
基于树核函数的“it”待消解项识别研究
2010-06-19 06:25陈九昌朱巧明周国栋
中文信息学报 2010年5期
陈九昌,孔 芳,朱巧明,周国栋
(1.苏州大学计算机科学与技术学院,江苏 苏州 215006;2.江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
1 引言
指代是指在篇章中用一个指代词回指某个以前说过的语言单位。在语言学中,指代词称为照应语,所指的对象或内容称为先行语。指代消解就是确定照应语和先行语之间相互关系的过程,它是自然语言处理的关键问题之一。在文本摘要、机器翻译、多语言信息处理和信息抽取等诸多运用中都涉及到指代消解问题。
待消解项识别是判断指代词是否指向某个语言单位,是否需要消解的过程,它是指代消解研究的重点问题之一。Stoyanov等[1]详细论述了影响指代消解性能的三个因素,其中第三个因素就是待消解项的识别(Anaphoricity Determination),他指出加入待消解项识别可以减少错误的消解元素(Coreference Elements),使需要消解的元素集更接近正确标注的元素集,他在MUC、ACE语料进行的理想实验证明F值可以提高6~10。在待消解项识别研究中,“it”待消解项的识别最为复杂,Evans[2]将“it”的用法归纳为7类:名词性指代、从句指代、前置词、向后照应、篇章中心、系表结构、习惯用法,并尝试使用机器学习的方法进行“it”类别的判断,效果不是很好。由此看出,准确地识别“it”的用法是极具挑战性的。
在指代消解研究的早期就有研究者意识到待消解项识别的重要性,经过这些年的发展,关于待消解项的识别方法经历了基于规则的方法,基于统计的方法和基于分类的方法。本文采用基于树核的机器学习方法属于第三类,但将规则、统计的研究成果运用于句法树的裁剪,且又将分类方法中的特征方法与树核方法融合起来,综合产生“it”待消解项分类器。最后将分类器加入到代词指代消解,实验证明能够明显地提高代词指代消解性能。
2 相关工作
早期的“it”待消解项识别是基于规则的方法,Hobbs等[3]使用句法树进行代词指代消解研究时,对指向时间、天气的“it”不进行指代消解。Lappin等[4]在指代消解平台中引入了用于识别“it”是否是待消解项的独立识别模块。在识别模块中,设定了一些模式,例如:“It is Cogv-ed that Sentence” ,其中Cogv是像think、believe等这样的认知动词。随着大规模语料库的产生,出现了基于统计的方法,代表是Bergsma等[5],他利用“it”的局部上下文句式进行过滤识别,在大型语料库中对句式出现频度进行统计,再根据结果进行“it”是否是非待消解项的判断。随后产生的基于机器学习的方法又分为基于特征向量的方法和基于树核的方法,Ng等[6]给出了一种基于特征的待消解项识别方法。他们选取了包括词法、语法、句式、语义、位置等多方面的37个特征,以M UC-6和MUC-7作为训练、测试语料,并将生成的待消解项识别模型应用于已有的指代消解系统,通过实验证明了待消解项识别模块的引入,能进一步提高指代消解系统的性能,但对代词的性能提高帮助不是很大。王海东等[7]使用复合核研究英文代词消解时,对“it”进行了简单的规则过滤,提高了代词指代消解性能。Zhou等[8]从特征和树核两方面研究了待消解项识别,都取得了很好的效果。特别是树核,通过不同的裁剪策略,构造不同的句法树,充分包含了指代词的结构化信息,训练出的过滤器具有较高的性能。但是,对于“it”来说,单纯的结构化信息很难区分它是否是待消解项。比如:
例1:You can make it in advance.
例2:You can make it in Hollywood.
例1和例2在结构上非常相似,但例1中的“it”是待消解项,例2的则是非待消解项,它和“make”构成一个固定搭配,表示“成功”。如果配合上下文信息,例2中的“it”也可能是待消解项。
本文受Zhou等[8]启发,在树核方面探索更能区分“it”是否是待消解项的句法树剪裁策略,同时将规则、统计方法的研究成果扩展为树的剪裁方法。在特征方面选择能够充分表示“it”自身及其上下文信息的特征集。两者信息结合产生训练实例,在交由支持复合核函数的SVM训练生成“it”待消解项分类器。最后将其运用到现有的指代消解平台中,在ACE2003基准语料上的实验表明,在较少损失召回率的情况下,极大地提高了代词指代消解系统的准确率,F值也明显得到提高。
3 复合核
3.1 线性核
线性核函数K,对所有的 x,z∈X,满足:

这里Φ表示从输入空间X到特征空间F的映射 。具体而言 :x=(x1,…,xk)a,Φ(x)=(Φ1(x),…,Φn(x)),则将输入空间X映射到了一个新的空间F={Φ(x)|x∈X}。线性核是最优分类面中采用适当的内积函数K(xi,xj),实现某一非线性变换后的线性分类,同时计算复杂度却没有增加。
3.2 卷积树核
卷积树核函数是通过计算两棵解析树之间的相同子树的数量来比较解析树之间的相似度。例如有两棵解析树T1和T2,要计算相似度
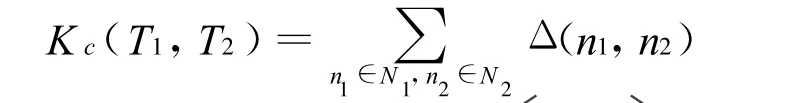
其中Nj是Tj的节点集合计算以n1和n2为根的共同子树个数,可以按照下面这种递归的计算方法:

其中#ch(n1)是节点n1的子节点数目,ch(n,k)是节点n的第 k个子节点,λ(0<λ<1)是衰退因子。
3.3 复合核
本文使用的复合核属于线性复合,函数如下:

其中KL和KP分别表示基于平面特征的线性核函数和基于结构化句法信息的卷积树核函数,两者都经过归一化,从而避免复合函数的值过多地依赖于其中的一个函数,α是两者的复合系数,用于调整两个函数对复合函数的贡献,以期取得最好的效果。经多次实验测试,对于本文所研究的问题,α取0.4时所得到的系统性能最好。这说明复合核充分发挥了卷积树核和线性核的作用,并且使两者相辅相成,表现出更好的分类性能。复合核训练、测试实例如图1所示。

图1 复合核训练、测试实例
|BT|与|ET|之间的内容是按照不同剪裁策略得到的“it”自身及其周围相关结构化信息,由于句法树中叶子节点所包含的信息可由它的词性标注体现,为减少噪音,句法树的叶子节点被舍弃,以“E”标记“it”在句法树中的位置。在|ET|之后的是平面特征信息。
4 句法树裁剪
待消解项识别的训练、测试实例与指代消解的产生方式有所不同,一般指代消解的实例包含照应语和候选先行词,在树的裁剪时主要包含这两者的信息,例如 Yang等[9]提出的三种不同剪裁策略。而待消解项通常是一个指代词,例如“it”,需要通过对它自身属性,上下文环境的判断来决定它是否为照应语。Zhou等适当地对已剪裁的句法树进行扩展,添加一些附加节点,取得了最好的性能,但也存在破坏句法树自身结构的可能性,本文将这些扩展的信息作为特征加入训练实例,最大可能地保持句法树结构的完整,同时也不丢失这些信息。结合以上研究,本文将剪裁窗口设置为5,探索了以下三种“it”句法树的剪裁方式。
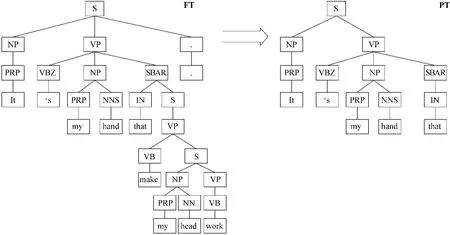
图2 PT树
对于Evans称之为系表结构的“it”,由于它在词语的顺序上有一定的规律,这种规律可以通过词性标注反映出来,所以在树的裁剪时关注“it”跟在其后的介词 ,如“to”、“for”、“that”等 ,然后剪裁出这些词与“it”之间的 PT树(Path_enclosed Tree)。FT(Full Tree)是由 Charniak Parser得到的“it”所在句子的完整句法树。
除系表结构的“it”之外,通过观察句法树,在语法角色中担任受施者角色的“it”,其左右节点能反映“it”的相关信息,因此以“it”为中心,裁剪出前后扩展两个节点的MT树(Middle Tree),以包含“it”前后的句法信息,如图3所示。
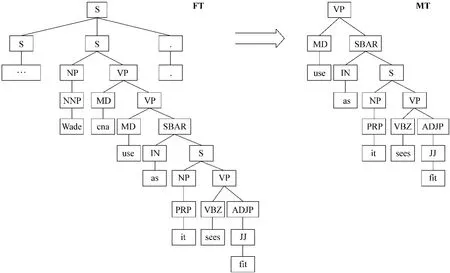
图3 MT树
“it”在句法树中可能是某个动词的主语或直接宾语,也可能依存于其他句法成分或被其他成分依存,这些节点的信息更能够反映“it”的性质。为此,本文提出了第三种剪裁方案 DT树(Dependency Tree),如图 4 所示 。在 FT 树中,“it”是“intends”的主语,也是“allow”的间接主语,这些依存关系可以通过Stanford Parser得到。
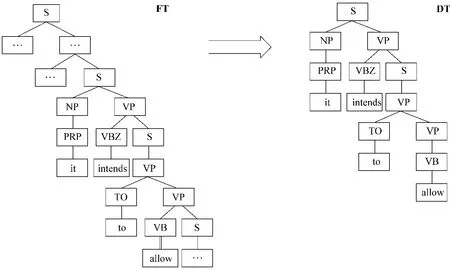
图4 DT树
5 特征选择
在指代消解中,贡献度比较高的特征是全匹配,Soon[10]在MUC-6语料上,单独使用全匹配特征F值就达到了53.9。同时,同位语、别名这两个特征对消解也很重要,F值分别为7.3、38.4。但本文发现这些特征是反映照应语与先行语之间关系,而非照应语或先行语自身的特征,对待消解项识别作用不是很大,所以将它们作为次要特征加入特征集。
Kong等[11]研究了基于中心理论的语义角色对指代消解的作用,她将中心理论的研究成果拓展到语义层,提炼成三组特征集加入了指代消解。通过在ACE 2003语料上的实验表明,三组特征集的引入能极大提升系统的性能,特别是对代词指代消解的性能,而这些特征也正能够反映“it”上下文信息。
Muller[12]探索了如何判断口语对话领域中的“it”是否为待消解项,他提出的特征包含语法模式、词汇特征、距离特征、其他特征,对本文的特征选择具有很大的参考价值。
结合上述研究,本文提出了如表1所列的特征,基本包含了“it”自身及其上下文环境。

表1 “it”待消解项识别过滤器特征集
6 实验及结果分析
实验语料采用ACE2003基准语料,它包含NWIRE、NPAPER、BNEWS三个子类,本文对各类中“it”情况进行了统计(见表2)。表中数据显示非待消解项“it”在各语料中的比例都超过60%,能否正确判断“it”的类型将直接影响代词乃至整体指代消解性能。
本文的原型系统采用基于特征的机器学习方法进行指代消解,是在Soon系统的基础上扩展,使用SVM Light①http://svmlig ht.joachims.org/作为分类器。原始文本预处理包括:句子识别、分词、词性标注、命名实体识别、语义类别获取、句法分析等。本文使用Zhou等[13]的预处理系统,其中命名实体识别、词性标注以及名词短语识别都是基于错误驱动的HMM模型;名词短语的中心词获得用的是Collins的方法[14];语义信息则从WordNet中获取。每一个训练和测试用例都使用形式{AN,CAi},其中AN表示照应语,CA表示它的可能先行语,i表示当前的词语是第几个候选语,不同的是训练阶段实例具有指代关系,而测试阶段是将实例交由训练生成的分类模型判断是否具有指代关系。
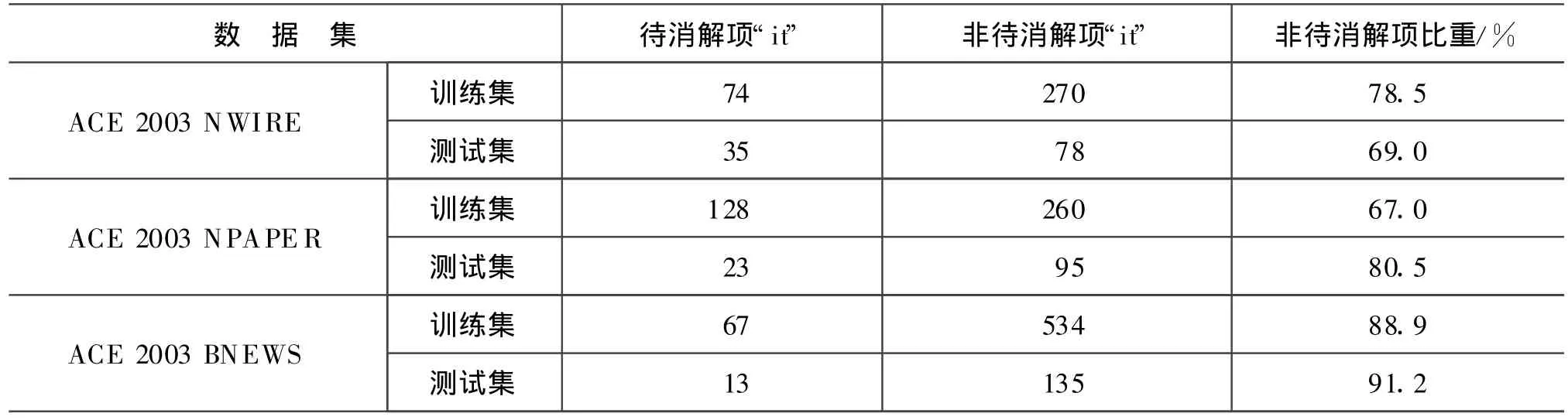
表2 ACE2003语料中“it”频率统计
待消解项分类器的产生流程与原型系统类似,不同的是实例只包含AN信息,采用的是复合核的方法。本文采用Zhou等对待消解过滤器的性能评测参数为:正例准确率Acc+,即正确识别“it”为待消解项个数占应识别的待消解项“it”个数的比例,这一准确率越高,说明被丢失的待消解项越少,召回率的损失越低;负例的准确率Acc-,即正确识别“it”非待消解项的个数占总非待消解项“it”个数的比例,这一准确率越高,无效实例越少,引入的噪音越少。
6.1 待消解项分类器性能
首先,测试基于特征的“it”待消解项分类器的性能(见表3)。由表中数据看出正例的准确率比较低,而负例的准确率相对较高。导致这一现象原因,一是非待消解项的“it”比例比较大,而正例数量很少,二是特征不充分,导致很多正例被识别成负例。由于系表结构的“it”在语料中比例不是很高,所以PT与M T或DT结合使用。例如PTMT是指先判断当前“it”是否是系表结构,如果不是再使用M T方法。“+”表示加上特征信息,组合生成复合核的实例。从整体上来看,复合核的方法能明显提高分类器的性能,对比PTMT和PTDT,根据依存关系裁剪的方法更加有效。三大语料中负例的高准确率说明分类器性能已取得比较高的水平。对于BNEWS语料上正例的准确率高达84.6%,这可能是因为BNEWS中正例的“it”仅为13。
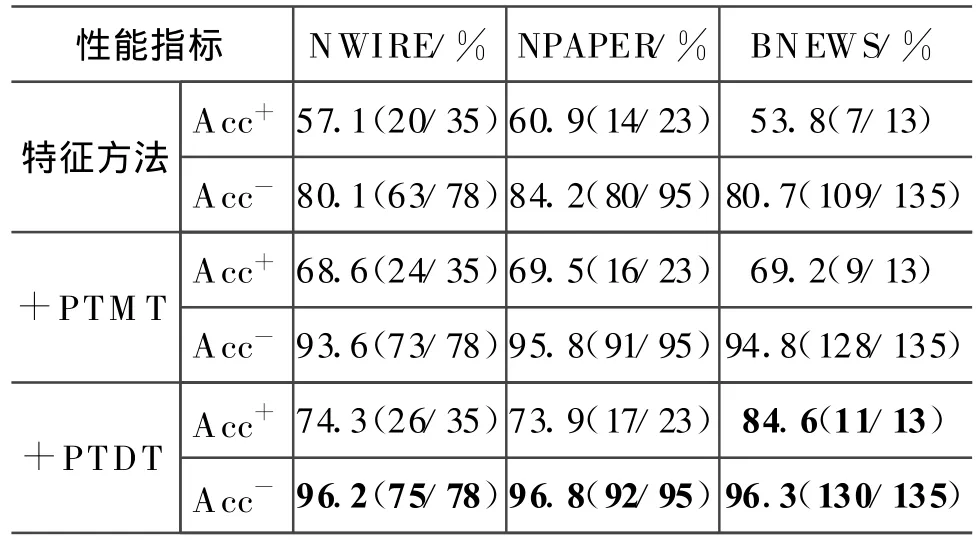
表3 “it”待消解项分类器性能
6.2 代词指代消解
将训练生成的“it”待消解项分类器引入代词的指代消解中,测试其对代词指代消解各方面性能的影响。引入“it”待消解项分类器时,代词指代消解原型系统的训练过程不变,只是在生成测试实例时,将代词“it”交由分类器判断是否为待消解项,如果是则继续后续的消解流程;如果不是则直接放弃。
代词指代消解原型系统的性能参数如表4所示,从表中数据看出,本文采用的原型系统具有较高的水平,略低于Zhou等所采用的基准系统。采用特征方法生成的“it”待消解项分类器,三大语料的代词消解性能略有提高,F值分别提高了0.3、0.4、1.3。采用特征和PTMT组合生成的“it”待消解项识别分类器使三大语料中代词消解的准确率分别提高了5.7%,5.2%,12.6%,召回率略有下降,这是由于分类器的高Acc-和低Acc+所造成。特别是BNEWS语料,不需要消解的“it”的比例高达91.2%(见表 2),过滤掉这些噪音,准确率竟提高了12.6%。采用PTDT方法的分类器使代词指代消解取得了最好的性能,相比原型系统,F值分别提高了2.7、3.5、6.2。这也证明了 Stoyanov等[1]对待消解项识别重要性的观点。由于PTDT方法在正例的“it”识别率上有所提高,所以在性能上优于PTMT方法和特征方法。
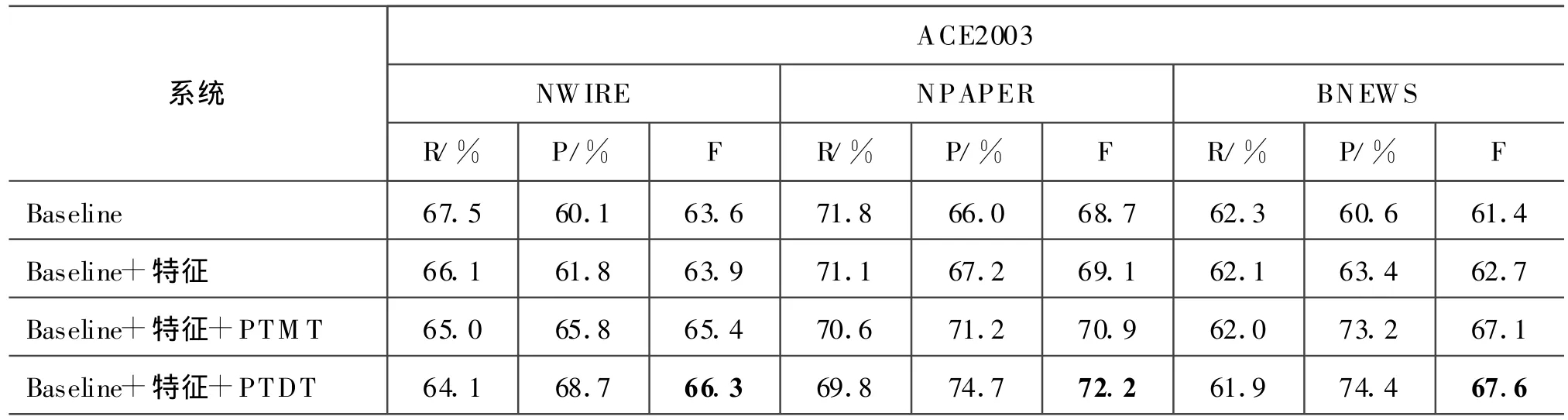
表4 引入分类器的代词指代消解性能
7 总结
“it”待消解项识别一直是研究的热点,采用规则、特征、树核的方法已取得不错效果。本文采用复合核,结合了树核和特征的优点,训练生成“it”待消解项分类器。在树的裁剪方面,根据“it”在句法树的特点,提出了三种裁剪策略。在特征选择方面,结合已有的和最新的研究成果,挖掘能反映“it”自身及上下文环境的特征。在ACE2003基准语料测试表明“it”待消解项分类器取得了较好的性能。然后将其用于代词的指代消解中,实验证明了它对代词指代性能的提高有很大的帮助。
本文下一步研究是树的裁剪方法和更大规模的“it”语料库,现有的树的裁剪是基于观察、经验,没有充分利用“it”在句法树上的语法、句法等信息,如若采用更加合理的裁剪策略,相信能进一步提高分类器的性能。ACE2003基准语料中待消解项“it”与非待消解项“it”的数量比较少且比例很不均衡,不利于充分比较特征、树核、复合核之间的差异,需要寻找更加具有代表性的语料。
[1]Veselin Stoyanov,Nathan Gilbert,Claire Cardie and Ellen Riloff.Conundrums in Noun Phrase Coreference Resolution:Making Sense of the State-of-the-Art[C]//ACL'2009:656-664.
[2]Richard Evans.Applying Machine Learning Toward an Automatic Classification of It[C]//Literary and Linguistic Computing,2001,16(1):45-57.
[3]J.Hobbs.1978.Resolving pronoun references[J].Lingua,44:339-352
[4]Lappin S.,Herbert J.L.An algorithm for pronominal anaphora resolution[J].Computational Linguistics,1994,20(4):535-561.
[5]Bergsma S.,Lin D.and Goebel R.Distributional Identification of Non-referential Pronouns[C]//ACL'2008:10-18.
[6]Ng V.and Cardie C.Identify Anaphoric and Non-Anaphoric Noun Phrases to Improve Coreference Resolution[C]//COLING'2002.
[7]王海东.基于树核函数的英文代词消解研究[J].中文信息学报,2009,23(5):33-39.
[8]Zhou G.D.and Kong F.Global Learning of Noun Phrase Anaphoricity in Coreference Resolution via Label Propagetion[C]//EMNLP'2009:978-986.
[9]Yang X.F.,Su J.and Tan C.L.Kernel-Based Pronoun Resolution with Structured Syntactic Knowledge[C]//ACL'2006:41-48.
[10]Soon W.M.,Ng H.T.and Lim D.A machine learning approach to coreference resolution of noun phrase[J].Computational Linguistics,2001,27(4):521-544.
[11]Kong F.,Zhou G.D.and Zhu Q.M.Employing the Centering Theory in Pronoun Resolution from the Semantic Perspective[C]//EMNLP'2009:987-996
[12]Christoph Muller.Automatic detection of nonreferential It in spoken multi-party dialog[C]//EACL'2006:49-56.
[13]ZhouG.D.andSuJ.A high- performance coreference resolution system using a multi-agent strategy[C]//COLING'2004:522-528.
[14]Collins M.Head-driven statistical models for natural language parsing[D].Ph.D.Thesis,the University of Pennsylvania.1999.
[15]王厚峰.指代消解的基本方法和实现技术[J].中文信息学报,2002,16(6):9-17.
[16]王晓龙,关毅,等.计算机自然语言处理[M].北京:清华大学出版社,2005.
猜你喜欢
科学咨询(2022年19期)2022-11-24
通信技术(2021年12期)2022-01-25
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
考试与评价·八年级版(2020年1期)2020-10-26
高中生·天天向上(2018年1期)2018-04-14
自动化学报(2017年11期)2017-04-04
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
