
应用EFR编码技术改善MOS语音效果分析
2010-06-26 06:25连正川
电信工程技术与标准化 2010年3期
连正川
(中国联通福建分公司 福州 361000)
1 概述
GSM系统是数字移动通信系统,因此话音信号需进行数字化处理,即把话音模拟信号转换成数字信号后再进行传输,包括了采样、量化、编码三个过程。语音编码技术通常分为三类:波形编码、参量编码(声源编码)和混合编码。
波形编码直接对模拟语音取样、量化、编码,主要以脉冲编码调制(PCM)和增量调制(AM)为代表。波形编码速率一般在16~64kbit/s之间。它可提供很好的话音质量,但编码速率较高,一般应用在信号带宽要求不高的通信中,如有线通信。数码率在64~32kbit/s之间音质优良,当数码率低于32kbit/s的时候音质明显降低,16kbit/s时音质非常差。
参量编码又称声源编码,是以发音模型作基础,从模拟话音提取各个特征参量并进行量化编码,可实现低速率语音编码,达到2~4.8kbit/s。但话音质量只能达到中等。
混合编码:是将波形编码和参量编码结合起来,既有波形编码的高质量优点又有参量编码的低速率优点。其压缩比达到4~16kbit/s。
GSM规范规定载频间隔是200kHz。 每个200kHz信道又被分成8个时隙,每时隙最大传输22.8kbit/s的原始信道容量。由于无线传输并不可靠,需要为数据增加保护。因此要在规定的带宽内,实现较好的话音质量,必须大大降低每个话音信道编码的比特率,这就需要采用低速率话音编码技术来实现。GSM语音编码主要采用混合编码方式。为了满足GSM系统的窄带通信模式,GSM目前主要采用四种话音编码技术,即:速率为13kbit/s的全速率(FR)编码技术、速率为12.2kbit/s的增强型全速率(EFR)编码技术、自适应多速率(AMR)以及速率为5.6kbit/s的半速率(HR)编码技术。
本文主要重点介绍GSM的增强型全速率(EFR)编码技术和全速率(FR)编码技术两种,并通过实际应用中,对两者在改善用户语音通话效果的不同情况进行分析。
2 某地市开通EFR前后MOS评估效果比较
2.1 DT测试MOS评估对比
福建某地市岛内区域全网开通EFR编码技术。开通后对相关拨测人员进行调查,普遍反映通话声音比开通前更清晰,保真度明显更好,通话效果接近CDMA网络。采用鼎利公司MOS语音评估测试设备,以该地市BSC65覆盖区域为DT测试范围,对FR条件下和EFR条件下的MOS语音评估值进行DT测试对比,具体测试情况如图1~4所示。
从统计结果看,开通EFR后,MOS值在4以上比例明显比在FR条件下要高得多,在EFR条件下DT测试网络MOS语音评估平均值达到3.53,比FR条件下测试得到的MOS平均值3.08提高了0.45;具体结果如表1。

图1 在FR条件下MOS评估测试轨迹图

图2 开通EFR后MOS评估测试轨迹图
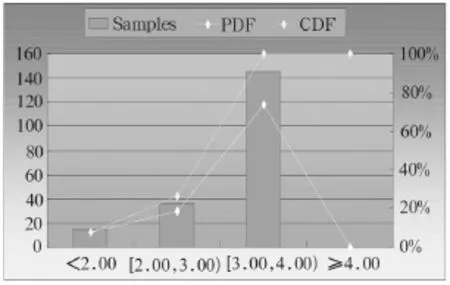
图3 在FR条件下MOS评估柱状图
2.2 CQT测试MOS评估对比
本次CQT测试选定了省网优中心办公楼、联通机房、火炬工商银行三个地方进行定点CQT测试,采用鼎利MOS语音评估设备在FR和EFR条件下分别进行多次语音呼叫,最终得出两种不同条件下的MOS评估结果。开通EFR技术后CQT测试MOS平均值达到3.97,比FR条件下的MOS平均值3.38提高了0.59,测试结果如表2所示。
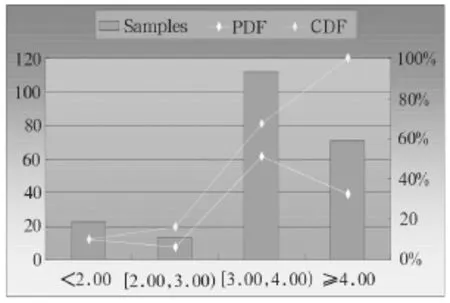
图4 开通EFR后MOS评估柱状图
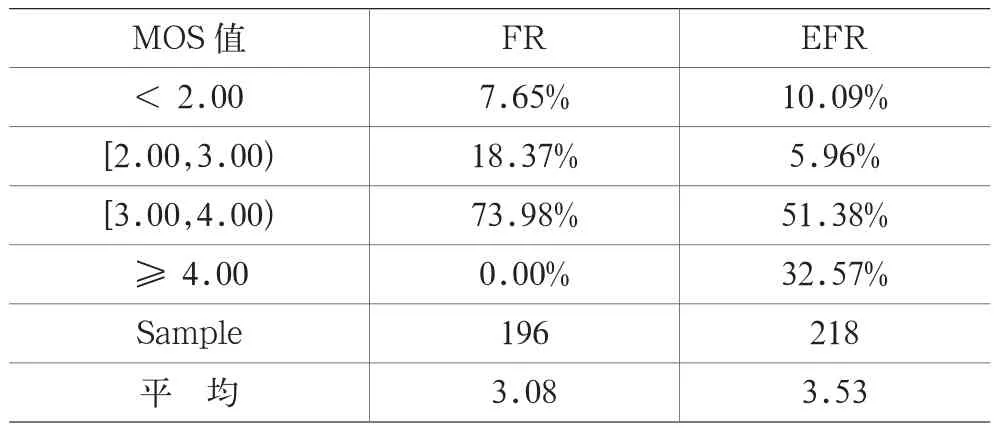
表1 开通EFR前后BSC65覆盖区域MOS评估统计情况

表2 开通EFR前后定点CQT测试MOS评估对比
2.3 实验结论
从上面DT测试和CQT测试均表明,在相同无线环境下,采用EFR编码技术得到的MOS语音评估值要比采用FR编码技术要高,与实际用户反映相吻合,因此开通EFR编码技术对改善用户主观感受意义重大。
3 FR与EFR编码技术介绍
3.1 全速率(FR)编码技术
FR即速率为13kbit/s的全速率(FR)编码技术,全称为线性预测编码-长期预测编码-规则脉冲激励编码器(LPC-LTP-RPE编码器),编码器原理图如图5所示。主要通过两种技术来提高LPC 编码器的质量,即长时预测LTP(Long Term Prediction)与规则脉冲激励RPE(Regular Pulse Excitation)。LPC+LTP为声码器,RPE为波形编码器,再通过复用器混合完成模拟话音信号的数字编码,每话音信道的编码速率为13kbit/s。它是一种混合编码技术,集成了波形编码与声源编码两项技术之长,可以获得达到4.0左右QoS的语音通信质量(国际电联规定语音通信质量QoS满分为5)。声码器将话音信号分成20ms的声码块,分析这一时间段内所对应的滤波器的参数,并提取此时的脉冲串频率,输出其激励脉冲序列。相关的话音段是十分相似的,LTP将当前段与前一段进行比较,相应的差值被低通滤波后进行波形编码。其中LPC十LTP参数:3.6 kbit/s;RPE参数:9.4kbit/s;因此,话音编码器的输出比特速率是13kbit/s。

图5 LPC-LTP-RPE编码器原理示意图
3.2 增强型全速率(EFR)编码技术

图6 CELP编码器原理示意图
EFR声码器是一种代数码激励线性预测(ACELP)编码器,是码激励线性预测(CELP)编码中的一种。它计算更加密集,能在输出端得到更为精确的结果。CELP语音编码算法采用线性预测提取声道参数,用一个包含许多典型的激励矢量的码本作为激励参数,每次编码时都在这个码本中搜索一个最佳的激励矢量,这个激励矢量的编码值就是这个序列的码本中的序号。编码器的基本原理框图如图6所示。
与LPC模型类似,CELP模型中也有激励信号和声道滤波器,但它的激励信号不再是LPC模型中的二元激励信号。在目前常用的CELP模型中,激励信号来自两个方面:长时基音预测器(又称自适应码本)和随机码本。自适应码本被用来描述语音信号的周期性(基音信息)。固定的随机码本则被用来逼近语音信号经过短时和长时预测后的线性预测余量信号。从自适应码本和随机码本中搜索出的最佳激励矢量乘以各自的最佳增益后相加,便可得到激励e(n)。它一方面被用来更新自适应码本,另一方面则被输入到合成滤波器H(z)以得到合成语音^s(n)。^s(n)与原始语音s(n)的误差通过感觉加权滤波器W(z)后可得到感觉加权误差信号e(n)。使e(n)均方误差为最小的激励矢量就是最佳激励矢量。
为了提高重建话音的自然度,编码端增加一组预测滤波器,采用闭环LPC结构,由特征参数激励得到预测信号,将此信号与原信号s(n)相减得到残差信号e(n)。如果把此信号与有关参数一并编码传送,在解码端进行误差修正可有效改善语音质量,但此时将降低编码效率。如果能对一定时间内残差信号可能出现的各种样值的组合按一定规则排列构成一个码本,编码时从本地码本中搜索出一组最接近的残差信号,然后对该组残差信号对应的地址编码并传送,解码端也设置一个同样的码本,按照接收到的地址取出相应的残差信号加到滤波器上完成话音重建,则显然可以大大减少传输比特数,提高编码效率。这就是CELP编码的基本原理。对CELP编码来说码本很关键,码本编得好,就可以在低码率下获得较好的语音质量。
EFR声码器的12.2kbit/s输出等于每帧244bit。但是其所编码语音是通过拥有260位容量的常规GSM全速率空中信道来传输,其余16bit被填以CRC以及重复一些用于冗余的最重要编解码器参数,因此也提高了抗误码能力。
4 推广
与FR相比,采用EFR增强型全速率可以更好的改善用户主观通话感受,这在福建某地市具体实践得到验证。另一方面,EFR增强型全速率需要网络服务商开通此项网络功能,手机终端也要支持EFR功能才能配合实现。在福建某地市开通EFR后,通过网管统计全网有94.57%的用户采用EFR编码方式,仅2.30%用户使用FR方式,其余3.13%用户因为话务负荷原因占用HR信道。这表明目前市场上绝大部分的手机终端均已支持EFR编码方式,因此开通EFR可以达到改善全网用户感受的预期,值得进一步推广应用。
[1]李昌立,吴善培编著. 数字语音-语音编码实用教程. 北京:人民邮电出版社,2004年
[2]GSM Phase2+,GSM 0610-Full Rate Speech Transcoding
[3]GSM Phase2+, GSM 0660-Enhanced Full Rate (EFR)Speech Transcoding
[4]陈润洁,钟子发,王红军. GSM数字移动通信系统语音信源编解码技术.电讯技术,2004年
猜你喜欢
南京邮电大学学报(自然科学版)(2022年4期)2022-09-20
中国民航大学学报(2021年3期)2021-08-04
通信学报(2020年3期)2020-04-06
纯粹数学与应用数学(2018年3期)2018-10-10
成都信息工程大学学报(2018年3期)2018-08-29
物联网技术(2018年6期)2018-06-29
制造技术与机床(2017年7期)2018-01-19
电子器件(2015年5期)2015-12-29
无线电工程(2014年1期)2014-06-14
电测与仪表(2014年13期)2014-04-04
