
基于GMM-UBM的语言辨识算法研究
2010-07-16 11:07:02陈业仙张歆奕毛杰
五邑大学学报(自然科学版) 2010年3期
陈业仙,张歆奕,毛杰
基于GMM-UBM的语言辨识算法研究
陈业仙,张歆奕,毛杰
(五邑大学 信息工程学院,广东 江门 529020)
运用Matlab软件,以自已建立的语音数据库为基础,对与文本无关的基于GMM-UBM的语言辨识系统进行了测试,获得的平均识别率达74%,与传统GMM算法的测试对比,基于GMM-UBM的语言辨识算法能更好地改善语言辨识系统的性能.
语言辨识;高斯混合-全局背景模型;期望最大化;贝叶斯自适应算法
随着信息时代的快速发展,全球合作日趋频繁,语言辨识技术越来越受到人们的关注. 语言辨识是计算机分析处理一个语音片断并判别其所属语言种类的过程[1],主要用在信息检索和机器翻译等领域,作为自动翻译、自动转换、多语种通信系统等的前端处理技术[2]. 本文提出了基于GMM-UBM的语言辨识算法,以期改善语言辨识系统的性能,获得更好的识别率和系统移植性.
1 高斯混合模型
1.1 高斯混合模型的基本概念

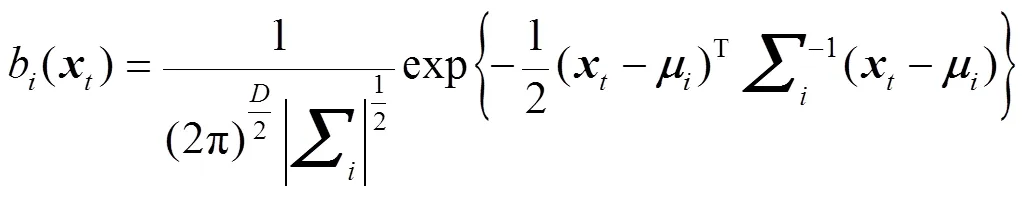
完整的混合高斯模型由参数均值向量、协方差矩阵和混合权重组成,即

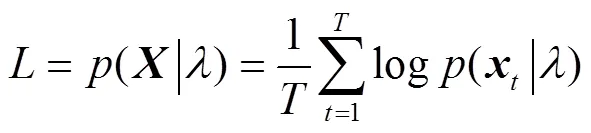
1.2 GMM的参数估计
本文用EM算法进行50次迭代实验得到GMM,实验结果如图1所示. 由图1可知:得到的似然函数是单调递增的,且最后收敛.

图1 EM算法训练GMM得到的似然函数曲线
2 高斯混合-全局背景模型
在语言辨识系统中,高斯混合-全局背景模型(GMM-UBM)是一个与语言无关的背景模型,它利用除目标语言外的所有训练数据获得一个语言UBM,基于GMM-UBM的语言辨识系统框图见图2[3].
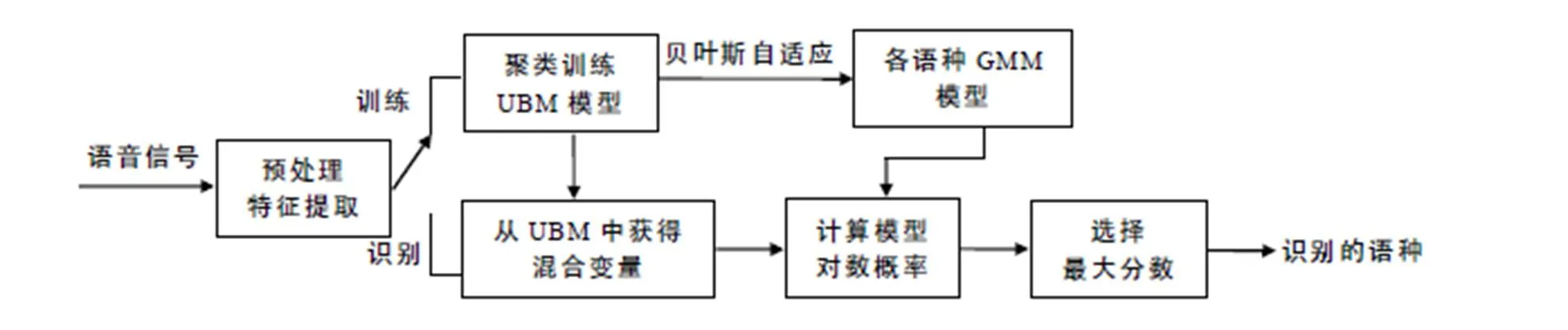
图2 基于GMM-UBM的语言辨识系统框图
2.1 训练
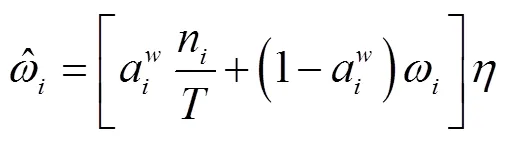
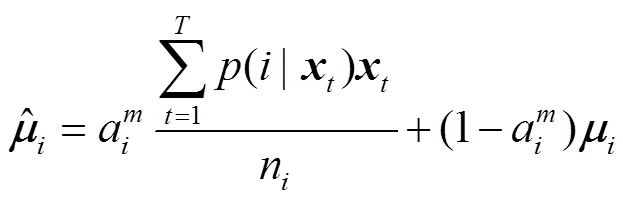
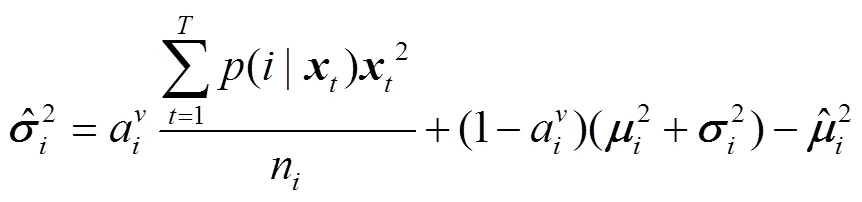
2.2 识别
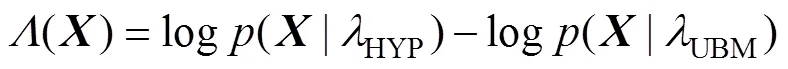
3 实验
以网络下载、光盘、磁带及真实环境下录制的数据自建语音数据库并作为本文采用的实验数据.信号以8 kHz进行采样,16 bit量化. 语音经预加重后通过加窗得到语音帧,加窗选用256点(32 ms)的汉明窗,帧移为l6 ms并去除静音帧和低能量帧,特征参数是提取12阶的LPCC倒谱系数. 训练阶段,用所有语种数据训练得到UBM后,通过贝叶斯自适应算法快速获得每种语言的GMM;识别阶段,计算每段输入语音的对数概率分数,最终判别语言的种类.
3.1 10人双语GMM实验
训练时,选取10位固定说话人,用中文和英文2种语言,建立中文GMM模型. 测试时进行开集、闭集实验,闭集实验数据是来自相同说话人的训练与测试语音数据,开集实验数据是来自不同说话人的训练与测试语音数据,中文为目标语言,英文为闯入者语言,实验内容如下:
3.2 10人双语GMM-UBM实验
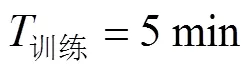
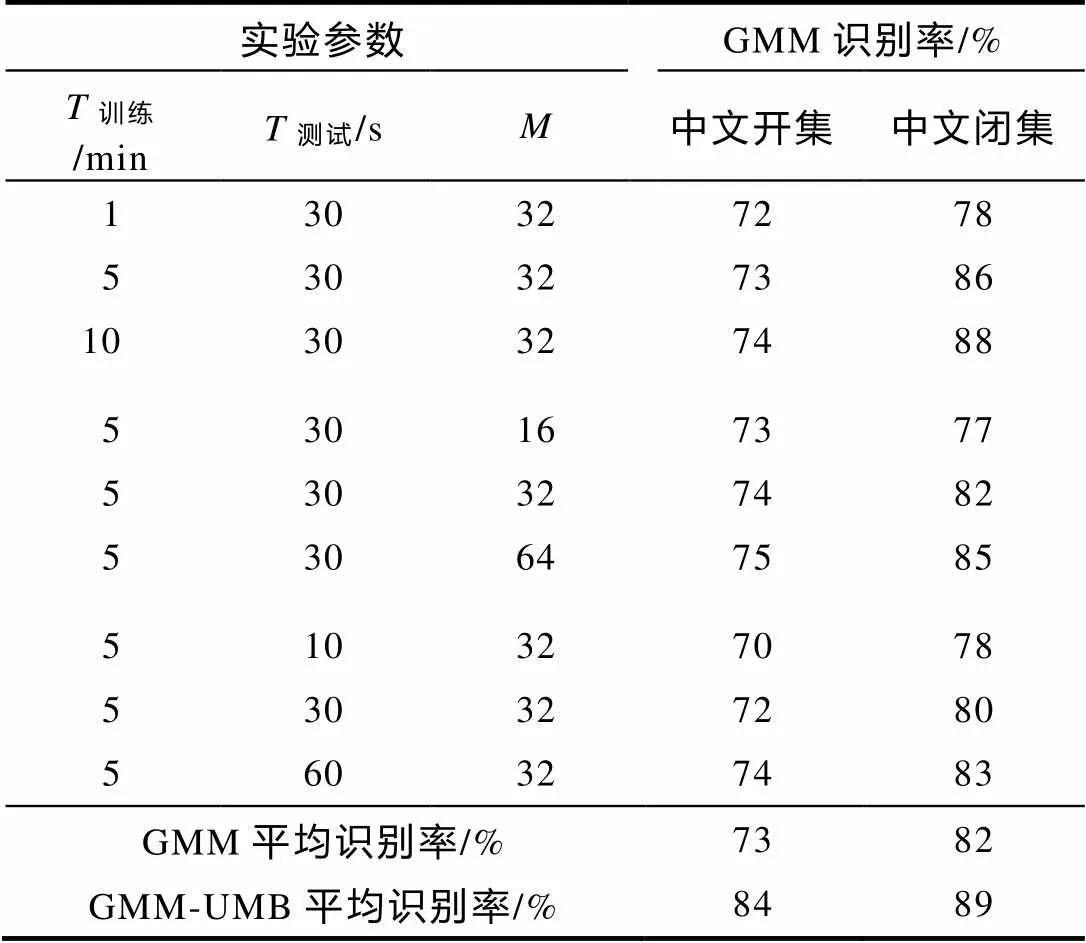
表1 2种模型10人双语开集、闭集实验结果对照
3.3 100人3种语音开集实验
通过上述实验得知:GMM-UBM的性能在语言辨识中比GMM性能更好. 在此基础上,本文进行了更大规模的开集实验,实验结果如图3、图4所示.
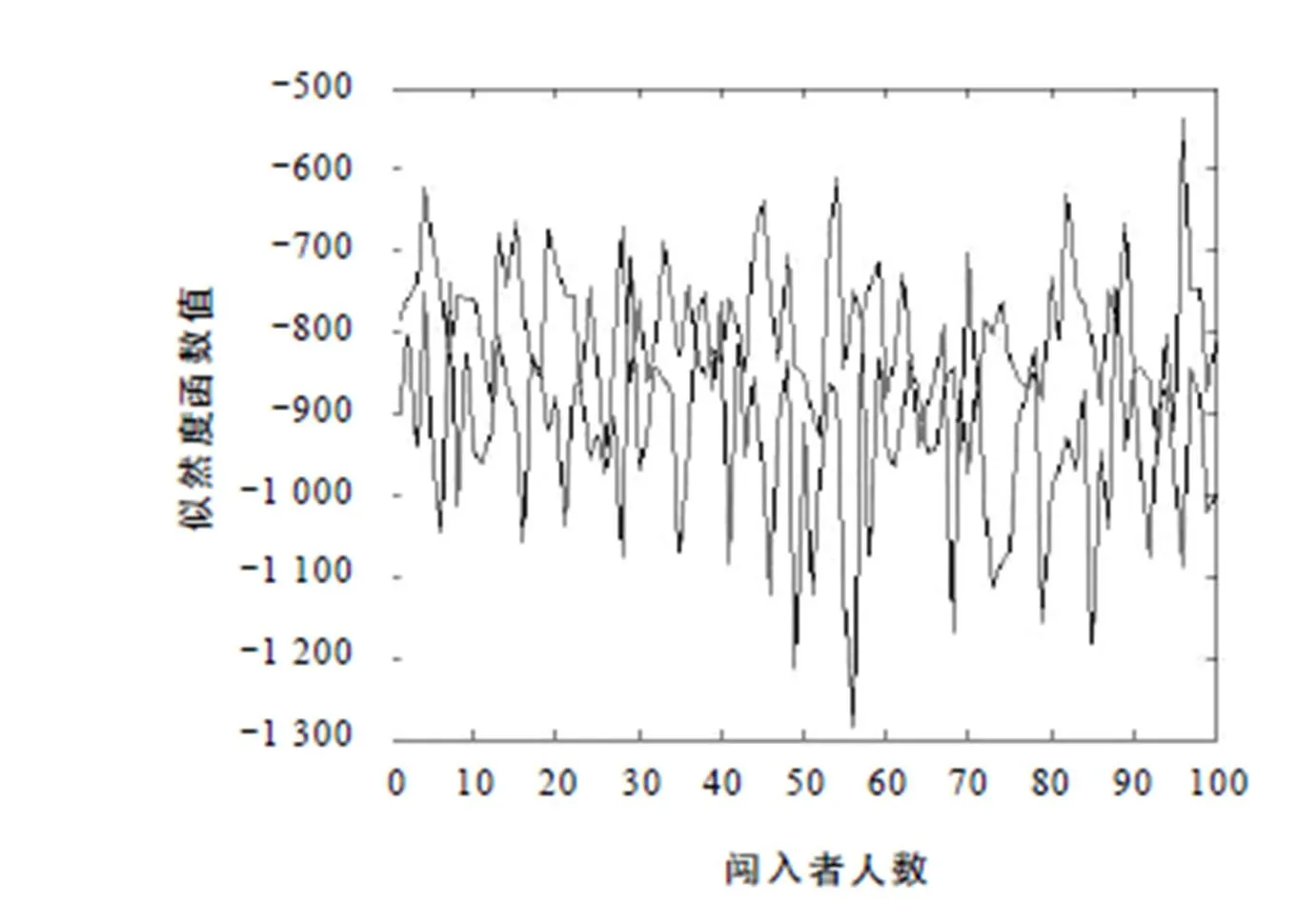
图3 中文GMM似然曲线图
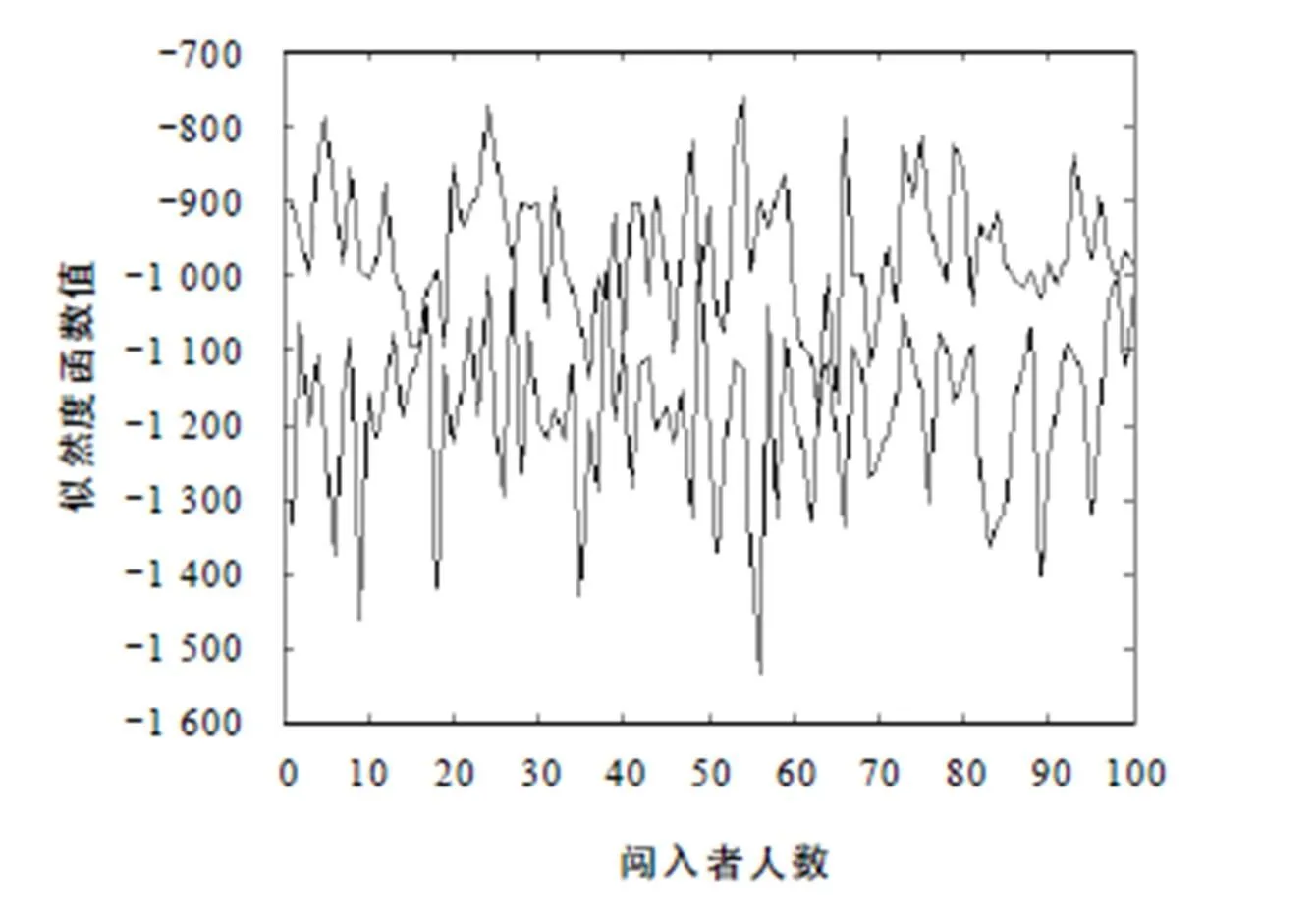
图4 中文GMM-UBM似然曲线图



表2 3种语言的开集实验结果对照 %
由上述实验可知:用于训练的原始数据量越充分,系统的性能越好;GMM-UBM充分利用了GMM的优点,反映了所有待识别语种的特征分布,涵盖了更多语言的发音情况,且利用贝叶斯自适应算法能快速地分离出各种语言的GMM参数,得到每种语种的模型. 与传统的GMM方法相比,UBM方法的训练和识别速度更快,识别率明显高于GMM.
4 结束语
本文将GMM-UBM用于语言辨识系统,获得了平均正确率74%的识别效果,这说明GMM-UBM模型是语言辨识的一种有效方法.
[1] 赵力. 语音信号处理[M]. 北京:机械工业出版社,2003.
[2] 屈丹,王炳锡,魏鑫. 基于GMM-UBM模型的语言辨识研究[J]. 信息处理,2003, 19(1): 85-88.
[3] 姜洪臣,郑榕,张树武,等. 基于SDC特征GMM-UBM模型的自动语种识别[J]. 中文信息学报,2007, 21(1): 49-53.
[4] 王炳锡,屈丹,彭煊. 实用语音识别基础[M]. 北京:国防工业出版社,2005.
[责任编辑:孙建平]
A Study of a Language Identification Algorithm Based on the GMM-UBM Model
CHENYe-xian,ZHANGXin-yi,MAOJie
Language identification technology is a very important part of the speech recognition technology. In this paper, based on the practical application and a self-established voice database, a language identification system based on the GMM-UBM model and independent of the speaker is studied and compared with the traditional GMM methods. Experiment results show that this algorithm can effectively improve the performance of the language identification system and achieve an average recognition rate of 74%.
language identification; GMM-UBM; EM; Bayesian adaptive algorithm
1006-7302(2010)03-0005-56
TP391.4
A
2009-05-20
陈业仙(1970—),女,广东阳江人,实验师,硕士,研究方向:语音信号处理,E-mail: chenyexian@126.com.
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
时代邮刊(2021年8期)2021-07-21 07:52:44
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:05
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
高中生·天天向上(2009年11期)2009-12-17 02:55:44
