模式识别、最邻接技术、可视化技术挖掘等。Web挖掘就是数据挖掘方法中的一种,它是指从大量Web文档的集合C中发现隐含的模式p。如果将C 看作输入,将p看作输出,那么Web挖掘的过程就是从输入到输出的一个映射N: C→p。按照挖掘对象的不同,Web挖掘又可以分为两类:内容挖掘和结构挖掘。内容挖掘指的是从Web文档的内容信息中抽取知识,结构挖掘指的是从 Web文档的结构信息中推导知识。Web内容挖掘又分为对文本文档(包括 text,HTML 等格式)和多媒体文档(包括image,audio,video 等媒体类型)的挖掘。Web 文本挖掘可以对Web上大量文档集合的内容进行总结、分类、聚类、关联分析,以及利用 Web 文档进行趋势预测等。本文所探讨的对象为针对于Web文本文档的挖掘。
2 Web文本挖掘中的聚类算法
聚类是根据个体所满足的属性对个体域进行剖分,把属性相同或相近的个体划归为同一个“概念类”的过程,它是机器学习领域中的一个重要研究方向。文档聚类的目标即使将文档聚集成类,使得类与类之间的相似度尽量的小,而类内的相似度尽量的大。处理聚类问题,主要有以下几种方法:统计方法、机器学习方法、神经网络方法和面向数据库的方法等。
聚类算法一般分为分割聚类法和分层聚类法。分割聚类算法通过一个评价函数把数据集分割为K个部分,需要K作为输入参数。典型的分割聚类算法有 K-means 算法、K-medoids 算法、CLARANS 算法;分层聚类是由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系,不需要K作为输入参数。典型的分层聚类算法是 BIRCH算法、DBSCAN算法和CURE算法。目前,使用聚类方法自动建立文档的类别过程通常如下所示:
(1)输入多篇无类别标识的文本。
(2)借助词典对这些文本进行分词处理。
(3)提取每一个文本的特征向量。
(4)利用文本的特征向量,使用聚类算法进行类别组合计算。
(5)人工为每个得到的文本类别建立类别标识。
3 分层聚类法算法实现
本文采用分层聚类法并结合了改进的特征词权重计算等方法,进行了无类别文档集合的划分处理。具体算法如下:输入:无文本类别标识的文本集输出:标识了类别的训练文本集(1)文本分词处理。
(2)统计词频,完成非完整词串取舍,提取出文本文档中的关键词。
(3)公式(1)计算词的特征值。
(4)按照词的特征值使用插入排序算法递增排序,并从排好序的词集中提取前M个词作为当前文档的特征词,从而得到每一个文档的特征向量di(i=1,2,3,……,n)。
(5)di看作是一个具有单个成员的类Ci={di},从而构成了该文档集合的一个聚类C(n)={c1,c2,……,cn}。
(6)用公式(2)计算C中每对类(ci,cj)之间的相似度。
(7)选取具有最大相似度的类对,并将其合并为一个新的类,从而构成该文档集合的一个新的聚类 C(n-1)={c1,c2,……,cn-1}。
(8)如果n!=1,转到步骤3。
(9)对各个类文档进行人工建立标号。算法说明:
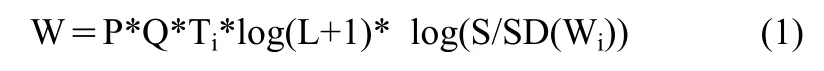
其中:P为位置加权系数,Q为受限语义加权系数,L为Wi的长度,Ti为在文档中出现的频率,S为总文档数,SD为在其中出现至少一次的文档的数目。
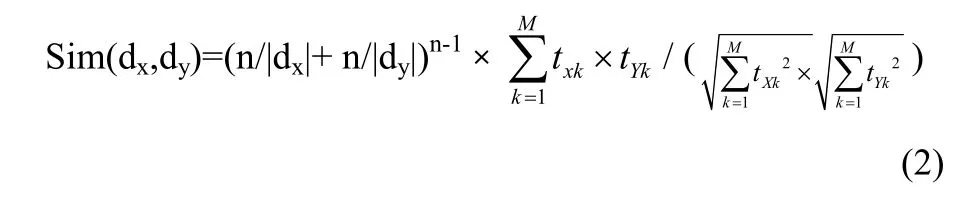
其中:n为文档 dx与 dy共同所有的特征词个数,|dx|文档dx中特征词总数,|dy|文档dy中特征词总数,txk为向量dx第k维值。
4 结束语
本文对文本挖掘中所使用的层次聚类分析方法进行了探讨,通过以上聚类算法的分析处理,我们可以在一定范围内完成对各类训练文本库的建立。但是针对于公式中参数的选取还需要进一步的研究,以便在更大范围内完成训练语料库的建立。
[1] 邹腊梅,肖基毅,龚向坚.Web 文本挖掘技术研究.情报杂志.2007.
[2] 王继成,潘金贵,张福炎.Web 文本挖掘技术研究.计算机研究与发展.1999.
[3] J.Han,Micheline,Kamber,Data,Mining:Concepts and Tchniques.San Mateo,CA:Morgan Kaufmann.2000.
[4] 张红云,石阳,马垣.数据挖掘中聚类算法比较研究.鞍山钢铁学院学报.2001.
[5] 于琨,糜仲春,蔡庆生.可应用与互联网的自学习中文关键词抽取算法.中国科学技术大学报.2002.
[6] 顾立帆,王永成.联想树分析方法及其在无词库中文自动标引中的应用.情报学报.1992.
[7] 何新贵,彭甫阳.中文文本的关键词自动抽取和模糊分类.中文信息学报.1998.
[8] 罗三定,陆文彦,王浩,贾维嘉.基于概念的文本类别特征提起与文本模糊匹配.计算机工程与应用.2002.
[9] 孙丽华,张积东,李静梅.一种改进的 KNN 方法及其在文本分类中的应用.应用技术. 2002.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
信息安全研究(2016年4期)2016-12-01 06:06:54
新校长(2016年8期)2016-01-10 06:43:59
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中文信息学报(2015年4期)2015-04-21 08:29:12
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
