
一种新的语音通信抗分组丢失方法—分布式子帧交织描述
2010-08-06 09:28:44马丽红吴锦泉叶蔼笙
通信技术 2010年6期
马丽红, 吴锦泉,②, 叶蔼笙
(①广东省教育厅无线通信网络和终端重点实验室,华南理工大学电信学院,广东 广州 510641;②中国移动通信有限公司 佛山分公司,广东 佛山 528000;③广东省电信无线网络运营中心 广州中心,广东 广州 510000)
0 引言
在突发错误信道中,多描述编码(MDC)[1]是处理 VoIP(Voice over IP)丢包及帧擦除问题的有效方法[2]。相比于重传技术,MDC能够提高传输的可靠性而不引入大的延迟。MDC信号分裂成两个以上的描述,各自独立传输。每一描述均能部分地恢复原始信号;如果能够得到两个或更多个描述,联合解码可得质量更高的重建信号。不过,大部分 MDC方案的主要问题是带宽利用率低,MDC描述数越多,系统重建的语音质量越好,但所需码率也越高。
MD编码已用于图像和视频信号[3],但MD语音编码发展缓慢,主要原因是实时通信和语音的时变特性的约束。令人满意的通信,端对端延迟应该小于200 ms,但是语音的非平稳随机特性,使其冗余远少于图像和视频。也就是说,MDC方案能利用的冗余信息有限。另一方面,很多语音编码标准是基于CELP(Code-Excited Linear-Prediction)技术的,当提供可接受的语音质量时,在 1/2 CELP的码率下,难以得到平衡的边描述。基于 CELP多描述编解码器大致可划分为三类:
①冗余参数分集描述[4-5]。该类方法把包含重要特性的数据或提取参数同时嵌入多个编码描述中,作为信息增强的子集。这种差异并存的多路方法简单有效,但计算复杂度和比特率会剧烈增加;
②比特率零冗余MD编解码[6]。利用相邻帧线谱对(LSP)的相关性,为一个更大的子帧生成激励,并在多个描述中复制相同的关键码字。不过零冗余 MD编解码器比特流虽然不增加任何带宽,但即使用所有描述来解码,其合成质量也较差,因为子帧尺寸增大,实际上得到的是参数的平均估计,不能反映语音的时变和短时相关特性;
③编码数据流分裂方法[7-8]。数据流以一定准则分裂成多个冗余子流,生成不同描述。码流分裂 MD方法优点明显,它在使用不同路径、增加较少比特率的代价下,提供了更好的语音质量;但是当数据作分组传输时,其效率可能会变得很差, 因为每一描述的各个分组在数据封装时均需要增加一个格式说明,增加的包头信息在数据分裂型MDC中成为可观的负载。
为了解决MDC高带宽和部分附加延时问题,本文提出一个新的交织方法,用于码流分裂型 MDC。与一般的位流分裂不同,本文从两个相邻帧的分布式子帧交织生成两个描述。实验结果证明,从编码效率和可允许延时来比较,该方法优于传统的分裂型MD和SD编码器,即使加上包头,增加的带宽和延迟也很少。
1 多描述编码的交织方案
当多个语音帧封装传输时,交织是一项可行的技术[9]。图1所示为4帧/分组的交织方案。交织流丢失的分组,在重构码流里被分散成多个小的缺失数据段,通过差错隐藏技术或人耳听觉系统的低通滤波特性,更容易修复小段失真信号。因而,交织改善了不可靠传输的语音质量,而没有增加带宽,但是当分组的语音帧个数增加时,会引入较大的延迟。
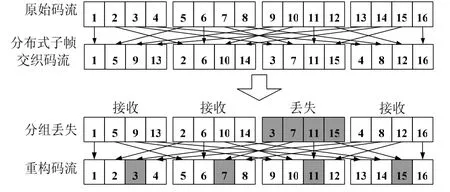
图1 4帧/分组的帧交织原理
为了在带宽利用率和编码时延之间实现折衷,本文提出了 MDC分布式子帧交织方法(DSI)。与传统的帧交织不同,我们提出的方案交织的子帧分别在两个相邻帧,而只引入一帧延迟。尽管分组只包含一个帧语音,我们的方案仍然可行。图2是两子帧DSI的原理图,分组包含一帧语音,语音帧分成奇子帧和偶子帧。每一帧数据由三个元素{Fi, Sfi,1, Sfi,2}组成:Fi是第i帧的帧级数据更新,Sfi,1(Sfi,2)是第i帧的奇(偶)子帧的更新数据。Fi会被交织到不同的分组,与传统的帧交织不同,对于任何整数 i,所有 Sfi,1被分配到一个奇分组,所有Sfi,2被分配到一个偶分组。因此,子帧交织之后,依照分组序号的奇偶校验检查,将两个分组分配到不同的描述。相比原始SD流,DSI方法中分组大小和总数不变,而只引入了一分组(两帧)的额外延迟,与原始 SD流保持相同的码率。
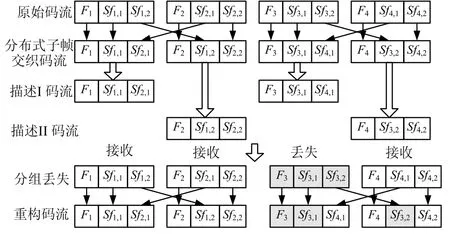
图2 两子帧DSI原理
图 2也展示了分组丢失时,DSI的差错隐藏程序。假定描述I的第2个分组发生丢失,即相应DSI流的第3个分组,在重建流中解交织能够将丢失的数据{F3,Sf3,1,Sf4,1}分散到第3和第4个分组。由于DSI流里的第3和第4个分组是同时传送的,同一时间丢包的概率很低,能够利用第 4个分组及之前接收的分组来隐藏丢失的分组,而在接收端不会引入额外的延迟。另一方面,当可得到未来语音帧时,内插比外推法产生更好的质量。因此,在本文的方案,采用参数内插重构丢失的信息。通过式(1)实现隐藏操作,其中I( )表示内插:

2 分布式子帧交织的多描述语音编码器
前面提出的DSI语音多描述方案应用于G.729,并命名为MD-G.729,编码方案如下:
(1)ITU-T G.729的参数
ITU-T G.729是一个使用共轭结构代数码激励、线性预测编码(CS-ACELP)技术的语音编码器。码率为8 kb/s,编码语音帧长10 ms,预留准备有5 ms,总运算延迟为15 ms,每一个语音帧由两个子帧组成。G.729的比特分配如下页表1的SD-G.729列所示。第i帧的80比特数据是通过多元矢量表示成如下参数:

LSP1i表示LSP的第一级矢量量化(VQ);LSP2i表示 LSP的第二级矢量量化;Pi,1表示第一子帧的自适应码书(ACB)基音延迟;Pi,2表示第二子帧的自适应码书基音延迟;FCBi,1表示第一子帧的固定码书(FCB)位置和符号,FCBi,2表示第二子帧的固定码书(FCB)位置和符号;Gi,1表示第一子帧的ACB和FCB增益;Gi,2表示第二子帧的ACB和FCB增益。
(2)MD-G.729编码器
一般的编码器结构如图3(a)所示。如上所述,MD-G.729通过在G.729中的两个相邻帧应用DSI,生成两个速率相同的平衡描述。
与第II部分介绍的DSI不同的是:当只收到一个描述时,为了改善语音质量,每一个描述都引入了LSP的重要信息作为冗余。依照G.729的语音帧的编号,将语音帧分成奇帧和偶帧。我们将描述I表示为D1,描述II表示为D2。
MD-G.729的比特分配如表1的MD-G.729列所示。
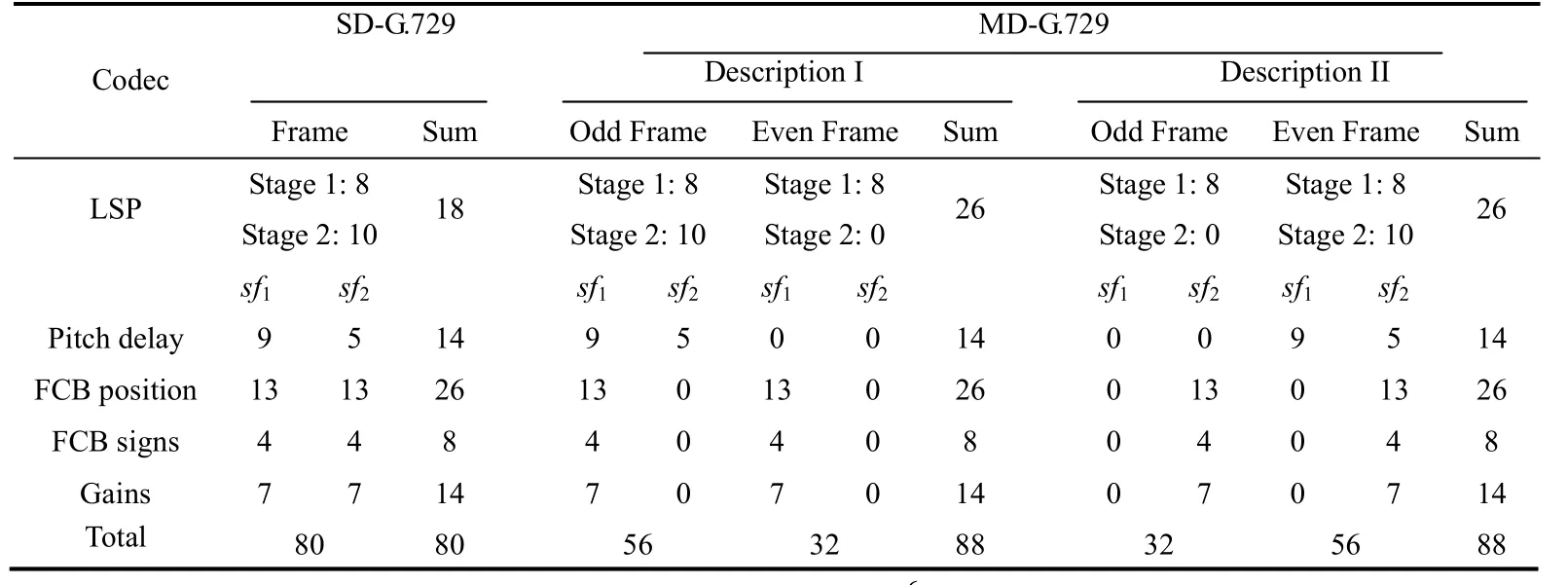
表1 标准SD-G.729 和提出的MD-G.729的比特分配
如上所述,子帧级更新的所有参数(除了基音延迟)被交织到两个不同的描述,即D1包含FCBi,1和Gi,1,而D2包含FCBi,2和Gi,2。两子帧的基音延迟总包含在同一描述,这是因为第二子帧的基音延迟使用了差分编码,Pi,1丢失了,Pi,2也没用。所以对于奇(偶)帧,Pi,1和 Pi,2都被分配到D1(D2)。对于奇(偶)帧LSP1i和LSP2i被分配到D1(D2),而对于偶(奇)帧LSP1i注入到D1(D2)作为冗余。然后两个描述打包成两个分组。如表I所示,D1(D2)的奇(偶)帧比特流有 56比特数据,而 D2(D1)的奇(偶)帧比特流有 32比特数据。D1(D2)总共88比特数据如下所示:
每一描述的平均码率是 4.4 kb/s,MD-G.729总码率为8.8 kb/s,因DSI而引入额外延迟10 ms。
(3)MD-G.729解码器
图3(b)为MD-G.729解码器。若收到两个描述,中心解码器工作(与G.729相同);当两个描述都丢失,用G.729标准差错隐藏算法隐藏丢失信号;若只收到一个描述,则边解码器依照如下规则工作:
①若仅收到D1(D2),则解码器重构奇(偶)帧的LSP矢量,而只使用第一级 VQ的接收到的比特部分重构偶(奇)帧的LSP矢量。丢失的第二级偶(奇)帧的LSP矢量置零;
②通过前一帧的第二子帧基音延迟tn-1,2和下一帧的第一子帧基音延迟tn+1,1的线性内插估计基音延迟tn,1和tn,2。如下式所示:

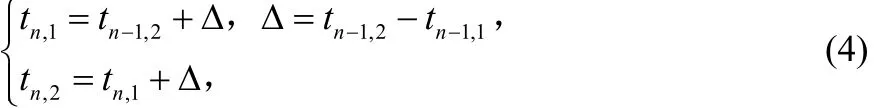
通过使用前一帧的基音延迟 tn-1,1和 tn-1,2的推测,可以估计D2的基音延迟:上述奇偶帧间的基音延迟的隐藏是不同的,当仅丢失D1时,下一帧(偶帧)的基音延迟由 D2内插得到;相反,当仅丢失D2时,仅有包含在D1的前一帧(奇帧)的基音延迟可推断;
③通过前一帧和下一帧的增益在对数域的线性内插来估计丢失子帧的ACB增益;
④缺失的FCB增益不能内插恢复,因为FCB增益是用滑动平均预测器量化的,因此我们用随机选择机制来的隐藏丢失的FCB矢量。
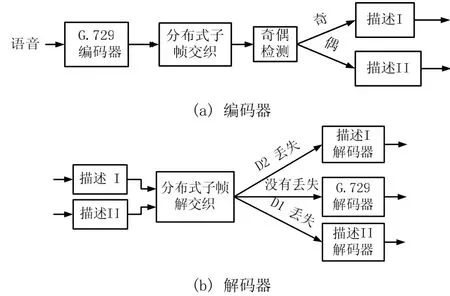
图3 提出的MD-G.729编解码器
3 实验结果
使用PESQ(Perceptual Evaluation of Speech Quality)对基于G.729的SD和MD方法与提出的MD方案的性能进行比较分析,参与比较的编码器包括:
①单信道下标准G.729编码器(SD);
②单信道冗余数据传输(RDT-SD)[10]。之前传输的G.729帧的副本也包含在目前的G.729帧的分组里,码率为16 kb/s,相比G.729引入了10 ms的额外延迟;
③多路径并发G.729编码器(DSD-PD),每一帧的两个副本通过两个独立的信道同时发送,不引入额外延迟;
④多路径下G.729 MD编码器(MD-PD)[8],每一帧的比特分配方案与MD-G.729类似,但仅通过分裂G.729比特流而不使用DSI来生成两个平衡的描述;
⑤本文的MD-G.729编码器,编码比特流通过不同路径传送(MD-DSI-PD)。
实验假定在发送和接收端间总是存在两条相似路径;测试数据为9男和9女样本,每段语音持续时间约为10 s;在两种丢包环境下验证:
①随机丢包,通过贝努利模型模拟;
②突发丢包,使用平均突发错误长度为3的吉尔伯特模型模拟,每种环境下分别生成10个不同的声轨文件来模拟分组网络。上述方法中,由于在两个相邻帧进行子帧交织,所以本文的方法需要20 ms的分组,而其它的方法都是使用10 ms分组。
(1)带宽和延迟的比较
表2展示了五种方法中不考虑包头,额外延迟,每帧需要的平均分组数目,以及是否路径分集情况下,有效负载的比特率的比较。从表2,可以知道不考虑包头,两个MD编码器的码率都比SD稍高,而RDT-SD和DSD-PD是SD带宽的两倍。另一方面,由于加上包头及使用路径分集,DSD-PD和MD-PD的带宽急剧增加,而MD-DSI-PD的带宽只有稍微增加,因为它的包数与SD的一样。相比其它三种方法,MD-DSI-PD 和RDT-SD都引入了10 ms额外延迟。但对于MD-DSI-PD,相比剧烈地增加带宽,这是一个更好的折衷。
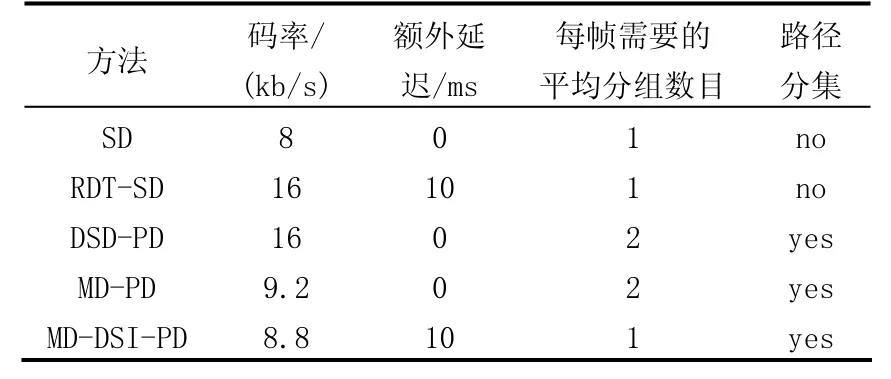
表2 5种方法的比较
(2)分组网络仿真
网络仿真结果见图4,图5。图4为随机丢包信道,图5为突发丢包信道。对于两个信道的所有错误率的情况,DSD-PD的性能是最好的,然而,无论加不加包头,这个性能的获得都是以双倍SD-G.729的带宽为代价。在随机丢包情况,RDT-SD的性能与DSD-PD类似,而在突发丢包情况,RDT-SD的性能比DSD-PD差,这是因为RDT-SD仅仅抵抗单一的丢包。如果发生连续丢包,相同帧的数据和冗余副本会丢失,因而,当遇到突发错误时RDT-SD变得低效。另一方面,不同路径的两个MD方法能有效地应付突发错误,尤其在突发丢包的情况,对于所有丢包率,MD-PD和MD-DSI-PD的性能优于SD。MD方法较好的差错隐藏性能归因于两个描述间的相关性以及不同路径的信道独立性。在突发丢包情况下,SD的性能比在随机丢包情况下要差得多,这是由于SD编码器的差错隐藏算法主要处理短时丢包。
对于裸数据的传送,两个MD方法都是高效的。但是,当加上包头时,MD-PD的包头是SD和MD-DSI-PD的两倍,导致带宽大大增加。相反,MD-DSI-PD在带宽几乎与SD一样的情况下,仍然能提供较好的语音质量。此外,对于所有丢包情况和丢包率,MD-DSI-PD的语音质量总是优于MD-PD,当仅接收到一个描述时,对于基音延迟和ACB增益,通过更好的差错隐藏技术实现MD-DSI-PD的超级性能;相比MD-PD使用的恢复技术,奇帧内插而偶帧外推能更精确和平滑地估计丢失的基音延迟信息;采用内插去隐藏丢失的ACB增益比MD-PD使用的削弱替换更加有效,尤其是对于奇帧的第二子帧以及偶帧的第一子帧,其中的基音延迟信息在接收的描述中可以得到。从根本上讲,MD-DSI-PD较好的差错复原性能正是源于DSI数据的合理组织。
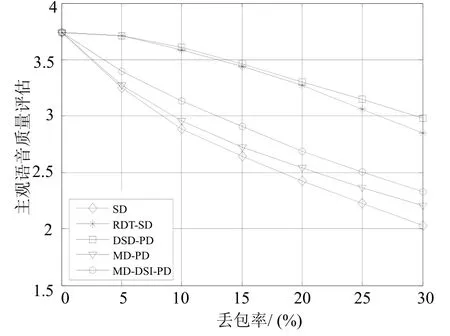
图4 不同随机丢包率下的PESQ
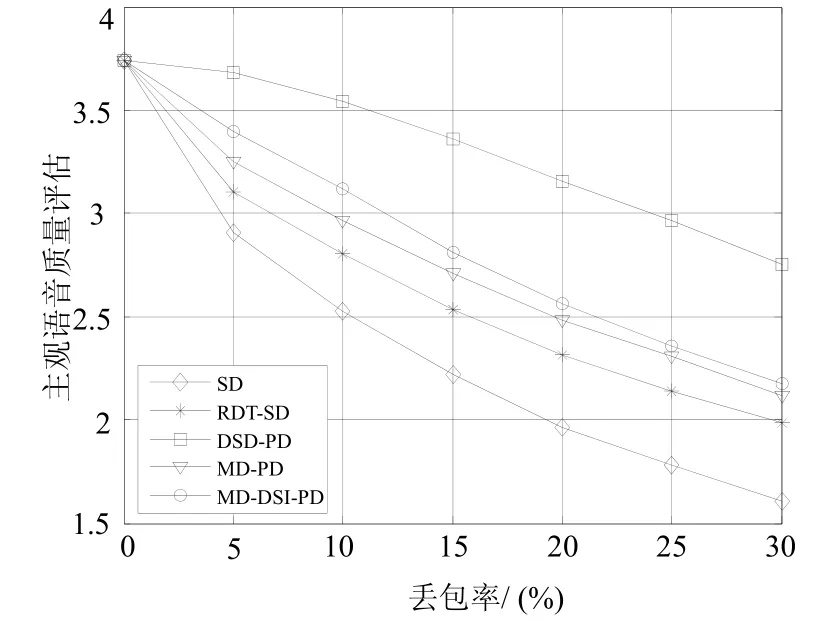
图5 不同突发丢包率下的PESQ
4 结语
本文提出了一个新颖的MDC交织方案——分布式子帧交织,在两种不同的丢包情况下的测试说明:综合考虑带宽和语音质量,提出的MD编码器优于其它的编码器(如SD,RDT-SD,DSD-PD和MD-PD)。
在分组网络,相比传统的SD编码器,本文的MD编码器提供更好的语音质量,而只增加很少带宽和10 ms额外延迟,尤其在频繁发生丢包时这是一个好的折衷。通过使用DSI,提出的MD编码器能够克服其它MD方法效率低的缺点。
[1] Goyal V K.Multiple Description Coding: Compression Meets the Network[J].IEEE Signal Process,2001(18):74-93.
[2] 江虹,林明. 改进NSGA-Ⅱ在无线MD视频中的应用[J].通信技术,2009,42(06):154-158.
[3] 刘艳,付慧生,李雪峰.现代通信技术与 VoIP[J].通信技术,2007,40(04):49-50.
[4] Lee C C.Diversity Control Among Multiple Coders: A Simple Approach to Multiple Descriptions[C]//In Proc. 2000 IEEE Workshop on Speech Coding.Delavan:WI,2000:69-71.
[5] Zhong X, Juang B H.Multiple Description Speech Coding withDiversities[C]//In Proc. 2002 IEEE International Conferenceon Acoustics,Speech,And Signal Processing.Dallas,Texas,USA:IEEE,2002:177-180.
[6] Wah B W, Dong L.LSP-based Multiple-description Coding for Real-time Low Bit-rate Voice Transmissions[C]//In Proc.2002IEEE International Conference on Multimedia and Expo..Lau-sanne,Switzerland:IEEE,2002:597-600.
[7] Dong H, Gersho A, Cuperman V, et al.A Multiple Description Speech Coder Based on AMR-WB for Mobile ad hoc Networks[C]//In Proc. 2004 IEEE International Conference on Acoustics, Speech and Signal Processing.Montreal,Canada:IEEE,2004:277-280.
[8] Balam J,Gibson J D.Multiple Description Coding and Path Diversity for Voice Communication over MANETs[C]//In Proc.Conference Record Thirty-Ninth Asilomar Conference on Signals, Systems & Computers 2005.Pacific Grove:CA,2005:310-314.
[9] Perkins C, Hodson O, Hardman V. A Survey of Packet Loss Recovery Techniques for Streaming Audio[J].IEEE Network,1998,12(05):40-48.
[10] Kostas J.Real-Time Voice over Packet Switched Networks[J].IEEE Network,1998,12(01):18-27.
猜你喜欢
成都信息工程大学学报(2019年1期)2019-05-20 09:14:16
计算机应用(2018年7期)2018-08-27 10:42:40
电信科学(2016年7期)2016-11-30 08:21:59
科技创新导报(2016年3期)2016-05-30 23:19:30
江西理工大学学报(2015年3期)2015-12-22 05:26:24
计算机工程(2015年8期)2015-07-03 12:19:56
小演奏家(2014年11期)2014-12-17 01:18:52
宇航学报(2014年2期)2014-12-15 02:49:06
电子技术应用(2014年12期)2014-12-10 05:37:50
数据采集与处理(2014年2期)2014-07-25 04:28:08
