
基于OPC UA的历史数据存取
2010-07-25 08:43陈骞剑强汪镭胡飞凰吴启迪
微型电脑应用 2010年2期
陈骞,剑强,汪镭,胡飞凰,吴启迪
0 引言
OPC(OLE for Process Control)技术在当今过程控制领域,是一种非常流行的数据交换技术。但是随着技术的发展和设备的革新,企业在应用OPC技术的过程中又遭受到重重难关,OPC技术自身的缺陷成了企业进一步发展壮大的瓶颈。首先是它的COM基础,使开发过程受到限制;其次是OPC规范的局限性,没有提供必要的网络安全性、协同互操作性及可靠性;再次是现行OPC平台不独立,它受限于Microsoft 公司的操作系统,对Linux、OS等系统缺乏支持。基于这种情况,OPC基金会推出了新一代OPC UA(OPC Unified Architecture)规范。
1 OPC UA简介
OPC UA 是一个新的工业软件应用接口规范,其目的在于提出一个企业制造模型的统一对象和架构定义,具有跨平台、增强命名空间、支持复杂数据内置、大量通用服务等新特点。
OPC UA规范由十三部分构成,其中主要的核心规范为Data Access,Alarm & Conditions,Historical Access三部分。每种规范对应着一种类型的服务器和客户程序的开发,它们的区别是实现功能的侧重点不同。
其中,历史存取(Historical Access)服务器包括历史数据存取和历史事件存取两部分,历史数据存取是指将不同应用层次的实时数据用统一的标准集成起来,保存在数据存储器中,然后根据客户程序需求访问指定的历史数据;历史事件存取是指将警报和条件规范中得到的事件保存起来,以供客户程序访问。
2 OPC UA历史数据存取
OPC UA规范作为新一代的OPC技术,势必将广泛应用在实际工业生产流程中。如今的工业信息量在膨胀式增长,在整个流程工业中所集成的数据采集点数通常有几千到十几万,数据采集间隔要达到毫秒级,数据量很大,为了使工业生产系统快速、有效地管理数据,提高磁盘存储效率以及查询性能,必须要有一套高效的数据存储机制来保存历史数据。
历史数据的存取需要数据存储器来管理数据,数据存储器可以使用文件系统,也可以使用关系数据库,比如SQL Server。 OPC UA规范描述了历史访问服务器要实现的功能,不涉及服务器的内部实现。历史数据是基于时间的一些连续模拟量或数字量(比如温度、压力、流量、阀门开关等) ,完全不同于普通关系数据库处理的那些离散的、非连续的、不基于时间的二维关系表数据(比如订单信息、财务信息、人事管理信息等)。
因此,本文采用文件系统作为数据存储器,在符合规范定义的条件下,通过存储过程、存储方式和查询过程三部分给出一种历史数据的存取机制,并设计了一种文件结构,以便客户程序准确高效地处理历史数据。
3 数据存储过程
数据存储过程分为四个部分完成,首先是将从现场设备采集的历史数据进行过滤操作,接着是历史数据的压缩处理,然后是内存数据操作,包括队列和缓冲区的设计,最后是将缓冲区的内存数据归档到磁盘文件,如图 1所示给出数据存储过程的流程图:
1) 来自不同设备的数据首先要进行过滤,使满足要求的数据被传送;过滤操作设置三个参数:过滤最小偏差、过滤最大偏差、最小时间偏差:
过滤最小偏差:当前数据和上一个数据之间的绝对差值的最小规定,此参数限定可以过滤一些变化率较小的数据。
过滤最大偏差:当前数据和上一个数据之间的绝对差值的最大规定,此参数限定可以过滤一些异常的数据。
最小时间偏差:当前数据和上一个数据过滤的时间偏差的最小规定,此参数限定可以避免部分现场噪音的干扰。
2) 当新数据与前一数据的绝对差值在设定的过滤最小偏差和过滤最大偏差之间并且两个数据的时间差大于或等于给定的最小时间偏差,新数据将通过过滤而送往历史数据源队列过滤完的数据送到历史数据源队列中成为需要归档的历史数据源, 为了确保高效的数据存储,需要对历史数据进一步压缩处理;
3)通过压缩的数据被送到位于内存中的归档数据队列中,归档数据队列对送往归档文件的数据进行缓冲:归档过程使用定时器定时将数据传送;如果归档数据队列已满并且归档过程不可用时,归档数据队列将会把数据写入临时磁盘文件,等归档可用时再转存入归档文件中;
为了降低与磁盘的操作频率,从归档数据队列出来的数据将被送往归档缓冲区。系统为每个属性ID设定一个缓冲区,当归档缓冲区中数据达到一定值,则将这些数据以数据块形式一起写入磁盘归档文件存储。

图1 实时数据的存储过程
4 数据存储方式
由于历史数据的采集、处理、存储和查询都有较高的时间要求,数据的存储方式按照OPC UA标准采用网络数据模型,将数据的索引和结构分为设备、数据ID和数据其他信息三级,其中设备和数据ID作为索引结构存储,数据其他信息以数据块的形式存储。
存储设备数据的每一条历史数据记录需要包含四个字段:ID,Status Code,Value,Time。ID表示每个标签点(测量点)的标识符,在同一系统中每个标签点的ID是唯一的;Status Code表示实时历史数据的质量码,OPC UA规范书定义质量码为32位的无符整型;Value表示实时历史数据的数值,根据设备数据的数据类型用不同的结构来存储;Time表示实时历史数据的时间戳,在存储过程中,Time采用差分法表示,索引字段中存储时间基准值,数据字段中存储时间偏移量(以毫秒为单位的整型变量)。
5 文件结构
本文设计的文件结构有如下特点:
历史数据按时间段分为多个文件保存,每个文件保存一段时间内的历史数据,文件大小可根据需要设置,文件路径根据时间范围保存在索引文件中
索引结构采用分级索引,包括外部索引和内部索引两部分,其中内部索引和同一段时间内的数据保存在相同文件中,外部索引保存在索引文件中
实时历史数据的ID与其它数据在文件内分开保存,便于在查询过程中快速定位所需标签点数据的位置
存储系统包括两种类型的文件:“索引文件”和“数据文件”。索引文件记录所有数据文件的基本信息,在系统中是唯一的;
数据文件记录实际的历史数据。
5.1 索引文件
索引文件由外部索引项构成,每一项对应一个数据文件。索引项中的内容包括与其相对应的数据文件的开始时间、结束时间和文件路径。
在查询过程中,使用索引文件可以快速定位查询条件中时间范围内数据所在文件的路径,结构如下图所示:

图2 文件结构图
5.2 数据文件
数据文件由文件头、设备组索引区、标签点索引区、时间索引区和数据区五部分构成
5.2.1 文件头
文件头包含此文件的基本信息,其大小固定以便于数据读写操作,如下图结构所示:

图3 文件头结构
设备组索引区的每一项包括设备名称号和对应设备的标签点索引区的初始位置,大小由文件头的最大设备组数决定;标签点索引区的所有项按设备种类分块顺序存储,每一项都包括历史数据的ID和对应的时间索引区初始位置及当前使用位置,为了提高查询效率,同一个设备的ID按升序排列。结构图如下所示:
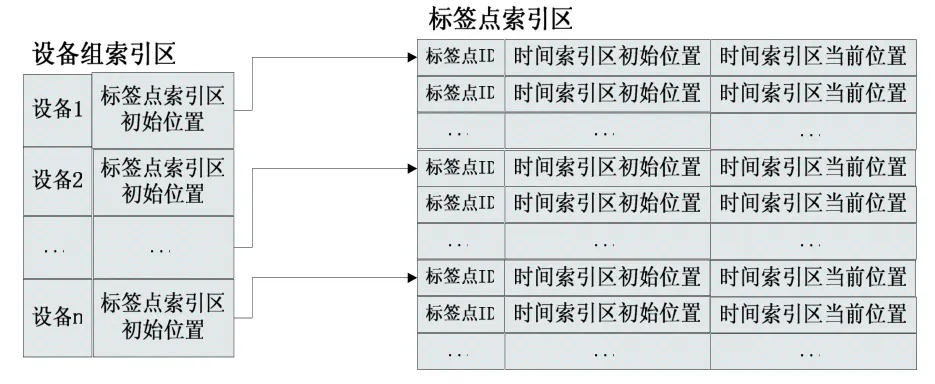
图4 设备组、标签点索引区结构图
5.2.3 时间索引区&数据区
时间索引区的每一项包括对应数据块的开始时间和结束时间,数据块在文件中的位置,以及同一个标签点使用的下一个时间索引项的位置。这样,每个标签点使用的时间索引形成一个链表。
数据区是由数据块构成的,每个数据块存储标签点的时间偏移量(相对于时间索引区的开始时间)、质量码和数据值;数据块的大小由归档缓冲区的大小决定,并且以数据块为基本单位进行数据读取,结构如图5所示:

图5 时间索引区&数据区结构图
6 数据查询过程
数据查询有很多种类型,一般查询部分标签点的一段时间的历史数据,查询条件为标签点的ID和时间范围。根据前面数据存储过程和文件结构的描述,数据查询过程可以分为以下几步:
第一步:根据查询条件的时间范围,在索引文件中得到数据所在的文件路径;
第二步:读取上一步得到的文件,根据查询条件的标签点 ID,利用内部索引结构的设备组索引和标签点索引,得到指定标签点数据的时间索引位置;
第三步:读取上一步得到的时间索引区,根据查询条件的时间范围得到查询所需的数据块位置;
第四步:读取上一步得到的数据块,将所需数据信息写入查询结果数组。
7 性能测试
根据前面的存储机制和文件结构描述,测试在P43.0G,512M 内存的电脑上实验,采用 VS2005为程序平台,用VC++的控制台应用程序实现数据存取功能的模拟,并且通过线程和定时器实现存储过程,文件的存储和查询用二进制数据流形式。为了便于控制和测试,数据源用定时采集到的周期为30s的模拟数据表示,结构符合第四部分的存储方式要求。下面分别用表格的形式给出存取指定数据个数所花费的时间及单位时间的存取效率。
7.1 存储性能测试

表1 数据存储的性能测试表
7.2 查询性能测试

表2 数据查询的性能测试表
7.3 性能分析
从表1和表2的存取数据性能测试结果分析,历史数据的存储和查询完全能够满足海量数据的实时性要求,并且能够准确地存储到本文设计的文件结构,以及高效地查询所需的历史数据,实现OPC UA历史存取服务的功能。
8 总结
OPC UA技术是未来工业控制接口的发展方向,由于其对应用广泛的OPC进行补充和改进,各生产厂商可以实现企业上层网络与现场设备层的无缝集成。但是基于OPC UA的各类数据采集设备会产生数量庞大的实时数据,对历史数据存取的性能和效率提出了巨大的挑战。
本文的创新点:设计了一种新的文件结构,并且给出了一套历史数据存取机制,该机制从存储查询过程、存储方式和文件结构等方面综合考虑数据读写性能,通过多级缓存和多级索引的优化方案,为OPC UA的历史数据存取服务器提出了一种高效的文件系统存储设计方案。
[1] OPC Foundation. OPC Unified Architecture Specification[Z] . Historical Access Version 1.01 2008.7.
[2] 訾树波,于德敏,许增朴,王永强.工业生产实时数据采集及管理数据库模型设计[J] 微计算机信息,2005 7- 3:104-106.
[3] 张志凛.实时数据库原理及应用[M] 北京: 中石化出版社,2001.
[4] 刘云生.现代数据库技术[M] .北京:国防工业出版社, 2001.
[5] 王成光.流程工业大型实时数据库理论、技术与应用 [D] .杭州:浙江大学,2003.
猜你喜欢
智能制造(2021年4期)2021-11-04
河北电力技术(2021年2期)2021-07-29
学生天地(2020年6期)2020-08-25
数学年刊A辑(中文版)(2020年2期)2020-07-25
网络安全和信息化(2018年9期)2018-03-03
信息安全研究(2018年1期)2018-02-07
网络安全和信息化(2017年12期)2017-11-08
电脑知识与技术(2017年16期)2017-07-14
新课程·下旬(2016年12期)2017-06-07
系统医学(2016年8期)2016-02-20
